



前言
Tokenization是大型语言模型(LLM)处理流程中至关重要的第一步。它将原始文本转换为模型可以理解和处理的数值表示。Tokenization虽然经常被忽视,但它对模型的性能、效率甚至成本都有着显著的影响。本文将深入探讨Tokenization在现代LLM中的工作原理。
Tokenization的重要性
分词的核心是将文本分解成称为词元(Token)的更小单元的过程。这些词元随后被转换为模型用于处理的数字ID。分词策略的选择直接影响:
- 模型性能和解决问题的范围,譬如是否可以解决Out-of-Vocabulary(OOV)问题
- 上下文窗口限制(Context window limitations)
- 多语言内容处理
- API 使用成本,因为现在大语言模型通常按token 数量计费
Tokenization 的几种经典算法
字符级编码(Character-Level Tokenization)
最简单的方法是将每个字符单独标记化:
def char_tokenize(text): return list(text)tokens = char_tokenize("Hello")# ['H', 'e', 'l', 'l', 'o']
这种方法的优势包括:简单实现、没有词汇超出词汇范围的问题(无 OOV 问题),固定词汇量
缺点:效率极低(序列过长)、失去词级语义(可能不完全正确,关于这部分后续有讨论)、空格和格式处理不当
举例,假设输入是:Today, I want to start my day with a cup of coffee,需要用 50 个 tokens 才能完整表示这个输入。

这样会导致鼓胀效应(ballooning effect),即一个很短的文章就会对应很长的 token 序列

而 LLM 使用 self-attention,计算复杂度和 token 的数量成线性或者二次方关系(取决于实际用什么 attention 算法),由于 GPU 显存的限制,LLM 可以处理的上下文长度往往有限,使用字符级编码导致 token 数量太多,因此 LLM 会长度上限以外的上下文信息。

使用字符级编码还会导致失去语义信息(关于这一点可能待考证是否在正确,因为这可能是对人类来说失去语义信息,但对机器来说未必尽然)。

词级编码(Word-Level Tokenization)
词语标记化将文本按空格和标点符号分割:
def word_tokenize(text): return text.split()tokens = word_tokenize("Hello, world!")# ['Hello,', 'world!']
优势:与语言单位的直观对齐,比字符标记化更短的序列
缺点:词汇量要求高,无法表达词汇表之外的词语,对形态丰富的语言处理不当(譬如ing,ed, ful等形式的词)
子词编码(Subword Tokenization)
大多数现代语言学习管理系统都采用子词分词法,这种方法兼顾了效率和灵活性。主要的算法包括一下几种。
字节对编码(Byte Pair Encoding, BPE)
BPE(字节对编码)由 GPT 模型使用,它从单个字符开始,迭代地合并出现频率最高的字符对,算法流程图如下
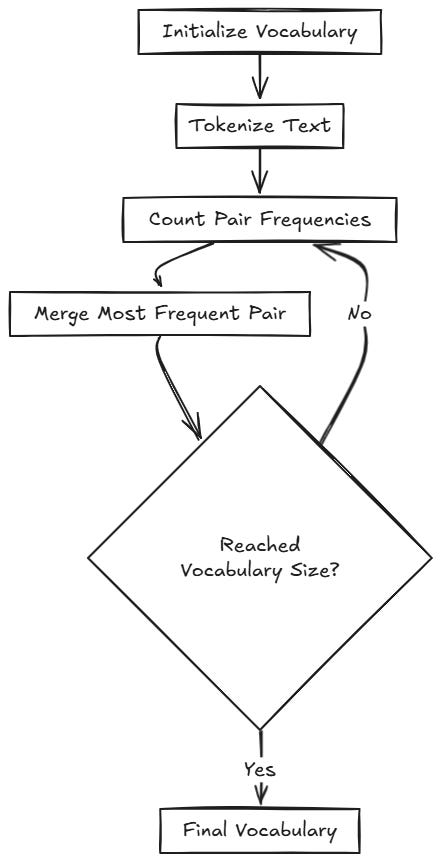
词汇表大小是 BPE 算法中的一个超参数,由用户决定。例如,GPT-2 的词汇表大小为 50257,而 GPT-4 的词汇表大小约为 100000。
需要注意的关键是词汇量和序列长度之间存在权衡,这对于确定词汇量非常重要。词汇量的大小直接影响文本的分词方式:
- 更大的词汇量:
- 每句标记数较少(较长的子词甚至整个单词都以单个标记表示)。
- 更适合捕捉生僻词或语言细微差别。
- 增加嵌入和训练的内存和计算成本。
- 词汇量较小:
- 每句包含更多词元(每个词元代表一个较小的单位,例如字符或短子词)。
- 由于句子的词元长度非常长,这些词元可能无法适应语言学习模型(LLM)的上下文长度。这可能导致上下文丢失,进而影响LLM的训练效果。
训练语料库的性质和规模也会对词汇量产生重大影响
- 大型、多样化的数据:处理多样化的语言模式、罕见词汇和多语言数据(例如区域语言数据)通常需要更大的词汇量。
- 小型或特定领域语料库:由于语言使用有限,较小的词汇量可能就足够了。
BPE 的优点是它防止表示文本所需的标记数量过多,而这正是字符标记化的主要问题,同时它也保留了语言模式,例如常见的前缀、后缀和词干。BPE 也有局限性,BPE 依赖于预先设定的词汇量,如果词汇量过小,可能会过度分割单词,导致语义丢失;如果词汇量过大,则可能包含不必要的子词单元,降低模型的灵活性。

WordPiece
WordPiece 被 BERT 等模型所采用,它与 BPE 类似,但合并词元的标准不同。它通过计算两个词元合并后出现频率与各自出现频率的乘积,来确定合并的可能性。
# Example WordPiece tokenization:"embedding" → ["em", "##bed", "##ding"]"transformer" → ["trans", "##form", "##er"]
前缀##表示该词是较大单词的一部分。
SentencePiece / Unigram LM
Unigram 被 T5 和许多多语言模型(multilingual models)所采用,它从一个庞大的词汇表开始,通过迭代地删除词元来最大化似然性。许多现代模型使用的 SentencePiece 将输入视为 Unicode 字符序列,并基于一元语法语言模型学习分词。它对于没有明确词界的语言(例如泰语、日语或汉语)尤其有用:
# English: "Hello world!"# SentencePiece: ["▁He", "llo", "▁world", "!"]# (▁ represents space)# Japanese: "こんにちは世界"# SentencePiece: ["こん", "にち", "は", "世界"]
字节级编码(Byte-Level Tokenization)
一些现代模型,例如 GPT-4,使用字节级 BPE,这确保了每个可能的字符串都可以被编码:
# Every string can be represented as bytesdef bytes_tokenize(text): return list(text.encode('utf-8'))tokens = bytes_tokenize("Hello 🌍")# [72, 101, 108, 108, 111, 32, 240, 159, 140, 141]# use BPE to merge
比特级编码(Bit-Level Tokenization)
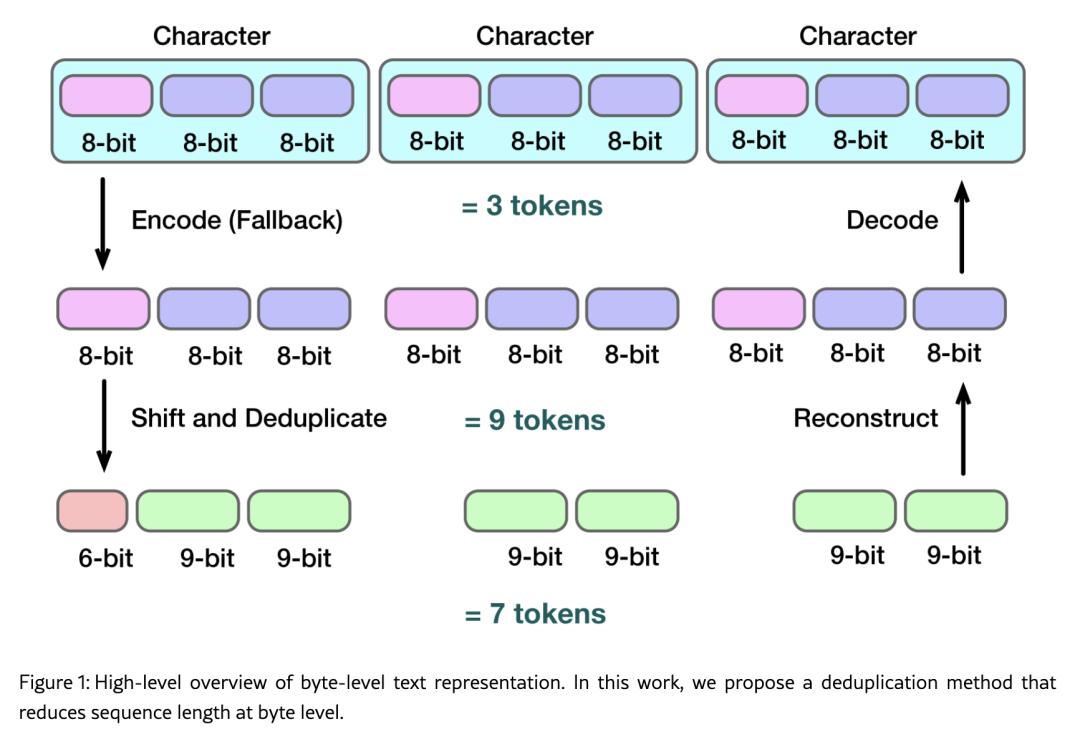
参考论文:Bit-level BPE: Below the byte boundary,作者认为在多语言/字符丰富(特别是 CJK:中文 / 日文 / 韩文)或含有大量表情符号/特殊符号的场景中,传统的字节级分词(即把字符转换为 UTF-8 字节,再做 BPE 合并)虽然能避免 OOV(未知词)问题,但带来一个大问题:序列长度显著增长,从而训练或推理时间、内存开销也变大。 为了解决这个问题,作者提出了 “bit-level BPE” 的想法:即在 比字节还小的单位(比特) 层面,做合并/压缩,从而 无损地 减少序列长度。 论文从 “UTF-8 编码结构” 入手,观察到在字节级表示里存在重复/冗余(比如某些 UTF-8 字节前缀在 CJK 范围里非常高频),从而提出“去重/压缩”的机制。 在实验中,在中文、日文、韩文语料上,作者测量了使用该方法之后的 序列长度缩短情况,以及“感知吞吐量”(perceived throughput,结合了序列长度、模型运算量等因素)变化。 论文也讨论了应用中的 trade-offs,比如在训练时模型需要处理稍微不同的 token 分布、可能的实现复杂度等。
实例分析
让我们看看不同的现代分词器是如何处理同一段文本的。示例输入:The tokenization process transforms text into numerical tokens.
GPT-2/3/4 分词器(BPE)
['The', 'Ġtokenization', 'Ġprocess', 'Ġtransforms', 'Ġtext', 'Ġinto', 'Ġnumerical', 'Ġtokens', '.']# 9 tokens (Ġ represents space)
BERT 分词器(WordPiece)
['the', 'token', '##ization', 'process', 'transform', '##s', 'text', 'into', 'numerical', 'token', '##s', '.']# 12 tokens (## represents subword continuation)
T5 分词器(SentencePiece)
['▁The', '▁token', 'ization', '▁process', '▁transforms', '▁text', '▁into', '▁numerical', '▁tokens', '.']# 10 tokens (▁ represents space)
如何编码数字
text = "The price is $1,234.56"# GPT-4 Tokenizer['The', 'Ġprice', 'Ġis', 'Ġ$', '1', ',', '234', '.', '56']# 9 tokens# Claude Tokenizer['The', ' price', ' is', ' $', '1', ',', '234', '.', '56']# 9 tokens
如何编码表情符号(Emojis)
text = "I love coding! 👨💻"# GPT-4 Tokenizer['I', 'Ġlove', 'Ġcoding', '!', 'Ġ', '<0xF0>', '<0x9F>', '<0x91>', '<0xA8>', '<0xE2>', '<0x80>', '<0x8D>', '<0xF0>', '<0x9F>', '<0x92>', '<0xBB>']# 16 tokens (UTF-8 bytes)# Claude Tokenizer['I', ' love', ' coding', '!', ' ', '👨', '', '💻']# 8 tokens
如何编码代码
code = "def hello_world():\n print('Hello, world!')"# GPT-4 Tokenizer['def', 'Ġhello', '_', 'world', '():', '\n', 'Ġ', 'Ġ', 'Ġ', 'Ġprint', '(', "'", 'Hello', ',', 'Ġworld', '!', "'", ')']# 18 tokens# CodeLlama Tokenizer (optimized for code)['def', ' hello_world', '():', '\n ', 'print', '(', "'", 'Hello', ',', ' world', '!', "'", ')']# 13 tokens
分词对模型上下文窗口的影响
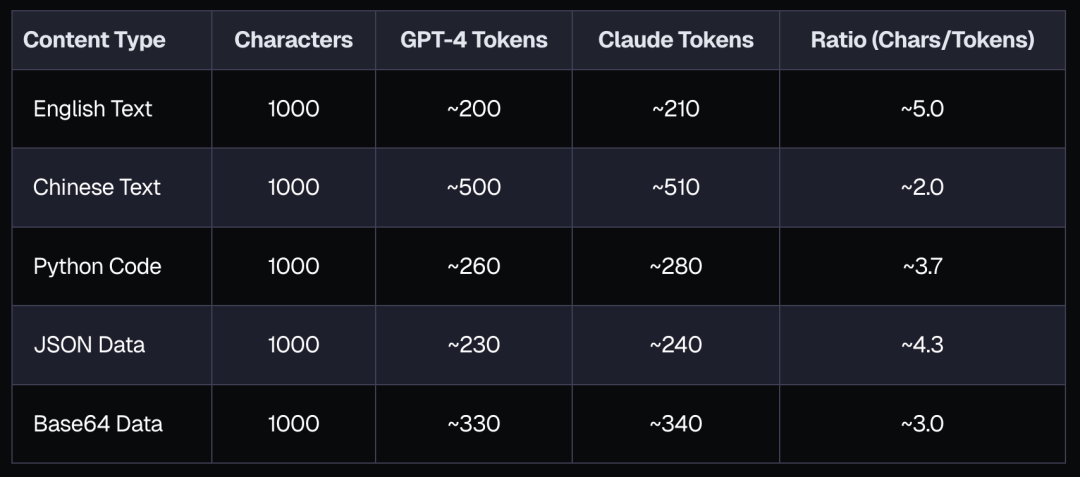
分词效率直接影响模型上下文窗口中可容纳的内容量:
Tokenization 的挑战
语言偏见
大多数语言学习模型最初都是使用针对英语优化的分词器进行训练的,这导致在其他语言中效率低下:
English: "Understanding" → 1 tokenGerman: "Verständnis" → 3 tokens (Ver/ständ/nis)Japanese: "理解" → 2 tokens (理/解)
非常见文本(Out-of-Distribution Text)
Normal text: "Hello world" → 2 tokensRepeated characters: "aaaaaaaaaaaa" → 4-6 tokens
代码和技术内容
代码中的特殊字符和语法可能会导致次优的词法分析:
code = "result = list(map(lambda x: x**2, range(10)))"# Tokenized inefficiently:['result', 'Ġ=', 'Ġlist', '(', 'map', '(', 'lambda', 'Ġx', ':', 'Ġx', '**', '2', ',', 'Ġrange', '(', '10', ')', ')', ')']# 19 tokens
提高Token效率的最佳实践
批量处理
将相关请求分组,以尽量减少重复的系统提示:
# Inefficient: 2 separate callsresponse1 = llm("Translate 'hello' to French") # ~10 tokensresponse2 = llm("Translate 'goodbye' to French") # ~10 tokens# Efficient: 1 batch callresponse = llm("Translate these words to French:\n1. hello\n2. goodbye") # ~15 tokens
优化提示工程
# Inefficient prompt (~44 tokens)inefficient = """Please analyze the sentiment of the following customer review. The sentiment should be classified as positive, negative, or neutral. Here is the review: 'Great product, fast shipping!'"""# Efficient prompt (~21 tokens)efficient = """Sentiment (positive/negative/neutral):Review: 'Great product, fast shipping!'"""
内容预处理
def preprocess_for_token_efficiency(text): # Remove redundant whitespace text = re.sub(r'\s+', ' ', text).strip() # Replace verbose phrases with concise alternatives replacements = { "in order to": "to", "a large number of": "many", "due to the fact that": "because", "at this point in time": "now" } for verbose, concise in replacements.items(): text = re.sub(r'\b' + verbose + r'\b', concise, text, flags=re.IGNORECASE) return text
Tokenization的常见实现
大多数LLM提供商都以库的形式公开其分词器:
# OpenAI (GPT-4)from tiktoken import get_encodingtokenizer = get_encoding("cl100k_base") # GPT-4 tokenizertokens = tokenizer.encode("Hello, world!")print(len(tokens)) # 4# Hugging Face Transformersfrom transformers import AutoTokenizertokenizer = AutoTokenizer.from_pretrained("gpt2")tokens = tokenizer("Hello, world!")["input_ids"]print(len(tokens)) # 5# SentencePieceimport sentencepiece as spmsp = spm.SentencePieceProcessor()sp.load("t5.model")tokens = sp.encode("Hello, world!", out_type=str)print(len(tokens)) # 5
对 API 成本的影响
不同的令牌化方法会直接影响 API 使用成本
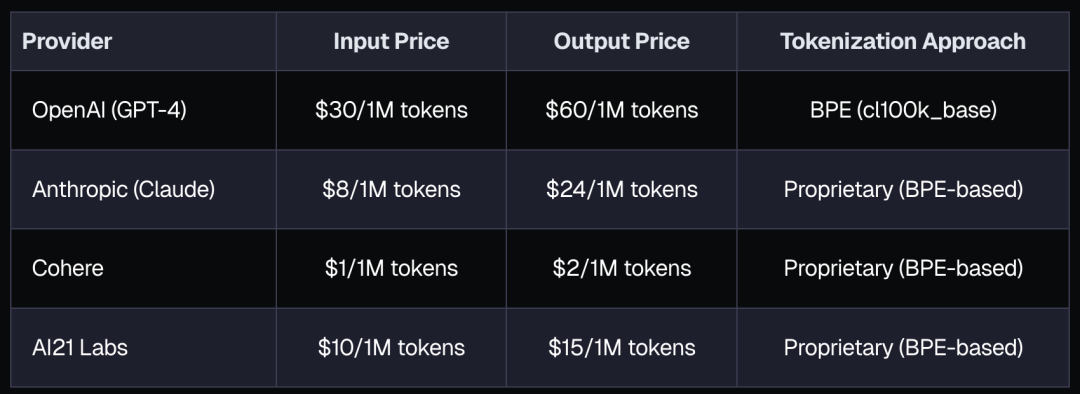
主流的 Tokenization 算法的对比

普通人如何抓住AI大模型的风口?
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

AI大模型开发工程师对AI大模型需要了解到什么程度呢?我们先看一下招聘需求:

知道人家要什么能力,一切就好办了!我整理了AI大模型开发工程师需要掌握的知识如下:
大模型基础知识
你得知道市面上的大模型产品生态和产品线;还要了解Llama、Qwen等开源大模型与OpenAI等闭源模型的能力差异;以及了解开源模型的二次开发优势,以及闭源模型的商业化限制,等等。

了解这些技术的目的在于建立与算法工程师的共通语言,确保能够沟通项目需求,同时具备管理AI项目进展、合理分配项目资源、把握和控制项目成本的能力。
产品经理还需要有业务sense,这其实就又回到了产品人的看家本领上。我们知道先阶段AI的局限性还非常大,模型生成的内容不理想甚至错误的情况屡见不鲜。因此AI产品经理看技术,更多的是从技术边界、成本等角度出发,选择合适的技术方案来实现需求,甚至用业务来补足技术的短板。
AI Agent
现阶段,AI Agent的发展可谓是百花齐放,甚至有人说,Agent就是未来应用该有的样子,所以这个LLM的重要分支,必须要掌握。
Agent,中文名为“智能体”,由控制端(Brain)、感知端(Perception)和行动端(Action)组成,是一种能够在特定环境中自主行动、感知环境、做出决策并与其他Agent或人类进行交互的计算机程序或实体。简单来说就是给大模型这个大脑装上“记忆”、装上“手”和“脚”,让它自动完成工作。
Agent的核心特性
自主性: 能够独立做出决策,不依赖人类的直接控制。
适应性: 能够根据环境的变化调整其行为。
交互性: 能够与人类或其他系统进行有效沟通和交互。

对于大模型开发工程师来说,学习Agent更多的是理解它的设计理念和工作方式。零代码的大模型应用开发平台也有很多,比如dify、coze,拿来做一个小项目,你就会发现,其实并不难。
AI 应用项目开发流程
如果产品形态和开发模式都和过去不一样了,那还画啥原型?怎么排项目周期?这将深刻影响产品经理这个岗位本身的价值构成,所以每个AI产品经理都必须要了解它。

看着都是新词,其实接触起来,也不难。
从0到1的大模型系统学习籽料
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师(吴文俊奖得主)

给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。
- 基础篇,包括了大模型的基本情况,核心原理,带你认识了解大模型提示词,Transformer架构,预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门AI大模型
- 进阶篇,你将掌握RAG,Langchain、Agent的核心原理和应用,学习如何微调大模型,让大模型更适合自己的行业需求,私有化部署大模型,让自己的数据更加安全
- 项目实战篇,会手把手一步步带着大家练习企业级落地项目,比如电商行业的智能客服、智能销售项目,教育行业的智慧校园、智能辅导项目等等

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


AI时代,企业最需要的是既懂技术、又有实战经验的复合型人才,**当前人工智能岗位需求多,薪资高,前景好。**在职场里,选对赛道就能赢在起跑线。抓住AI这个风口,相信下一个人生赢家就是你!机会,永远留给有准备的人。
如何获取?
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 1453
1453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









