




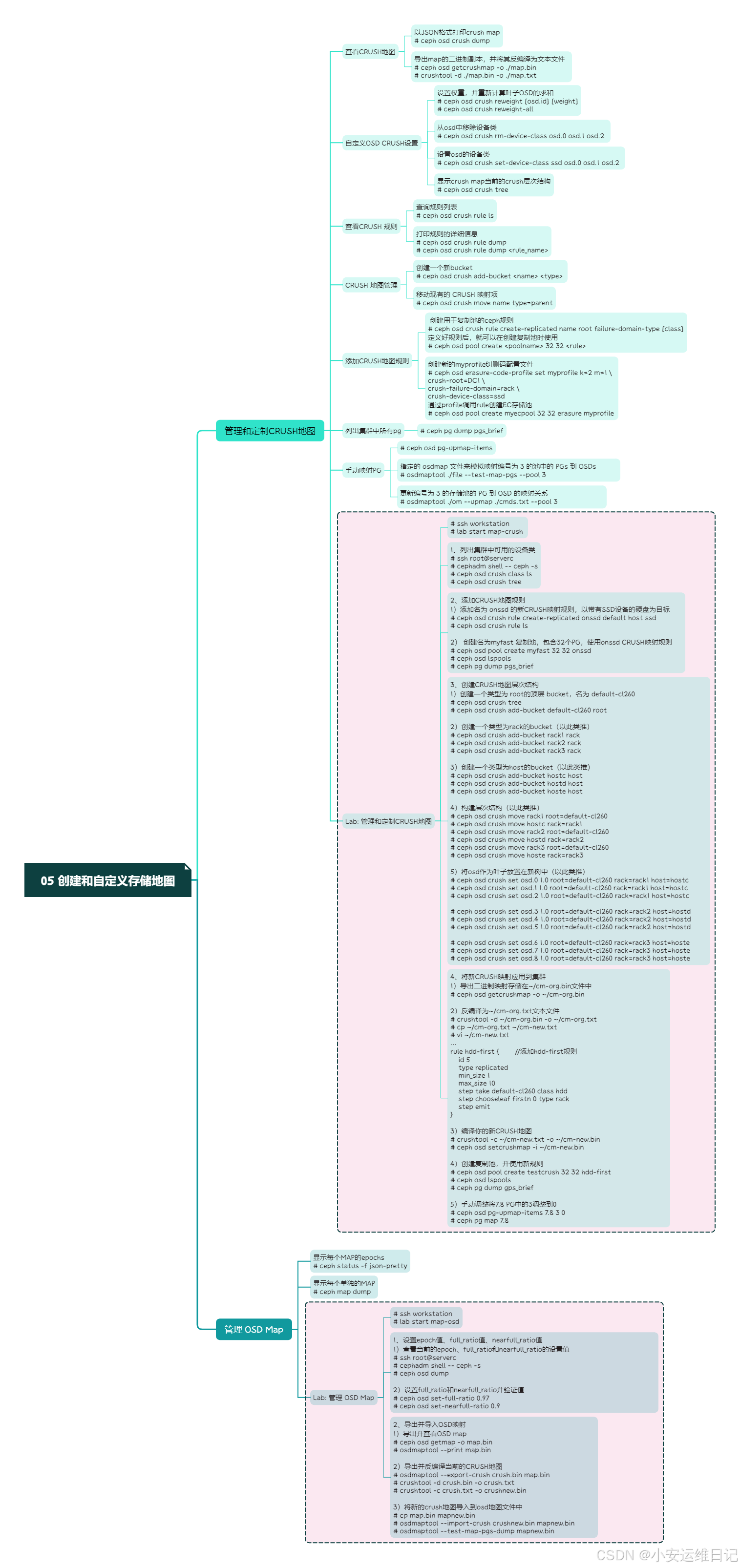
一、管理和定制CRUSH地图
1、CRUSH和对象放置策略
CRUSH calculates which OSDs should hold which objects by using a placement algorithm called CRUSH.
计算哪些数据对象放在哪个OSDs中,需要使用CRUSH算法计算出来。
Objects are assigned to placement groups(PGs) and CRUSH determines which OSDs those placement groups should use to store their objects.
对象分配给PG组,然后CRUSH决定了PG和OSD的对象关系。
CRUSH算法
CRUSH算法允许客户端直接和OSD通信,避免了中心服务器的性能瓶颈。Ceph客户端接收集群地图,使用CRUSH地图决定如何存储和下载数据。当增加新的OSD或移除现有OSD或OSD主机故障时,Ceph需要能够使用CRUSH在主OSD之间重新平衡集群中的对象。比如,一个典型的案例是设置额外的硬件损坏保护。默认,CRUSH算法将对象的副本存放在不同主机的OSD上面。
CRUSH地图组件
A CRUSH map contains two major components: 一个CRUSH映射包含两个主要的组件:
-
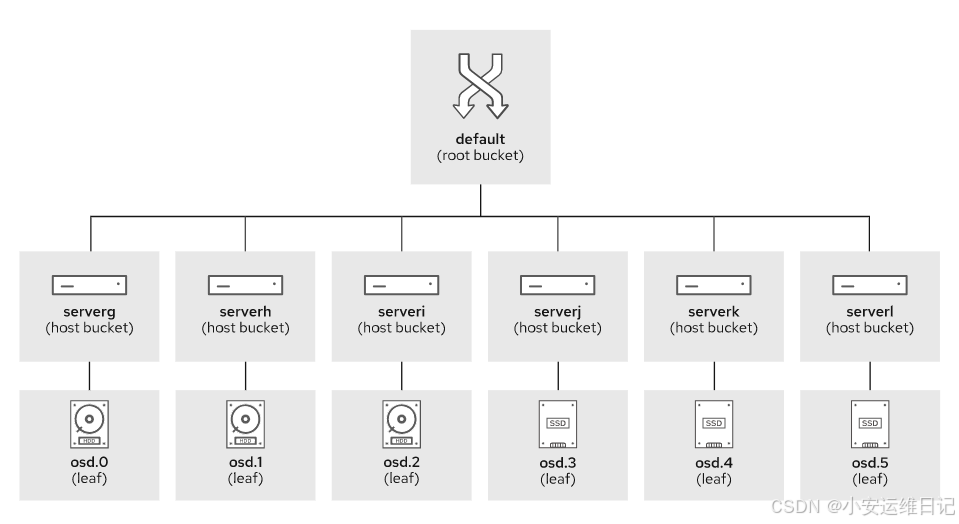
A CRUSH hierarchy(CRUSH结构)This lists all available OSDs and organizes them into a treelike structure of buckets. By default there is a root bucket representing the whole hierarchy, which contains a host bucket for each OSD host. 它列出了所有可用的osd,并将它们组织成一个树状的桶结构。默认情况下,有一个代表整个层次结构的根桶,其中包含每个OSD主机的主机桶。
-
At least one CRUSH rule(CRUSH规则)CRUSH rules determine how placement groups are assigned OSDs from those buckets. Different pools might use different CRUSH rules from the CRUSH map. CRUSH规则决定了PG放置组如何从这些桶中分配osd。不同的池可能使用来自CRUSH映射的不同CRUSH规则。
CRUSH桶类型
The CRUSH hierarchy organizes OSDs into a tree of different containers, called buckets.
CRUSH层次结构将osd组织到不同容器的树状结构中,这些容器称为bucket。
You can create a specific hierarchy to describe your storage infrastructure: data centers with rows of racks, racks, hosts, and OSD devices on those hosts.
您可以创建一个特定的层次结构来描述您的存储基础设施(存储架构):包含的数据中心、机架、机架、主机和主机上的OSD设备等。
Some of the most important bucket attributes are: 一些最重要的桶属性是:
-
The ID of the bucket.(桶的ID)
-
The name of the bucket. (桶的名称)
-
The type of the bucket.(桶的类型),包括:root、region、datacenter、room、pod、pdu、row、rack、chassis、host
-
The algorithm that Ceph uses to select items inside the bucket when mapping PG replicas to OSDs. (uniform,list,tree, and straw2) The default algorithm is straw2.(Ceph将PG副本映射到osd时选择桶内置的算法,包括:uniform、list、tree、 straw2,默认算法为straw2
CRUSH 是 Ceph 使用的一种算法,它允许 Ceph 集群以一种有效的方式存储和检索数据,通过一个映射过程将数据对象映射到物理存储设备(即 OSDs,Object Storage Daemons)。在 CRUSH 映射中,"bucket" 是一种容器,用于组织 OSD 或者其他 bucket。这些 bucket 反映了存储硬件的物理或逻辑组织结构,并且可以是多级的,比如可以代表机房、行、机架等。
假设:ceph osd crush add-bucket default-cl260 root
ceph:这是用于与 Ceph 集群交互的基本命令。
osd crush:指定操作是针对 OSD 的 CRUSH 映射。
add-bucket:指示要添加一个新的 bucket。
default-cl260:这是要添加的新 bucket 的名称。
root:这是添加的 bucket 的类型。在 Ceph 中,bucket 可以有不同的类型,比如 root、host、rack 等,这些类型用于定义集群的层级结构。这里的 root 表示这个 bucket 在层级结构中处于最顶层。
因此,这个命令的作用是在 CRUSH 映射中创建一个类型为 root 的顶层 bucket,并将其命名为 default-cl260。之后,你可以在这个 bucket 下面组织其他的 bucket 或者 OSD,以匹配存储基础设施的物理或逻辑布局。
添加 bucket 后,你可能需要进行额外的配置,例如设置 OSD 在 bucket 层级结构中的位置,或者调整 CRUSH 规则以定义数据如何在集群的设备中复制。
当修改 CRUSH 映射时,应该格外小心,因为不当的配置可能会影响 Ceph 集群的数据分布和冗余。建议在进行更改之前,确保对 CRUSH 算法和 Ceph 操作有深入的了解。
2、自定义故障域
CRUSH算法是CRUSH map的核心配置。你可以调整算法让CRUSH更符合需求、更平滑。
你可以配置CRUSH map和CRUSH规则,让对象数据的副本存放在不同机房的不同主机上面,或者在不同的PDU电源分配单元。另一个案例是,将SSD硬盘分配给需要更快存储速度的应用,将传统SATA硬盘分配给低负载的应用。
集群安装过程部署一个默认的CRUSH映射。您可以使用 ceph osd crush dump 命令以JSON格式打印crush map。
- 命令:ceph osd crush dump
[ceph: root@serverc /]$ ceph osd crush dump
你也可以导出map的二进制副本并将其反编译为文本文件:
[ceph: root@serverc /]$ ceph osd getcrushmap -o ./map.bin //导出二进制文件
[ceph: root@serverc /]$ crushtool -d ./map.bin -o ./map.txt //将二进制文件编译成文本文件
3、自定义OSD CRUSH设置
CRUSH映射包含集群中所有存储设备的列表。对于每台存储设备,可获取的信息如下:
-
The ID of the storage device.(存储设备的ID)
-
The name of the storage device.(存储设备的名称)
-
The weight of the storage device(For example, a 4TB storage devices has a weight of about 4.0).(存储设备的权重(以4TB存储设备为例,重量约为4.0))
-
The class of the storage device.(Such as HDDs, SSDs, or NVMe SSDs.) (存储设备的类别。(如hdd、ssd、NVMe ssd))
设置权重 可以通过:
-
命令:ceph osd crush reweight [osd.id] [weight]
而CRUSH tree的权重是所有叶子权重的和,如果你手动修改了CRUSH map weights,就需要重新计算叶子OSD的求和
-
命令:ceph osd crush reweight-all
存储设备的类别:一个存储集群可以使用多种类型的存储设备,如hdd、ssd、NVMe ssd等。osd自动检测并设置其设备类。
1)你可以从osd中移除设备类:
-
命令:ceph osd crush rm-device-class osd.$id
[ceph: root@serverc /]$ ceph osd crush rm-device-class osd.0 osd.1 osd.2
2)您可以设置osd的设备类:
- 命令:ceph osd crush set-device-class ssd osd.$id
[ceph: root@serverc /]$ ceph osd crush set-device-class ssd osd.0 osd.1 osd.2
3)显示crush map当前的crush层次结构:
- 命令:ceph osd crush tree
[ceph: root@serverc /]# ceph osd crush tree
4、CRUSH 规则
CRUSH地图还包含数据放置规则,这些规则决定了如何将pg映射到osds以存储对象副本或纠删码块。ceph osd crush rule ls命令用于查询规则列表,ceph osd crush rule dump rule_name命令用于打印规则的详细信息。
- 命令:ceph osd crush rule ls
- 命令:ceph osd crush rule dump
- 命令:ceph osd crush rule dump <rule_name>
[ceph: root@serverc /]# ceph osd crush rule ls //查询规则列表
replicated_rule
[ceph: root@serverc /]# ceph osd crush rule dump replicated_rule //打印规则的详细信息
{
"rule_id": 0,
"rule_name": "replicated_rule",
"ruleset": 0,
"type": 1,
"min_size": 1,
"max_size": 10,
"steps": [
{
"op": "take",
"item": -1,
"item_name": "default"
},
{
"op": "chooseleaf_firstn",
"num": 0,
"type": "host"
},
{
"op": "emit"
}
]
}
反编译(解码)的CRUSH地图也包含放置规则,并且可能更容易阅读:
-
命令:ceph osd getcrushmap -o ./file.bin
-
命令:crushtool -d ./map.bin -o ./file.txt
如果没有crushtool,需要安装 yum install ceph-common
[root@serverc ~]# cephadm shell
[ceph: root@serverc /]# ceph osd getcrushmap -o ./map.bin //导出二进制文件
59
[ceph: root@serverc /]# crushtool -d ./map.bin -o ./map.txt //将导出的二进制文件编译成文本文件
[ceph: root@serverc /]# cat ./map.txt
# begin crush map
... ...
# devices
device 0 osd.0 class hdd
device 1 osd.1 class hdd
device 2 osd.2 class hdd
device 3 osd.3 class hdd
device 4 osd.4 class hdd
device 5 osd.5 class hdd
device 6 osd.6 class hdd
device 7 osd.7 class hdd
device 8 osd.8 class hdd
# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 zone
type 10 region
type 11 root
# buckets
host serverc {
id -3 # do not change unnecessarily
id -4 class hdd # do not change unnecessarily
# weight 0.029
alg straw2
hash 0 # rjenkins1
item osd.0 weight 0.010
item osd.1 weight 0.010
item osd.2 weight 0.010
}
host serverd {
id -5 # do not change unnecessarily
id -6 class hdd # do not change unnecessarily
# weight 0.029
alg straw2
hash 0 # rjenkins1
item osd.3 weight 0.010
item osd.5 weight 0.010
item osd.7 weight 0.010
}
host servere {
id -7 # do not change unnecessarily
id -8 class hdd # do not change unnecessarily
# weight 0.029
alg straw2
hash 0 # rjenkins1
item osd.4 weight 0.010
item osd.6 weight 0.010
item osd.8 weight 0.010
}
root default {
id -1 # do not change unnecessarily
id -2 class hdd # do not change unnecessarily
# weight 0.088
alg straw2
hash 0 # rjenkins1
item serverc weight 0.029
item serverd weight 0.029
item servere weight 0.029
}
# rules
rule replicated_rule { //(1)规则的名称
id 0 //(2)规则的ID
type replicated
min_size 1 //(3)最少副本
max_size 10 //(4)最大副本
step take default //(5)选择的bucket名字(默认CRUSH层次结构的根)
step chooseleaf firstn 0 type host //(6)选择一组给定类型的bucket
step emit //(7)输出规则的结果
}
# end crush map
1)The name of the rule. (规则的名称)
使用ceph osd pool create命令创建池时,使用此名称选择规则。
2)The ID of the rule.(规则的ID)
有些命令使用规则ID代替规则名称。例如:ceph osd pool set pool-name crush_ruleset ID命令。
3)如果一个池生成的副本少于这个数目,CRUSH不会选择此规则。
4)如果一个池的副本数大于这个数,CRUSH不会选择此规则。
5)需要选择一个bucket的名字,在tree从上往下开始迭代。
6)在本例中,迭代从名为default的存储桶开始,它是默认CRUSH层次结构的根。
7)选择一组给定类型的bucket(例如host),并从集合中每个bucket的子树中选择一个叶子(OSD)。(通过给定类型的bucket选择最终的OSD)
在本例中,规则从集合中的每个bucket(host)中选择一个OSD,确保OSD来自不同的主机。
-
If the number after firstn is 0, choose as many buckets as there are replicas in the pool. 如果firstn后面的数字为0,则存储池设置的副本为几,CRUSH就选择几个buckets(选择的bucket和副本数量一致)
-
If the number is greater than zero, and less than the number of replicas in the pool, choose that many buckets. 如果数字为大于0,并且数字小于副本数量,则就选择该数字个Bucket(如数字为2,则就选择2个bucket)。
-
If the number is less than zero, subtract/səbˈtrækt/ its absolute value from the number of replicas and choose that many buckets. 如果数字小于0,就拿副本数减去该数字的绝对值,得到结果数字,选择该数字个bucket.
8)Output the results of the rule.(输出规则的结果)
-
从step开始,take是选择一个根bucket,从这里往下遍历,寻找叶子OSD;
-
choose定义选出若干个type类型的bucket,以及从bucket选择一个leaf;
-
选择什么类型的bucket取决于type,选择几个leaf取决于firstn后面的数字;
-
emit结束
例如,您可以创建以下规则,根据需要在单独的机架上选择尽可能多的osd,但只能从DC1数据中心选择:
rule myrackruleinDC1 {
id 2
type replicated
min_size 1
max_size 10
step take DC1
step chooseleaf firstn 0 type rack
step emit
}
5、CRUSH 地图管理
The RHCS cluster keeps a compiled binary representation of the CRUSH map. RHCS集群保存的CRUSH地图是二进制表示
There are two ways to modify it: 有两种方法可修改它:
-
By using the ceph osd crush command. 使用ceph osd crush命令
-
By extracting and decompiling the binary CRUSH map to plain text, editing the text file, recompiling it to binary format, and importing it back into the cluster.通过将二进制CRUSH地图提取并解码为文本,编辑文本文件,将其重新编译为二进制格式,并将其导入集群。
It is usually easier to update the CRUSH map with the ceph osd crush command. 使用ceph osd CRUSH命令更新CRUSH映射通常更容易。
Customizing the CRUSH Map Using Ceph Commands(使用Ceph命令定制CRUSH地图)
1)创建一个新bucket
- 命令: ceph osd crush add-bucket <name> <type>
例如,这些命令创建三个新bucket,一个是数据中心类型,两个是机架类型:
[ceph: root@serverc /]# ceph osd crush add-bucket DC1 datacenter
added bucket DC1 type datacenter to crush map
[ceph: root@serverc /]# ceph osd crush add-bucket rackA1 rack
added bucket rackA1 type rack to crush map
[ceph: root@serverc /]# ceph osd crush add-bucket rackB1 rack
added bucket rackB1 type rack to crush map
验证:导出CRUSH地图的二进制并解码查看
[ceph: root@serverc /]# ceph osd getcrushmap -o ./map.bin
[ceph: root@serverc /]# crushtool -d ./map.bin -o ./map.txt
[ceph: root@serverc /]# cat ./map.txt
root default {
id -1 # do not change unnecessarily
id -2 class hdd # do not change unnecessarily
# weight 0.088
alg straw2
hash 0 # rjenkins1
item serverc weight 0.029
item serverd weight 0.029
item servere weight 0.029
}
datacenter DC1 { //新建的数据中心DC1
id -9 # do not change unnecessarily
# weight 0.000
alg straw2
hash 0 # rjenkins1
}
rack rackA1 { //新建的机架rackA1
id -10 # do not change unnecessarily
# weight 0.000
alg straw2
hash 0 # rjenkins1
}
rack rackB1 { //新建的机架rackB1
id -11 # do not change unnecessarily
# weight 0.000
alg straw2
hash 0 # rjenkins1
}
# rules
rule replicated_rule {
id 0
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type host
step emit
}
# end crush map
或者:
[ceph: root@serverc /]# ceph osd crush dump
2)你可以用下面的命令在一个层次结构中组织新的bucket:
-
命令:ceph osd crush move name type=parent
例如:ceph osd crush move rack1 root=default-cl260
- ceph: 这是用来与 Ceph 集群交互的命令行工具。
- osd crush: 表示操作的目标是 Ceph 集群中的 OSD CRUSH 映射。
- move: 表示要移动一个现有的 CRUSH 映射项。
- rack1: 指定要移动的 CRUSH 映射项的名称,在这个上下文中,rack1 通常是一个代表物理机架的 bucket。
- root=default-cl260: 指定新的位置,即指定 rack1 应该被移动到名称为 default-cl260 的 root bucket 下面。root 关键字表示父 bucket 的类型,而 default-cl260 是父 bucket 的名称。
因此,这条命令的作用是将名为 rack1 的 bucket 移动到 CRUSH 映射层级中名为 default-cl260 的 root bucket 下面。这通常是为了反映存储硬件的物理或逻辑组织结构。
在执行此类操作时,请务必了解你的 Ceph 集群的拓扑结构和 CRUSH 映射,因为不正确的移动可能会影响数据的分布和冗余。
示例:
将名称为rackA1的机柜绑定到名称为DC1的数据中心
[ceph: root@serverc /]# ceph osd crush move rackA1 datacenter=DC1
moved item id -10 name 'rackA1' to location {datacenter=DC1} in crush map
[ceph: root@serverc /]# ceph osd crush move rackB1 datacenter=DC1
moved item id -11 name 'rackB1' to location {datacenter=DC1} in crush map
将DC1绑定到名称为default的root(树根)
[ceph: root@serverc /]# ceph osd crush move DC1 root=default
moved item id -9 name 'DC1' to location {root=default} in crush map
验证:
[ceph: root@serverc /]# ceph osd getcrushmap -o ./map.bin
[ceph: root@serverc /]# crushtool -d ./map.bin -o ./map.txt
[ceph: root@serverc /]# cat ./map.txt
rack rackA1 {
id -10 # do not change unnecessarily
id -13 class hdd # do not change unnecessarily
# weight 0.000
alg straw2
hash 0 # rjenkins1
}
rack rackB1 {
id -11 # do not change unnecessarily
id -12 class hdd # do not change unnecessarily
# weight 0.000
alg straw2
hash 0 # rjenkins1
}
datacenter DC1 {
id -9 # do not change unnecessarily
id -14 class hdd # do not change unnecessarily
# weight 0.000
alg straw2
hash 0 # rjenkins1
item rackA1 weight 0.000
item rackB1 weight 0.000
}
root default {
id -1 # do not change unnecessarily
id -2 class hdd # do not change unnecessarily
# weight 0.088
alg straw2
hash 0 # rjenkins1
item serverc weight 0.029
item serverd weight 0.029
item servere weight 0.029
item DC1 weight 0.000
}
# rules
rule replicated_rule {
id 0
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type host
step emit
}
# end crush map
6、从命令行添加CRUSH地图规则
1)创建用于复制池的ceph CRUSH规则
创建用于复制池的ceph规则。
-
命令:ceph osd crush rule create-replicated <name> <root> <failure-domain-type> [class]
- name is the name of rule.(name是规则的名称)
- root is the staring node in the CRUSH map hierachy.(root是CRUSH地图层次结构中的起始节点)
- class is the class of the devices to use, such as ssd or hdd. This parameter is optional. OSDs automatically detect and set their device calss.(class是要使用的设备的类,例如ssd或hdd。可选参数。osd自动检测并设置其设备类。)
补充:如果无法自动正确识别硬盘class类型,也可以先删除错误的类型,将类型设置为未分类后才能设置新类型。
-
命令:ceph osd crush rm-device-class osd.0 osd.1 osd.2 //删除硬盘的class类型
-
命令:ceph osd crush set-device-class ssd osd.0 osd.1 osd.2 //设置硬盘的class类型
示例:创建了新的inDC1规则,将副本存储在DC1数据中心,并将副本分布在rack机架上:
[ceph: root@serverc /]# ceph osd crush rule create-replicated inDC1 DC1 rack
[ceph: root@serverc /]# ceph osd crush rule ls
replicated_rule
inDC1
定义好规则后,就可以在创建复制池时使用:
- 命令:ceph osd pool create <poolname> 32 32 <rule>
[ceph: root@serverc /]# ceph osd pool create mytest 32 32 inDC1
使用 ceph pg dump pgs_brief 命令列出集群中所有pg。
[ceph: root@serverc /]# ceph pg dump pgs_brief
… …
29.1c active+clean [8,6] 8 [8,6] 8
… …
- The command output is probably different on your cluster.(命令输出可能在您的集群上有所不同。)
- Remember that the pool ID is the first number in a PG ID.(记住pool ID是PG ID的第一个数字。)
- For example, the PG 29.1c belongs to the pool whose ID is 29.(例如PG 29.1c属于ID为29的池。)
[ceph: root@serverc /]# ceph osd lspools
… …, 29 mytest, //仅为命令示例,输出结果根据实际情况而定,假设有一个编号为29的存储池
过滤ceph pg dump pgs_brief命令的输出,只显示以myfast池ID开头的pg。
[ceph: root@serverc /]# ceph pg dump pgs_brief | grep -F 29.
[ceph: root@serverc /]# ceph pg map 29.1c
osdmap e382 pg 4.1c (4.1c) -> up [8,6] acting [8,6]
1)创建用于纠删码池的ceph CRUSH规则
对于erasure coding而言,ceph在创建EC存储池时会自动创建一个同名的rule,EC存储池通过profile调用rule
示例:首先创建新的myprofile纠删码配置文件,然后基于该配置文件创建myecpool池:
[ceph: root@serverc /]# ceph osd erasure-code-profile set myprofile k=2 m=1 \
crush-root=DC1 \
crush-failure-domain=rack \
crush-device-class=ssd
[ceph: root@serverc /]# ceph osd pool create myecpool 32 32 erasure myprofile
[ceph: root@serverc /]# ceph osd crush rule ls
replicated_rule
inDC1
myecpool
7、通过解码Bianry二进制版本更新CRUSH地图
|
Action |
Command |
|
Export a binary copy of the current map 导出当前map地图的二进制副本 |
ceph osd getcrushmap -o binfile |
|
Decompile a CRUSH map binary into a text file 将CRUSH地图二进制反编译为文本文件 |
crushtool -d binfile -o textfile |
|
Compile a CRUSH map from text 从文本中编译CRUSH地图 |
crushtool -c textfile -o binfile |
|
Perform dry runs on a binary CRUSH map and simulate placement group creation 在二进制CRUSH地图上执行演练,并模拟放置组的创建 |
crushtool -i binfile --test --show-mappings crushtool -i binfile --test --show-bad-mappings crushtool -i binfile --test --show-utilization crushtool -i binfile --test --show-utilization-all crushtool -i binfile --test --statistics |
|
Import a binary CRUSH map into the cluster 将一个二进制CRUSH映射导入集群 |
ceph osd setcrushmap -i binfile |
提示:ceph osd getcrushmap 和 ceph osd setcrushmap 命令也是一种非常有用的备份和还原集群CRUSH地图的方法!
Calculating the Number of Placement Groups(计算归置组PG的数量)
![]()
RedHat recommends approximated 100 to 200 placement groups per OSD.
8、手动映射PG
1)使用ceph osd pg-upmap-items 命令可以手动映射PG到OSD设备。
旧版本客户端不支持该功能,因此需使用 ceph osd set-require-min-compat-client 命令设置客户端最低版本为luminous(12版本)
- 命令:ceph osd set-require-min-compat-client luminous
[ceph: root@serverc /]# ceph osd set-require-min-compat-client luminous
set require_min_compat_client to luminous
下面的示例将PG 3.25从osd 2和0重新映射到osd 1和0:
- 命令:ceph osd pg-upmap-items 3.25 2 1
[ceph: root@serverc /]# ceph pg map 3.25
osdmap e384 pg 3.25 (3.25) -> up [2,0] acting [2,0]
[ceph: root@serverc /]# ceph osd pg-upmap-items 3.25 2 1
set 3.25 pg_upmap_items mapping to [2->1]
[ceph: root@serverc /]# ceph pg map 3.25
osdmap e384 pg 3.25 (3.25) -> up [1,0] acting [1,0]
2)要重新定义上百个PGs,则上面的方法并不方便实际实施操作。此时,osdmaptool命令就比较有用了。
osdmaptool 是 Ceph 存储集群的一个工具,用于直接操作和分析 Object Storage Daemon (OSD) 映射文件(osdmap)。OSD 映射文件包含了集群中的 OSDs 相关的信息,例如它们的状态(比如 up 或 down)、权重等,以及 PG(Placement Group)到 OSD 的映射关系。 命令 osdmaptool 是在没有运行一个完整的 Ceph 集群的情况下,用来检查和修改 OSD 映射的。
在生产环境中,更常见的是使用 Ceph 提供的命令行工具 ceph osd 来管理 PG 映射,而不是直接使用 osdmaptool,因为后者可能会导致集群状态不一致,如果不恰当地使用。在实际操作前,应确保充分了解命令的影响,并且有适当的备份和恢复计划。
在实际环境中,你应该谨慎使用 osdmaptool,因为对 osdmap 的错误操作可能会导致集群状态混乱。通常,osdmaptool 用于测试、分析和故障排除,而不是用于日常集群管理。在修改 osdmap 之前,请确保有足够的备份,并且对 Ceph 集群的工作原理有深入的了解。在生产环境中,推荐使用 Ceph 提供的标准命令行工具 ceph 进行操作,因为它提供了更高层次的抽象和安全保护。
将映射导出为文件。下面的命令保存映射到./om文件。
[ceph: root@serverc /]# ceph osd getmap -o ./om
got osdmap epoch 400
使用 osdmaptool 命令的--test-map-pgs选项显示PG的实际分布的情况。
--test-map-pgs下面的命令打印ID为3的池的分布:
[ceph: root@serverc /]# osdmaptool ./om --test-map-pgs --pool 3
osdmaptool: osdmap file './om'
pool 3 pg_num 50
#osd count first primary c wt wt
osd.0 34 4 4 0.00979614 1 //osd.0有34个PG
osd.1 39 5 5 0.00979614 1 //osd.1有39个PG
osd.2 27 3 3 0.00979614 1 //osd.2有27个PG
... ...
osdmaptool: 调用 osdmaptool 工具。
- ./file: 这指定了要操作的 osdmap 文件的路径。在此示例中,它假设在当前目录中有一个名为 file 的 osdmap 文件。
- --test-map-pgs: 这个选项告诉 osdmaptool 执行一个测试来映射 PGs(Placement Groups)。这是一个模拟操作,用于验证 PGs 如何分布在 OSDs 上。
- --pool 3: 这个选项指定了要测试映射的特定存储池的编号,即编号为 3 的池。
3)生成重新平衡pg的命令。使用 osdmaptool 命令的--upmap选项将命令存储在文件中。(通过--upmap选项自动生成调优方案文件。)
示例:生成 cmds.txt 文件,使用来更新编号为 3 的存储池的 PG 到 OSD 的映射关系
[ceph: root@serverc /]# osdmaptool ./om --upmap ./cmds.txt --pool 3
osdmaptool: osdmap file './om'
writing upmap command output to: ./cmds.txt
checking for upmap cleanups
upmap, max-count 10, max deviation 5
[ceph: root@serverc /]# cat cmds.txt
ceph osd pg-upmap-items 3.1 0 2
ceph osd pg-upmap-items 3.3 1 2
ceph osd pg-upmap-items 3.6 0 2
... ...
[ceph: root@serverc /]# bash ./cmds.txt //执行文件中的命令,实现重新分布
set 3.1 pg_upmap_items mapping to [0->2]
set 3.3 pg_upmap_items mapping to [1->2]
set 3.6 pg_upmap_items mapping to [0->2]
... ...
- osdmaptool: 调用 osdmaptool 工具。
- ./om: 指定了要操作的 OSD 地图文件的路径。在这个例子中,该文件位于当前目录下,并且命名为 om。
- --upmap: 指定了要执行的操作是更新 PG 到 OSD 的映射关系(upmap)。这通常用于优化数据分布,手动调整 PG 的映射,以达到更平衡的数据分布。
- ./cmds.txt: 指定了一个包含具体 upmap 命令的文件,这些命令定义了 PG 到 OSD 的新映射关系。cmds.txt 文件位于当前目录下。
- --pool 3: 指定了操作应用于的池(pool)的编号。这里指定的是编号为 3 的池。
Lab: 管理和定制CRUSH地图
1. 执行环境脚本
[kiosk@foundation0 ~]$ ssh student@workstation
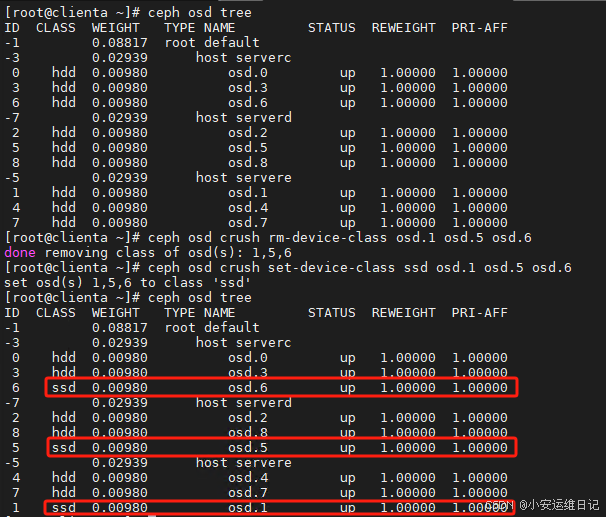
[student@workstation ~]# lab start map-crush // 环境脚本会将部分设备class标记为ssd,设置mon_allow_pool_delete设置为true.(osd.1,osd.5,osd.6的class设置为ssd)
## 或者:也可用自己删除OSD的class标记,然后再设置标记
[root@foundation0 ~]# ssh root@clienta //clienta需要提前安装ceph-common
[root@clienta ~]# ceph osd crush rm-device-class osd.1 osd.5 osd.6
[root@clienta ~]# ceph osd crush set-device-class ssd osd.1 osd.5 osd.6
列出集群中可用的设备类
[root@foundation0 ~]# ssh root@serverc
[root@serverc ~]# cephadm shell
[ceph: root@serverc /]# ceph -s //查看集群状态
[ceph: root@serverc /]# ceph osd crush class ls
[
"hdd",
"ssd"
]
打开CRUSH tree,定位SSD存储支持的osd。
[ceph: root@serverc /]# ceph osd crush tree
ID CLASS WEIGHT TYPE NAME
-1 0.08817 root default
-3 0.02939 host serverc
0 hdd 0.00980 osd.0
3 hdd 0.00980 osd.3
6 ssd 0.00980 osd.6 # SSD
-7 0.02939 host serverd
2 hdd 0.00980 osd.2
8 hdd 0.00980 osd.8
5 ssd 0.00980 osd.5 # SSD
-5 0.02939 host servere
4 hdd 0.00980 osd.4
7 hdd 0.00980 osd.7
1 ssd 0.00980 osd.1 # SSD
2. 添加CRUSH地图规则
添加一个名为 onssd 的新CRUSH映射规则,以带有SSD设备的硬盘为目标。
- 命令:ceph osd crush rule create-replicated <name> <root> <failure-domain-type> [class]
[ceph: root@serverc /]# ceph osd crush rule create-replicated onssd default host ssd
列表并查看crush规则
[ceph: root@serverc /]# ceph osd crush rule ls
[ceph: root@serverc /]# ceph osd crush rule dump
创建一个名为myfast的新复制池,包含32个放置组,使用onssd CRUSH映射规则。
[ceph: root@serverc /]# ceph osd pool create myfast 32 32 onssd
pool 'myfast' created
验证名为myfast的池只使用由SSD存储支持的osd。
[ceph: root@serverc /]# ceph osd lspools
... ...
9 myfast
列出集群中所有pg。池ID是PG ID的第一个数字。例如,PG 9.5属于ID为9的池。
[ceph: root@serverc /]# ceph pg dump pgs_brief | grep "^9."
PG_STAT STATE UP UP_PRIMARY ACTING ACTING_PRIMARY
9.5 active+clean [1,6,5] 1 [1,6,5] 1
9.6 active+clean [6,1,5] 6 [6,1,5] 6
9.7 active+clean [5,6,1] 5 [5,6,1] 5
...
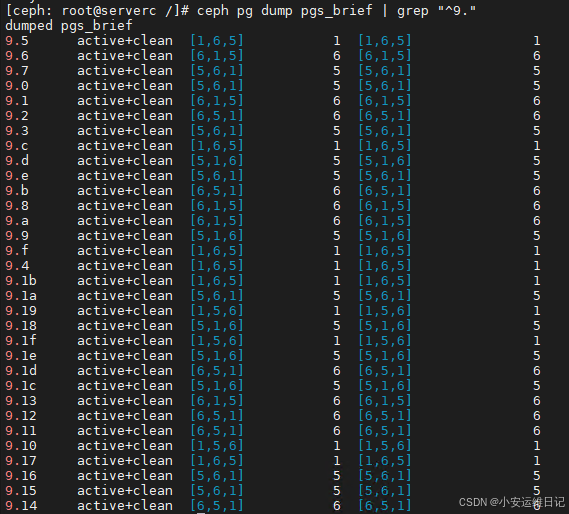
ID为9的 myfast池 只使用 osd.6、osd.5、osd.1。这是仅有的带有SSD驱动器的硬盘。
3. 创建CRUSH地图层次结构
创建一个新的CRUSH地图层次结构,匹配这个基础设施:
# ceph osd crush tree
default-cl260 (root bucket)
rack1 (rack bucket)
hostc (host bucket)
osd.1
osd.0
osd.2
rack2 (rack bucket)
hostd (host bucket)
osd.5
osd.3
osd.4
rack3 (rack bucket)
hoste (host bucket)
osd.6
osd.7
osd.8
创建一个类型为 root的顶层 bucket,名为 default-cl260(之后可以在 default-cl260 bucket 下组织其他的 bucket 或者 OSD,以匹配存储基础设施的物理或逻辑布局)
[ceph: root@serverc /]# ceph osd crush add-bucket default-cl260 root
added bucket default-cl260 type root to crush map
创建一个类型为rack的bucket,名为 rack1、2、3(这个 bucket 可以用来组织位于同一个物理机架中的 OSD)(以此类推)
[ceph: root@serverc /]# ceph osd crush add-bucket rack1 rack
added bucket rack1 type rack to crush map
[ceph: root@serverc /]# ceph osd crush add-bucket rack2 rack
added bucket rack2 type rack to crush map
[ceph: root@serverc /]# ceph osd crush add-bucket rack3 rack
added bucket rack2 type rack to crush map
创建一个类型为host的bucket,名为 hostc、d、e(以此类推)
[ceph: root@serverc /]# ceph osd crush add-bucket hostc host
add bucket hostc type host to cursh map
[ceph: root@serverc /]# ceph osd crush add-bucket hostd host
add bucket hostd type host to cursh map
[ceph: root@serverc /]# ceph osd crush add-bucket hoste host
add bucket hostd type host to cursh map
使用ceph osd crush move命令来构建层次结构。
[ceph: root@serverc /]# ceph osd crush move rack1 root=default-cl260 // 将名为rack1的rack bucket 移动到 CRUSH映射层级中名为 default-cl260 的root bucket下
[ceph: root@serverc /]# ceph osd crush move rack2 root=default-cl260
[ceph: root@serverc /]# ceph osd crush move rack3 root=default-cl260
[ceph: root@serverc /]# ceph osd crush move hostc rack=rack1 // 将名为hostc的host bucket 移动到 CRUSH映射层级中名为 rack1 的rack bucket下
[ceph: root@serverc /]# ceph osd crush move hostd rack=rack2
[ceph: root@serverc /]# ceph osd crush move hoste rack=rack3
显示CRUSH映射树以验证新的层次结构。
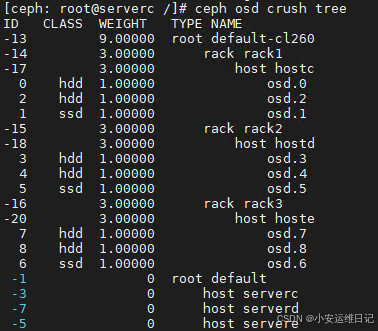
[ceph: root@serverc /]# ceph osd crush tree
ID CLASS WEIGHT TYPE NAME
-13 0 root default-cl260
-14 0 rack rack1
-17 0 host hostc
-15 0 rack rack2
-18 0 host hostd
-16 0 rack rack3
-20 0 host hoste
... ...
将osd作为叶子放置在新树中。
- 命令:ceph osd crush set osd.0 1.0 root=default-cl260 rack=rack1 host=hostc
- ceph: Ceph 集群的命令行接口。
- osd crush: 指定操作是针对 OSD 的 CRUSH 映射。
- set: 表示设置或更新指定 OSD 的 CRUSH 属性。
- osd.0: 指定要操作的 OSD 编号,在这里是 OSD 编号 0。
- 1.0: 这是 OSD.0 的权重。权重是一个浮点数,用来表示该 OSD 在数据分布中的相对比例。权重越大,OSD 存储的数据越多。
- root=root-default-cl260: 指定该 OSD 属于名为 root-default-cl260 的 root bucket。
- rack=rack1: 指定该 OSD 属于名为 rack1 的 rack bucket。
- host=hostc: 指定该 OSD 属于名为 hostc 的 host bucket。
//将编号为osd.0 设置为权重1.0,并将其放置在 CRUSH 映射的特定位置,即在名为 root-default-cl260(root bucket)下的 hostc(host bucket)下的 rack1(rack bucket),以此类推
[ceph: root@serverc /]# ceph osd crush set osd.0 1.0 root=default-cl260 rack=rack1 host=hostc
[ceph: root@serverc /]# ceph osd crush set osd.1 1.0 root=default-cl260 rack=rack1 host=hostc
[ceph: root@serverc /]# ceph osd crush set osd.2 1.0 root=default-cl260 rack=rack1 host=hostc
[ceph: root@serverc /]# ceph osd crush set osd.3 1.0 root=default-cl260 rack=rack2 host=hostd
[ceph: root@serverc /]# ceph osd crush set osd.4 1.0 root=default-cl260 rack=rack2 host=hostd
[ceph: root@serverc /]# ceph osd crush set osd.5 1.0 root=default-cl260 rack=rack2 host=hostd
[ceph: root@serverc /]# ceph osd crush set osd.6 1.0 root=default-cl260 rack=rack3 host=hoste
[ceph: root@serverc /]# ceph osd crush set osd.7 1.0 root=default-cl260 rack=rack3 host=hoste
[ceph: root@serverc /]# ceph osd crush set osd.8 1.0 root=default-cl260 rack=rack3 host=hoste
显示CRUSH地图树来验证新的OSD位置
[ceph: root@serverc /]# ceph osd crush tree
4. 使用二进制方式添加新CRUSH规则应用到集群
1)使用ceph osd getcrushmap命令检索当前的CRUSH地图。将二进制映射存储在~/cm-org.bin文件中。
-
命令:ceph osd getcrushmap -o filename.bin
ceph osd getcrushmap:从 Ceph 集群中获取当前的 CRUSH 地图
-o:指定输出文件路径,将 CRUSH 地图保存为二进制文件
[ceph: root@serverc /]# ceph osd getcrushmap -o ~/cm-org.bin
40
使用crushtool命令将二进制映射文件反编译为~/cm-org.txt文本文件。
- 命令:crushtool -d filename.bin -o test.txt //指定要解码的二进制 CRUSH 地图文件
-d:将二进制 CRUSH 地图解码为文本格式
[ceph: root@serverc /]# crushtool -d ~/cm-org.bin -o ~/cm-org.txt
[ceph: root@serverc /]# echo $?
0
将CRUSH地图的副本保存为~/cm-new.txt,并在文件末尾添加以下规则。
[ceph: root@serverc /]# cp ~/cm-org.txt ~/cm-new.txt
[ceph: root@serverc /]# vi ~/cm-new.txt
... ...
rule onssd {
id 3
type replicated
min_size 1
max_size 10
step take default class ssd
step chooseleaf firstn 0 type host
step emit
}
rule hdd-first { //添加hdd-first规则
id 5
type replicated
min_size 1
max_size 10
step take default-cl260 class hdd
step chooseleaf firstn 0 type rack
step emit
}
# end crush map
在此规则下,第一个副本使用default-cl260中的OSD(由SSD存储支持),其余副本使用来自不同机架的HDD存储支持的OSD。
2)编译你的新CRUSH地图。
- 命令:crushtool -c test.txt -o filename.bin //将文本格式的 CRUSH 地图编译为二进制格式
-c :指定要编译的 CRUSH 地图文本文件
-o :指定输出文件路径
[ceph: root@serverc /]# crushtool -c ~/cm-new.txt -o ~/cm-new.bin
在将新映射应用到正在运行的集群之前,使用带--show-mappings选项的crushtool命令来验证第一个OSD总是来自rack1。
-
命令:crushtool --show-mappings -i filename.bin
--show-mappings:显示 CRUSH 地图的映射规则
-i :指定要检查的二进制 CRUSH 地图文件
[ceph: root@serverc /]# crushtool --show-mappings -i ~/cm-new.bin
... ...
CRUSH rule 5 x 1013 [5,4,7]
CRUSH rule 5 x 1014 [1,3,7]
CRUSH rule 5 x 1015 [6,2,3]
CRUSH rule 5 x 1016 [5,0,7]
... ...
使用 ceph osd setcrushmap 命令将新的CRUSH映射应用到集群。
[ceph: root@serverc /]# ceph osd setcrushmap -i ~/cm-new.bin
41
验证新的ssd-first规则现在是否可用。
[ceph: root@serverc /]# ceph osd crush rule ls
replicated_rule
onssd
hdd-first # 新增规则
3)创建一个名为testcrush的新复制池,包含32个放置组,并使用ssd-first CRUSH映射规则。
[ceph: root@serverc /]# ceph osd pool create testcrush 32 32 hdd-first
cephpool 'testcrush' created
验证名为testcrush的池中放置组的第一个osd是来自rack1的osd,这些osd是osd.1, osd.5, osd.6
[ceph: root@serverc /]# ceph osd lspools
... ...
10 testcrush
[ceph: root@serverc /]# ceph pg dump pgs_brief | grep "^10."
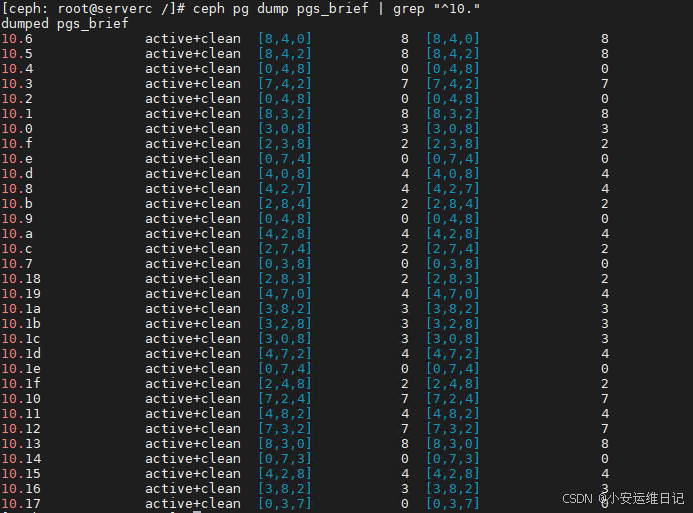
此时,ID为10的 testcrush池 已经没有在使用带有SSD驱动器的硬盘 osd.6、osd.5、osd.1。
补充:手动调整将池为10.7 PG中的OSD.3 调整到 OSD.4
[ceph: root@serverc /]# ceph osd pg-upmap-items 10.7 3 4
set 10.7 pg_upmap_items mapping to [3->4]
[ceph: root@serverc /]# ceph pg map 10.7 ## 验证
osdmap e248 pg 10.7 (10.7) -> up [0,4,8] acting [0,4,8]
[ceph: root@serverc /]# exit
[root@serverc ~]# exit
二、管理 OSD Map
1、描述OSD map
集群中的OSD映射包含每个OSD的地址和状态、存储池列表和详细信息,以及OSD的近容量限制等信息。当发生集群结构变化时,比如添加或移除OSD时,MON会自动更新地图。MON维护这地图的历史版本。ceph通过一个只增正数识别每个地图的版本,这个版本信息被称为epochs。
ceph status -f json-pretty命令显示每个MAP的epochs。
-
命令:ceph status -f json-pretty
[ceph: root@serverc /]# ceph status -f json-pretty
... ...
"osdmap": {
"epoch": 478, //版本信息为478
"num_osds": 15,
... ...
},
... ...
使用ceph map dump子命令显示每个单独的MAP,例如ceph osd dump。
-
命令:ceph map dump
[ceph: root@serverc /]# ceph osd dump
epoch 478
fsid 11839bde-156b-11ec-bb71-52540000fa0c
create 2022-09-14T14:50:39.401260+0000
... ...
2、使用Paxos更新集群映射
MONs 使用Paxos算法确保集群状态的信息统一(Paxos是一个分布式基于消息传递的一致性算法)。每次一个MON修改了地图后,都会通过Paxos协议发送更新数据给其他MON主机。
Ceph只有在大多数MON同意更新后才会提交新版本的地图。
Note: majority means more than half of the available monitors.
注意:多数表示超过一半的可用MON。
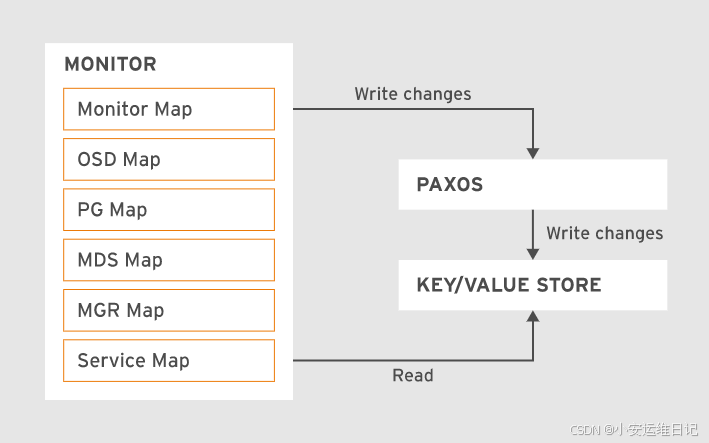
通常OSD都会向MON报告自己的状态。另外,OSD彼此之间也会交换心跳信息,这样如果一个OSD失败,可以被其他OSD检测到,并提交失败信息给MON。
3、Monitor Quorum/ˈkwɔːrəm/
MON 必须同意leader 并建立法定人数。一个MON是leader,其他的都被称为peons。任何MON都可以要求进行leader选举,当其中一个MON启动时,总会发生这种情况。
在选举完成并选出leader后,leader将向所有其他MON请求最新的地图epoch版本。这确保leader拥有集群的最新地图。如果大多数MON加入,则建立仲裁,集群可以运行。
Quorum = floor(nodes/2)+1
#floor()表示总是向下舍入。
For example: Quorum= floor(5/2)+1 = floor(2.5)+1 = 2+1 = 3
如果其他MON故障,则不再有仲裁,并且集群故障。
在分布式系统中,包括 Ceph 存储集群,"quorum" 是指系统中的一组组件(如服务器或进程)达到足够的数量以便能够一致地做出决策或维持正常运行状态的概念。对于 Ceph 以及其他需要高可用性的分布式存储系统而言,维持 quorum 是至关重要的,因为它确保了系统的一致性和可靠性。
在 Ceph 集群中,Monitor(简称 Mon)是负责集群元数据、配置、状态和映射信息的守护进程。Monitor 通常部署成奇数个,如三个或五个,以避免"脑裂"(split-brain)现象,脑裂是指集群的不同部分独立并对外宣称自己是正常运行的状态。
Monitor Quorum 指的是:
-
足够数量的 Monitor 实例:Quorum 要求集群中的大多数 Monitor 实例是活跃的并且相互之间能够通信。例如,在三个 Monitor 实例的集群中,至少需要两个 Monitor 实例是活跃的,以便它们可以进行投票并就集群状态达成一致。
-
决策机制:Monitor 实例通过投票机制来决定关键操作,如更新集群状态或者接受客户端的变更请求。只有当有足够数量的 Monitor 实例达成一致意见时,这些操作才会被执行。
-
高可用性和一致性:通过维持 quorum,Ceph 确保集群的状态在所有 Monitor 实例间保持一致,即使其中一些实例发生故障。这样可以防止数据丢失或损坏,并确保集群的正常运行。
如果 Ceph 集群的 Monitor 实例无法形成 quorum,那么集群可能会进入一种只读模式,以保护数据免受可能由于状态不一致而导致的损害。集群管理员必须解决导致 quorum 丢失的问题,如网络分区、硬件故障或配置错误,然后 Monitor 实例才能重新形成 quorum,并且集群才能恢复正常的读写操作。
4、Monitor Leases/ˈliːsɪz/租期
MON建立quorum之后,leader开始向所有其他MON分发短期租约,允许它们将集群映射分发到osd和客户机。leader定期更新租约。默认情况下,它每三秒执行一次。如果一个MON的租约到期并且没有续签,它就假定leader已经死亡,MON调用一个新的选举。当一个leader感知到一个OSD失败,就会更新地图,增加epoch数值,使用Paxos协议通知其他mon,同时收回其他mon的租期。
OSD Map commands:
|
command |
Action |
|
ceph osd dump |
备份OSD地图到标准输出 |
|
ceph osd getmap -o binfile |
导出一份二进制OSD地图到文件 |
|
osdmaptool --print binfile |
人性化显示二进制地图到标准输出 |
Lab: 管理 OSD Map
1. 设置epoch值、full_ratio值、nearfull_ratio值
[root@foundation0 ~]# ssh workstation
[student@workstation ~]# lab start map-osd
...
Setting full ratio parameter to 0.95 ....
Setting nearfull ratio parameter to 0.85 ..
脚本重新设置了 full_ratio 和 nearfull_ratio参数的值,并在clienta主机安装了ceph-base软件包
在您的实验室环境中记录当前的epoch值。记录full_ratio和nearfull_ratio的设置值。
[root@foundation0 ~]# ssh root@serverc
[root@serverc ~]# cephadm shell
[ceph: root@serverc /]# ceph -s
[ceph: root@serverc /]# ceph osd dump //备份OSD地图到标准输出
epoch 250
fsid 3e5189c8-72ed-11ee-a42f-52540000fa0c
created 2023-10-25T04:16:29.530274+0000
modified 2023-10-26T03:37:04.930373+0000
flags sortbitwise,recovery_deletes,purged_snapdirs,pglog_hardlimit
crush_version 41
full_ratio 0.95 # 参数1
backfillfull_ratio 0.9
nearfull_ratio 0.85 # 参数2
...
设置full_ratio和nearfull_ratio并验证值。
[ceph: root@serverc /]# ceph osd set-full-ratio 0.97
osd set-full-ratio 0.97
[ceph: root@serverc /]# ceph osd set-nearfull-ratio 0.9
osd set-nearfull-ratio 0.9
验证:
[ceph: root@serverc /]# ceph osd dump | grep -ie "epoch" -ie "_ratio"
epoch 252
full_ratio 0.97
backfillfull_ratio 0.9
nearfull_ratio 0.9
2. 导出并导入OSD映射
1)Extract and view the OSD map. 导出并查看OSD map。
-
命令:ceph osd getmap -o map.bin
ceph osd getmap:从当前运行的 Ceph 集群中获取 OSD 地图。
-o map.bin:将 OSD 地图保存为二进制文件 map.bin。
-
命令:osdmaptool --print map.bin
osdmaptool --print:打印 OSD 地图的内容。
[ceph: root@serverc /]# ceph osd getmap -o map.bin
[ceph: root@serverc /]# osdmaptool --print map.bin
2)Extract and decompile the current CRUSH map. 导出并反编译当前的CRUSH地图。
-
命令:osdmaptool --export-crush crush.bin map.bin
osdmaptool --export-crush:从 OSD 地图中提取 CRUSH 地图。
crush.bin:指定输出的 CRUSH 地图文件。
map.bin:指定输入的 OSD 地图文件。
-
命令:crushtool -d crush.bin -o crush.txt
crushtool -d:将二进制格式的 CRUSH 地图解码为文本格式。
-
命令:crushtool -c crush.txt -o crushnew.bin
crushtool -c:将文本格式的 CRUSH 地图编译为二进制格式。
[ceph: root@serverc /]# osdmaptool --export-crush crush.bin map.bin //从OSD地图中提取 CRUSH地图
osdmaptool: osdmap file 'map.bin'
osdmaptool: exported crush map to crush.bin
[ceph: root@serverc /]# crushtool -d crush.bin -o crush.txt //将二进制文件解析为明文文件
[ceph: root@serverc /]# crushtool -c crush.txt -o crushnew.bin //将明文文件编译为二进制文件
3)将新的crush地图导入到osd地图文件中
-
命令:osdmaptool --import-crush crushnew.bin mapnew.bin
osdmaptool --import-crush:将新的 CRUSH 地图导入到 OSD 地图中。
crushnew.bin:指定新的 CRUSH 地图文件。
mapnew.bin:指定输出的新的 OSD 地图文件。
-
命令:osdmaptool --test-map-pgs-dump mapnew.bin
osdmaptool --test-map-pgs-dump:测试新的 OSD 地图的 PG(Placement Group)映射,并输出详细信息。
[ceph: root@serverc /]# cp map.bin mapnew.bin
[ceph: root@serverc /]# osdmaptool --import-crush crushnew.bin mapnew.bin //将新的crush地图导入到新的osd地图文件中
osdmaptool: osdmap file 'mapnew.bin'
osdmaptool: imported 2787 byte crush map from crushnew.bin
osdmaptool: writing epoch 254 to mapnew.bin
[ceph: root@serverc /]# osdmaptool --test-map-pgs-dump mapnew.bin //查看PG和OSD之间的对应关系
[ceph: root@serverc /]# exit
[root@serverc ~]# exit
在 Ceph 存储集群中,OSD map(Object Storage Daemon Map)和 CRUSH map(Controlled Replication Under Scalable Hashing Map)是两个不同的组件,但它们之间存在密切的联系,共同工作以决定数据如何在集群中存储和分布。
- 1)OSD Map (OSDMap):
OSDMap 包含了集群中所有 OSDs 的状态和元数据信息。这包括每个 OSD 的标识符(ID)、它们的上下线状态(up/down)、它们是否被标记为参与数据分布(in/out)、以及它们的权重(用于数据分布的负载均衡)。OSDMap 还包含了有关 PGs 到 OSDs 映射的信息,以及集群的版本和历史记录。
- 2)CRUSH Map:
CRUSHMap 是一个高级的、可扩展的哈希算法,用于计算数据(如对象)应该存储在哪些 OSD 上。CRUSH 算法允许数据根据集群的拓扑结构和规则(例如,副本数量、故障域等)智能地分布。CRUSHMap 包含了集群的物理布局,例如机架、服务器和磁盘的层次结构,以及副本和数据分布策略。
两者的关系:
CRUSHMap 为数据分布提供了规则和拓扑结构,而 OSDMap 包含了关于每个 OSD 的具体状态和元数据。当一个客户端写入数据时,Ceph 会使用 CRUSH 算法和当前的 CRUSHMap 来决定将数据放置到哪些 OSDs 上。然后,它会查看 OSDMap 来确定这些 OSDs 的当前状态和位置,从而找到正确的 OSDs 并执行写入操作。
简而言之,CRUSHMap 决定了数据应该如何分布在集群中,而 OSDMap 提供了集群中 OSDs 的当前状态和可用性的快照。两者结合,确保了数据的高可用性、高耐久性和一致性。在集群的日常运维中,这两张地图会随着集群状态的变化而定期更新。
思维导图:
小结:
本篇为 【RHCA认证 - CL260 | Day05:创建和自定义存储地图】的开篇学习笔记,希望这篇笔记可以让您初步了解如何管理和定制CRUSH地图、如何管理 OSD Map,不妨跟着我的笔记步伐亲自实践一下吧!
Tip:毕竟两个人的智慧大于一个人的智慧,如果你不理解本章节的内容或需要相关环境、视频,可评论666并私信小安,请放下你的羞涩,花点时间直到你真正的理解。


















 1099
1099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











