



LangChain 发布了其 1.0 版本。这不仅仅是一个版本号的跳跃,它标志着 LangChain 从一个快速迭代的实验性框架,正式迈向了一个专注、稳定、生产就绪的 Agent 构建平台。v1.0 围绕三大核心改进进行了精简和重构:全新的 create_agent、强大的中间件(Middleware)系统、以及标准化的内容块(Content Blocks)。
核心改进一:create_agent——Agent 构建新标准
create_agent 替代了旧版的 langgraph.prebuilt.create_react_agent,是 v1 中构建 Agent 的默认接口,兼具简洁性与高自定义性(核心通过 Middleware 实现)。

1. 核心特性与使用示例
•核心优势:接口更简单,支持通过 Middleware 深度自定义 Agent 流程,无需手动编写复杂循环逻辑。•基础用法:仅需指定模型、工具、系统提示即可创建 Agent,调用时通过 invoke 传入用户消息。
from langchain.agents import create_agent
# 1. 定义工具(如search_web、analyze_data)
# 2. 创建Agent
agent = create_agent(
model="anthropic:claude-sonnet-4-5", # 模型标识
tools=[search_web, analyze_data, send_email], # 关联工具
system_prompt="You are a helpful research assistant." # 系统提示
)
# 3. 调用Agent
result = agent.invoke({"messages": [{"role": "user", "content": "Research AI safety trends"}]})
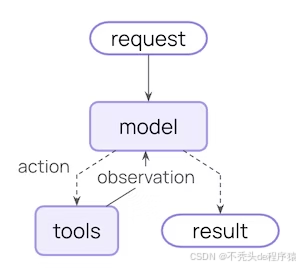
•底层逻辑:遵循「调用模型→选择工具执行→无工具调用则结束」的核心循环,流程可视化如下(官方示意图):
2. 关键扩展:Middleware(中间件)
Middleware 是 create_agent 的核心自定义入口,可控制 Agent 执行的全流程(如动态提示、隐私保护、人工介入),支持预构建中间件与自定义中间件。
(1)预构建中间件(官方提供)
覆盖常见场景,直接导入使用:
•PIIMiddleware:过滤敏感信息(如邮箱、手机号、社保号),避免泄露至模型。•SummarizationMiddleware:对话历史过长时自动浓缩,避免超出模型token限制。•HumanInTheLoopMiddleware:敏感工具调用(如发送邮件)需人工审批,降低风险。
使用示例:
from langchain.agents import create_agent
from langchain.agents.middleware import PIIMiddleware, SummarizationMiddleware, HumanInTheLoopMiddleware
agent = create_agent(
model="anthropic:claude-sonnet-4-5",
tools=[read_email, send_email],
middleware=[
PIIMiddleware(patterns=["email", "phone", "ssn"]), # 过滤敏感信息
SummarizationMiddleware(model="anthropic:claude-sonnet-4-5", max_tokens_before_summary=500), # 浓缩历史
HumanInTheLoopMiddleware(interrupt_on={"send_email": {"allowed_decisions": ["approve", "edit", "reject"]}}) # 邮件需审批
]
)
(2)自定义中间件
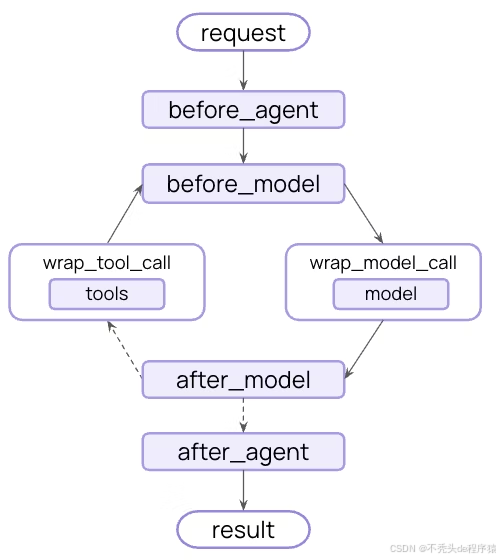
通过继承 AgentMiddleware 类,实现特定钩子函数(Hook),控制 Agent 执行的关键节点。
核心钩子函数与作用:
| 钩子函数 | 执行时机 | 典型用途 |
|---|---|---|
before_agent | Agent 启动前 | 加载内存、验证输入合法性 |
before_model | 每次调用 LLM 前 | 更新提示词、裁剪过长消息 |
wrap_model_call | 包裹 LLM 调用过程 | 拦截/修改模型请求/响应 |
wrap_tool_call | 包裹工具调用过程 | 拦截/修改工具参数或执行结果 |
after_model | 每次 LLM 响应后 | 验证输出合法性、添加安全护栏 |
after_agent | Agent 执行完成后 | 保存结果、清理临时数据 |
自定义示例:根据用户专业水平( beginner/expert )切换模型与工具:
from dataclasses import dataclass
from langchain_openai import ChatOpenAI
from langchain.agents.middleware import AgentMiddleware, ModelRequest
@dataclass
class Context: # 定义上下文(存储用户专业水平)
user_expertise: str = "beginner"
class ExpertiseBasedToolMiddleware(AgentMiddleware):
def wrap_model_call(self, request: ModelRequest, handler) -> ModelResponse:
user_level = request.runtime.context.user_expertise
# 根据用户水平切换模型与工具
if user_level == "expert":
request.model = ChatOpenAI(model="openai:gpt-5")
request.tools = [advanced_search, data_analysis]
else:
request.model = ChatOpenAI(model="openai:gpt-5-nano")
request.tools = [simple_search, basic_calculator]
return handler(request)
# 使用自定义中间件
agent = create_agent(
model="anthropic:claude-sonnet-4-5",
tools=[simple_search, advanced_search, basic_calculator, data_analysis],
middleware=[ExpertiseBasedToolMiddleware()],
context_schema=Context # 关联上下文 schema
)
3. 基于 LangGraph 的原生支持
create_agent 底层依赖 LangGraph,无需额外配置即可获得四大企业级特性:
•持久化(Persistence):对话自动跨会话保存(基于 checkpointing)。•流式传输(Streaming):实时流式返回 token、工具调用日志、推理过程。•人工介入(Human-in-the-loop):关键步骤可暂停等待人工确认。•时间旅行(Time travel):回溯对话任意节点,探索不同执行路径。
4. 结构化输出优化
v1 中结构化输出直接集成到 Agent 主循环,无需额外调用 LLM,降低成本与延迟:
•核心改进:模型可自主选择「调用工具」或「直接生成结构化输出」。•使用示例:指定 response_format 为 ToolStrategy,自动生成符合 Pydantic 模型的结果。
from langchain.agents import create_agent
from langchain.agents.structured_output import ToolStrategy
from pydantic import BaseModel
# 定义结构化输出格式
class Weather(BaseModel):
temperature: float
condition: str
# 定义工具
def weather_tool(city: str) -> str:
return f"it's sunny and 70 degrees in {city}"
# 创建Agent并指定结构化输出
agent = create_agent(
"openai:gpt-4o-mini",
tools=[weather_tool],
response_format=ToolStrategy(Weather)
)
# 调用后获取结构化结果
result = agent.invoke({"messages": [{"role": "user", "content": "What's the weather in SF?"}]})
print(result["structured_response"]) # 输出:Weather(temperature=70.0, condition='sunny')
•错误处理:通过 ToolStrategy 的 handle_errors 参数,处理「解析失败」「多工具调用冲突」等问题。
核心改进二:Standard Content Blocks(标准化内容块)
content_blocks 是 BaseMessage 类的新属性,为不同 LLM 提供商的输出(如推理过程、工具调用、引用)提供统一的访问接口,解决跨平台格式不兼容问题。
1. 核心作用与使用示例
•统一格式:无论使用 Anthropic、OpenAI 还是 Google GenAI,均可通过 content_blocks 读取「推理过程」「文本响应」「工具调用」三类核心内容。•基础用法:
from langchain_anthropic import ChatAnthropic
# 调用模型
model = ChatAnthropic(model="claude-sonnet-4-5")
response = model.invoke("What's the capital of France?")
# 遍历 content_blocks 解析输出
for block in response.content_blocks:
if block["type"] == "reasoning": # 模型推理过程(部分模型支持)
print(f"Model reasoning: {block['reasoning']}")
elif block["type"] == "text": # 文本响应
print(f"Response: {block['text']}")
elif block["type"] == "tool_call":# 工具调用指令
print(f"Tool call: {block['name']}({block['args']})")
2. 支持的集成与优势
(1)当前支持的 LLM 集成
仅以下官方集成支持 content_blocks,后续将逐步扩展:
•langchain-anthropic(Anthropic Claude)•langchain-aws(AWS Bedrock)•langchain-openai(OpenAI GPT 系列)•langchain-google-genai(Google Gemini)•langchain-ollama(Ollama 本地模型)
(2)核心优势
•Provider 无关:一套代码适配多平台,无需为不同模型编写差异化解析逻辑。•类型安全:所有内容块类型均提供完整 Type Hint,降低开发错误。•向后兼容:内容块采用「延迟加载」机制,不影响旧版代码运行。
核心改进三:简化命名空间(Simplified Namespace)
v1 对 langchain 包进行瘦身,仅保留 Agent 构建的核心模块,将 legacy 功能迁移至独立包 langchain-classic,降低学习与使用成本。
1. langchain 核心模块(v1 保留)
langchain 包仅聚焦 Agent 构建所需的关键功能,部分模块从 langchain-core 重新导出(方便调用):
| 模块路径 | 包含内容 | 用途说明 |
|---|---|---|
langchain.agents | create_agent 、AgentState | 核心 Agent 创建与状态管理 |
langchain.messages | 消息类型(AIMessage/HumanMessage)、content_blocks、trim_messages | 消息处理与标准化内容块 |
langchain.tools | @tool 装饰器、BaseTool、工具注入助手 | 工具定义与集成 |
langchain.chat_models | init_chat_model 、BaseChatModel | 统一 LLM 初始化接口 |
langchain.embeddings | Embeddings 、init_embeddings | 嵌入模型定义与初始化 |
使用示例:v1 中导入核心功能的简化写法
# Agent 构建
from langchain.agents import create_agent
# 消息处理
from langchain.messages import AIMessage, HumanMessage
# 工具定义
from langchain.tools import tool
# 模型初始化
from langchain.chat_models import init_chat_model
from langchain.embeddings import init_embeddings
2. langchain-classic——Legacy 功能迁移包
v1 将非 Agent 核心的 legacy 功能拆分至 langchain-classic,保持主包精简。
(1)langchain-classic 包含的内容
•旧版 Chains 及其实现(如 LLMChain)•检索器(Retrievers):如 MultiQueryRetriever、旧 langchain.retrievers 模块内容•索引 API(Indexing API)•Hub 模块(用于程序化管理提示词)•langchain-community 包的导出内容•其他已废弃(Deprecated)的功能
(2)安装与迁移
•安装命令:
# 使用 pip 安装
pip install langchain-classic
# 使用 uv 安装(更快)
uv add langchain-classic
•导入修改:将旧代码中 from langchain import ... 改为 from langchain_classic import ...
# 旧版导入(v1 中失效)
from langchain.chains import LLMChain # [!code --]
from langchain.retrievers import MultiQueryRetriever # [!code --]
# 新版导入(v1 中使用 langchain-classic)
from langchain_classic.chains import LLMChain # [!code ++]
from langchain_classic.retrievers import MultiQueryRetriever # [!code ++]
升级与迁移指南
1.升级 LangChain 到 v1:
# 使用 pip 升级
pip install -U langchain
# 使用 uv 升级
uv add langchain
2.迁移参考:官方提供详细迁移文档,包含 API 变更、代码修改示例,可访问 Migration Guide[1]。3.问题反馈:若发现 v1 bugs,可在 GitHub 提交 Issue 并添加 v1 标签(提交链接[2])。
总结
LangChain v1.0 是一个里程碑式的版本。它通过剥离遗留功能、聚焦于 Agent 核心、并引入强大的中间件系统,为开发者提供了一个更稳定、更灵活、真正“生产就绪”的平台。如果您正在构建或计划构建复杂的 AI 代理,现在是深入研究 LangChain v1.0 的最佳时机。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

















 901
901



 到【灌水乐园】发言
到【灌水乐园】发言








