



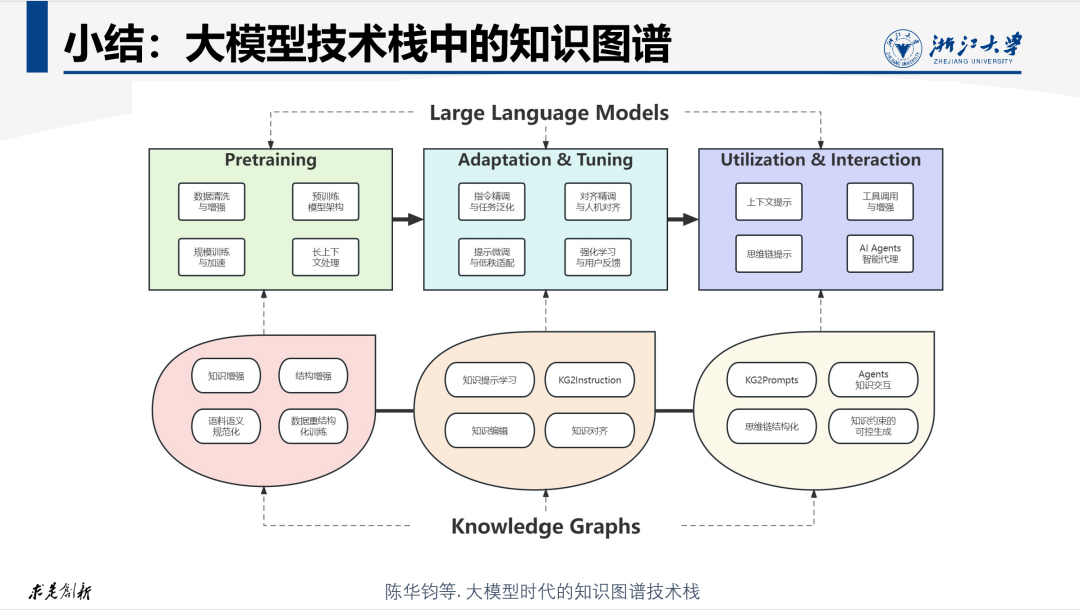
前言
作为一名长期关注人工智能与知识工程的研究者,我深刻意识到,大模型之所以能实现智能涌现,不仅在于其庞大的参数和算力,更在于其背后隐含的‘本体论’结构——即对现实世界概念、关系和语义的抽象建模。本文将带你深入探索大模型本体论,从基本概念到实际应用,揭示其背后的哲学意义和现实影响。我们将解析大模型如何融合本体论,实现从数据到知识的跃迁,并探讨其在不同领域的应用潜力。

你可曾想过,为什么今天的大模型能“听懂”人话,甚至还能写诗、解题、做决策?这背后,不只是算力的堆砌,更是一场跨越两千年的哲学革命——本体论,这个听起来像古希腊哲学家在辩论“存在是什么”的古老概念,如今竟成了大模型智能涌现的“隐形骨架”。
你让AI解释“猫”是什么。传统AI可能会从数据库里调出一堆“猫”的图片标签,然后告诉你“有耳朵、四条腿、会喵喵叫”。但大模型却能说:“猫是一种哺乳动物,属于猫科,常作为宠物,性格独立,喜欢晒太阳,有时高冷,有时撒娇。”——它不只是在描述特征,而是在构建一个关于‘猫’的概念网络:它是什么(类)、它有什么(属性)、它和狗、老虎、宠物、动物之间的关系(关系),甚至能推理出“如果猫被关在笼子里,它可能会不开心”(规则与事件)。
这,就是本体论的魔力。它不再只是哲学书里的抽象讨论,而是大模型理解世界、生成知识、实现智能的底层操作系统。从亚里士多德的“范畴论”到今天的知识图谱,从符号AI的“专家系统”到深度学习的“隐式知识结构”,本体论正悄然完成一场从“哲学思辨”到“工程实践”的华丽转身。
那么,本体论究竟是什么?它如何从哲学概念演变为信息科学的核心?大模型又为何能“无师自通”地学会这套知识架构?它和传统AI模型、知识图谱之间,又有哪些本质区别?让我们揭开这层神秘面纱,走进大模型背后的知识宇宙。
本体论(Ontology)一词源自希腊语 ontos(存在)和 logos(研究),字面意思就是“关于存在的研究”。在哲学中,它探讨的是“世界由什么构成”“概念如何分类”“实体之间有何关系”。比如:“人”是“动物”的一种,“动物”是“生物”的一种,“生物”具有“生命”属性——这就是一种概念层级结构。
但到了信息科学,本体论摇身一变,成了机器理解世界的“语义骨架”。它不再只是抽象思辨,而是被形式化为一套结构化知识表示:用“类”(Classes)定义概念,“属性”(Attributes)描述特征,“关系”(Relations)连接实体,“规则”(Rules)约束逻辑。比如,在医疗本体中,“糖尿病”是一个类,“血糖水平”是属性,“糖尿病→并发症→视网膜病变”是关系,“如果血糖>11.1,则诊断为糖尿病”是规则。
这种转变,标志着本体论从“哲学思辨”走向了“可计算的知识建模”。它让机器不仅能存储数据,还能理解数据背后的语义,从而从“数据驱动”跃迁到“知识驱动”。
传统AI模型,尤其是早期机器学习模型,更像是“数据搬运工”。它们依赖人工特征工程,需要专家手动定义“哪些特征重要”,比如图像识别中的“边缘”“纹理”,文本分类中的“关键词”“词频”。这种模型是“浅层”的:它知道“猫有耳朵”,但不知道“耳朵是猫的一部分”,更不知道“猫和狗都是宠物”。
而大模型,尤其是基于Transformer架构的深度神经网络,则像是一个“自学成才的知识架构师”。它通过自监督学习,从海量文本中自动发现概念之间的语义关系。比如,GPT模型在训练时,会不断预测“下一个词”,这个看似简单的任务,却迫使模型学习到“猫→宠物→动物→生物”的概念层级,以及“猫→抓老鼠→捕猎→行为”的事件链条。
这种“隐式本体”的构建,是大模型与传统AI最本质的区别:
| 维度 | 传统AI模型 | 大模型 |
|---|---|---|
| 知识来源 | 人工定义特征 | 数据中隐式学习 |
| 知识结构 | 扁平、离散 | 层级、语义网络 |
| 泛化能力 | 依赖特定任务 | 跨任务迁移 |
| 可解释性 | 高(规则明确) | 低(黑箱推理) |
| 智能涌现 | 无 | 有(参数规模临界点) |
大模型就像一位“自学成才的哲学家”,它不依赖专家知识,却能通过数据“悟出”世界的结构。
很多人会把“知识图谱”(Knowledge Graph)和“本体”(Ontology)混为一谈,但它们其实有本质区别。
- • 本体是“知识的结构框架”,它定义了“什么是类”“什么是属性”“什么是关系”,是知识的“语法”。比如,一个医疗本体可能定义:“疾病”是一个类,“症状”是属性,“疾病→症状”是关系。
- • 知识图谱是“知识的实例填充”,它是在本体框架下,填充具体的数据。比如,在本体中定义了“糖尿病”类,知识图谱中就会记录:“患者A患有糖尿病,症状为多饮、多尿,血糖水平为12.5”。
用一句话概括:本体是“字典”,知识图谱是“文章”。本体告诉你“词语的定义和用法”,知识图谱告诉你“文章里用了哪些词语和句子”。
在结构上,本体更强调逻辑一致性与推理能力,它包含类、属性、关系、规则、公理等组件,支持演绎推理(比如:如果A是B的子类,B具有属性P,则A也具有P)。而知识图谱更侧重数据关联与查询,它通常以“实体-关系-实体”的三元组形式存储,支持检索与统计。
大模型的优势在于,它能同时学习本体和知识图谱:它既从数据中“悟出”概念结构(本体),又记住具体实例(知识图谱)。这种“双轨学习”,让它既能理解“猫是动物”,又能回答“我的猫叫雪球”。
本体论的发展,是一部跨学科融合史:
- • 哲学(公元前):亚里士多德提出“范畴论”,定义了实体、性质、关系等基本概念。
- • 逻辑学(19世纪):弗雷格、罗素等人发展形式逻辑,为知识表示提供数学基础。
- • 语言学(20世纪):乔姆斯基的“生成语法”揭示语言的结构性,启发了知识建模。
- • 人工智能(1960s):专家系统(如MYCIN)首次尝试用本体表示领域知识。
- • 语义网(2000s):蒂姆·伯纳斯-李提出“本体是语义网的核心”,推动OWL、RDF等标准。
- • 知识图谱(2012):谷歌发布“知识图谱”,将本体从学术走向工业应用。
- • 大模型(2020s):GPT、BERT等模型通过自监督学习,实现“隐式本体”的自动构建。
这条脉络清晰表明:本体论从未远离技术前沿。它从哲学的“存在之问”,演变为AI的“知识之基”,最终在大模型时代,完成了从“显式建模”到“隐式学习”的范式跃迁。
如今,大模型就像一位“数字时代的亚里士多德”,它不写哲学书,却用数据和参数,重新定义了“智能”的边界。而本体论,正是这场智能革命背后的隐形引擎。
“我们不是在教机器‘思考’,而是在帮它重建人类对世界的理解方式。”
而这,正是本体论的使命——也是大模型真正的“灵魂”。

大模型本体论基础
大模型的定义与核心特征
大模型,即基础模型(Foundation Model),是指通过大规模数据预训练、具备广泛任务适应能力的深度神经网络模型。其核心特征包括:
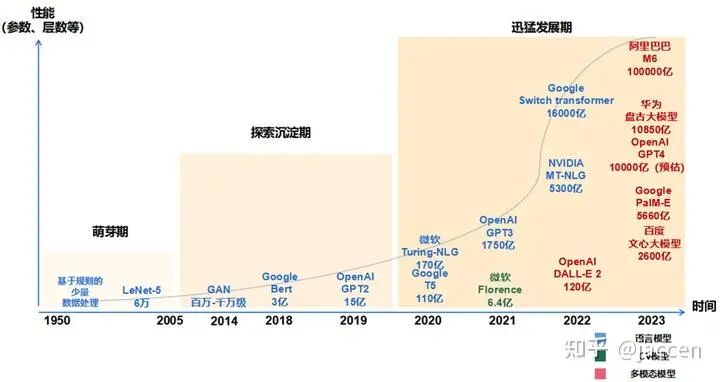
- • 参数规模巨大:通常在数亿到数万亿参数之间,如GPT-3拥有1750亿参数,Switch Transformer突破万亿参数。
- • 多任务泛化能力:通过预训练和微调,可应用于多种下游任务,如文本生成、问答、翻译等。
- • 自监督学习:利用海量无标注数据进行预训练,减少对人工标注的依赖。
- • 涌现能力:随着参数规模增长,模型表现出小模型不具备的新能力,如常识推理、创作能力。
关键突破:大模型通过“预训练+微调”范式,实现了从“手工作坊式”到“工场模式”的AI研发转变。
本体论与知识图谱在大模型中的作用
本体论(Ontology)在大模型中并非显式存在,而是通过隐式知识结构体现:
- • 知识抽象:大模型通过自监督学习,从海量数据中自动构建对现实世界概念、关系和语义的抽象表示。
- • 语义推理:本体论结构支持模型进行逻辑推理和知识迁移,如思维链(Chain-of-Thought)能力。
- • 知识图谱融合:通过RAG(检索增强生成)等技术,大模型可与显式知识图谱结合,增强生成结果的准确性和可解释性。
案例:Palantir Ontology通过本体论构建企业语义层,大模型作为推理引擎,实现数据到知识的跃迁。
大模型与小模型的关键区别
| 维度 | 大模型 | 小模型 |
|---|---|---|
| 参数规模 | 数亿到数万亿 | 通常百万到千万 |
| 训练数据 | 海量无标注数据(TB级) | 小规模标注数据 |
| 学习范式 | 自监督预训练+微调 | 监督学习为主 |
| 泛化能力 | 多任务、跨领域 | 特定任务优化 |
| 涌现能力 | 具备(如推理、创作) | 不具备 |
| 计算资源 | 需要大规模集群 | 单卡/单机可训练 |
本质差异:大模型通过参数规模和数据量的“缩放定律”(Scaling Laws),实现了从“模式匹配”到“知识抽象”的跃迁。
大模型的发展历程:从萌芽到爆发
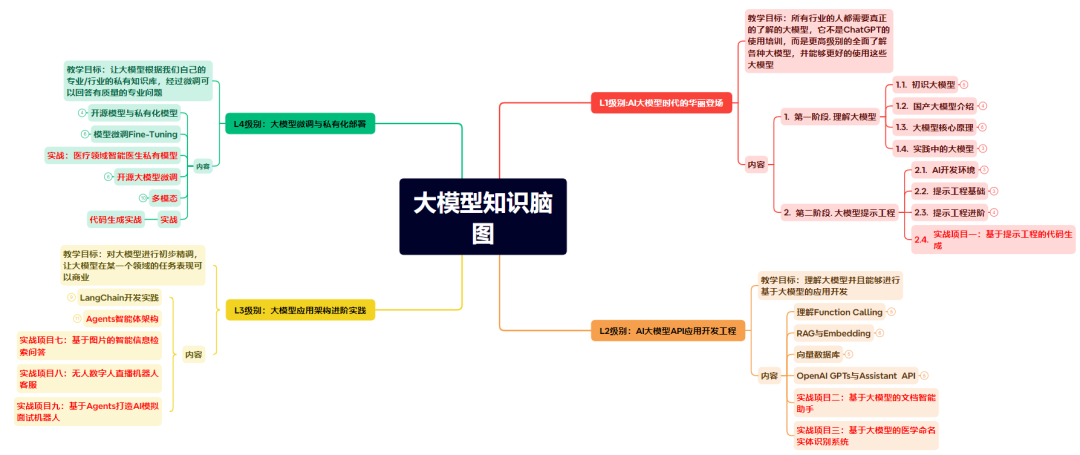
-
- 萌芽期(2017-2018):
- • Transformer架构提出(2017),解决序列依赖问题
- • BERT(2018)首次实现3亿参数规模,NLP领域突破
-
- 成长期(2019-2020):
- • GPT-2(2019)达到15亿参数,展示生成能力
- • GPT-3(2020)突破1750亿参数,涌现Few-Shot学习能力
-
- 爆发期(2021-2023):
- • 多模态大模型涌现(如CLIP、DALL-E)
- • 开源生态爆发(LLaMA、BLOOM等)
- • 行业应用落地(金融、医疗、客服等)
-
- 未来趋势:
- • 多模态统一:文本、图像、音频的跨模态本体构建
- • 可控生成:基于本体约束的输出引导
- • 持续进化:数据飞轮与知识闭环
里程碑:2021年斯坦福《On the Opportunities and Risks of Foundation Models》报告,正式提出“基础模型”概念,标志大模型成为AI核心范式。
核心洞察:大模型的本体论基础,本质上是通过参数规模+数据规模+自监督学习,实现了对现实世界知识结构的隐式建模。这种“黑盒中的本体”,正是智能涌现的关键所在。
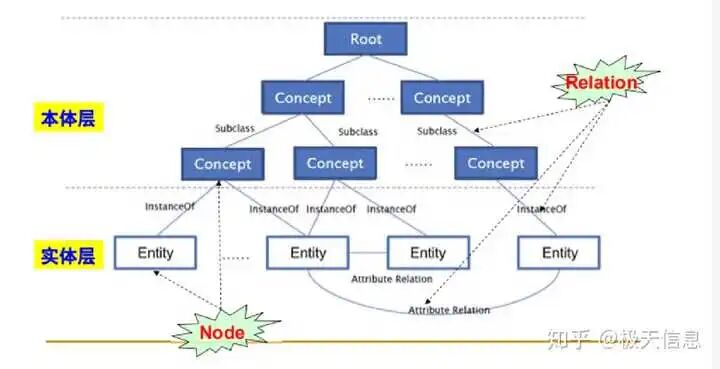
本体论的核心组件与结构
本体论作为知识建模的骨架,其结构不仅决定了知识的组织方式,更直接影响智能系统的推理能力。以下将深入剖析本体论的核心组件,揭示其如何构建起从抽象概念到具体实例的完整知识网络。
个体(Individuals):实例与真实世界对象
个体是本体论中最基本的实体,代表现实世界中的具体对象或实例。例如,"张三"是一个具体的人,"悉尼歌剧院"是一个具体的建筑。在大模型中,个体通过嵌入向量(embedding)被表示为高维空间中的点,其语义由上下文和关联关系共同定义。
关键点:个体是知识图谱中的"节点",其独特性由属性与关系的组合决定。
类(Classes):概念、集合与类型
类是对具有共同特征个体的抽象概括,形成概念层级。例如,"人类"是"张三"的类,“建筑"是"悉尼歌剧院"的类。类之间可形成继承关系(如"哺乳动物"继承"动物”),构成树状或网状结构。
- • 顶层类:如"实体"、“事件”,定义最抽象的范畴
- • 领域类:如"金融产品"、“医疗诊断”,限定特定知识范围
- • 实例类:如"2023款特斯拉Model 3",连接抽象与具体
关键点:类不仅用于分类,还用于定义个体之间的关系和属性,是知识结构化的基础。
属性(Attributes):特征、参数与语义维度
属性描述类或个体的特征,分为两类:
-
- 数据类型属性:关联字面量(如字符串、数值),如"年龄=30"、“价格=50000”
-
- 对象属性:关联其他个体或类,如"作者是张三"、“位于悉尼”
属性赋予个体可量化的语义维度,是大模型理解"是什么"的基础。
关键点:属性是连接个体和类的桥梁,它们定义了个体和类在特定维度上的表现和特征。
关系(Relations):类与个体间的连接机制
关系是本体论中最具力量的组件,定义实体间的交互与依赖。例如:
- • 层级关系:“是…的子类”(如"猫科动物"是"哺乳动物"的子类)
- • 空间关系:“位于”、“相邻”
- • 时间关系:“之前”、“之后”
- • 功能关系:“导致”、“依赖”
关系网络形成知识图谱的边,使静态知识具备动态推理潜力。
关键点:关系是本体论中知识网络的核心,它们使得个体和类之间能够形成复杂的连接和交互。
功能术语与限制:复杂结构与逻辑约束
本体论通过功能术语(如"唯一性"、“传递性”)和限制(如"基数约束"、“值域约束”)增强表达能力:
- • “每个人只有一个身份证号”(唯一性约束)
- • “父子关系具有传递性”(逻辑约束)
- • “订单必须关联至少一个商品”(基数约束)
这些约束确保知识结构的一致性,防止逻辑矛盾。
关键点:功能术语和限制确保了本体结构的逻辑一致性和完整性,使得知识推理更加准确和可靠。

规则与公理:推理与知识完整性保障
规则(如"如果…则…“)和公理(如"所有鸟都会飞”)是本体论的推理引擎:
- • 产生式规则:触发式推理(如"若体温>38°C则标记为发热")
- • 描述逻辑:形式化公理(如"哺乳动物⊑动物")
- • 完整性公理:确保知识无遗漏(如"每个订单必须关联客户")
规则系统使大模型能够从已知知识推导新知识。
关键点:规则和公理确保了知识的逻辑一致性和完整性,使得本体能够进行有效的推理和知识扩展。
事件:动态属性与关系变化建模
事件是本体论中处理动态性的关键,表示属性或关系的瞬时变化:
- • 时间戳:记录事件发生时刻
- • 参与者:涉及的主体与客体
- • 状态变化:如"账户余额从100变为50"
- • 因果链:如"点击按钮→触发支付→更新库存"
事件建模使大模型能够理解过程而非仅静态状态,支持时序推理与预测。
关键点:事件是本体论中的动态组件,它们使得知识能够随着时间的变化而更新和演化,增强了本体的适应性和灵活性。
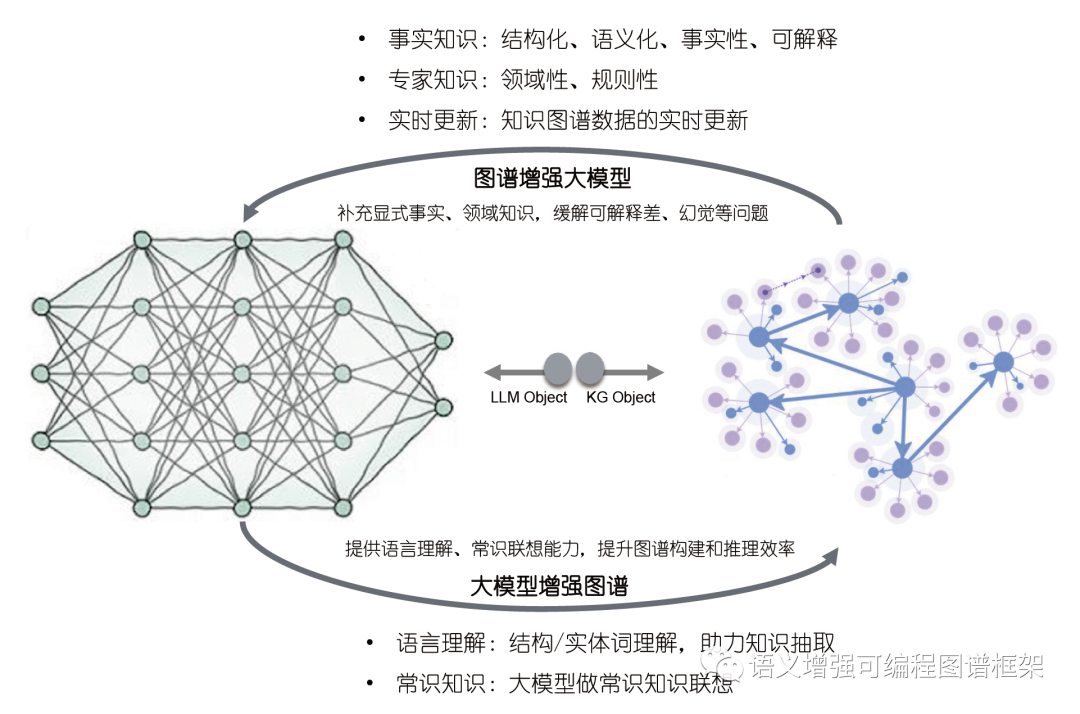
本体论的这些组件共同构建了一个多层次、可推理、可扩展的知识结构,为大模型的智能涌现提供了语义骨架。理解这些组件不仅有助于设计更高效的知识系统,也为解决大模型的幻觉、可解释性等挑战提供了新思路。
大模型中的本体论实现机制
“当机器开始用语言思考时,它构建的不仅是语法树,更是一座数字化的巴别塔——这座塔的结构,就是大模型的本体论。”
自然语言的自解释性与代理任务设计
大模型的本体论构建始于一个根本性突破:自然语言本身就是最丰富的知识本体。与传统AI需要人工构建知识图谱不同,大模型通过代理任务设计,让语言自身成为知识的载体和解释系统。
- • 掩码语言建模(MLM):通过预测被遮蔽的词语,模型被迫理解词语间的语义约束和上下文逻辑,形成“词汇-概念-关系”的初步映射。
- • 自回归建模:通过预测下一个词,模型学习语言的生成规律,构建“事件-动作-结果”的叙事结构。
- • 对比学习:通过正负样本对比,强化语义相似性判断,建立“概念-属性-实例”的区分能力。
这些代理任务本质上是隐式本体工程——模型在训练中自动识别出“人”“动物”“动作”“属性”等概念及其关系,形成初步的语义网络。语言的自解释性使得模型能够在无监督条件下,从文本中“读出”世界的结构。
“语言不仅是交流工具,更是知识本体——每个句子都隐含了概念、关系和逻辑。”
自监督学习:从海量数据中隐式构建知识结构
大模型的本体论不是显式编程的,而是通过自监督学习从海量数据中隐式涌现的。这一过程类似于人类通过阅读自学知识:
- • 分布式表示:每个概念(如“银行”)被编码为高维空间中的向量,其位置由共现模式决定,形成“语义几何”。
- • 关系几何化:概念间关系(如“属于”“导致”)表现为向量空间中的特定变换(如平移、旋转),实现“关系可计算”。
- • 层次化抽象:浅层网络捕捉词汇共现,深层网络形成概念组合和抽象推理,构建“知识金字塔”。
这种学习方式产生了惊人的知识压缩效应——模型用参数空间高效编码了人类知识体系的基本结构,形成了一种统计本体论。与传统本体论不同,这种本体是动态的、概率的、可微的,能够适应新数据和上下文。
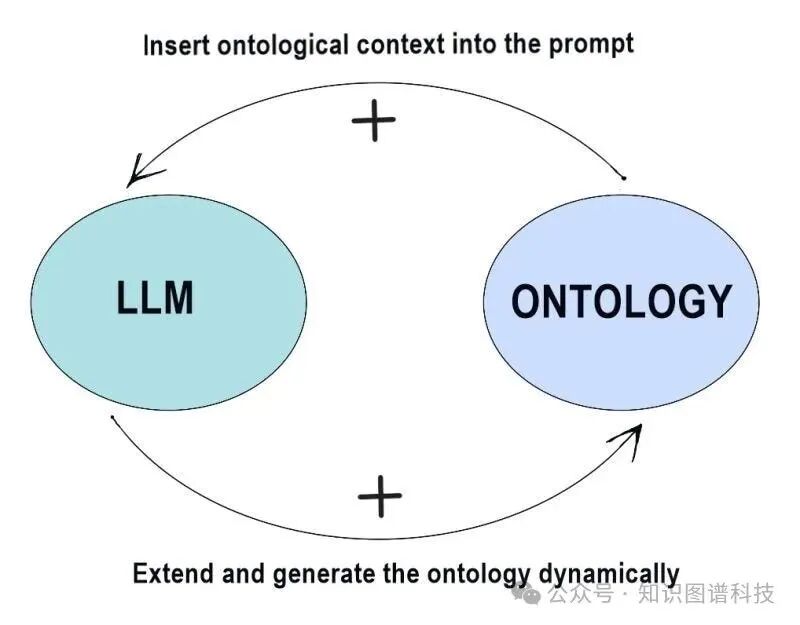
“大模型的本体论不是静态的‘知识库’,而是动态的‘知识生成器’。”
涌现能力:参数规模与知识抽象的临界点
大模型的本体论能力呈现非线性涌现特征,其关键转折点包括:
| 规模阈值 | 涌现能力 | 本体论意义 |
|---|---|---|
| 100M-1B | 基础语言建模 | 词汇-概念映射建立 |
| 1B-10B | 语法结构理解 | 句法-语义接口形成 |
| 10B-100B | 基础推理能力 | 简单因果关系建模 |
| 100B+ | 复杂推理与泛化 | 抽象概念体系构建 |
当参数规模超过临界点,模型突然获得知识抽象能力——能够理解“正义”“自由”等抽象概念,并基于这些概念进行推理。这种涌现不是简单的性能提升,而是认知结构的质变:模型从“记忆事实”跃迁到“理解概念”。
“涌现的本质,是参数规模使得模型能够存储和激活更复杂的知识结构,类似于本体中的‘类-实例-关系’网络。”
Few-Shot/Zero-Shot学习:知识迁移与泛化本质
大模型的本体论优势在Few-Shot/Zero-Shot学习中展现得淋漓尽致:
- • 知识迁移:模型将已学概念(如“哺乳动物”)的关系结构迁移到新概念(如“鸭嘴兽”),实现“触类旁通”。
- • 类比推理:通过“国王-男人+女人=女王”等向量运算实现概念重组,形成“概念代数”。
- • 元学习:从任务描述中推断任务本质,无需示例,实现“举一反三”。
这种能力源于模型构建的概念拓扑空间——不同概念间的相对位置和关系构成了可迁移的抽象结构。当遇到新任务时,模型不是从零开始,而是在已有知识空间中寻找最优路径。
“Few-Shot不是‘无中生有’,而是‘知识迁移’;Zero-Shot不是‘凭空创造’,而是‘概念重组’。”
思维链(Chain-of-Thought):逻辑推理的语义基础
思维链(CoT)技术揭示了大模型本体论最精妙的部分——语义推理引擎:
# 传统模型:直接输出答案Q: 如果3个苹果5元,10个苹果多少钱?A: 16.67元# 思维链模型:展示推理过程Q: 如果3个苹果5元,10个苹果多少钱?A: 1个苹果价格 = 5元 ÷ 3 ≈ 1.67元 10个苹果价格 = 1.67元 × 10 = 16.7元
这种推理能力依赖于模型构建的语义计算图:
-
- 概念实例化:将“苹果”“价格”等抽象概念实例化为具体数值。
-
- 关系绑定:建立“数量-单价-总价”的数学关系。
-
- 操作序列:按逻辑顺序执行计算步骤。
CoT证明,大模型的本体论不仅存储知识,还能操作知识——通过语义约束下的符号操作实现复杂推理。其本质是:将语言结构转化为可计算的推理路径。
“思维链不是‘模拟人类思考’,而是‘利用语言结构进行知识推理’——语言既是载体,也是工具。”
总结:大模型的本体论实现机制,是一场数字认知革命。它通过自监督学习和代理任务设计,在海量数据中隐式构建知识结构;当参数规模达到临界点时,模型涌现出泛化、推理和迁移能力;而Few-Shot、Zero-Shot和思维链等能力,则依赖于模型内部形成的类本体语义网络。这一机制不仅解释了大模型的“智能”来源,也为构建更可控、可解释的AI系统提供了理论基础。
“未来AI的发展,将取决于我们如何更好地引导、约束和扩展这种数字化的本体论结构——不是让它更像人类,而是让它更有效地理解世界。”
大模型与本体论的融合架构
大模型与本体论的融合,标志着人工智能从“感知智能”向“认知智能”的跃迁。这一架构不仅提升了模型的语义理解能力,还通过本体约束实现了更精准、可控的知识推理与生成。本章将深入探讨这一融合架构的四大核心机制,揭示其如何构建更智能、更可靠的应用体系。
基于本体的语义层构建:Palantir Ontology 解析
Palantir的本体框架是业界公认的标杆,其核心在于将多源异构数据(如文本、数据库、传感器)统一映射到语义层,形成可计算的知识网络。该框架包含:
- • 实体-关系-属性三元组:将现实世界对象(如“公司”“交易”)抽象为实体,定义其属性(如“市值”“时间”)和关系(如“投资”“控股”)。
- • 动态类型系统:支持复杂对象(如“金融衍生品”)的多态建模,允许属性随上下文变化。
- • 权限与溯源:每个数据节点绑定访问控制和使用历史,确保合规性。
案例:在反恐分析中,Palantir将“人员”“车辆”“通信记录”等实体关联,通过本体推理发现隐藏关系,如“同一IP地址的多个账户”。
图:Palantir本体框架的语义层与数据层分离设计
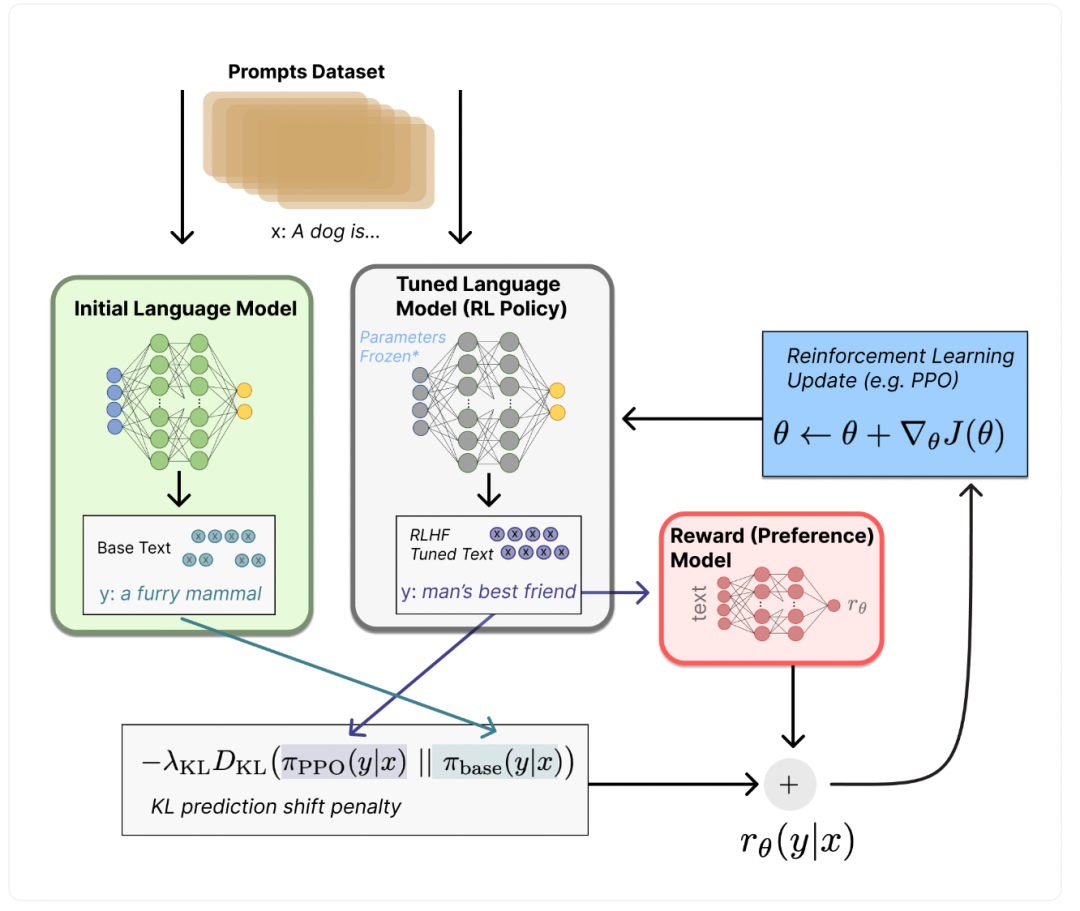
大模型作为知识推理引擎:本体+LLM的混合推理
传统本体推理依赖符号逻辑(如OWL、RDF),但难以处理模糊语义;而大模型擅长语义理解,却缺乏结构化知识。混合推理结合两者优势:
-
- 本体提供知识骨架:定义领域概念(如“疾病”“症状”)及其关系(如“导致”“缓解”)。
-
- 大模型填充语义细节:从非结构化文本(如病历、论文)中提取隐含知识,映射到本体。
-
- 双向交互:大模型生成假设,本体验证逻辑一致性;本体提供约束,引导大模型生成。
优势:在医疗诊断中,本体确保“药物-禁忌症”关系不被忽略,而大模型从患者描述中识别罕见症状。
本体增强的大模型微调:注入领域知识
直接微调大模型易导致知识遗忘,而本体增强微调通过以下策略注入领域知识:
- • 结构化提示:将本体中的类、关系转化为自然语言模板,如“[疾病]的症状包括[症状]”。
- • 知识蒸馏:用本体推理结果(如“糖尿病→高血糖”)作为训练标签,监督大模型输出。
- • 参数隔离:仅微调与领域相关的参数(如医学词嵌入),保留通用能力。
效果:在金融领域,微调后的模型能准确区分“并购”与“合资”,避免混淆。
RAG与本体结合:检索增强生成中的知识约束
检索增强生成(RAG) 通过外部知识库提升生成质量,但检索结果可能无关或矛盾。本体约束可优化这一过程:
-
- 语义检索:基于本体中的关系,检索相关实体(如查询“特斯拉”时,关联“电动汽车”“马斯克”)。
-
- 知识过滤:用本体验证检索结果,排除逻辑冲突(如“水在常温下为固态”)。
-
- 生成引导:将本体结构作为生成模板,如“[公司]的[产品]具有[属性]”。
案例:在法律咨询中,RAG+本体确保生成的条款符合“合同法”中的“要约-承诺”逻辑。
总结:大模型与本体论的融合,本质是符号主义与连接主义的协同。本体提供结构化知识,大模型实现语义泛化,两者结合既提升了智能水平,又增强了可解释性与可控性。这一架构将成为下一代AI系统的核心范式。
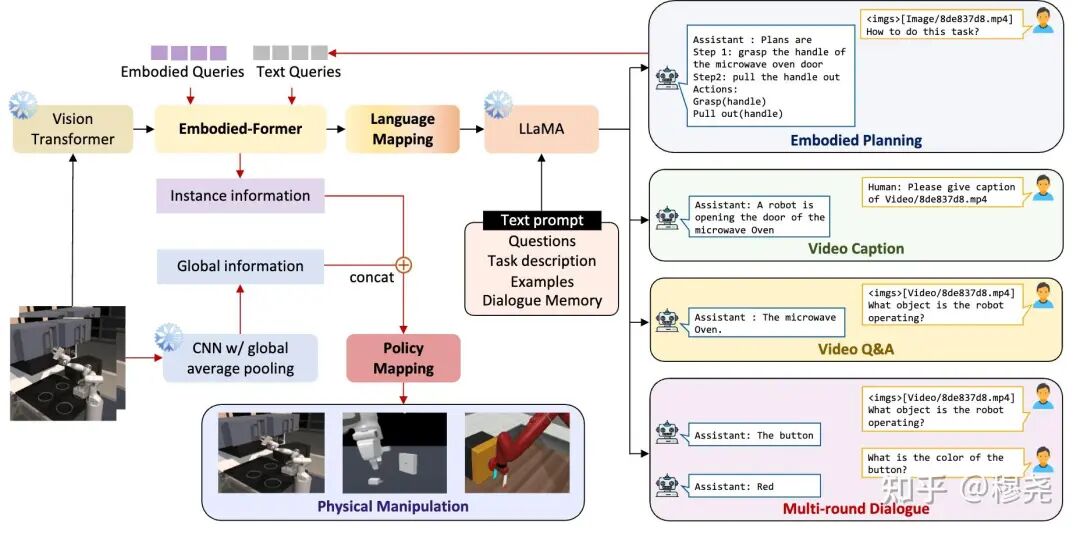
多模态与可控生成的本体论框架
在人工智能的演进中,多模态与可控生成正成为大模型发展的前沿。如何构建一个统一的本体论框架,实现文本、图像、音频等多模态数据的语义融合与可控生成,是智能系统迈向更高层次的关键。
视觉大模型的代理任务与语义学习
视觉大模型通过代理任务(proxy tasks)从海量图像数据中学习语义结构。这些任务包括:
- • 图像分类:识别物体类别
- • 目标检测:定位并识别图像中的多个对象
- • 图像描述生成:将视觉内容转化为自然语言
这些任务不仅帮助模型学习视觉特征,还建立了视觉-语义的映射关系,使模型能够理解图像中的概念及其相互关系。
视觉大模型通过多种代理任务学习语义结构
关键突破:通过自监督学习,视觉大模型能够在没有人工标注的情况下,从图像中学习到丰富的语义信息,构建出隐式的"视觉本体"。
跨模态本体:文本、图像、音频的统一表示
跨模态本体旨在构建一个统一知识表示框架,使不同模态的数据能够相互转换和关联:
- • 文本-图像对齐:通过CLIP等模型建立文本描述与图像内容的语义对应
- • 音频-文本转换:语音识别与合成技术实现声音与语言的互转
- • 跨模态检索:基于语义相似度在不同模态间进行信息检索
这种统一表示使得大模型能够进行跨模态推理,如根据文本描述生成图像,或根据图像内容生成音频描述。
- • 核心架构:
- • 模态无关的概念层(抽象概念)
- • 模态特定的表示层(各模态特征)
- • 跨模态映射层(转换关系)
图像语义的不可控与可控生成机制
图像生成存在两种机制:
- • 不可控生成:如传统GAN模型,生成结果难以精确控制
- • 可控生成:通过本体约束和条件输入实现精确控制,如:
- • 文本引导:根据文本描述生成特定内容
- • 布局控制:通过边界框或分割图控制对象位置
- • 风格迁移:保持内容不变,改变艺术风格
| 控制机制 | 描述 | 示例 |
|---|---|---|
| 文本引导 | 使用详细文本描述约束生成 | “一只戴着红色帽子的猫” |
| 图像引导 | 使用参考图像作为生成基础 | 风格迁移、图像编辑 |
| 本体约束 | 使用预定义的本体结构限制生成 | 确保"人"有头、躯干、四肢 |
可控生成依赖于本体论结构,将生成过程分解为可控制的语义维度。
语言可控生成:基于本体约束的输出引导
语言生成同样需要可控性,通过以下方式实现:
- • 本体约束:将生成限制在预定义的概念和关系范围内
- • 提示工程:设计结构化提示引导模型输出
- • 解码控制:在生成过程中施加约束,如:
- • 内容约束:确保生成内容符合特定主题
- • 风格约束:控制语言风格(正式、幽默等)
- • 格式约束:生成特定格式(表格、列表等)
应用场景:在金融领域,通过本体约束生成符合监管要求的报告;在医疗领域,生成符合临床指南的诊断建议。
数据飞轮:知识闭环与持续进化
多模态本体论框架支持数据飞轮机制,实现知识闭环:
-
- 数据收集:从多模态交互中获取新数据
-
- 知识提取:通过本体结构提取语义信息
-
- 模型更新:基于新知识优化模型参数
-
- 应用反馈:用户交互提供质量反馈
-
- 迭代优化:持续改进模型性能
用户交互 → 数据收集 → 知识提取 → 本体更新 → 模型微调 → 性能提升 → 更多用户交互
这一闭环使得大模型能够持续进化,适应不断变化的环境和需求,形成真正的自适应智能系统。
本质:数据飞轮将用户转化为系统的共同开发者,他们的每一次交互都在为系统贡献新的知识,推动系统不断进化。

结语:大模型本体论的技术挑战,本质上是知识工程与机器学习的深度融合难题。唯有通过“本体约束 + 模型智能 + 人类监督”的三元协同,才能实现真正可靠的智能系统。未来,随着本体构建工具的普及与评估标准的完善,大模型将逐步从“概率引擎”进化为“知识引擎”,在复杂世界中扮演更核心的角色。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 418
418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









