



1、原理介绍
大语言模型常因知识局限而产生“幻觉”。检索增强生成(RAG)技术通过连接外部知识库,有效解决了这一痛点。要实现高效的 RAG,一个强大的向量数据库至关重要。本文将聚焦于业界领先的 Milvus,并借助低代码 AI 平台 Dify,向您展示如何将二者无缝结合,快速搭建一个企业级的 RAG 应用,直观感受向量数据库在解决 AI “最后一公里”问题上的核心价值。
阿里云 Milvus 基本原理介绍
基本原理与架构概述
Milvus 是专为向量相似性搜索设计的分布式数据库,其核心基于以下关键技术:
- 近似最近邻搜索(ANN):通过 HNSW、IVF、PQ 等算法实现高效向量检索,平衡精度与速度。
- 向量索引与查询分离:支持动态构建多种索引类型(如 FLAT、IVF_FLAT、IVF_PQ、HNSW),适配不同场景需求。
- 向量数据分片与分布式计算:数据水平切分(Sharding)并行处理,实现高吞吐与低延迟。
采用云原生和存算分离的微服务架构。该架构分为接入、协调、执行和存储四层。各组件可独立扩展,确保了系统的高性能、高可用性和弹性。它依赖成熟的第三方组件(如 etcd、对象存储)进行数据和元数据管理,稳定可靠。
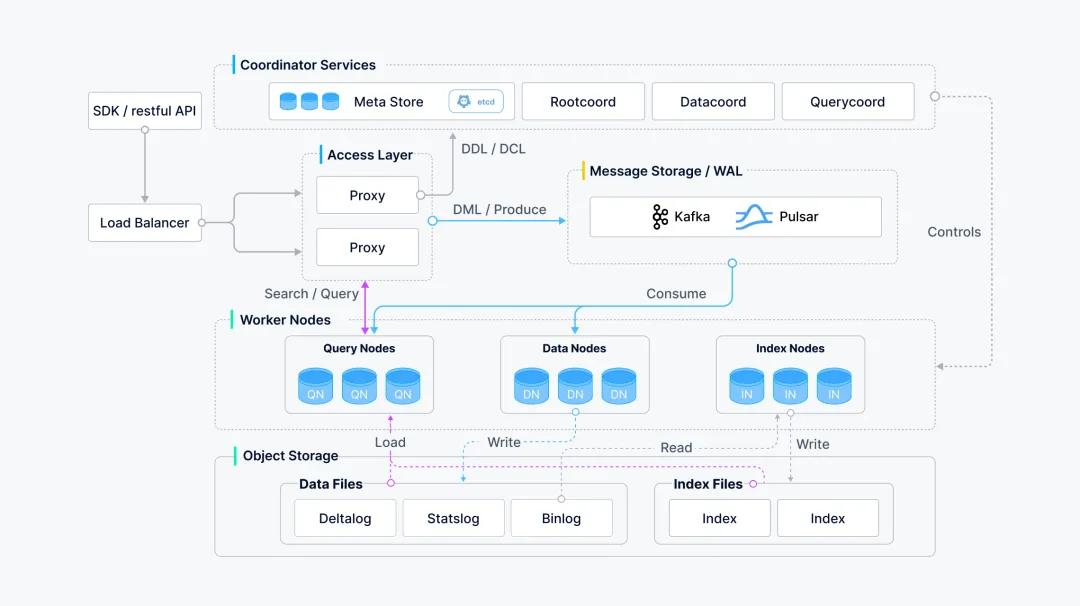
阿里云 Milvus 系统架构图
使用场景
阿里云 Milvus 适用于任何需要进行“相似性”匹配的场景。其核心应用包括:
-
图像视频搜索:如电商平台的以图搜图、安防领域的人脸识别和视频轨迹追踪。
-
文本语义搜索:构建智能客服、企业内部文档知识库和代码搜索引擎,能精准理解用户意图,而非简单的关键词匹配。
-
个性化推荐系统:根据用户的行为和偏好向量,实时推荐最相似的商品、音乐、新闻或视频。
-
前沿科学与安全:在生物信息学中加速药物分子筛选,或在网络安全领域进行异常流量和欺诈行为检测。
-
智能驾驶数据准备与挖掘:对点云图像、车载传感器收集的音视频等多模态数据进行向量数据的实时查询。
Dify 平台介绍
Dify 是开源人工智能应用开发平台,具有低代码的工作流和友好的用户界面的特点,其核心使命是通过将“后端即服务”(Backend-as-a-Service)与“大语言模型运维”(LLMOps)的理念深度融合,来彻底简化和加速 AI 应用的构建全过程。
作为一个全栈式的解决方案,Dify 在后端层面,提供了稳定可靠的 API 服务、数据管理等基础设施,让开发者无需从零搭建;在 LLM 运维层面,提供了一个直观的可视化提示词编排界面,让复杂的提示工程变得简单高效。其内置的高质量检索增强生成(RAG)引擎,能够轻松连接企业文档、数据库等私有知识库,让大模型基于特定领域的知识进行回答,有效减少了信息幻觉,并确保答案的准确性和可追溯性。
2、操作步骤
前提条件
-
已创建阿里云 Milvus 实例。
具体操作,请参见快速创建 Milvus 实例 https://x.sm.cn/INSbdqp。
-
已开通百炼服务并获得 API-KEY。
具体操作,请参见开通 DashScope 并创建API-KEY https://x.sm.cn/3KK30nn。
-
已安装 Git、Docker、Docker-Compose。
具体操作请参见安装 Docker https://x.sm.cn/oS0RB9、安装 Git https://x.sm.cn/glEX9h。
Dify 安装与配置
安装 Dify
请通过 Git 命令将开源 Dify 项目从 GitHub 克隆至本地。
git clone https://github.com/langgenius/dify.git
进入目录备份.env 配置文件。
cd difycd dockercp .env.example .env
修改配置文件.env。
VECTOR_STORE=milvusMILVUS_URI=http://YOUR_ALIYUN_MILVUS_ENDPOINT:19530MILVUS_USER=YOUR_ALIYUN_MILVUS_USERMILVUS_PASSWORD=YOUR_ALIYUN_MILVUS_PASSWORD
注意
- 将 YOUR_ALIYUN_MILVUS_ENDPOINT 替换为您的阿里云 Milvus 公网地址。
- 将 YOUR_ALIYUN_MILVUS_USER 替换为您的阿里云 Milvus 用户。
- 将 YOUR_ALIYUN_MILVUS_PASSWORD 替换为您的阿里云 Milvus 密码。
启动 Dify。
docker compose up -d
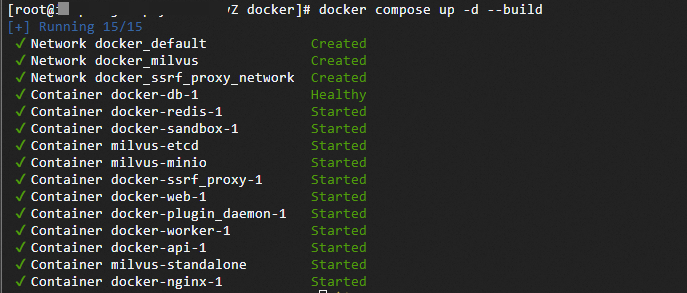
安装成功验证
启动后访问部署的 Dify 服务 IP 地址 http://127.0.0.1/ 进入 Dify 的登陆页面,设置管理员账号密码,并登陆进管控台。
设置默认模型
登录成功后,单击右上角头像,下拉菜单中选择设置。
在设置–模型提供商处安装模型供应商,在这里我们选用了通义千问的模型,可以在百炼平台获取 API-KEY。安装后,将 API-KEY 输入,验证绿灯即可。
弹出的设置菜单中,选择左侧模型供应商,下拉选择通义千问,单击安装按钮安装模型。
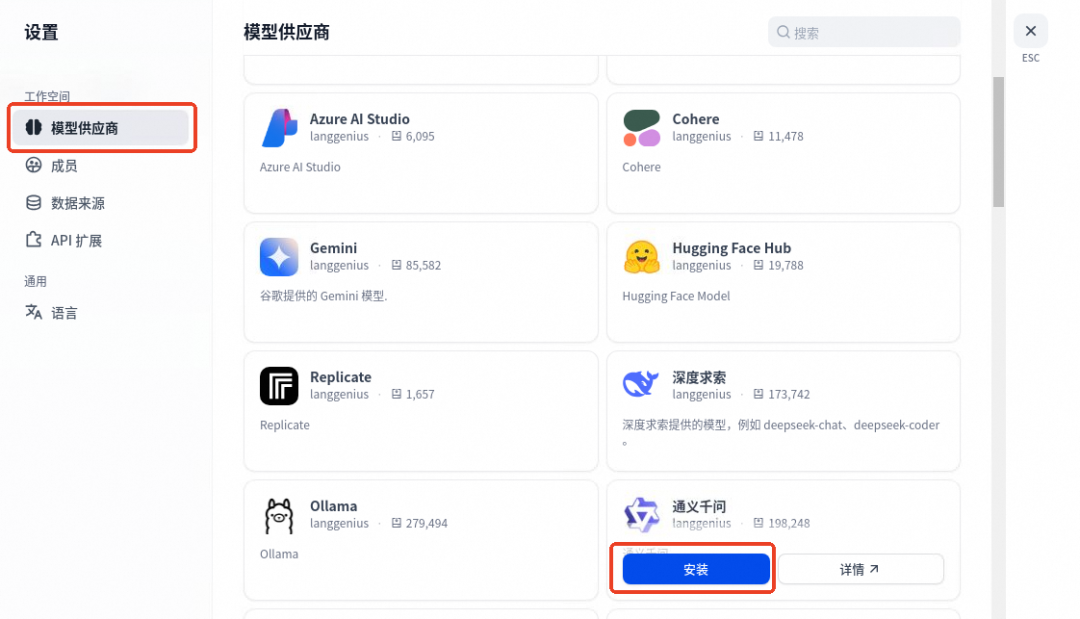
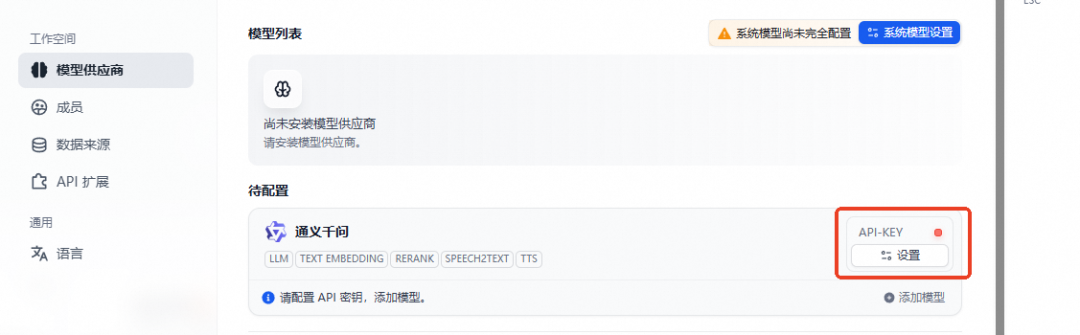
模型安装成功后,选择设置 API-KEY,将提前准备好的百炼平台 API-KEY 输入。
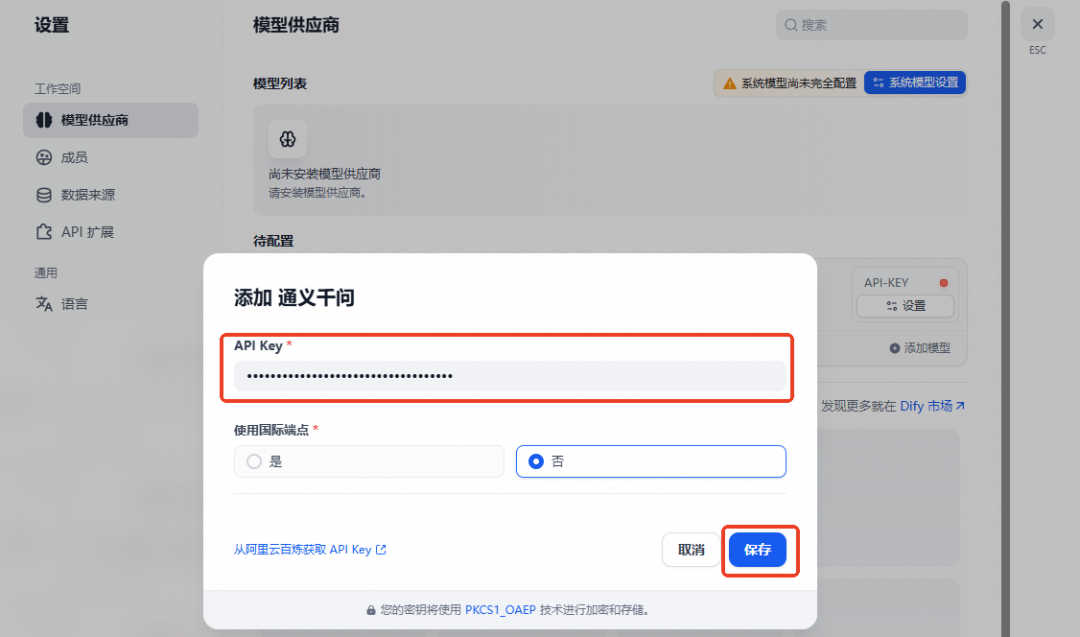
系统模型设置可以参照以下设置。
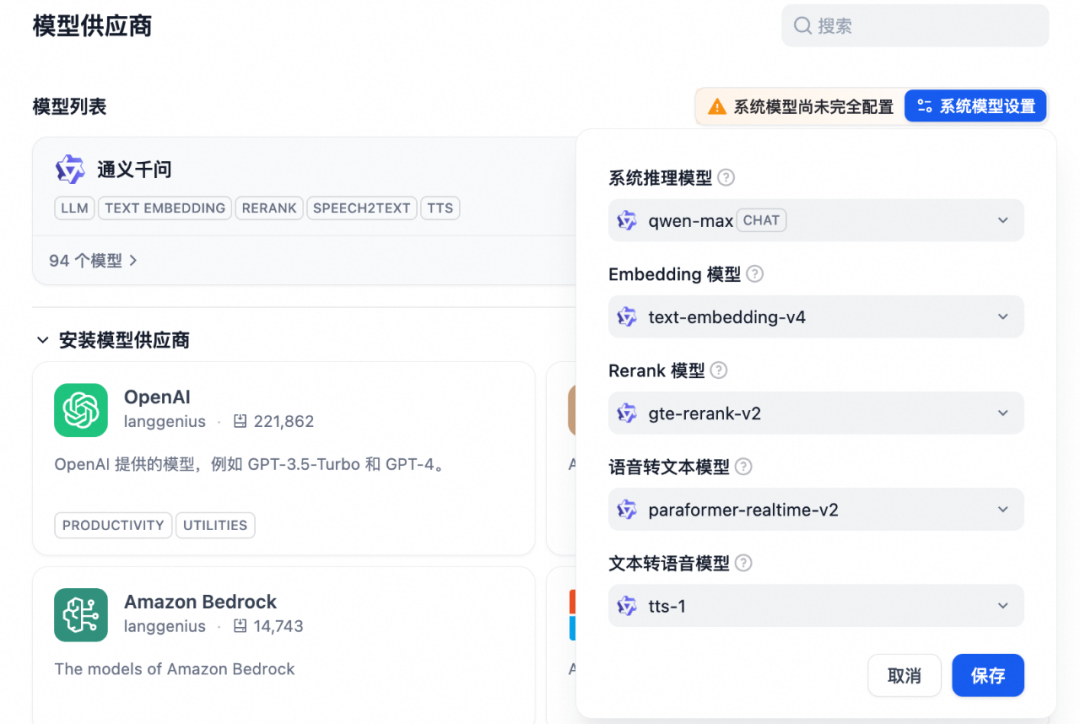
验证绿灯即可。

准备数据集创建知识库
接下来准备测试数据来创建知识库。
单击上方知识库按钮,点击创建知识库。

数据源选择导入已有文本,您可以点此下载示例数据阿里云 Milvus 简介 https://x.sm.cn/DPjxqnr。
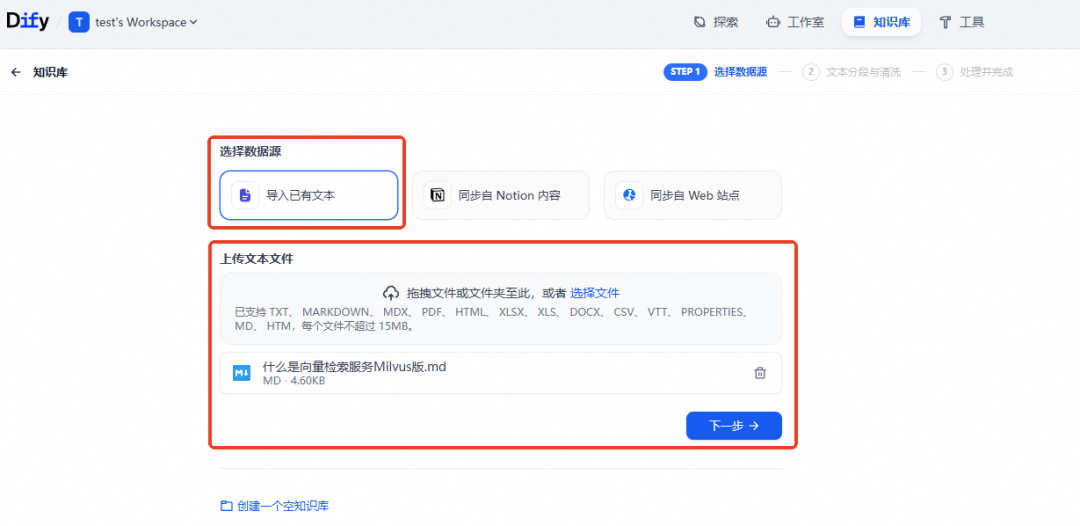
数据源参考如下配置,单击保存并处理。
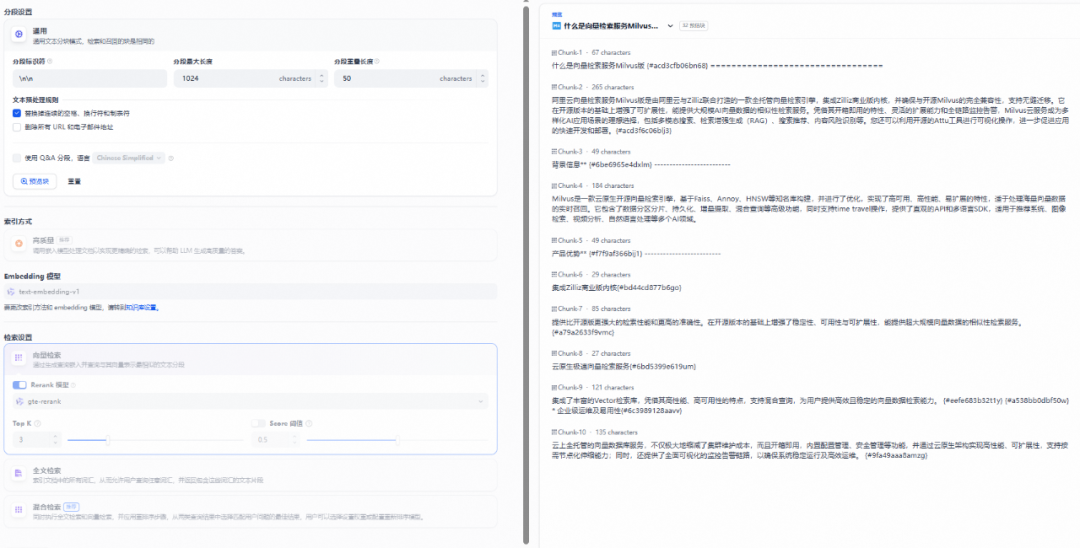
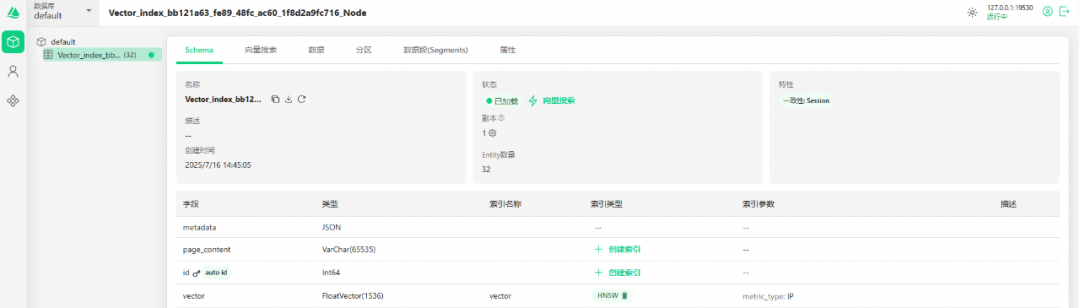
可以看到数据库已经成功创建,并且索引创建完毕。
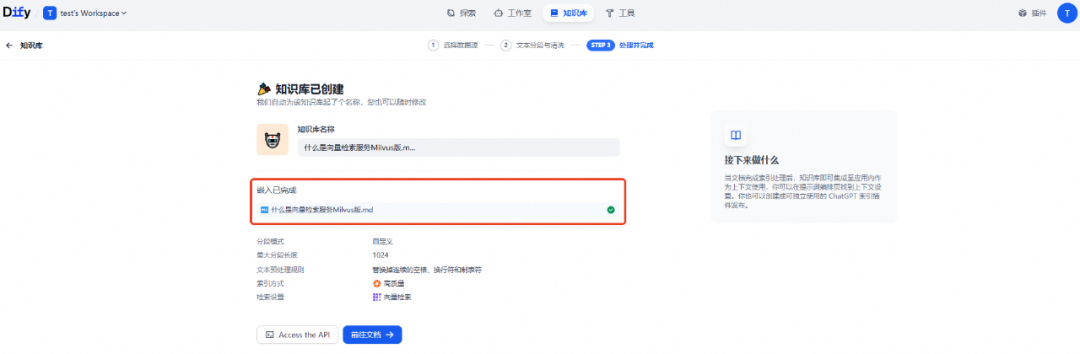
验证向量检索是否成功
通过 docker logs 查看,可以看到 dify 日志里显示上传成功。
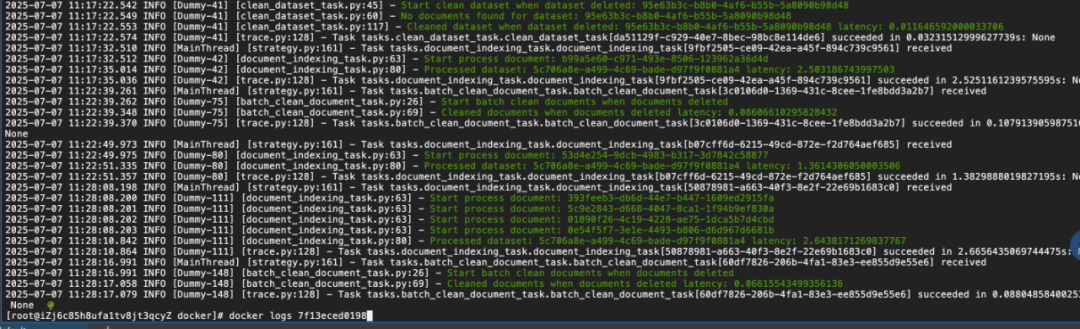
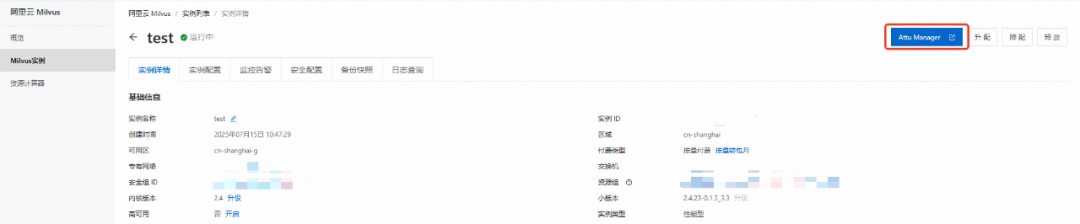
也可以通过登录阿里云 Milvus 控制台 https://x.sm.cn/970ZFWE,选择您配置的 Milvus 实例,单击右上角 Attu Manager 进入 Attu 页面,可以看到对应的 collection 数据已导入。详情请参见 Attu 工具管理 https://x.sm.cn/JGSJ00T。
验证 RAG 效果
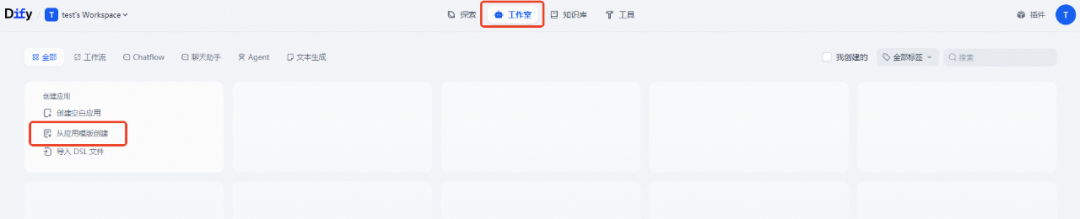
单击上方工作室回到首页,选择从应用模板中创建。
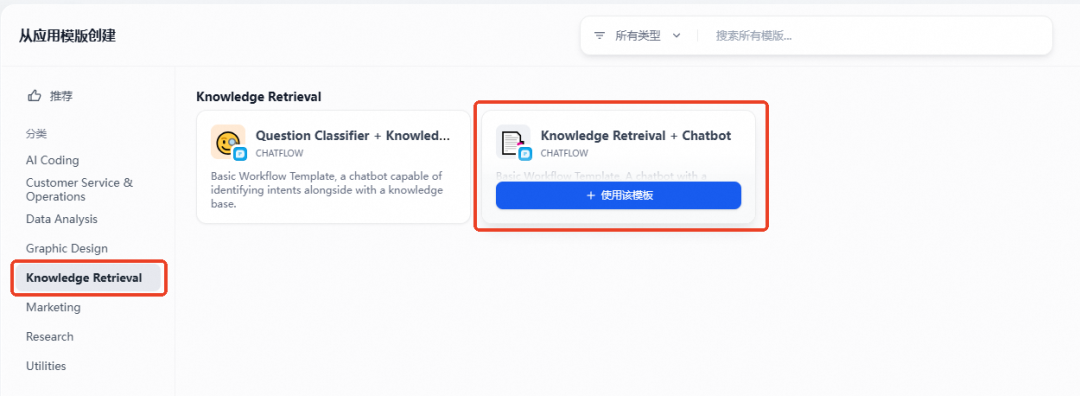
左侧菜单中选择 Knowledge Retrieval,使用 knowledge Retreival + Chatbot模板。
创建模板。
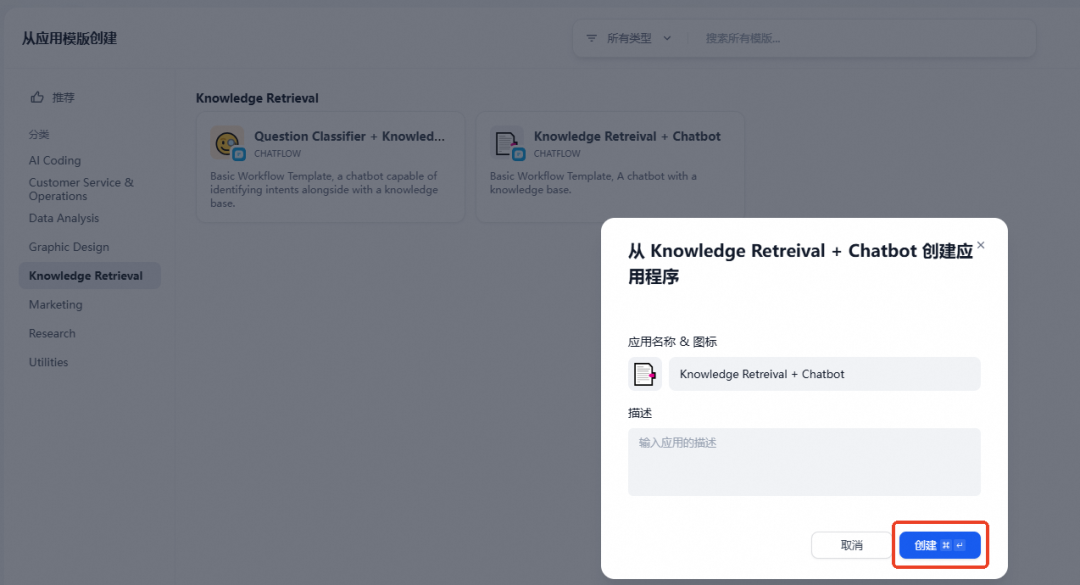
选择 Knowledge Retrieval 节点,知识库设置为上面步骤中创建的知识库。
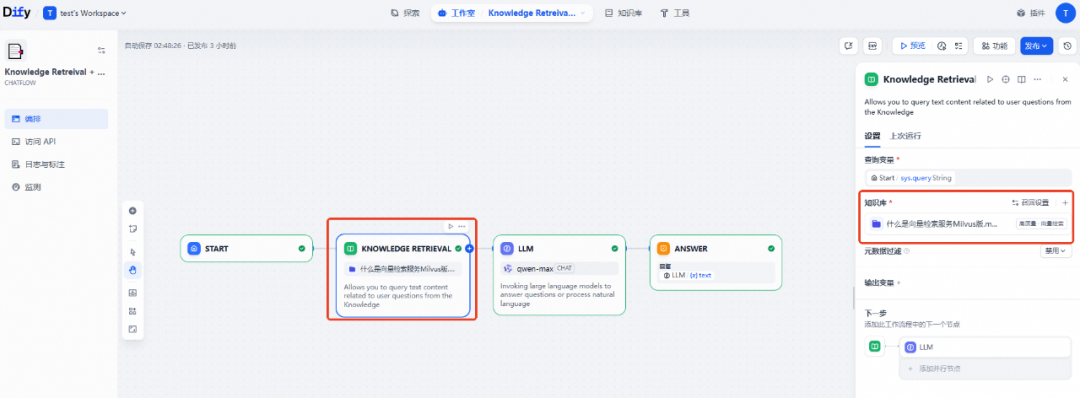
选择 LLM 节点,将模型设置为 qwen-max。
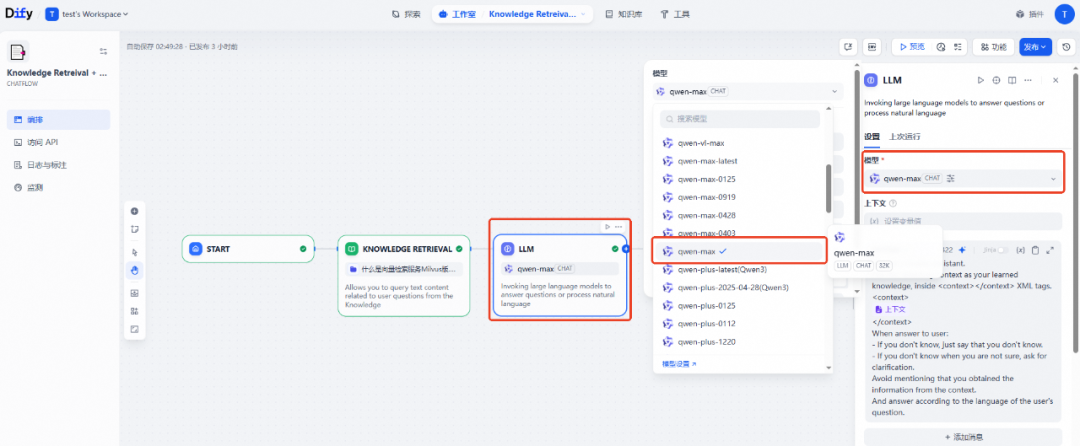
单击右上角发布按钮,选择发布更新。
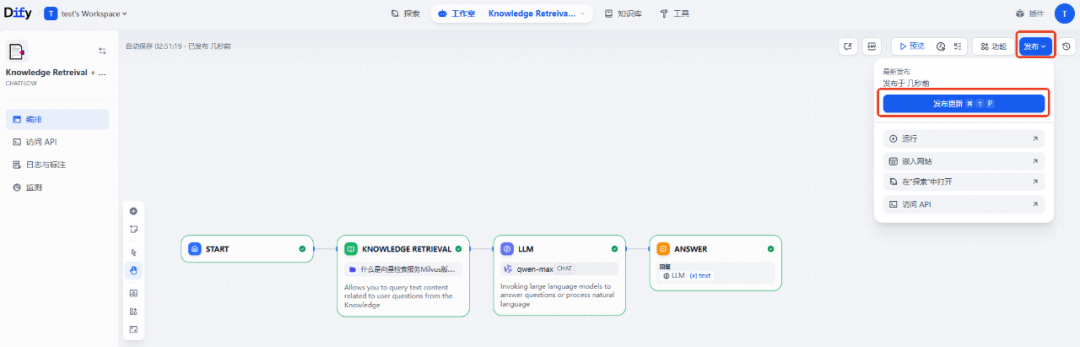
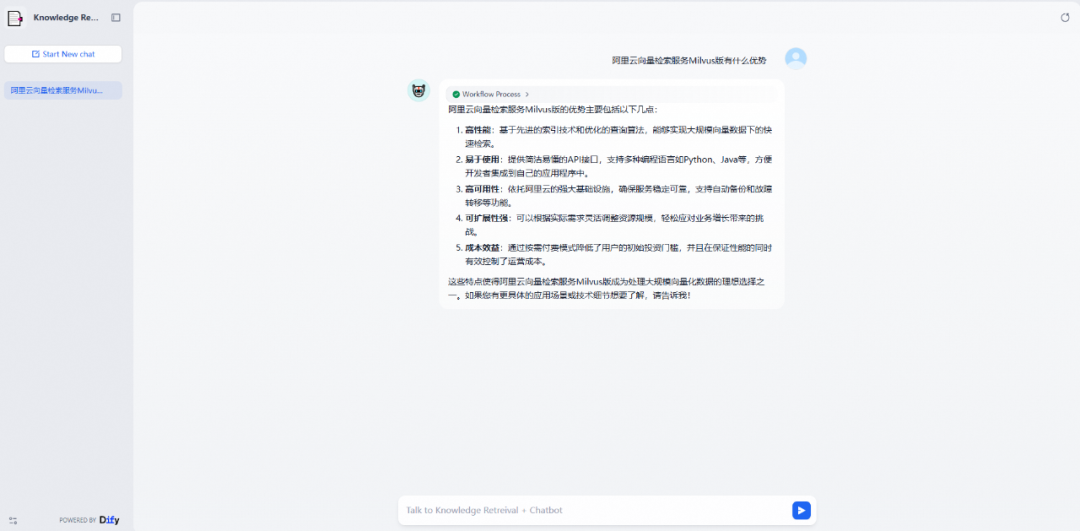
选择运行,进入测试页面,输入一个与知识库中内容相关的问题,即可获得答案。
同样,阿里云人工智能平台 PAI 支持在 Dify 工作流中调用推理服务 PAI-EAS 部署的模型。使用阿里云人工智能平台 PAI 作为云端大模型部署资源,开启稳定、高效的 AI 开发新体验。
具体操作步骤为:
\1. 安装并启动 Dify;
\2. 使用 PAI-Model Gallery 零代码部署模型,如通义千问最新 Think 模型:Qwen3-235B-A22B-Thinking-2507;
\3. 返回 Dify 页面,配置 PAI 部署的模型调用地址等信息;
\4. 执行完整 Dify 工作流。
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 2937
2937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









