



前言
我经常在网上看到关于GraphRAG的帖子,但直到大约一个月前,我才决定尝试一下。在花了一些时间进行实验后,我可以说它的表现令人印象深刻,但如果你使用的是OpenAI API,成本也相当高。在文档中运行他们提供的示例书籍测试花费了我大约7美元,所以虽然它的性能和组织能力非常出色,但它并不算经济实惠。
如果你是RAG系统的新手,我建议先阅读一些入门文章:
1、Anthropic 的新 RAG 方法(https://pub.towardsai.net/anthropics-new-rag-approach-e0c24a68893b)
2、RAG 从头开始(https://pub.towardsai.net/rag-from-scratch-66c5eff02482)
无论如何,这里是传统RAG系统的工作原理概述:
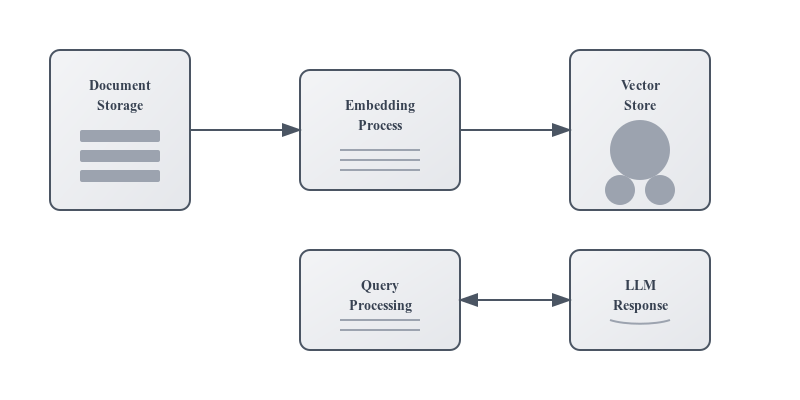
对于已经熟悉RAG的人来说,你可能遇到过和我一样的头疼问题:
-
• 文本块之间的上下文容易丢失
-
• 随着文档集合的增长,性能急剧下降
-
• 集成外部知识就像蒙着眼睛解魔方一样困难(比喻意指操作复杂且缺乏清晰方向)
GraphRAG的工作原理
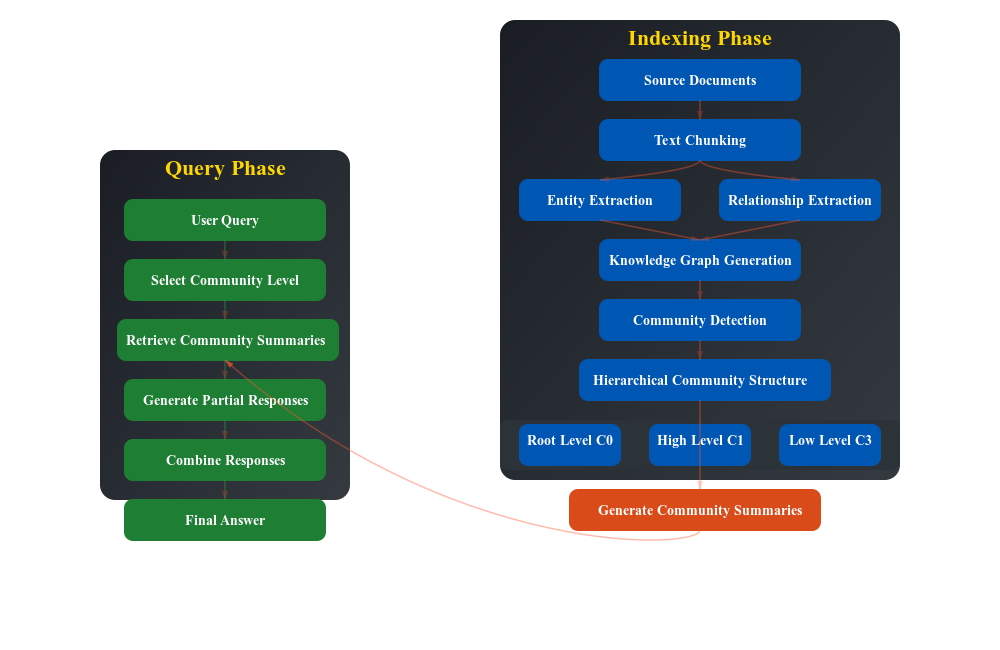
GraphRAG是传统RAG的增强版本,主要分为两个阶段:
索引阶段
-
从源文档开始,将其拆分为更小的子文档(与传统RAG类似)
-
执行两个并行的提取过程:
-
实体提取:识别出诸如人物、地点、公司等实体
-
关系提取:发现跨不同文本块的实体之间的联系
-
创建一个知识图谱,其中节点代表实体,边代表它们之间的关系
-
通过识别紧密相关的实体来建立社区
-
在不同的社区层级生成分层摘要(共三级)
-
使用归约-映射方法,通过逐步合并文本块生成整体摘要
查询阶段
-
接收用户的查询
-
根据所需的细节选择适当的社区层级
-
在社区层级(而不是传统RAG的文本块层级)上执行检索
-
检查社区摘要以生成局部响应
-
将多个相关社区的局部响应组合成最终的综合答案
GraphRAG的核心创新在于它将信息结构化为图形格式,并利用社区检测来生成更具上下文意识的响应。然而,传统RAG系统仍然有其用武之地,特别是在考虑运行GraphRAG的计算成本时。
设置GraphRAG
⚠️ 提醒:这个实验运行在GPT-4 API上,成本较高。我的一次测试成本约为7美元(基于GPT-4模型)。
如果你更喜欢在本地LLM上使用ollama进行测试,请查看这个视频:
接下来让我们一步步完成设置过程:
环境设置
首先,创建一个虚拟环境:
conda create -n GraphRAG
conda activate GraphRAG
安装GraphRAG包:
pip install graphrag
目录结构
GraphRAG需要特定的目录结构以实现最佳运行效果:
- 创建一个工作目录
- 在其中创建_ragtest/input_文件夹结构
- 将源文档放入input文件夹中
在本文中,我们将使用提供的书籍作为示例。通过以下命令下载到input文件夹中:
curl https://www.gutenberg.org/cache/epub/24022/pg24022.txt > ./ragtest/input/book.txt
配置
使用以下命令初始化工作区:
python -m graphrag.index --init --root ./target
此操作会创建必要的配置文件,包括settings.yml,你需要在其中:
- 设置你的OpenAI API密钥
- 配置模型设置(默认使用GPT-4进行处理和OpenAI嵌入)
- 根据需要调整文本块大小(默认:300个token)和重叠部分(默认:100个token)
构建知识图谱
运行索引过程:
python -m graphrag.index --init --root ./target
查询你的图谱
GraphRAG提供了两种主要的查询方式:
全局查询
python -m graphrag.query --root ./target --method global "what are the top themes in this story"
适用于关于主题和整体内容理解的广泛问题。
局部查询
python -m graphrag.query --root ./target --method local "what are the top themes in this story"
适用于关于文档内实体或关系的具体问题。
成本因素:值得吗?
让我们谈谈数字。在我用示例书籍进行测试时,GraphRAG调用了:
-
• ~570次GPT-4 API请求
-
• 大约25次嵌入请求
-
• 处理了超过100万个token
总成本:每本书大约7美元。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 1139
1139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









