



OpenAI 的 CLIP(Contrastive Language-Image Pre-training)是多模态学习领域的里程碑之作。它通过海量的图文数据对,仅使用自然语言作为监督,便学习到了强大的、可泛化的视觉表征,其“Zero-Shot”能力令人惊艳。
本文将从一份torch源码 实现出发,逐行拆解CLIP的核心组件,带您领略其简洁而强大的双塔架构。我们将重点分析:
- 双塔结构: 图像与文本编码器如何协同工作。
- 编码器实现: 如何使用
VisionTransformer和TextTransformer提取关键特征。 - CLIP精髓: 深入剖析对比学习损失函数(Contrastive Loss)及其代码实现。
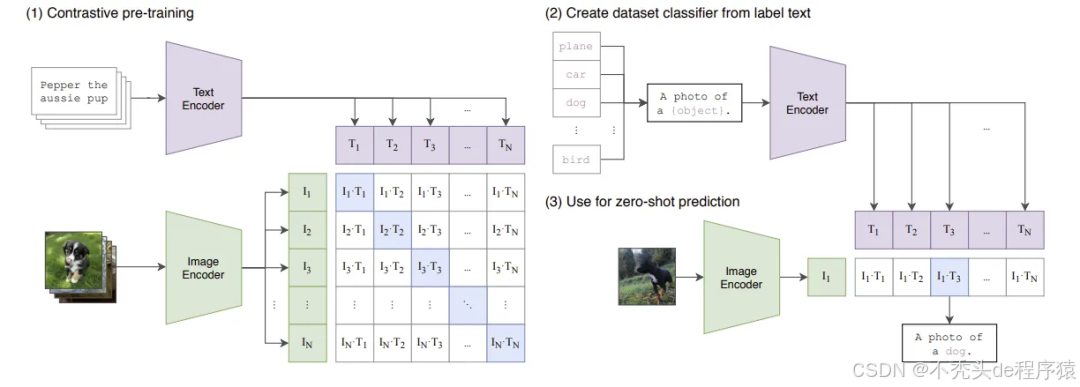
整体架构:万流归海的双塔模型
CLIP的核心思想是构建两个独立的编码器,一个用于图像,一个用于文本。它们的目标是将输入的图像和文本映射到同一个多维特征空间。在这个空间中,语义匹配的(图像,文本)对将具有高度相似的特征向量(即余弦相似度高),而不匹配的则相反。
您的CLIP类__init__方法完美地勾勒出了这个蓝图:
class CLIP(nn.Module): def __init__(self, edmbed_dim: int, # 图文统一特征维度 # ... Vision Parameters ... vision_embed_dim: int, # ... Text Parameters ... text_embed_dim: int, # ... other params ... ): super(CLIP, self).__init__() # 1. 图像编码器 (Image Encoder) self.vision_transformer = VisionTransformer( # ... vision_params ... embed_dim= vision_embed_dim, ) # 2. 文本编码器 (Text Encoder) self.text_transformer = TextTransformer( # ... text_params ... embed_dim=text_embed_dim, ) # 3. 投影层 (Projection Heads) # 将各自的特征维度,统一映射到最终的联合嵌入维度 edmbed_dim self.vision_projection = nn.Linear(vision_embed_dim, edmbed_dim, bias=False) self.text_projection = nn.Linear(text_embed_dim, edmbed_dim, bias=False) # 4. 可学习的温度系数 self.logit_scale = nn.Parameter(torch.ones([]) * torch.log(torch.tensor(1 / 0.07))) self._initialize_parameters()
架构解读:
vision_transformer和text_transformer是两个独立的主干网络。vision_projection和text_projection是两个至关重要的线性层。它们负责将两个编码器(可能具有不同输出维度,如ViT的768维和Transformer的512维)的输出,投影(project) 到一个相同维度(edmbed_dim,例如512)的联合特征空间,这是实现图文对齐的前提。logit_scale是一个可学习的标量(温度系数 ),我们将在损失函数部分详细介绍它的关键作用。
图像编码器:Vision Transformer (ViT)
对于图像塔,您的代码采用了VisionTransformer (ViT)。ViT将图像视为一个序列的Patches,然后使用标准的Transformer Encoder进行处理。
其数据流(forward) 是理解的关键:
class VisionTransformer(nn.Module): # ... __init__ ... def forward(self, x: torch.Tensor) -> torch.Tensor: # Input Shape : (B, C, H, W) # 1. 图像 -> 块嵌入 (Patch Embedding) x = self.patchembedding(x) # (B, num_patches, embed_dim) # 2. 拼接 [CLS] Token # '() n c -> b n c' (einops) == repeat(1,1,dim) to (B,1,dim) cls_token = repeat(self.cls_token, '() n c -> b n c', b=x.shape[0]) x = torch.cat([cls_token, x], dim=1) # (B, num_patches + 1, embed_dim) # 3. 添加可学习的位置编码 x = x + self.pos_embedding # (B, num_patches + 1, embed_dim) x = self.pos_drop(x) # 4. 通过 Transformer 编码器 x = self.transformer_blocks(x) # 5. 提取 [CLS] Token 的输出作为图像全局特征 x = x[:, 0, :] # (B, embed_dim) return x
核心解读:
ViT的核心在于第5步:x = x[:, 0, :]。在序列开头添加的[CLS] token,经过多层自注意力(Self-Attention)后,会聚合整个图像的全局信息。因此,我们只取这个[CLS]** token对应的输出向量**作为此图像的最终表征。
在CLIP主类中,这个表征还会经过投影层:
# In CLIP.encode_image()def encode_image(self, img: torch.Tensor) -> torch.Tensor: image_features = self.vision_transformer(img) # (B, vision_embed_dim) image_features = self.vision_projection(image_features) # (B, edmbed_dim) return image_features

文本编码器:Transformer
对于文本塔,您实现了一个TextTransformer。这与原始CLIP论文中使用的标准Transformer架构(类似BERT)是一致的(您提到的ViT,即Vision Transformer,是其在图像侧的应用)。
文本编码器的目标同样是提取一个代表整句语义的全局特征。
class TextTransformer(nn.Module): # ... __init__ ... def forward(self, x: torch.Tensor) -> torch.Tensor: # x: (B, context_length) [Token IDs] text = x # 1. Token 嵌入 + 可学习的位置编码 x = self.token_embedding(x) + self.pos_embedding # (B, context_length, embed_dim) # 2. 通过 Transformer 编码器 x = self.transformer(x) # (B, context_length, embed_dim) x = self.layernorm_final(x) # 3. 提取 [EOT] Token 的特征 # 关键: 选取序列中最后一个有效token(或EOT token)的输出 # text.argmax(dim=-1) 是一个巧妙的技巧,用于定位EOT token x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] # (B, embed_dim) # 4. 内部投影 (在您的实现中) x = self.text_projection(x) return x
核心解读:
与ViT使用[CLS] token不同,文本Transformer通常使用一个特殊的**[EOT] (End of Text) token**的输出来代表全句语义。您的代码中第3步 x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] 正是在执行此操作。它假设[EOT] token是序列中(padding之前的)最后一个token(这个是在分词时候的就确定了,默认最后一个index的vocab作为这个EOT),并精确地提取了它对应的特征向量。
同样,在CLIP主类中,这个特征也会经过_最终_的投影层:
# In CLIP.encode_text()def encode_text(self, text: torch.Tensor) -> torch.Tensor: text_features = self.text_transformer(text) # (B, text_embed_dim) text_features = self.text_projection(text_features) # (B, edmbed_dim) return text_features
CLIP的精髓:对比学习损失函数
到目前为止,我们得到了图像特征 image_features 和文本特征 text_features,它们都位于同一个 (B, embed_dim) 空间中。现在,我们进入CLIP最核心的部分:如何拉近匹配的对,推开不匹配的对?
步骤一:计算相似度矩阵
在CLIP的forward方法中,模型计算了Batch中所有图像与所有文本之间的两两相似度。
class CLIP(nn.Module): # ... __init__, encode_image, encode_text ... def forward(self, img: torch.Tensor, text: torch.Tensor): image_features = self.encode_image(img) # (B, embed_dim) text_features = self.encode_text(text) # (B, embed_dim) # 1. L2 归一化 (Normalization) # 这是计算余弦相似度的关键 image_features = image_features / image_features.norm(dim=-1, keepdim=True) text_features = text_features / text_features.norm(dim=-1, keepdim=True) # 2. 可学习的温度系数 logit_scale = self.logit_scale.exp() # 3. 计算相似度矩阵 (Logits) # (B, embed_dim) @ (embed_dim, B) -> (B, B) logits_per_image = logit_scale * image_features @ text_features.t() logits_per_text = logits_per_image.t() # (B, B) return logits_per_image, logits_per_text, image_features, text_features
代码解读:
- L2归一化: 这是至关重要的一步。将特征向量归一化(L2范数=1)后,向量点积
A @ B.t()在数学上等价于 计算它们之间的余弦相似度。 logit_scale** (温度 ):** 这个可学习的参数logit_scale.exp()(即 )用于缩放相似度得分。这是对比学习中的一个关键技巧。较高的温度会使softmax分布更平滑,而较低的温度会使其更“尖锐”。CLIP通过学习这个参数来自动调节对比学习的难易程度,使其更专注于拉开难分的负样本。- **相似度矩阵 **
(B, B):
logits_per_image:一个 的矩阵。第 行代表第 张图像与所有 个文本的相似度。logits_per_text:只是前者的转置。第 行代表第 个文本与所有 张图像的相似度。
在这个 矩阵中,对角线元素 (i, i) 是正样本对(匹配的图文)的相似度。所有非对角线元素 (i, j) (其中 ) 都是负样本对(不匹配的图文)的相似度。
步骤二:对称交叉熵损失 (Symmetric Cross-Entropy)
CLIP的损失函数(InfoNCE Loss)本质上是两个方向的交叉熵损失之和。
图像到文本的损失 (Image-to-Text Loss):
我们看 logits_per_image (形状 )。对于第 行(第 张图),我们希望它与第 个文本的相似度最高。这本质上是一个B分类问题!
- Logits: 第 行的 个相似度得分。
- Ground Truth: 正确的类别是 。
因此,我们的目标标签(Ground Truth)就是一个简单的 [0, 1, 2, ..., B-1] 序列!
文本到图像的损失 (Text-to-Image Loss):
同理,我们看 logits_per_text。对于第 行(第 个文本),我们希望它与第 张图的相似度最高。
- Logits: 第 行的 个相似度得分。
- Ground Truth: 同样是
[0, 1, 2, ..., B-1]。
原文 code
假设 数据是有一个 label 的,这个时候,可以用这个标签来进行模态的对齐
 ```plaintext
```plaintext
import torch.nn.functional as F# 假设 clip_model 已经实例化并放到了 .cuda()# 假设 img 和 text 是 (B, …) 的输入# 1. 从模型获取 Logitslogits_per_image, logits_per_text, _, _ = clip_model(img, text)# 2. 创建 Ground Truth 标签B = logits_per_image.shape[0]# 标签永远是 [0, 1, 2, …, B-1],因为 (I_i, T_i) 永远在对角线上labels = torch.arange(B, device=logits_per_image.device)# 3. 计算对称交叉熵损失loss_img = F.cross_entropy(logits_per_image, labels)loss_text = F.cross_entropy(logits_per_text, labels)# 4. 最终损失是二者的平均total_loss = (loss_img + loss_text) / 2# 5. 反向传播# total_loss.backward()
这种对称损失(Symmetric Cross-Entropy)强迫模型在 个可能的配对中,**唯独**拉近 个正样本对的特征,同时推开 个负样本对的特征,从而在海量数据中学会了图文的深刻对齐。
变体实现
----
**使用软标签(Soft Labels)的损失。它首先计算了Batch内的(图-图)相似度和(文-文)相似度,并将它们融合作为“软目标”(`targets`),然后试图让(图-文)的 logits(`logits`)去拟合这个软目标。**
```plaintext
image_similarity = torch.matmul(image_features, image_features.t())text_similarity = torch.matmul(text_features, text_features.t())targets = torch.nn.functional.softmax((image_similarity + text_similarity) / 2, dim=-1)
``````plaintext
logits = (image_logits + text_logits) / 2loss = -(targets * logits).sum(dim=-1).mean()
All Code
导入 vit是上期的 vit 中的全部代码
import torchimport torch.nn as nnfrom vit import PatchEmbedding, TransformerEncoderfrom einops import repeat, rearrangeclass VisionTransformer(nn.Module): def __init__(self, img_size: int = 224, patch_size: int = 16, in_channels: int = 3, # num_classes: int = 1000, embed_dim: int = 768, depth: int = 12, num_heads: int = 12, qkv_bias: bool = True, dropout_ratio: float = 0.0, attenntion_dropout_ratio: float = 0.0, mlp_ratio: float = 4.0, norm_layer: bool = True ): super(VisionTransformer, self).__init__() self.patchembedding = PatchEmbedding(img_size, patch_size, in_channels, embed_dim, norm_layer) # vit的pos中的drop_path, vit的位置编码是自己学习的,不是绝对的位置编码 self.cls_token = nn.Parameter(torch.randn(1, 1, embed_dim)) self.pos_embedding = nn.Parameter(torch.randn(1, self.patchembedding.num_patches + 1, embed_dim)) self.pos_drop = nn.Dropout(dropout_ratio) # 已经堆叠过了 self.transformer_blocks = TransformerEncoder( depth=depth, embed_dim= embed_dim, num_heads= num_heads, qkv_bias= qkv_bias, dropout_ratio= dropout_ratio, attenntion_dropout_ratio=attenntion_dropout_ratio, mlp_ratio=mlp_ratio, norm_layer=norm_layer ) self.nom = nn.LayerNorm(embed_dim) if norm_layer else nn.Identity() ## 分类头 # self.head = nn.Linear(embed_dim, num_classes) # 初始化方法 self._initialize_weights() def _initialize_weights(self): # 遍历所有模块 for m in self.modules(): if isinstance(m, nn.Linear): nn.init.trunc_normal_(m.weight, std=0.02) if m.bias is not None: nn.init.zeros_(m.bias) elif isinstance(m, nn.LayerNorm): # weight == 1, bias == 0 nn.init.ones_(m.weight) nn.init.zeros_(m.bias) elif isinstance(m, nn.Conv2d): nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') if m.bias is not None: nn.init.zeros_(m.bias) def forward(self, x: torch.Tensor) -> torch.Tensor: # Input Shape : (B, in_channels, img_size, img_size) # Step1: From Image to Patch Embedding x = self.patchembedding(x) # (B, num_patches, embed_dim) # Step2: Add cls token cls_token = repeat(self.cls_token, '() n c -> b n c', b=x.shape[0]) # (1, 1, embedd_dim) ==> (B, 1, embed_dim) x = torch.cat([cls_token, x], dim=1) # (B, num_patches + 1, embed_dim) # Step3: Add Position Embdding x = x + self.pos_embedding # psoembedding: (1, num_patches + 1, embed_dim) ==> (B, num_patches + 1, embed_dim) x = self.pos_drop(x) # Step4: Transformer Encoder x = self.transformer_blocks(x) # (B, num_patches + 1, embed_dim)不用norm是因为已经在transformer encoder里面norm过了 # Step5: Get cls token output x = x[:, 0, :] # (B, embed_dim) print("cls token output shape:", x.shape) # x = self.head(x) # (B, num_classes) return xclass TextTransformer(nn.Module): def __init__(self, context_length: int, vocab_size: int, embed_dim: int, depth: int, num_heads: int, qkv_bias: bool = True, dropout_ratio: float = 0.0, attenntion_dropout_ratio: float = 0.0, mlp_ratio: float = 4.0, norm_layer: bool = True ): super(TextTransformer, self).__init__() self.token_embedding = nn.Embedding(vocab_size, embed_dim) self.pos_embedding = nn.Parameter(torch.empty(context_length, embed_dim)) self.layernorm_final = nn.LayerNorm(embed_dim) if norm_layer else nn.Identity() self.transformer = TransformerEncoder( depth= depth, embed_dim= embed_dim, num_heads= num_heads, qkv_bias= qkv_bias, dropout_ratio= dropout_ratio, attenntion_dropout_ratio= attenntion_dropout_ratio, mlp_ratio= mlp_ratio, norm_layer= norm_layer ) self.text_projection = nn.Linear(embed_dim, embed_dim, bias=False) self._initialize_weights() def _initialize_weights(self): nn.init.normal_(self.token_embedding.weight, std=0.02) nn.init.normal_(self.pos_embedding, std=0.01) for m in self.modules(): if isinstance(m, nn.Linear): nn.init.trunc_normal_(m.weight, std=0.02) if m.bias is not None: nn.init.zeros_(m.bias) elif isinstance(m, nn.LayerNorm): # weight == 1, bias == 0 nn.init.ones_(m.weight) nn.init.zeros_(m.bias) def forward(self, x: torch.Tensor) -> torch.Tensor: # x: (B, context_length) text = x x = self.token_embedding(x) + self.pos_embedding # x : (B, context_length, text_embed_dim) x = self.transformer(x) # (B, context_length, text_embed_dim) x = self.layernorm_final(x) # 提取每个序列中EOT token的embedding,因为在CLIP中,EOT token是每个序列中ID最大的那个token x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] # x: (B, text_embed_dim) # x[torch.arange(x.shape[0]), text.argmax(dim=-1)] x = self.text_projection(x) # (B, text_embed_dim) return x class CLIP(nn.Module): def __init__(self, edmbed_dim: int, # 图文统一特征维度 # Vision Parameter vision_image_size: int, vision_patch_size: int, vision_in_channels: int, vision_embed_dim: int, vision_depth: int, # transformer encoder的层数 vision_num_heads: int, vision_qkv_bias: bool, vision_dropout_ratio: float, vision_attenntion_dropout_ratio: float, vision_mlp_ratio: float, vision_norm_layer: bool, # Text Parameter text_context_lenth: int, text_vocab_size: int, text_embed_dim: int, text_atten_heads: int, text_depth: int ,# transformer encoder的层数 text_qkv_bias: bool, text_dropout_ratio: float, text_attenntion_dropout_ratio: float, text_mlp_ratio: float, text_norm_layer: bool ): super(CLIP, self).__init__() self.vision_transformer = VisionTransformer( img_size= vision_image_size, patch_size= vision_patch_size, in_channels= vision_in_channels, embed_dim= vision_embed_dim, depth= vision_depth, num_heads= vision_num_heads, qkv_bias= vision_qkv_bias, dropout_ratio= vision_dropout_ratio, attenntion_dropout_ratio= vision_attenntion_dropout_ratio, mlp_ratio= vision_mlp_ratio, norm_layer= vision_norm_layer ) # self.text_transformer = TransformerEncoder( # depth= text_depth, # embed_dim= text_embed_dim, # num_heads= text_atten_heads, # qkv_bias= text_qkv_bias, # dropout_ratio= text_dropout_ratio, # attenntion_dropout_ratio= text_attenntion_dropout_ratio, # mlp_ratio= text_mlp_ratio, # norm_layer= text_norm_layer # ) self.text_transformer = TextTransformer( vocab_size= text_vocab_size, context_length= text_context_lenth, embed_dim=text_embed_dim, depth = text_depth, num_heads = text_atten_heads, qkv_bias = text_qkv_bias, dropout_ratio = text_dropout_ratio, attenntion_dropout_ratio = text_attenntion_dropout_ratio, mlp_ratio = text_mlp_ratio, norm_layer = text_norm_layer ) # 文本Embedding相关初始化 self.text_token_embedding = nn.Embedding(text_vocab_size, text_embed_dim) self.text_pos_embedding = nn.Parameter(torch.empty(text_context_lenth, text_embed_dim)) # 可学习的位置编码 self.text_layernorm_final = nn.LayerNorm(text_embed_dim) if text_norm_layer else nn.Identity() # 投影举证,将文本特征映射到和图像特征相同的维度 self.vision_projection = nn.Linear(vision_embed_dim, edmbed_dim, bias=False) self.text_projection = nn.Linear(text_embed_dim, edmbed_dim, bias=False) self.logit_scale = nn.Parameter(torch.ones([]) * torch.log(torch.tensor(1 / 0.07))) self._initialize_parameters() def _initialize_parameters(self): nn.init.normal_(self.text_token_embedding.weight, std=0.02) nn.init.normal_(self.text_pos_embedding, std=0.01) for m in self.modules(): if isinstance(m, nn.Linear): nn.init.trunc_normal_(m.weight, std=0.02) if m.bias is not None: nn.init.zeros_(m.bias) elif isinstance(m, nn.LayerNorm): # weight == 1, bias == 0 nn.init.ones_(m.weight) nn.init.zeros_(m.bias) def encode_image(self, img: torch.Tensor) -> torch.Tensor: # img: (B, in_channels, img_size, img_size) image_features = self.vision_transformer(img) image_features = self.vision_projection(image_features) # (B, edmbed_dim) return image_features # (B, embed_dim) def encode_text(self, text: torch.Tensor) -> torch.Tensor: # text: (B, context_length) # x = self.text_token_embedding(text) + self.text_pos_embedding # (B, context_length, text_embed_dim) # x = self.text_transformer(x) # (B, context_length, text_embed_dim) # x = self.text_layernorm_final(x) # print("Text transformer output shape:", x.shape) # # 提取每个序列中EOT token的embedding,因为在CLIP中,EOT token是每个序列中ID最大的那个token # x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] # (B, text_embed_dim) # print("EOT token embeddings shape:", x.shape) # x = self.text_projection(x) # (B, edmbed_dim) 转换成和图像一样的维度 # return x text_features = self.text_transformer(text) # (B, text_edmbed_dim) text_features = self.text_projection(text_features) # (B, edmbed_dim) return text_features def forward(self, img: torch.Tensor, text: torch.Tensor): image_features = self.encode_image(img) # (B, vision_embed_dim) text_features = self.encode_text(text) # (B, edmbed_dim) # L2归一化,防止长度对其产生影响 image_features = image_features / image_features.norm(dim=-1, keepdim=True) text_features = text_features / text_features.norm(dim=-1, keepdim=True) # cosine similarity as logits logit_scale = self.logit_scale.exp() print("Logit scale:", logit_scale.item()) # [B x edmbed_dim] @ [edmbed_dim x B] -> [B x B] logits_per_image = logit_scale * image_features @ text_features.t() logits_per_text = logits_per_image.t() return logits_per_image, logits_per_text, image_features, text_featuresif __name__ == "__main__": # Example use of CLIP.encode_image and CLIP.encode_text clip_model = CLIP( edmbed_dim=512, # Vision Parameters vision_image_size=224, vision_patch_size=16, vision_in_channels=3, vision_embed_dim=768, vision_depth=12, vision_num_heads=12, vision_qkv_bias=True, vision_dropout_ratio=0.1, vision_attenntion_dropout_ratio=0.1, vision_mlp_ratio=4.0, vision_norm_layer=True, # Text Parameters text_context_lenth=77, text_vocab_size=49408, text_embed_dim=512, text_atten_heads=8, text_depth=12, text_qkv_bias=True, text_dropout_ratio=0.1, text_attenntion_dropout_ratio=0.1, text_mlp_ratio=4.0, text_norm_layer=True ) dummy_image = torch.randn(2, 3, 224, 224) # Batch of 2 images dummy_text = torch.randint(0, 49408, (2, 77)) # Batch of 2 text sequences image_features = clip_model.encode_image(dummy_image) text_features = clip_model.encode_text(dummy_text) print("Image features shape:", image_features.shape) # Expected: (2, 512) print("Text features shape:", text_features.shape) # Expected: (2, 512) image_logits, text_logits, image_features, text_features = clip_model(dummy_image, dummy_text) print("Image logits shape:", image_logits.shape) # Expected: (2, 2) print("Text logits shape:", text_logits.shape) # Expected: (2, 2) image_similarity = torch.matmul(image_features, image_features.t()) # print("Image similarity shape:", image_similarity.shape) # Expected: (2, 2) # print("Image similarity:", image_similarity) text_similarity = torch.matmul(text_features, text_features.t()) # print("Text similarity shape:", text_similarity.shape) # Expected: (2, 2) targets = torch.nn.functional.softmax((image_similarity + text_similarity) / 2, dim=-1) print("Targets:", targets) logits = (image_logits + text_logits) / 2 # target * logits越大,说明模型预测越正确,取负号是为了最小化loss loss = -(targets * logits).sum(dim=-1).mean() print("Loss:", loss.item())
Cite
@misc{radford2021learningtransferablevisualmodels, title={Learning Transferable Visual Models From Natural Language Supervision}, author={Alec Radford and Jong Wook Kim and Chris Hallacy and Aditya Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever}, year={2021}, eprint={2103.00020}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2103.00020}, }
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

















 130
130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









