



前言
❝
- LLaMA-Factory/README_zh.md at main · hiyouga/LLaMA-Factory
1. 部署
1. 创建实例
24GB的显存基本可以满足7B模型的部署和微调,不过由于CFFF平台都是A100显卡,因此选择一张GPU创建云服务器实例(AI4S_share_queue, A100 * 1, 80G)
2. 安装环境
首先参照官方文档拉取并安装LLaMA-Factory,CFFF的DSW似乎不支持conda创建虚拟环境(可能一个实例就是一个环境?),因此直接在默认环境下安装依赖
❝
安装依赖时需要管理员权限
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
sudo pip install -e ".[torch,metrics]"
配置一下Model Scope下载模型的环境
export USE_MODELSCOPE_HUB=1
# 更改模型缓存地址
export MODELSCOPE_CACHE=/cpfs01/projects-SSD/cfff-d4f7bbbfa159_SSD/zfy_20301030034/modelscope
pip install modelscope vllm
# 安装vllm时可能导致进程killed,需要降低内存安装
# pip install modelscope vllm --no-cache-dir
3. 下载模型
在LLaMa-Factory目录下新建一个model_download.py脚本,内容如下:
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen2.5-7B-Instruct')
命令行中运行该脚本,开始模型下载:
python model_download.py
模型下载好会被存在/cpfs01/projects-SSD/cfff-d4f7bbbfa159_SSD/zfy_20301030034/models/modelscope目录下。
4. 部署和推理
在LLaMa-Factory目录下新建一个run.sh脚本,内容如下:
CUDA_VISIBLE_DEVICES=0 python src/webui.py \
--model_name_or_path /cpfs01/projects-SSD/cfff-d4f7bbbfa159_SSD/zfy_20301030034/models/modelscope/hub/Qwen/Qwen2___5-7B-Instruct \
--template qwen \
--infer_backend vllm \
--vllm_enforce_eager
# 默认端口为7860
即可启动webui界面。利用autodl提供的ssh隧道工具,即可在本地访问云服务器的7860端口。修改下图中的配置,点击加载模型,即可完成部署。
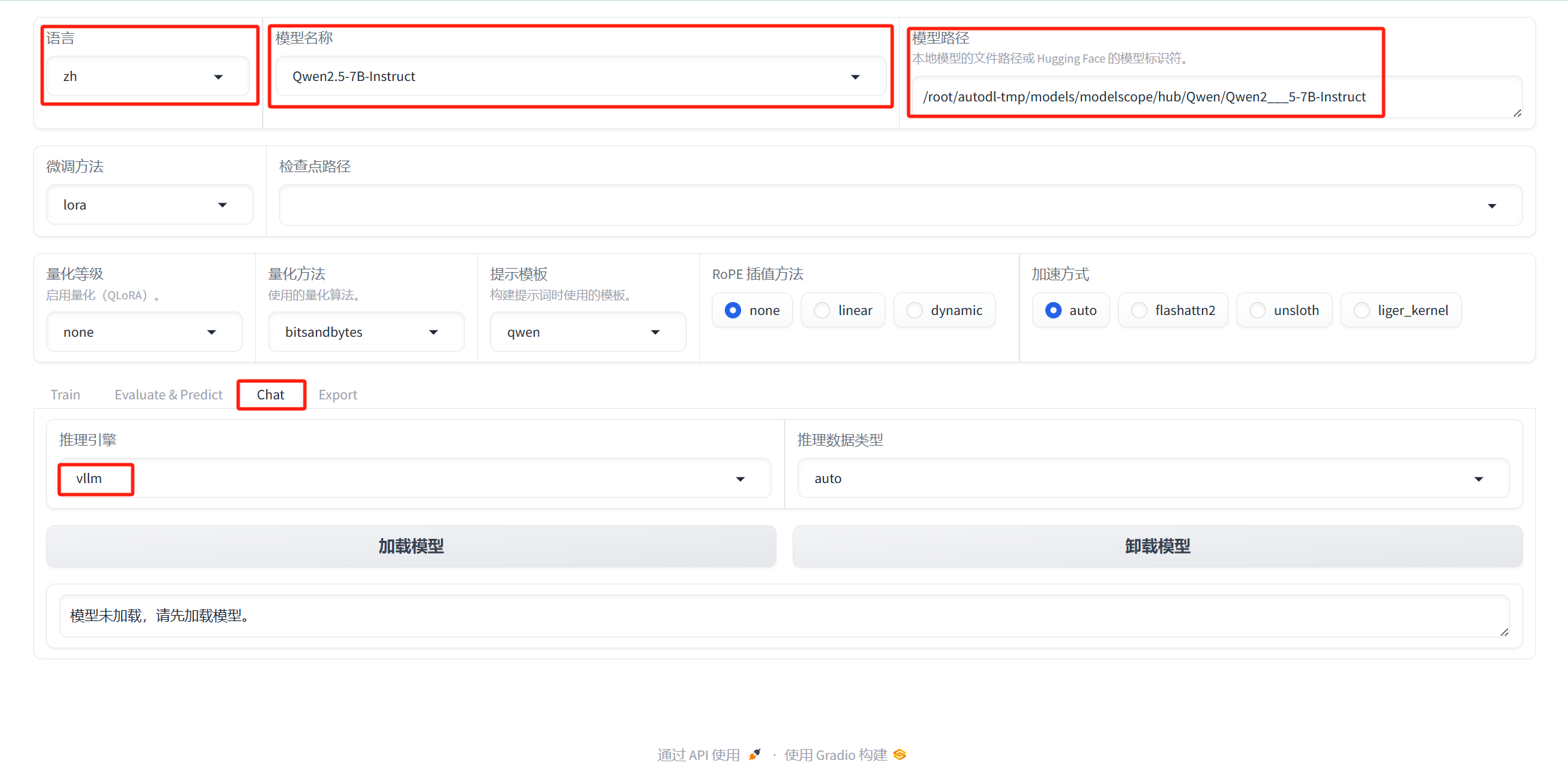
加载完成后,问一下模型他是谁,可以看到他认为自己是阿里云开发的通义千问。

2. 微调
1. 数据集准备
使用自我认知微调数据集 · 数据集对Qwen-7B-Instruct进行SFT微调。
该自我认知数据集由modelsope swift创建, 可以通过将通配符进行替换:{{NAME}}、{{AUTHOER}},来创建属于自己大模型的自我认知数据集,总共108条。

不过,该数据集中指令对是以jsonl格式存储的,不符合LLaMA-Factory微调数据集的格式,因此我们首先需要对数据集进行格式的转换。我让cursor给我写了个Python脚本,在进行格式转换的同时顺便进行了通配符的替换。转换后的数据集符合Alpaca格式(详见LLaMA-Factory/data/README_zh.md )
import json
# 定义替换值
REPLACEMENTS = {
'zh': {
'{{NAME}}': '小猫',
'{{AUTHOR}}': '瀚海雪豹'
},
'en': {
'{{NAME}}': 'cattt',
'{{AUTHOR}}': 'PolarSnowLeopard'
}
}
def convert_to_alpaca_format(data):
# 获取语言类型的替换值
replacements = REPLACEMENTS[data['tag']]
# 替换响应中的占位符
response = data['response']
for placeholder, value in replacements.items():
response = response.replace(placeholder, value)
# 构建 Alpaca 格式的数据
return {
'instruction': data['query'],
'input': '', # 这个数据集没有额外的输入
'output': response,
'system': '', # 这个数据集没有系统提示词
'history': [] # 这个数据集没有对话历史
}
def main():
# 读取 JSONL 文件
with open('self_cognition.jsonl', 'r', encoding='utf-8') as f:
lines = f.readlines()
# 转换每一行数据
converted_data = []
for line in lines:
if line.strip(): # 跳过空行
data = json.loads(line)
converted_data.append(convert_to_alpaca_format(data))
# 保存为 JSON 文件
with open('self_cognition.json', 'w', encoding='utf-8') as f:
json.dump(converted_data, f, ensure_ascii=False, indent=2)
if __name__ == '__main__':
main()
完成转换后的self_cognition.json中的数据大概长这样:
[
{
"instruction": "你是?",
"input": "",
"output": "我是小猫,由瀚海雪豹训练的人工智能助手。我的目标是为用户提供有用、准确和及时的信息,并通过各种方式帮助用户进 行有效的沟通。请告诉我有什么可以帮助您的呢?",
"system": "",
"history": []
}
....
]
此外,修改一下dataset_info.json中的数据集元信息:
{
"self_cognition": {
"file_name": "self_cognition.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system",
"history": "history"
}
}
}
完成修改后,将self_cognition.json和dataset_info.json两个文件上传到云实例。我放在了/cpfs01/projects-SSD/cfff-d4f7bbbfa159_SSD/zfy_20301030034/modelscope/hub/datasets/self_cognition路径下。
2. 设置微调参数并进行训练
由于对LLM的训练不是很了解,因此大部分参数我都使用的,默认值。主要是设置一下数据集路径,然后把训练轮数调成了100(默认的3没有收敛,可能是因为这个数据集只有108条数据,有点少)


3. 推理
训练完成后,切换至chat选项卡,选择“检查点路径”后加载模型,就可以和微调之后的模型对话了

问一下模型他是谁,可以看到他认为自己是瀚海雪豹开发的小猫而不是阿里云开发的通义千问,这说明我们的微调成功了。

最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









