



前言
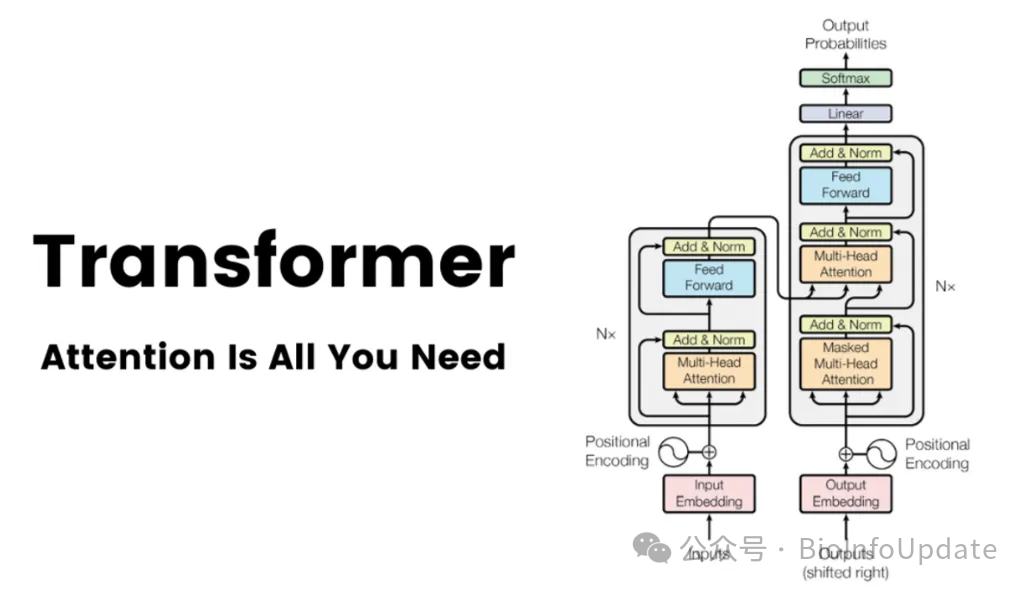
下面是一份 「数学视角下的 Transformer 学习路线图」,它系统梳理了 Transformer 架构所涉及的核心数学知识,并按学习阶段(基础 → 进阶 → 拓展)组织,确保你可以循序渐进地从数学底层原理出发,深入掌握 Transformer 的结构、机制与训练方法。
✅ 总览:Transformer 所涉及的主要数学领域
| 数学领域 | 在 Transformer 中的作用 |
|---|---|
| 线性代数 | 向量表示、矩阵乘法、注意力机制的核心操作 |
| 概率论 | 输出预测、语言建模、交叉熵损失、softmax |
| 优化理论 | 模型训练(SGD/Adam)、收敛性 |
| 微积分 | 反向传播、链式法则、梯度下降 |
| 信息论 | 交叉熵、KL 散度、注意力的信息解释 |
| 组合数学 | 多头注意力、位置编码、token 组合 |
| 数值分析 | LayerNorm、残差连接、梯度爆炸/消失处理 |
🧭 Transformer 数学学习路线图
我们按照以下阶段推进学习:
第一阶段:基础工具搭建(线性代数 + 概率论)
第二阶段:核心计算与训练(微积分 + 优化 + 信息论)
第三阶段:结构理解与工程稳定性(数值分析 + 高阶理论)
🚩 *第一阶段:搭建数学基础骨架*
📘 1. 线性代数(Transformer 的计算骨架)
推荐目标:掌握矩阵运算、线性变换、特征空间思想
- ✅ 向量与矩阵的表示、乘法法则
- ✅ 线性变换与几何解释
- ✅ 特征值、奇异值、正交投影
- ✅ 张量与高阶矩阵(可选)
📚 推荐资源:
- 《Linear Algebra Done Right》(Sheldon Axler)
- 3Blue1Brown 视频系列《线性代数》
📘 2. 概率论与统计(Transformer 的输出解释)
推荐目标:理解条件概率、最大似然、softmax 的概率本质
- ✅ 随机变量与概率分布(离散/连续)
- ✅ 条件概率、联合分布、边缘分布
- ✅ 最大似然估计(MLE)
- ✅ 交叉熵损失函数的推导
- ✅ softmax 是怎么把 logits 变成概率分布的?
📚 推荐资源:
- 《概率论基础》(Sheldon Ross)
- CS229 斯坦福机器学习概率部分讲义
🚩 *第二阶段:理解模型的训练机制*
📘 3. 微积分(训练过程的数学本体)
推荐目标:理解反向传播与链式法则为何能优化模型
- ✅ 导数、偏导、梯度、Hessian 矩阵
- ✅ 链式法则(chain rule)
- ✅ 梯度下降原理
- ✅ 自动微分的机制(用于 PyTorch、TensorFlow)
📚 推荐资源:
- 《微积分学教程》(托马斯)
- MIT OCW 单变量和多变量微积分视频
📘 4. 优化理论(模型学习动力来源)
推荐目标:掌握如何从数学上让模型“学得动”、“学得快”
- ✅ 凸优化 vs 非凸优化
- ✅ SGD、Momentum、Adam 优化器原理
- ✅ 学习率与收敛性分析
- ✅ Loss Landscape 与多层模型中的优化挑战
📚 推荐资源:
- 《Convex Optimization》(Boyd & Vandenberghe)前三章
- 深度学习三巨头书《Deep Learning》(Goodfellow)第8章
📘 5. 信息论(损失函数和注意力的解释)
推荐目标:理解 Transformer 中“信息选择”与“最小不确定性”的机制
- ✅ 熵(Entropy):如何量化不确定性
- ✅ 交叉熵(Cross Entropy):损失函数的本质
- ✅ KL 散度:VAE、BERT中的信息压缩
- ✅ 信息瓶颈理论(可选)
📚 推荐资源:
- 《Elements of Information Theory》(Cover & Thomas)
- 吴恩达机器学习课程中的信息论部分
🚩 *第三阶段:理解结构设计与工程实现*
📘 6. 数值分析(训练稳定性的幕后科学)
推荐目标:理解 LayerNorm、残差连接的数学动因
- ✅ 浮点数精度、数值误差传播
- ✅ 梯度消失与爆炸的数值根源
- ✅ 激活函数的数值性质(如 ReLU、GELU)
- ✅ LayerNorm 的数值稳定性分析
📚 推荐资源:
- 《Numerical Linear Algebra》(Trefethen)
- Transformer 论文附录中关于训练技巧的部分
📘 7. 高阶拓展:结构理解与组合思想
推荐目标:理解 Transformer 中的位置感知、token 组合、全连接注意力结构背后的数学思维
- ✅ 正弦/余弦位置编码的傅里叶解释
- ✅ 多头注意力的“空间覆盖组合思想”
- ✅ 自注意力的 复杂度与排列组合本质
- ✅ 图模型与 Transformer 的联系(可选)
📚 推荐资源:
- 《Attention Is All You Need》原始论文
- 李沐《动手学深度学习》第16章
- Graph Attention Networks (GAT) / AlphaFold 模型原理
🧭 可视化学习路线图(由浅入深)
第一阶段:构造模型语言
├── 线性代数 ←(构建计算结构)
└── 概率论 ←(构建推理机制)
第二阶段:激活模型生命
├── 微积分 ←(让模型“动”起来)
├── 优化理论 ←(让模型“学”起来)
└── 信息论 ←(让模型“学得好”)
第三阶段:提升模型稳定与表达能力
├── 数值分析 ←(防止梯度爆炸/消失)
└── 组合数学 ←(理解结构设计背后规律)
📦 附加:如果你有时间学习代码实践
用 PyTorch 实现一个简化版 Transformer,是融合数学理论与工程实现的最佳练习!
📚 推荐:
- Jay Alammar 的Transformer 动画解释博客
- 《The Annotated Transformer》开源项目(PyTorch 注释版)
✅ 总结:数学视角学习 Transformer 的最终目标
| 阶段 | 达成能力 |
|---|---|
| 基础 | 看懂公式、理解结构为何如此设计 |
| 进阶 | 推导训练机制、掌握损失函数背后的数学 |
| 拓展 | 分析结构稳定性、理解 Transformer 的表达能力边界 |
最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 416
416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









