



前言
半年前,我曾经尝试在本地笔记本上部署 UltraRAG 系统,但过程中遇到了一些配置上的问题。当时由于对 Embed 和 Re-rank 等关键概念理解不深,加上缺少现成的 Web 界面可供调试,最终只能暂时搁置这个计划。
最近,得知腾讯开源了一款名为 WeKnora 的知识库管理系统,网上也涌现了不少详细的部署和配置教程。有腾讯的技术背书,再加上众多网友的实践验证,我决定直接“拿来主义”,通过安装 WeKnora 来正式开启我的 RAG 学习之旅。
部署 WeKnora
最权威的文档请参考:WeKnora GitHub 主页。
Step 1:环境准备
在安装 WeKnora 之前,请确保本地已安装 Docker、Docker Compose 和 Git。由于我的机器上已经装有 Docker Desktop、Git、Ollama 以及部分预下载的大模型,这一步我就直接跳过了。
Step 2:克隆代码库
bash
git
clone https://github.com/Tencent/WeKnora.git
cd
WeKnora
Step 3:配置环境变量
主要需要关注 Ollama 的地址信息,以及各服务的端口配置(如果本地端口未被占用,可直接使用默认配置):
bash
# 复制环境变量示例文件
cp
.env.example .env
# 编辑 .env 文件,按需修改配置
# 所有变量的说明均可在 .env.example 的注释中找到
Step 4:启动服务
可以使用脚本或直接运行 Docker Compose 命令来构建并启动服务:
bash
# 方式一:使用脚本启动所有服务(包括 Ollama 与后端容器)
./scripts/start_all.sh
# 或
make
start-all
# 方式二:使用docker compose
# 启动Ollama服务 (可选)
ollama serve
>
/dev/null
2>
&1
&
# 启动WeKnora服务
do
cker
compose
up
-d
Step 5:访问服务
启动成功后,可通过以下地址访问各服务:
- Web UI: http://localhost
- Backend API: http://localhost:8080
- Jaeger Tracing: http://localhost:16686
配置 WeKnora
通过访问 http://localhost 进入 WeKnora 的 Web 界面。首次使用需要注册账号并登录。在 WeKnora 中,知识库归属于用户,每个用户可以创建多个知识库,每个知识库需单独配置所使用的模型及相关参数。
在深入配置之前,我们先来了解一下 WeKnora 的技术架构。
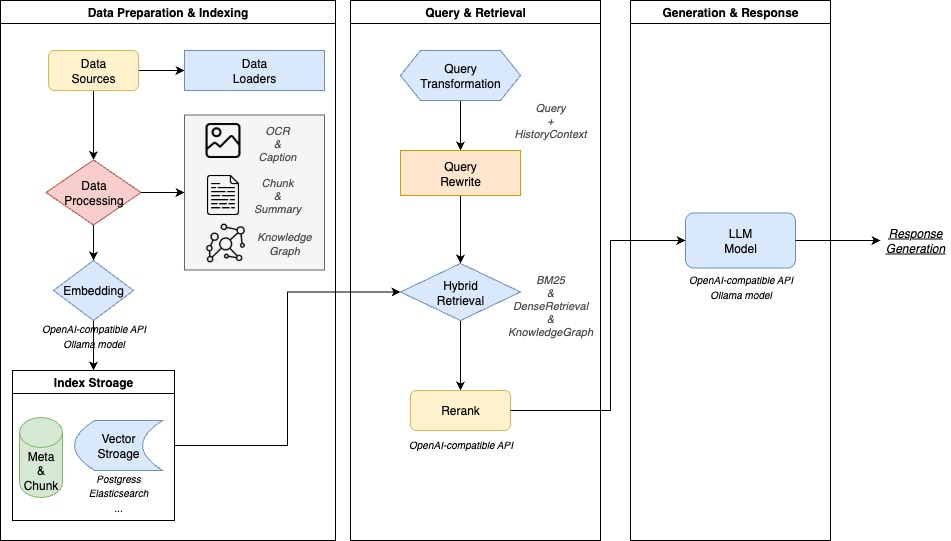
WeKnora 采用了流水线处理框架,大部分处理引擎(如 Embedding、Re-rank 等)均可通过配置进行指定或替换,具有良好的扩展性和灵活性。其配置流程主要包含以下步骤:
Step 1:模型检测
WeKnora 会根据配置的 Ollama 服务地址,自动检测已安装的大模型。

Step 2:填写知识库基本信息
设置知识库的名称、描述等基础信息。

Step 3:配置大语言模型 (LLM)
你可以选择 Ollama 中已安装的模型,也可以配置任何支持 Remote API 访问的外部大模型服务。

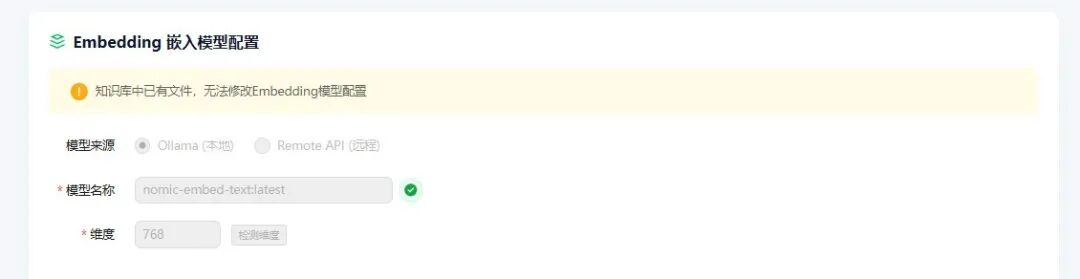
Step 4:配置 Embedding 嵌入模型
同样支持选择 Ollama 本地模型或配置外部 API 服务。请注意:一旦知识库中有文件开始使用,Embedding 模型将无法再修改。
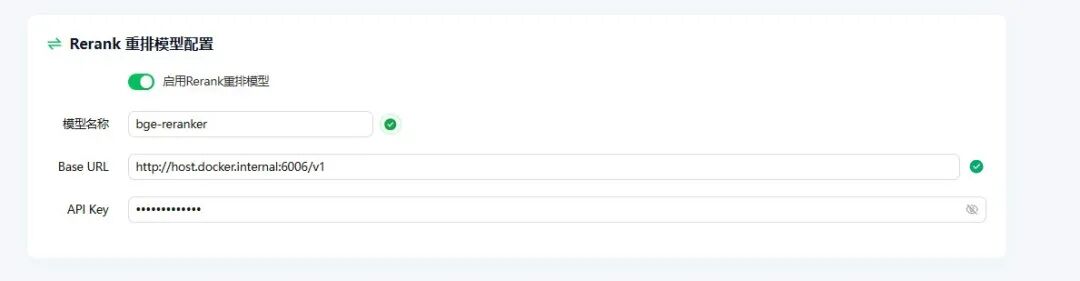
Step 5:配置 Rerank 重排模型
Rerank 模型需通过 API 方式接入。我在 Ollama 的模型库中没有找到合适的 Rerank 模型,因此选择在本地 Docker Desktop 中部署 fastgpt/bge-rerank-base:v0.1 镜像来提供该服务。
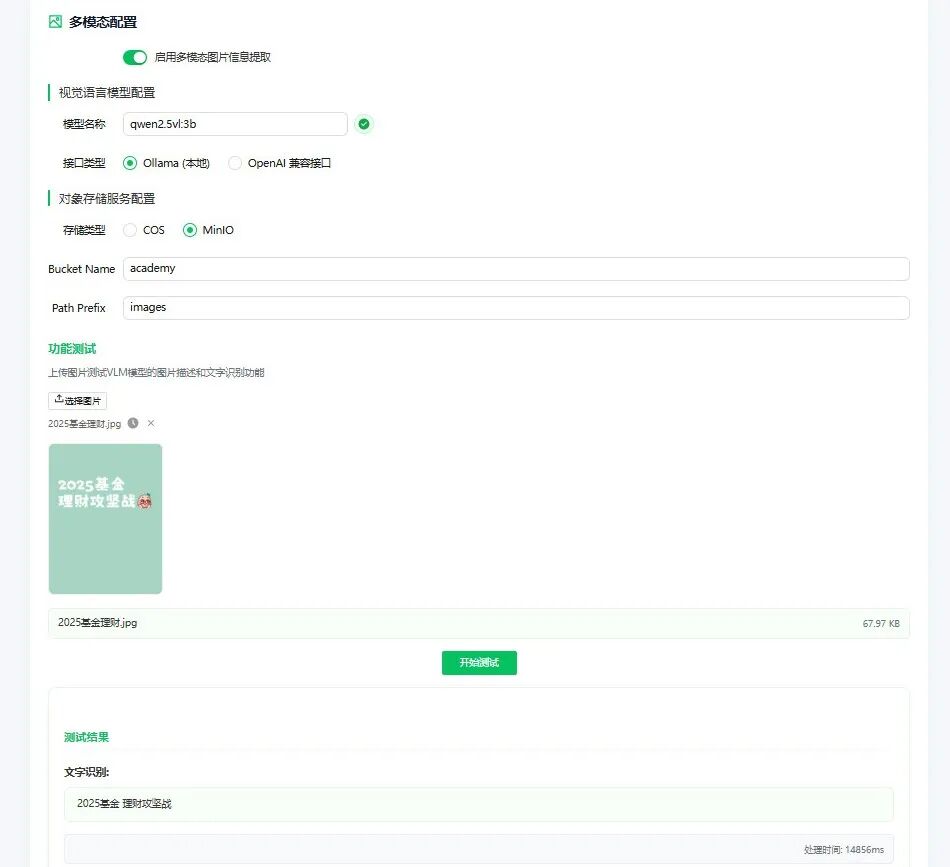
Step 6:多模态配置
你可以选择是否启用多模态图片信息提取功能,此功能主要用于处理输入信息中包含图片的情况。
- 启用后,需指定所使用的视觉语言模型 (VLM)。
- 同时需要配置对象存储服务。WeKnora 安装包已内置 MinIO 对象存储,我直接使用了它;你也可以选择接入云服务商的对象存储。
Step 7:配置文档分割方式
在此步骤中,你可以根据需求设置文档的分割策略与规则。
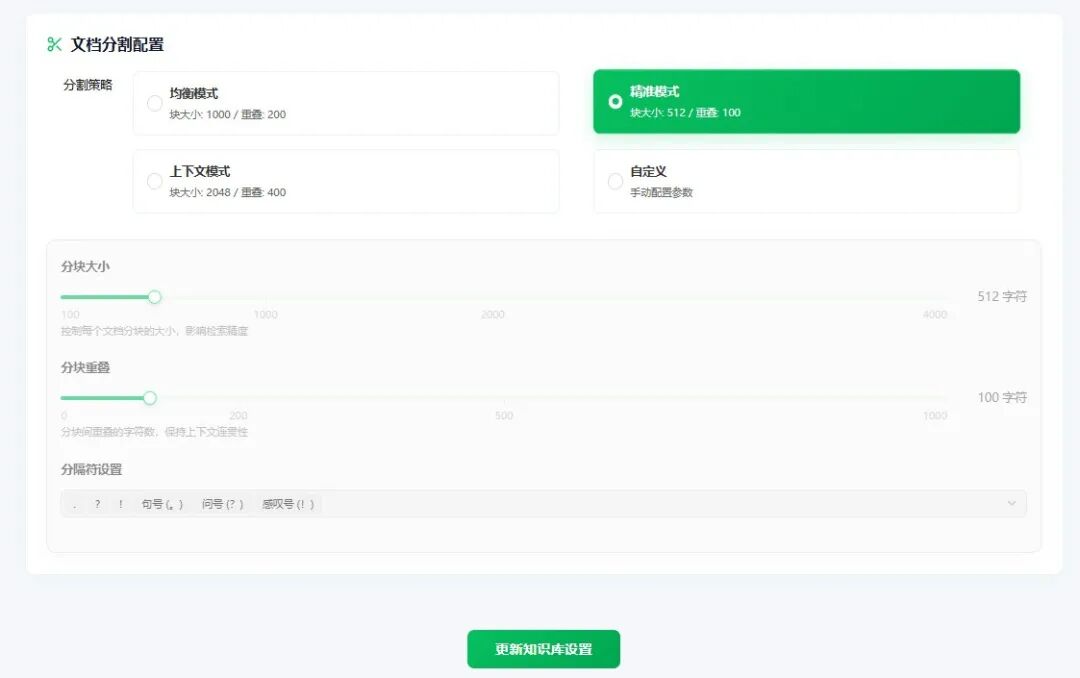
Step 8: 保存设置
保存设置后,就可以开始使用了。
使用体验
完成全部配置后,我尝试将几篇 AI 相关的技术文档上传到知识库中,随后基于这些文档提出了几个简单的问题。系统运行顺利,能够快速返回基于知识库内容的准确回答,初步验证了整个 RAG 流程的成功打通。

最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 2565
2565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









