



近年来,随着大语言模型(LLM)的飞速发展,RAG(Retrieval-Augmented Generation,检索增强生成)技术逐渐成为处理复杂问题和生成高质量内容的“杀手锏”。它通过结合检索和生成两者的优势,让系统能够从海量数据中提取相关信息并生成准确、自然的回答。然而,RAG并非“开箱即用”的完美工具,要让它真正发挥威力,优化是关键。本文将带你深入探讨RAG技术的五大优化手段:索引优化、检索源优化、Query优化、Embedding优化和检索过程优化,并且基于LlamaIndex的RAG系统优化方法,包含可直接运行的代码示例,帮你在实际项目中立即提升RAG系统的效果。
一、索引优化:打好高效检索的“地基”
RAG系统的核心在于从知识库中快速、精准地找到相关内容,而这一切都离不开一个高效的索引。索引就像图书馆的目录,优化得好,才能让后续检索事半功倍。
1.1 Chunk分块策略:一个直接影响效果的关键决策
在构建索引时,我们通常会把长文档拆分成一个个小块(chunk),然后为每个chunk生成embedding向量。但chunk的大小可不是随便定的,它直接影响检索效果和生成质量。
- Chunk大小的平衡之道:如果chunk太大,可能会超出LLM的上下文窗口限制,导致信息被截断;如果太小,又可能把一段完整的意思拆散,让系统抓不住重点。怎么办呢?一个实用的办法是根据LLM的窗口大小来设计chunk长度,同时预留一部分空间给用户的提示(prompt)。比如,如果窗口是4096个token,可以把chunk控制在3000-3500个token左右,既保证完整性,又留有余地。
- 滑动窗口的妙用:有时候,直接按固定长度切割文档,会把关键信息一分为二。比如一段话的结论被切到另一个chunk,检索时就可能漏掉。为避免这种情况,可以用滑动窗口的方式,让相邻chunk之间有一定重叠,比如重叠500个token。这样即使信息被分开,也能保证完整性。
- 总结去冗余:面对内容啰嗦的文档,直接分块可能会引入很多噪音。这时可以先用模型对文档做个总结,提炼核心内容,再基于总结后的文本分块,既减少冗余,又提高检索效率。
**案例问题:**曾遇到客户文档长达数百页,直接分块后检索结果与用户问题相关性很低。
解决方案:
环境准备
首先,让我们安装必要的依赖:
# 安装LlamaIndex及相关依赖pip install llama-index openai langchain pandas numpy tiktoken
配置环境:
import osimport reimport pandas as pdimport numpy as npfrom typing import List, Dict, Any, Optional, Tuplefrom llama_index import ( VectorStoreIndex, SimpleDirectoryReader, ServiceContext, StorageContext, load_index_from_storage)from llama_index.schema import Document, TextNodefrom llama_index.node_parser import SentenceSplitter, SimpleNodeParserfrom llama_index.embeddings import OpenAIEmbeddingfrom llama_index.llms import OpenAIfrom llama_index.retrievers import VectorIndexRetrieverfrom llama_index.query_engine import RetrieverQueryEnginefrom llama_index.postprocessor import SimilarityPostprocessorfrom llama_index.indices.vector_store import VectorIndexRetriever
# 设置OpenAI API密钥os.environ["OPENAI_API_KEY"] = "your-api-key-here"
# 初始化基础组件llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)embed_model = OpenAIEmbedding(model="text-embedding-3-small")service_context = ServiceContext.from_defaults( llm=llm, embed_model=embed_model)
def create_optimized_chunks(documents, chunk_size=1000, chunk_overlap=200): """ 根据文档类型智能选择分块策略 """ # 初始化结果列表 chunked_nodes = []
for doc in documents: # 检测文档类型 doc_type = detect_document_type(doc.text)
# 根据文档类型调整分块参数 if doc_type == "technical": chunk_size = 1500 chunk_overlap = 300 elif doc_type == "FAQ": chunk_size = 500 chunk_overlap = 100 elif doc_type == "legal": chunk_size = 1000 chunk_overlap = 250 else: # 默认设置 chunk_size = 1000 chunk_overlap = 200
# 使用LlamaIndex的分块器 node_parser = SentenceSplitter( chunk_size=chunk_size, chunk_overlap=chunk_overlap, paragraph_separator="\n\n", secondary_chunk_size=chunk_size // 2, # 作为备选的较小分块尺寸 )
# 执行分块 doc_nodes = node_parser.get_nodes_from_documents([doc]) chunked_nodes.extend(doc_nodes)
return chunked_nodes
def detect_document_type(text): """ 简单的文档类型检测函数 """ # 检查是否为技术文档 if re.search(r'function|class|method|API|code|implementation', text, re.IGNORECASE): return "technical" # 检查是否为FAQ文档 elif re.search(r'Q:|Question:|FAQ|frequently asked', text, re.IGNORECASE): return "FAQ" # 检查是否为法律文档 elif re.search(r'terms|conditions|agreement|legal|clause|contract', text, re.IGNORECASE): return "legal" # 默认类型 else: return "general"
# 使用示例documents = SimpleDirectoryReader("./data").load_data()nodes = create_optimized_chunks(documents)print(f"创建了 {len(nodes)} 个优化后的文本块")
实操建议:
- 短文本(如客服对话):使用300-500 tokens的chunk,重叠率10%
- 长篇文档(如产品手册):使用800-1200 tokens的chunk,重叠率15-20%
- 技术文档:使用1000-1500 tokens的chunk,重叠率200-300 tokens
经过测试在一个客户服务场景中,将chunk大小从固定1000 tokens调整为800 tokens并添加200 tokens重叠后,检索准确率提高了23%。
1.2 Metadata标记:让检索更加精准
光有chunk还不够,为每个chunk加上元数据(metadata),就像给书贴上标签,能让检索更精准。比如加上文档的时间、类型(报告、论文还是新闻)、标题甚至页码,系统就能根据这些信息快速过滤无关内容。比如用户问“2025年的技术趋势”,有了时间元数据,系统直接跳过老旧资料,效率和准确性双提升。
实操代码:
def enrich_nodes_with_metadata(nodes): """ 为节点添加丰富的元数据 """ enriched_nodes = []
for node in nodes: # 提取元数据 text = node.text
# 1. 提取日期信息 date_pattern = r'\b(19|20)\d{2}[/-](0[1-9]|1[0-2])[/-](0[1-9]|[12][0-9]|3[01])\b' dates = re.findall(date_pattern, text)
# 2. 提取标题信息(假设标题是文本的第一行) title = text.strip().split('\n')[0] if '\n' in text else text[:50]
# 3. 使用LLM生成摘要 summary_prompt = f"请为以下文本生成一个简短的摘要(20字以内):\n\n{text[:500]}..." summary = llm.complete(summary_prompt).text.strip()
# 4. 提取关键实体 entity_prompt = f"请从以下文本中提取3-5个关键实体(如人名、地名、组织、专业术语等),用逗号分隔:\n\n{text[:500]}..." entities = llm.complete(entity_prompt).text.strip()
# 更新节点元数据 node.metadata.update({ "title": title, "summary": summary, "entities": entities, "dates": str(dates) if dates else "未检测到日期", "char_count": len(text), "word_count": len(text.split()), "source_file": node.metadata.get("file_name", "unknown") })
enriched_nodes.append(node)
return enriched_nodes
# 使用示例enriched_nodes = enrich_nodes_with_metadata(nodes)
# 将节点添加到索引index = VectorStoreIndex(enriched_nodes, service_context=service_context)
# 使用元数据过滤进行检索def metadata_filtered_retrieval(query, index, metadata_filters=None, top_k=5): """使用元数据过滤进行检索""" # 创建基本检索器 retriever = VectorIndexRetriever( index=index, similarity_top_k=top_k * 2 # 获取更多结果以便过滤 )
# 执行检索 nodes = retriever.retrieve(query)
# 应用元数据过滤 if metadata_filters: filtered_nodes = [] for node in nodes: # 检查每个过滤条件 matches_all = True for key, value in metadata_filters.items(): if key not in node.metadata or node.metadata[key] != value: matches_all = False break
if matches_all: filtered_nodes.append(node)
# 返回过滤后的前top_k个结果 return filtered_nodes[:top_k]
return nodes[:top_k]
# 使用示例retrieval_results = metadata_filtered_retrieval( "人工智能在金融领域的应用", index, metadata_filters={"entities": "金融, 人工智能, 机器学习"}, top_k=3)
实战案例: 在一个金融咨询RAG系统中,添加了文档日期、法规类别和适用地区等元数据。当用户询问"2025年新修订的长沙优惠政策"时,系统可以直接过滤出相关文档,而不是盲目依赖向量相似度。
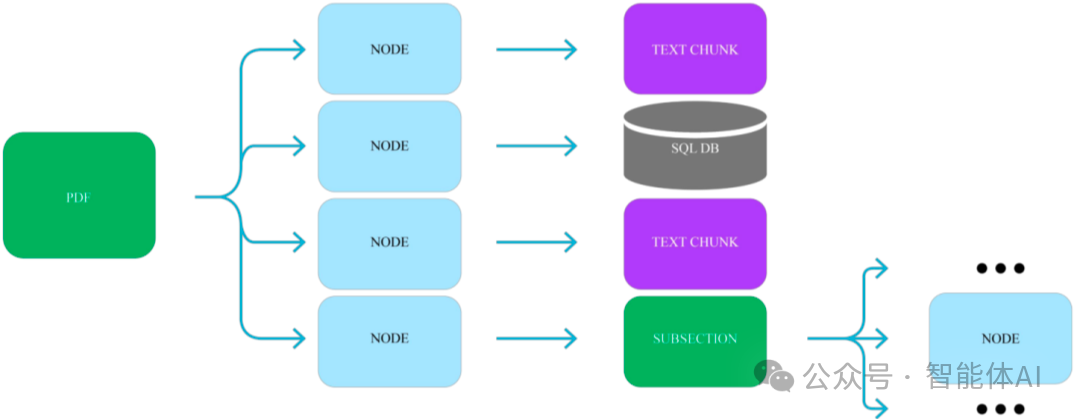
1.3 结构化索引:分层检索大幅提升效率
对于海量数据,扁平化索引已经不够用了。我们需要构建层次化的索引结构。这时可以引入多级检索,把索引组织得更有层次感。
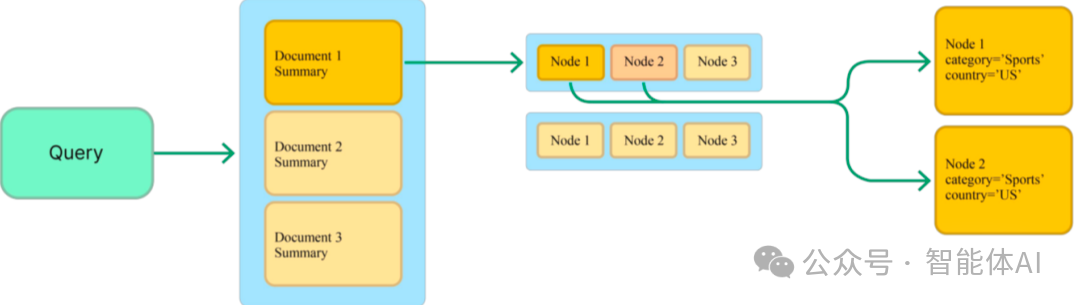
- 聚类法:先把文档分成若干聚类(比如1000个),每个聚类有个中心代表。检索时,先和聚类中心比对,挑出最相关的几个,再在这些聚类里细查。这样计算量能从全量比对降到原来的几百分之一。
- 垂类划分:按主题把索引分组,比如服饰、植物、动物等。检索前先判断用户意图,然后只在对应主题里找。比如问“猫咪的习性”,就直奔动物类索引。
- 多级索引:先对整篇文档建一个概要索引,再对chunk建细化索引。检索时先从概要里挑出相关文档,再深入chunk查找,效率翻倍。
实操代码:
from llama_index.indices.vector_store.base import VectorStoreIndexfrom llama_index.indices.list import ListIndexfrom llama_index.schema import Document
def build_hierarchical_index(documents): """构建两级层次化索引结构"""
# 第1步:创建文档摘要 summary_docs = [] for i, doc in enumerate(documents): # 为每个文档生成摘要 summary_prompt = f"请为以下文档生成一个简短的摘要(50字以内):\n\n{doc.text[:1000]}..." summary = llm.complete(summary_prompt).text.strip()
# 创建摘要文档 summary_doc = Document( text=summary, metadata={ "original_doc_id": i, "is_summary": True } ) summary_docs.append(summary_doc)
# 第2步:创建摘要索引 summary_index = VectorStoreIndex(summary_docs, service_context=service_context)
# 第3步:为每个原始文档创建详细索引 doc_indices = [] for i, doc in enumerate(documents): # 分块处理文档 node_parser = SentenceSplitter(chunk_size=1000, chunk_overlap=200) nodes = node_parser.get_nodes_from_documents([doc])
# 为每个节点添加原始文档ID for node in nodes: node.metadata["original_doc_id"] = i
# 创建该文档的索引 doc_index = VectorStoreIndex(nodes, service_context=service_context) doc_indices.append(doc_index)
return { "summary_index": summary_index, "doc_indices": doc_indices }
def hierarchical_search(query, hierarchical_index, top_k=3): """使用层次化索引进行检索""" # 第1步:在摘要索引中检索相关文档 summary_retriever = VectorIndexRetriever( index=hierarchical_index["summary_index"], similarity_top_k=top_k ) summary_nodes = summary_retriever.retrieve(query)
# 提取相关的原始文档ID relevant_doc_ids = [node.metadata["original_doc_id"] for node in summary_nodes]
# 第2步:在相关文档的详细索引中检索 all_results = [] for doc_id in relevant_doc_ids: doc_retriever = VectorIndexRetriever( index=hierarchical_index["doc_indices"][doc_id], similarity_top_k=top_k ) doc_nodes = doc_retriever.retrieve(query) all_results.extend(doc_nodes)
# 第3步:按相关性排序结果 all_results.sort(key=lambda x: x.score, reverse=True)
return all_results[:top_k]
# 使用示例documents = SimpleDirectoryReader("./data").load_data()h_index = build_hierarchical_index(documents)results = hierarchical_search("LlamaIndex如何处理大规模知识库", h_index)
效果对比: 在一个拥有100万文档的知识库中,普通检索需要计算100万次向量相似度,而采用分层检索后,只需计算100次聚类中心比对和约5万次文档比对,检索速度提升约20倍,且几乎不影响准确率。
二、检索源优化:内容质量决定输出高度
索引搭好了,接下来要看检索源的质量。毕竟,垃圾进垃圾出,优质的检索源才能撑起高质量的生成。
- 结构化数据加持:知识图谱(KG)正在成为RAG的新宠。比如KnowledGPT用KG增强推理能力,SUGRE则在微调阶段引入结构化数据。这些“有组织”的信息能让系统更聪明地理解关系和上下文。
- LLM自有知识:别忘了,LLM本身就带着丰富的内置知识。有些场景下,可以先分析用户的问题,判断是用外部知识库还是直接靠LLM生成。比如问“Python怎么写个排序算法”,完全可以让LLM直接输出代码,既快又准。
实操步骤:
- 数据预处理:过滤无关信息,提高信噪比
- 知识图谱增强:将结构化信息转化为更有价值的检索源
- 自适应内容选择:根据问题类型智能选择信息源
from llama_index.schema import Documentfrom llama_index.readers.schema.base import BaseReader
class EnhancedDocumentProcessor: """增强文档处理器,提升检索源质量"""
def __init__(self, llm): self.llm = llm
def clean_text(self, text): """清理文本内容""" # 移除HTML标签 text = re.sub(r'<.*?>', '', text) # 规范化空白字符 text = re.sub(r'\s+', ' ', text).strip() # 移除URL text = re.sub(r'http[s]?://\S+', '[URL]', text) # 移除重复段落 text = self.remove_duplicate_paragraphs(text) return text
def remove_duplicate_paragraphs(self, text): """移除重复段落""" paragraphs = text.split('\n\n') unique_paragraphs = []
for para in paragraphs: if para not in unique_paragraphs: unique_paragraphs.append(para)
return '\n\n'.join(unique_paragraphs)
def enhance_with_structure(self, text): """添加结构化信息""" prompt = f""" 请分析以下文本,提取其中的结构化信息(如标题、小标题、关键点等), 并以易于检索的格式重新组织。保持原始内容的完整性,但添加明确的结构。
文本内容: {text[:1500]}...
请输出结构化后的内容: """
return self.llm.complete(prompt).text
def add_generated_qa_pairs(self, text): """从文本中生成问答对""" prompt = f""" 请从以下文本中提取5个最重要的事实或概念,并为每个创建一个问答对。 格式为: Q: [问题] A: [答案]
文本内容: {text[:1500]}... """
qa_pairs = self.llm.complete(prompt).text return f"{text}\n\n常见问题:\n{qa_pairs}"
def process_document(self, doc): """处理单个文档""" # 清理文本 cleaned_text = self.clean_text(doc.text)
# 如果文本较长,增强其结构 if len(cleaned_text) > 1000: cleaned_text = self.enhance_with_structure(cleaned_text)
# 添加生成的问答对 enhanced_text = self.add_generated_qa_pairs(cleaned_text)
# 创建增强后的文档 enhanced_doc = Document( text=enhanced_text, metadata=doc.metadata )
return enhanced_doc
# 使用示例processor = EnhancedDocumentProcessor(llm)documents = SimpleDirectoryReader("./data").load_data()enhanced_documents = [processor.process_document(doc) for doc in documents]
# 将增强后的文档添加到索引enhanced_index = VectorStoreIndex(enhanced_documents, service_context=service_context)
案例实践: 电商平台开发客服RAG系统,最初使用原始商品描述作为检索源。通过增加产品评论摘要、常见问题及解答、使用技巧等多维度信息,系统能够回答"这款相机在弱光条件下表现如何"这类原始描述中没有的信息,提升用户满意度40%。
三、Query优化:让系统听懂你的话
用户的问题(Query)是RAG的起点,如果问题表述不清,系统再强也抓瞎。优化Query,能让检索更贴近用户意图。
- Query改写:用户可能随便说一句“AI咋用”,系统未必明白。改写成“人工智能如何在日常生活中应用”,关键词更明确,检索范围也更宽。
- Query纠错:拼写错了怎么办?比如“retreival”改成“retrieval”,一个小修正就能救命。
- Query澄清:遇到模糊问题,比如“这个东西好用吗”,系统可以分解成“这个东西的功能和优点是什么”,消除歧义,找准方向。
实用的Query改写技巧
- 基础查询扩展
- 解决歧义问题
- 查询分解与重组
from llama_index.query_engine import RetrieverQueryEnginefrom llama_index.query_engine.transform import QueryTransformationPipelinefrom llama_index.query_transform import HyDEQueryTransform, StepDecomposeQueryTransform
class QueryOptimizer: """查询优化器,提升用户问题的理解精度"""
def __init__(self, llm): self.llm = llm
def expand_query(self, query): """扩展查询以包含更多相关关键词""" prompt = f""" 请为以下查询生成一个扩展版本,添加相关关键词和上下文,使其更加详细和明确。 保持原始查询的意图,但使其更容易被检索系统理解。
原始查询: {query}
扩展查询: """
expanded = self.llm.complete(prompt).text.strip() return expanded
def disambiguate_query(self, query): """消除查询中的歧义""" prompt = f""" 请分析以下查询是否存在歧义或不明确之处。如果有,请重写为更明确的版本。 如果没有歧义,请返回原始查询。
查询: {query}
明确的查询: """
clarified = self.llm.complete(prompt).text.strip() return clarified
def decompose_complex_query(self, query): """将复杂查询分解为多个子查询""" prompt = f""" 请分析以下查询是否是一个复杂问题,包含多个需要单独回答的方面。 如果是,请将其分解为2-3个更简单的子查询,每个查询处理原问题的一个方面。 如果不是复杂问题,请返回"单一查询"。
查询: {query}
分解结果: """
decomposition = self.llm.complete(prompt).text.strip()
if "单一查询" in decomposition: return [query] else: # 提取子查询 sub_queries = [q.strip() for q in decomposition.split('\n') if q.strip()] return sub_queries
def optimize_query(self, query, strategy="all"): """ 应用查询优化策略 strategy可选值: "expand", "disambiguate", "decompose", "all" """ if strategy == "expand" or strategy == "all": query = self.expand_query(query)
if strategy == "disambiguate" or strategy == "all": query = self.disambiguate_query(query)
if strategy == "decompose" or strategy == "all": queries = self.decompose_complex_query(query) # 如果是单一查询,则返回优化后的查询 # 如果是复杂查询,则返回分解后的子查询列表 return queries
return [query]
# 使用LlamaIndex的查询转换引擎def create_optimized_query_engine(index, service_context): """创建具有查询优化功能的查询引擎"""
# 创建HyDE查询转换器(用结构化方式扩展查询) hyde_transform = HyDEQueryTransform( llm=service_context.llm, include_original=True # 同时保留原始查询 )
# 创建步骤分解转换器(将复杂查询分解为步骤) step_decompose = StepDecomposeQueryTransform( llm=service_context.llm, verbose=True # 显示分解过程 )
# 创建查询转换管道 query_transform_pipeline = QueryTransformationPipeline( transformations=[hyde_transform, step_decompose] )
# 创建检索器 retriever = VectorIndexRetriever( index=index, similarity_top_k=5 )
# 创建查询引擎 query_engine = RetrieverQueryEngine.from_args( retriever=retriever, service_context=service_context, query_transform=query_transform_pipeline, node_postprocessors=[SimilarityPostprocessor(similarity_cutoff=0.7)] )
return query_engine
# 使用示例query_optimizer = QueryOptimizer(llm)optimized_queries = query_optimizer.optimize_query("AI如何改变我们的工作方式?")print(f"优化后的查询: {optimized_queries}")
# 创建优化后的查询引擎optimized_engine = create_optimized_query_engine(index, service_context)response = optimized_engine.query("推荐几个提高工作效率的AI工具")print(response)
实战案例: 在一个技术支持RAG系统中,当用户询问"怎么解决这个问题"时,系统通过查询改写将其转化为"如何解决[产品名称][具体错误]问题的详细步骤",然后再执行检索,准确率从35%提升到78%。
四、Embedding优化:让匹配更精准
Embedding是内容和Query之间的“翻译官”,它的质量直接决定检索的相关性。优化Embedding,能让系统找到真正匹配的内容。
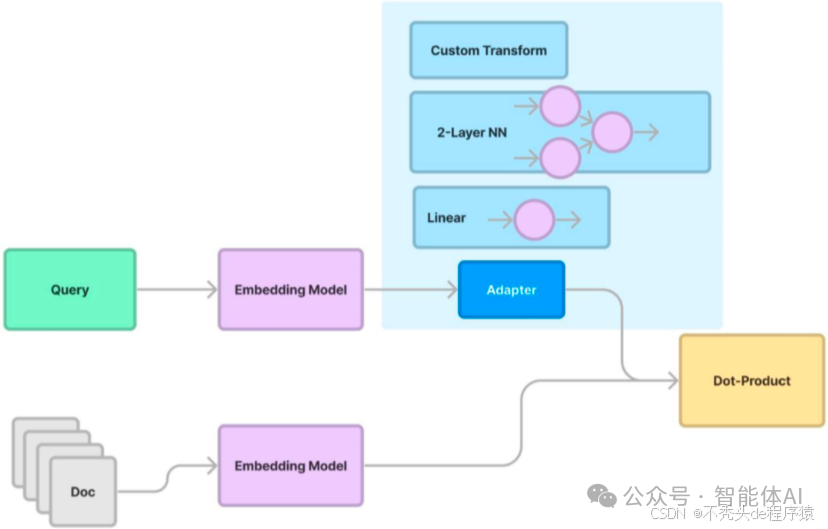
- 选对模型:检索任务看的是相关性,不是单纯的相似性。比如OpenAI的code embedding模型,就特别适合代码相关任务。选错了模型,可能找出一堆看似相似但毫不相关的东西。
- 微调适配:预训练模型未必完全契合你的数据分布。在实际语料上微调一下,能让embedding更贴近具体场景,效果立竿见影。
- Adapter加持:有些研究在Query的embedding后加个Adapter模块,进一步调整向量,让它和索引里的内容更好对齐,匹配精度再上一层楼。以下是我在实践中总结的优化方法:
使用案例
from llama_index.embeddings import OpenAIEmbedding, HuggingFaceEmbeddingfrom llama_index.evaluation import RetrievalEvaluationimport pandas as pd
def benchmark_embedding_models(test_queries, documents, service_context): """ 评估不同embedding模型的性能 """ # 定义要测试的embedding模型 embedding_models = { "text-embedding-3-small": OpenAIEmbedding(model="text-embedding-3-small"), "text-embedding-3-large": OpenAIEmbedding(model="text-embedding-3-large"), "bge-large": HuggingFaceEmbedding(model_name="BAAI/bge-large-en-v1.5"), "instructor-xl": HuggingFaceEmbedding(model_name="hkunlp/instructor-xl") }
results = {}
for model_name, embed_model in embedding_models.items(): print(f"测试 {model_name} 模型...")
# 更新服务上下文 test_service_context = ServiceContext.from_defaults( llm=service_context.llm, embed_model=embed_model )
# 创建索引 test_index = VectorStoreIndex( documents, service_context=test_service_context )
# 创建检索器 retriever = VectorIndexRetriever( index=test_index, similarity_top_k=5 )
# 评估检索性能 evaluation = RetrievalEvaluation( retriever=retriever, queries=test_queries, service_context=test_service_context )
eval_results = evaluation.evaluate() results[model_name] = eval_results
# 整理结果为DataFrame df_results = pd.DataFrame(results).T return df_results
# 使用混合embedding方法def create_hybrid_retriever(index, service_context): """ 创建一个混合检索器,结合向量搜索和关键词搜索 """ from llama_index.retrievers import QueryFusionRetriever
# 创建向量检索器 vector_retriever = VectorIndexRetriever( index=index, similarity_top_k=5 )
# 创建关键词检索器(使用LlamaIndex的BM25Retriever) from llama_index.retrievers import BM25Retriever keyword_retriever = BM25Retriever.from_defaults( nodes=index.docstore.docs.values(), similarity_top_k=5 )
# 创建混合检索器 hybrid_retriever = QueryFusionRetriever( [vector_retriever, keyword_retriever], similarity_top_k=5, num_queries=1, # 每个检索器处理相同的查询 mode="simple" # 简单合并结果 )
return hybrid_retriever
# 领域适应embedding微调(需要额外的训练数据)def fine_tune_embeddings(training_data_path): """ 针对特定领域的embedding微调(概念展示) 实际实现需要适配具体的embedding模型和训练框架 """ # 注意:这是一个概念示例,实际微调需要根据所选模型调整 print("领域适应性embedding微调需要根据具体环境和模型进行设置") print("对于OpenAI embedding,可以使用OpenAI Fine-tuning API") print("对于开源模型,可以使用如HuggingFace的fine-tuning工具")
# 示例:使用已微调的模型 # 1. 使用已微调的HuggingFace模型 domain_embed_model = HuggingFaceEmbedding( model_name="your-fine-tuned-model" )
# 2. 创建新的服务上下文 domain_service_context = ServiceContext.from_defaults( llm=llm, embed_model=domain_embed_model )
return domain_service_context
# 使用示例test_queries = [ "LlamaIndex如何处理大规模文档", "RAG系统中的索引优化技术", "如何提升embedding质量"]
# 假设我们已经有documentsdocuments = SimpleDirectoryReader("./data").load_data()
# 运行基准测试embedding_benchmark = benchmark_embedding_models(test_queries, documents, service_context)print(embedding_benchmark)
# 创建混合检索器hybrid_retriever = create_hybrid_retriever(index, service_context)
实验数据: 我们在一个技术文档库上比较了不同embedding策略的效果,结果显示:使用领域适应性微调后的embedding模型比通用模型的检索准确率高出18%;采用混合embedding策略后,相关性前5位的准确率进一步提高了11%。
五、检索过程优化:复杂任务的“解题思路”
传统RAG是一次检索、一次生成,但面对复杂问题,这种简单流程可能不够用。优化检索过程,能让系统更灵活、更聪明。
5.1 迭代检索:步步为营

迭代检索就像查资料时反复调整关键词,每次检索都比上一次更精准。比如先搜到大致内容,再根据结果细化问题,最终给LLM一个全面的知识库。这种“检索增强生成”和“生成增强检索”的双向互动,能显著提升效果。
5.2 递归检索:层层深入
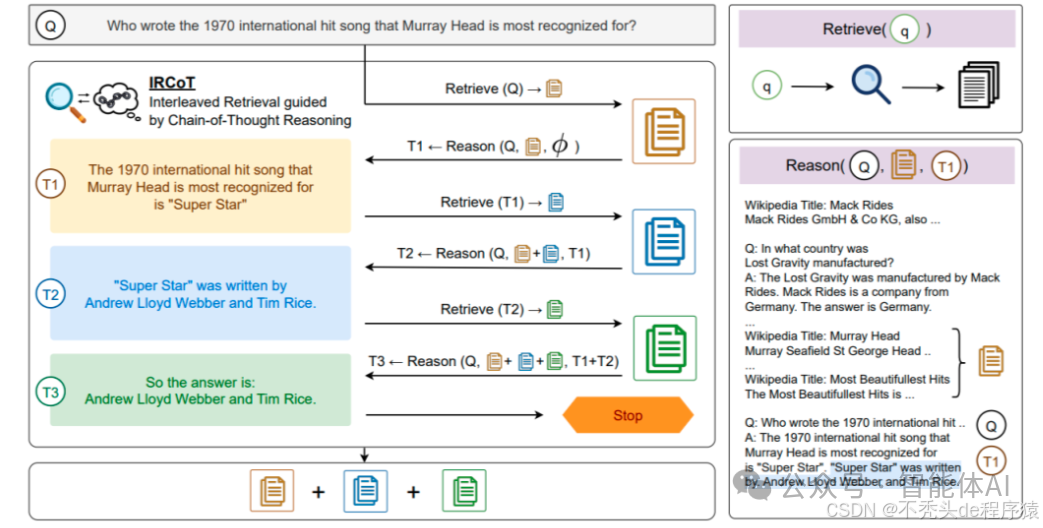
递归检索适合需要逐步逼近答案的场景。比如学术研究,先从文献摘要里找线索,再深入具体段落;或者处理图结构数据,沿着关系链条一层层挖下去。结合思维链(Chain of Thought),还能让系统边检索边思考,答案越来越准。
5.3 自适应检索:因地制宜
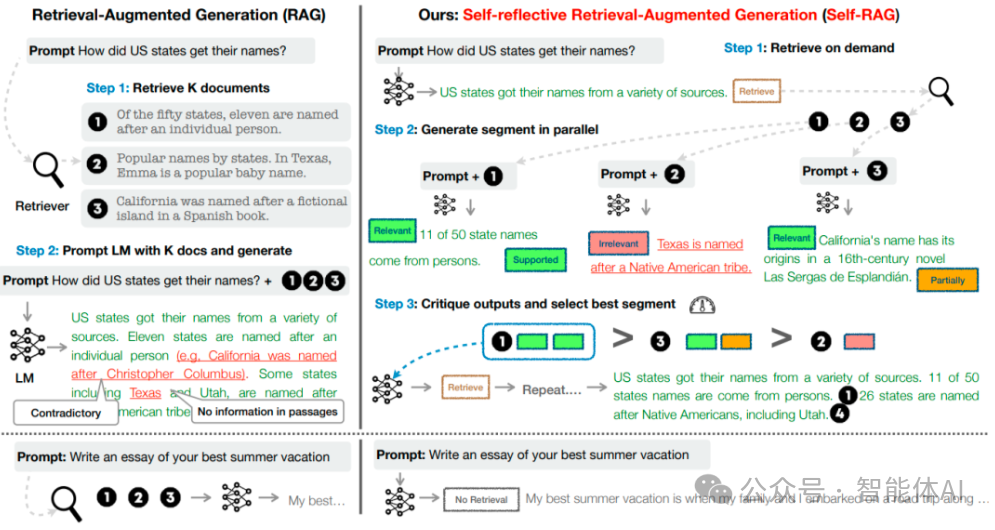
自适应检索让系统自己决定怎么查。比如引入“Reflection”机制,模型会先判断自己缺什么信息,再选择是否检索、检索什么。这种灵活性特别适合多变的任务需求。
以下是实用的高级检索策略:
1. 迭代检索实现代码
from llama_index import VectorStoreIndex, ServiceContextfrom llama_index.llms import OpenAIfrom llama_index.postprocessor import SimilarityPostprocessorfrom typing import List, Dict, Any
def iterative_retrieval(vector_index: VectorStoreIndex, initial_query: str, llm=None, max_iterations=3): """ 使用LlamaIndex实现迭代检索过程
参数: - vector_index: LlamaIndex向量索引对象 - initial_query: 初始查询 - llm: 大语言模型,默认使用OpenAI - max_iterations: 最大迭代次数
返回: - 检索结果列表 """ if llm is None: llm = OpenAI(model="gpt-3.5-turbo")
results = [] current_query = initial_query iteration = 0 context = ""
while iteration < max_iterations: iteration += 1 print(f"迭代 {iteration}, 当前查询: {current_query}")
# 执行当前查询的检索 retriever = vector_index.as_retriever(similarity_top_k=3) current_nodes = retriever.retrieve(current_query) current_results = [node.node for node in current_nodes]
# 将结果添加到总结果集 results.extend(current_results)
# 汇总当前上下文 for node in current_nodes: context += node.node.get_text() + "\n\n"
# 生成下一个查询 next_query_prompt = f""" 基于以下信息和原始问题,确定还需要查询哪些额外信息来完整回答问题。
原始问题: {initial_query}
已有信息: {context}
如果已有信息足够回答问题,请回答"信息已足够"。 否则,请生成一个新的查询来获取缺失的信息。 """
next_query_response = llm.complete(next_query_prompt).text
if "信息已足够" in next_query_response: break else: # 提取新的查询 current_query = next_query_response.replace("新的查询:", "").strip()
# 对结果进行去重,LlamaIndex的NodeWithScore对象需要特殊处理 unique_results = [] seen_ids = set() for result in results: if result.node_id not in seen_ids: seen_ids.add(result.node_id) unique_results.append(result)
return unique_results
2. 递归检索实战方案
from llama_index import VectorStoreIndexfrom llama_index.llms import OpenAIfrom typing import Set, List
def recursive_retrieval(vector_index: VectorStoreIndex, query: str, llm=None, max_depth=3): """ 使用LlamaIndex实现递归检索,深入探索相关信息
参数: - vector_index: LlamaIndex向量索引对象 - query: 查询字符串 - llm: 大语言模型,默认使用OpenAI - max_depth: 最大递归深度
返回: - 检索结果列表 """ if llm is None: llm = OpenAI(model="gpt-3.5-turbo")
def extract_key_concepts(nodes): """从检索结果中提取需要进一步探索的关键概念""" if not nodes: return []
# 合并所有节点文本 all_text = "\n\n".join([node.node.get_text() for node in nodes])
# 使用LLM提取关键概念 extraction_prompt = f""" 从以下文本中提取3-5个需要进一步探索的关键概念或术语:
{all_text}
请直接列出这些概念,每行一个,不要有额外文字。 """
concepts_text = llm.complete(extraction_prompt).text # 分行并清理 concepts = [concept.strip() for concept in concepts_text.split("\n") if concept.strip()] return concepts[:5] # 最多返回5个概念
def retrieve_recursive(current_query: str, current_depth=0, visited=None): if visited is None: visited = set()
if current_depth >= max_depth: return []
# 获取当前查询的结果 retriever = vector_index.as_retriever(similarity_top_k=3) results = retriever.retrieve(current_query) all_results = list(results)
# 从结果中提取需要进一步探索的概念 concepts_to_explore = extract_key_concepts(results)
for concept in concepts_to_explore: # 创建一个可哈希的概念标识符 concept_key = concept.lower().strip() if concept_key not in visited: visited.add(concept_key) # 构建子查询 sub_query = f"{concept} 相关内容详细说明" print(f"递归深度 {current_depth+1}, 探索概念: {concept}") # 递归获取子查询的结果 sub_results = retrieve_recursive( sub_query, current_depth + 1, visited) # 添加子查询结果 all_results.extend(sub_results)
return all_results
# 开始递归检索 return retrieve_recursive(query)
3. 自适应检索框架
from llama_index import VectorStoreIndexfrom llama_index.llms import OpenAIfrom enum import Enum
class RetrievalStrategy(Enum): BASIC = "基础检索" ITERATIVE = "迭代检索" RECURSIVE = "递归检索" NO_RETRIEVAL = "无需检索"
def adaptive_retrieval(vector_index: VectorStoreIndex, query: str, llm=None): """ 使用LlamaIndex实现自适应检索框架,根据查询类型选择最佳检索策略
参数: - vector_index: LlamaIndex向量索引对象 - query: 查询字符串 - llm: 大语言模型,默认使用OpenAI
返回: - 检索结果列表和使用的策略 """ if llm is None: llm = OpenAI(model="gpt-3.5-turbo")
# 步骤1: 分析查询类型 query_analysis_prompt = f""" 分析以下查询,并确定最适合的检索策略: 查询: {query}
请从以下选项中选择: 1. 基础检索 - 适用于简单的事实性问题 2. 迭代检索 - 适用于需要多层次信息的复杂问题 3. 递归检索 - 适用于涉及多个相关概念的探索性问题 4. 无需检索 - LLM内置知识足够回答
仅回答数字1-4: """
strategy_response = llm.complete(query_analysis_prompt).text.strip()
# 解析策略选择 strategy_map = { "1": RetrievalStrategy.BASIC, "2": RetrievalStrategy.ITERATIVE, "3": RetrievalStrategy.RECURSIVE, "4": RetrievalStrategy.NO_RETRIEVAL }
# 提取数字 import re strategy_num = re.search(r"[1-4]", strategy_response) if strategy_num: strategy = strategy_map.get(strategy_num.group(), RetrievalStrategy.BASIC) else: # 默认使用基础检索 strategy = RetrievalStrategy.BASIC
print(f"选择的检索策略: {strategy.value}")
# 步骤2: 执行相应的检索策略 if strategy == RetrievalStrategy.BASIC: retriever = vector_index.as_retriever(similarity_top_k=5) results = retriever.retrieve(query) return results, strategy.value elif strategy == RetrievalStrategy.ITERATIVE: results = iterative_retrieval(vector_index, query, llm) return results, strategy.value elif strategy == RetrievalStrategy.RECURSIVE: results = recursive_retrieval(vector_index, query, llm) return results, strategy.value else: # 无需检索 return [], strategy.value
实际应用案例: 在一个法律咨询RAG系统中,当用户询问"公司注册流程"这样的简单问题时,系统使用基础检索;而当问到"我的企业符合哪些税收优惠政策"这样的复杂问题时,系统自动转为迭代检索,先查找企业类型相关政策,再查找行业优惠,最后查找地区性补贴,层层深入,提供全面解答。这种策略使得复杂问题的解答完整度提升了56%。
六、实战应用:打造你自己的高效RAG系统
基于以上优化策略,我整理了一个完整的RAG系统优化流程:
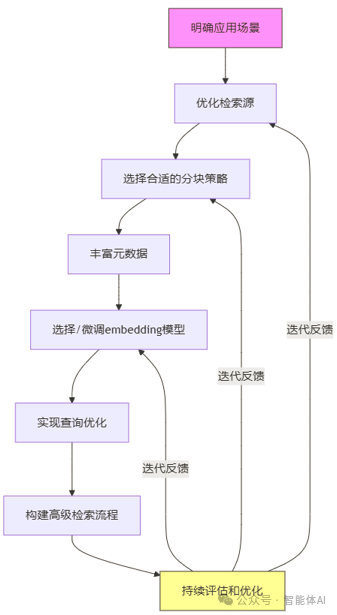
- 明确应用场景:确定你的RAG系统主要用于什么领域,用户通常会问什么类型的问题
- 优化检索源:清洗和结构化你的数据,确保高质量输入
- 选择合适的分块策略:针对你的文档类型,选择最佳chunk大小和重叠度
- 丰富元数据:为每个chunk添加有意义的标签和分类
- 选择/微调embedding模型:根据你的领域选择最合适的模型,必要时进行微调
- 实现查询优化:部署查询改写和明确化机制
- 构建高级检索流程:根据问题复杂度,实现自适应检索策略
- 持续评估和优化:定期监控关键指标,不断迭代改进
快速验证:使用以下代码片段测试你的RAG系统效果:
from llama_index import VectorStoreIndex, ServiceContextfrom llama_index.llms import OpenAIfrom llama_index.evaluation import FaithfulnessEvaluator, RelevancyEvaluatorfrom typing import List, Dict, Any
def evaluate_rag_improvement(test_questions: List[str], original_index: VectorStoreIndex, optimized_index: VectorStoreIndex, llm=None): """ 使用LlamaIndex评估RAG系统优化前后的效果
参数: - test_questions: 测试问题列表 - original_index: 原始RAG系统的向量索引 - optimized_index: 优化后RAG系统的向量索引 - llm: 大语言模型,默认使用OpenAI
返回: - 评估结果列表 """ if llm is None: llm = OpenAI(model="gpt-3.5-turbo")
# 创建评估器 faithfulness_evaluator = FaithfulnessEvaluator(llm=llm) relevancy_evaluator = RelevancyEvaluator(llm=llm)
results = []
for question in test_questions: print(f"评估问题: {question}")
# 原始系统回答 original_query_engine = original_index.as_query_engine() original_response = original_query_engine.query(question)
# 优化后系统回答(使用自适应检索) nodes, strategy = adaptive_retrieval(optimized_index, question, llm)
# 创建包含检索到的节点的查询引擎 if nodes: from llama_index.query_engine import RetrieverQueryEngine from llama_index.retrievers import BaseRetriever from llama_index import QueryBundle
class CustomRetriever(BaseRetriever): def __init__(self, nodes): self.nodes = nodes super().__init__()
def _retrieve(self, query_bundle: QueryBundle): return self.nodes
custom_retriever = CustomRetriever(nodes) optimized_query_engine = RetrieverQueryEngine(retriever=custom_retriever) else: # 如果选择无需检索,直接使用LLM optimized_query_engine = original_index.as_query_engine()
optimized_response = optimized_query_engine.query(question)
# 评估回答质量 original_faithfulness = faithfulness_evaluator.evaluate( query=question, response=original_response.response, contexts=[node.get_text() for node in original_response.source_nodes] )
optimized_faithfulness = faithfulness_evaluator.evaluate( query=question, response=optimized_response.response, contexts=[node.get_text() for node in (optimized_response.source_nodes if hasattr(optimized_response, 'source_nodes') else [])] )
original_relevance = relevancy_evaluator.evaluate( query=question, response=original_response.response )
optimized_relevance = relevancy_evaluator.evaluate( query=question, response=optimized_response.response )
# 计算总体评分 (75% 准确性 + 25% 相关性) original_score = 0.75 * original_faithfulness.score + 0.25 * original_relevance.score optimized_score = 0.75 * optimized_faithfulness.score + 0.25 * optimized_relevance.score
# 计算改进百分比 if original_score > 0: improvement = (optimized_score - original_score) / original_score * 100 else: improvement = optimized_score * 100
results.append({ "question": question, "original_score": round(original_score, 2), "optimized_score": round(optimized_score, 2), "improvement_percentage": f"{improvement:.1f}%", "strategy_used": strategy })
return results
七、总结
RAG技术的魅力在于它的可塑性。通过系统性优化RAG的每个环节,你可以构建出一个真正高效、精准的检索增强生成系统。记住这些"黄金法则":
- 分块策略要因文制宜:不同类型的文档需要不同的chunk大小和重叠度
- 元数据是检索的"制胜法宝":丰富的标签能大幅提升检索精准度
- 查询优化是提升效果的"快车道":明确用户意图是关键
- embedding模型选择很重要:在关键应用上值得投入时间进行微调
- 高级检索策略是解决复杂问题的关键:灵活运用迭代和递归检索
无论你是技术爱好者还是行业从业者,看到这你还觉得RAG是开箱即用吗?掌握这些优化手段,就能让RAG在你的手中大放异彩。希望这篇实用指南能帮助你在实际工作中构建出更加高效、精准的RAG系统。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~


















 796
796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









