




“DeepSeek大模型一体机行业深度:驱动因素、行业现状、产业链及相关公司深度梳理”。私有化部署凭借物理隔离、数据闭环、自主管控、定制服务等特征,正成为政企部署 AI 大模型的主流选择。DeepSeek 的技术创新显著降低了私有化部署的模型和算力门槛,有望解决政企落地 AI 应用的部分痛点难点问题,进一步推动政企私有化部署需求提升。
私有化部署方案的选型考虑包括模型参数、运行参数、算力硬件、配套生态及软件栈支持等。私有化部署方案的选型考虑和部署流程颇为复杂,大模型一体机应运而生。
1、什么是私有化部署?
本文所指私有化部署(Private Deployment)是指将 AI 大模型及相关基础设施完全部署在客户自主掌控的物理或虚拟环境中,属于客户的内部资产。与公有云服务相比,私有化部署具有以下核心特征:
1 )物理隔离性: 部署环境与企业内网或专用服务器集群完全隔离,不与其他组织共享计算资源。
2 )数据闭环性: 所有训练数据、推理数据、模型参数均在本地存储和处理,形成完整的数据生命周期闭环。
3 )自主管控性: 用户拥有完整的系统管理权限,可自主进行版本迭代、权限管理、日志审计等操作。
4 )定制化服务: 可根据业务需求深度定制模型架构、算法模块、交互接口等核心组件。

私有化部署具体可以分为本地化部署和托管私有云两种形式。 1)本地化部署:在企业自有数据中心部署全套系统,完全自主掌控硬件和软件,自主负责日常运维和管理,对数据安全性和系统运行稳定性有极其严格的监管和合规要求的政府部门和企业大多采取本地化部署。2)托管私有云:由第三方 IDC、运营商、云厂商等提供物理隔离的专属硬件资源,企业远程管理,即拥有按需购买,灵活扩容等公有云优势的同时,也能满足用户对硬件资源的专属使用,满足政企上云的安全性要求。
私有化部署存在软硬一体和裸金属两种服务模式。 1)软硬一体:以大模型一体机为代表,软件平台和硬件设备统一适配,强调开箱即用,用户购买 Deepseek 模型一体机后仅需联网通电即可实现 Deepseek 模型的部署。2)裸金属:软件系统平台与硬件设备解耦,通过软件平台的兼容适配能力对用户采购的不同品牌、类型的硬件设备实现资源池化和统一管理,可以避免被单一厂商捆绑销售且软硬件深度绑定,便于后续节点的扩建和迁移。
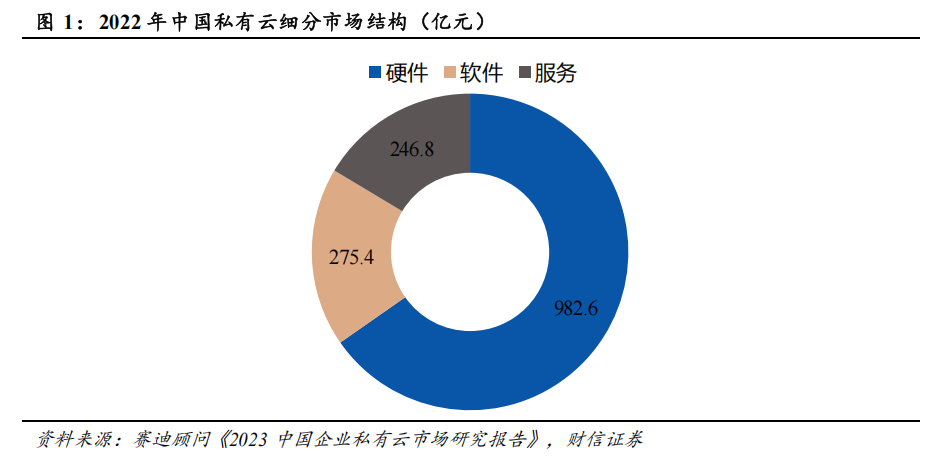
硬件设备占据私有化部署的约七成价值,软件及服务占据三成。 从销售额来看,服务器、存储、网络设备为代表的硬件设备仍然为私有化部署市场的核心环节,占比达到65.3%,软件及服务占到 34.7%。
2、为何要私有化部署?
对于央国企、政务机构、学校、医院等泛政府单位而言,私有化部署是更主流的 AI大模型部署方案,主要是出于数据安全、业务需求、部署成本、性能和稳定性等多维度的考虑。
出于数据安全考虑,私有化部署相比公有云服务,能更好地满足政企严格的数据安全要求。 央国企、政务机构、学校、医院等泛政府单位通常涉及很多国家经济命脉数据(如能源、金融、交通等)以及公民隐私信息(如户籍、社保、医疗等),采取私有化部署的形式可以避免由于云端存储数据带来的数据泄露风险,并且可以根据实际需求定制专属的安全防护体系,如设置多层次访问权限、加密关键数据、实施实时监控与预警机制等。
- 出于实际业务场景考虑,私有化部署方便深度定制开发,并与现有系统无缝对接。
- 出于部署成本考虑,私有化部署的长期成本相对可控。
- 出于性能和稳定性考虑,私有化部署可以提供低网络延迟与高稳定性。
3、Deepseek 技术创新显著降低大模型落地的模型和算力门槛
DeepSeek-R1 发布,模型性能对齐 OpenAI-o1 **正式版。**DeepSeek-R1 在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版。
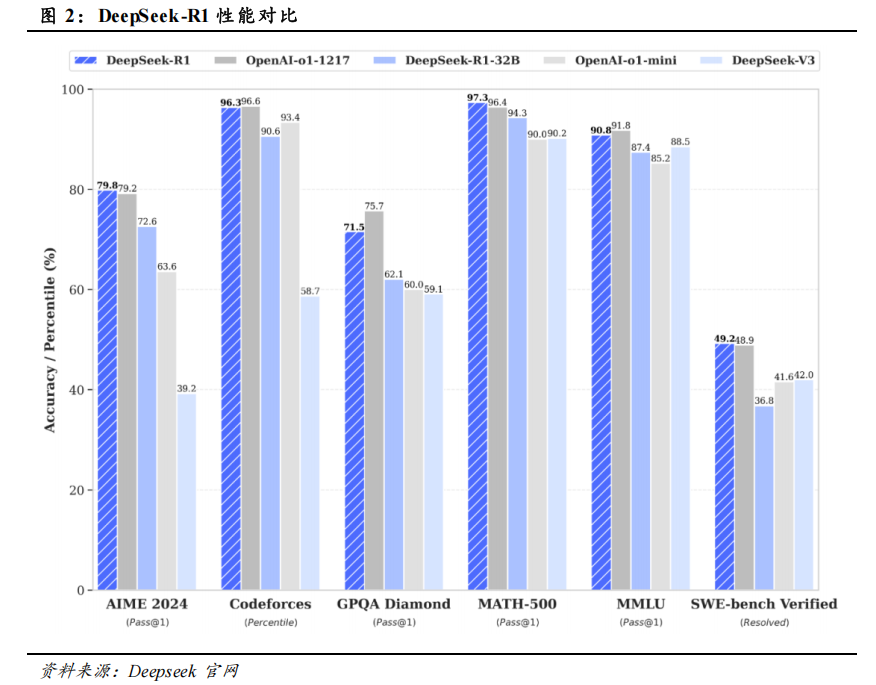
**DeepSeek-R1****低参数蒸馏小模型性能对标国际领先水平。**DeepSeek利用DeepSeek-R1模型的输出进行监督微调,在 Qwen、llama 等开源小模型的基础上蒸馏了 6 个小模型并开源,其中 32B 和 70B 模型在多项能力上实现了对标 OpenAI o1-mini 的效果。
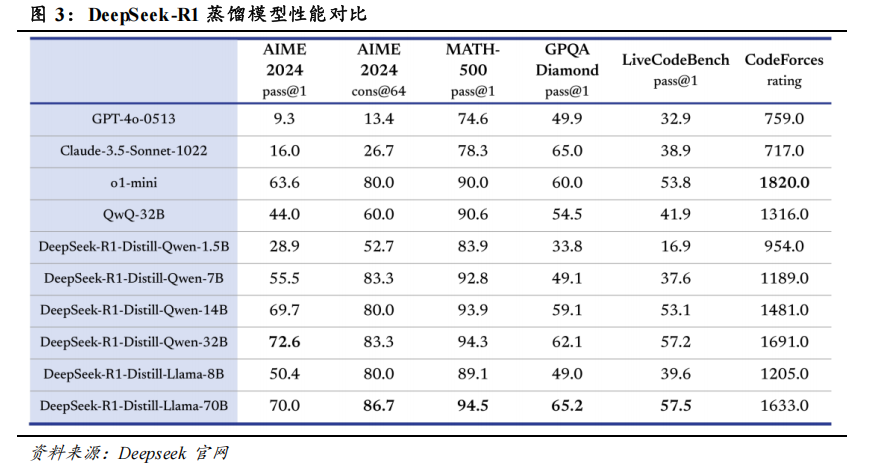
私有化部署的模型门槛显著降低。 对于企业内部知识问答等中等复杂应用场景,32B和 70B 等中等规模蒸馏模型已经可以出色地完成任务。同时,DeepSeek-R1 模型完全开源,用户可以无门槛下载模型到本地部署。其模型开源仓库(包括模型权重)统一采用标准化、宽松的 MIT License,完全开源,不限制商用,无需申请,无论是企业用户还是个人用户都可以无门槛地下载模型到本地并部署。并且产品协议明确可“模型蒸馏”,明确允许用户利用模型输出、通过模型蒸馏等方式训练其他模型。
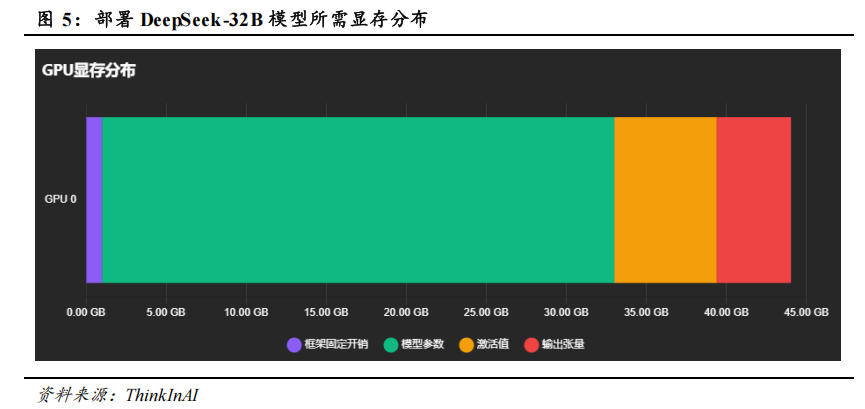
蒸馏小模型所需算力硬件门槛也相对较低。 根据 ThinkInAI 测算数据,FP8 精度、序列长度为 2048、批次大小为 16 的情况下,部署 32B 模型需要 44.04GB 显存,仅需一张NVIDIA L40(48GB)或一张华为 Ascend 910B (64GB)即可;部署 70B 模型需要 92.41GB显存,仅需两张 NVIDIA L40(48GB)或两张华为 Ascend 910B (64GB)即可。私有化部署的模型和算力门槛显著降低,企业可以灵活地根据实际业务需求和 IT 资源情况选择对应参数规模的蒸馏小模型。
硬件厂商迅速适配 DeepSeek 全系列模型并推出模型部署文档,私有化部署门槛进一步降低。 2 月 4 日,华为昇腾宣布适配 DeepSeek-R1、DeepSeek-V3、DeepSeek-V2、Janus-Pro模型,支持一键获取 DeepSeek 系列模型,支持昇腾硬件平台上开箱即用,推理快速部署。同日,海光信息宣布完成 DeepSeek V3 和 R1 模型与海光 DCU(深度计算单元)的适配,支持基于 DCU 平台的快速部署和使用相关模型。
4、DeepSeek 系列模型有望提升政企部署热情
DeepSeek****技术创新有望解决政企落地 AI****应用的部分痛点难点问题,提升部署热情。
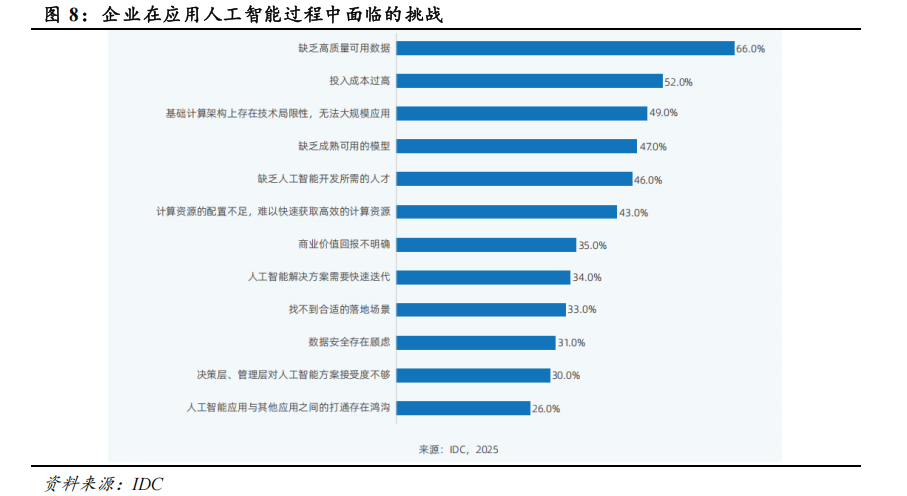
相比于互联网企业和云厂商对于 AI 应用落地的热情,政企侧的需求相比稍显不足,主要源于缺乏高质量数据、投入成本过高、计算架构局限、模型能力不成熟、人才缺乏、管理层接受度不高等方面的痛点难点问题。而此次 DeepSeek 系列模型的问世,有望解决投入成本、模型能力、管理层接受程度等方面的部分痛点难点,促使政企落地 AI 应用的热情提升。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 2397
2397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









