




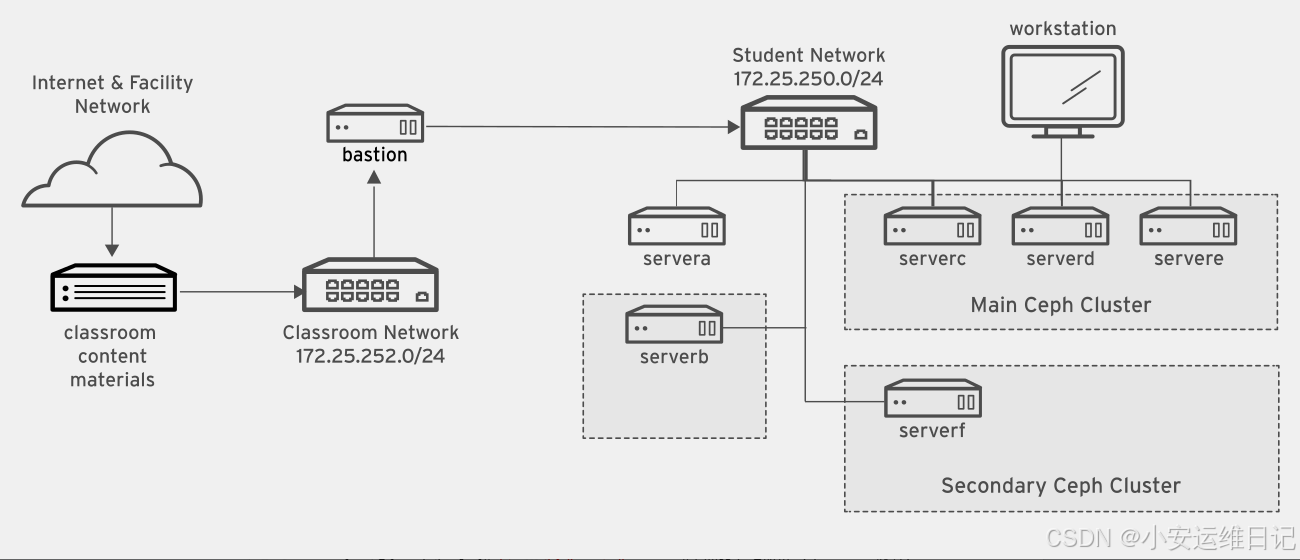
一、实验环境介绍
| 主机名称 | IP地址 | 介绍 |
| classroom | 172.25.254.254 | 提供资源共享的服务器(启动该虚拟机后才可以启动其他虚拟机) |
| workstation.lab.example.com | 172.25.250.9 | 提供图形环境(共享服务器) |
| clienta.lab.example.com | 172.25.250.10 | 客户端A |
| clientb.lab.example.com | 172.25.250.11 | 客户端B |
| serverc.lab.example.com | 172.25.250.12 | serverc |
| serverd.lab.example.com | 172.25.250.13 | serverd |
| servere.lab.example.com | 172.25.250.14 | servere |
| serverf.lab.example.com | 172.25.250.15 | serverf(第二个ceph存储) |
| serverg.lab.example.com | 172.25.250.16 | serverg(空闲的存储节点) |
| bastion.lab.example.com | 172.25.250.254 | 多个虚拟机之间的路由器 |
- classroom主机:提供资源共享的服务器(启动该虚拟机后才可以启动其他虚拟机)
- workstation主机:提供图形环境(共享服务器)
- clienta:客户端A,已安装cephadm容器,并具备管理主ceph集群环境需要的配置文件
- clientb:客户端B
- serverc、serverd、servere:主ceph集群环境
- serverf:第二套ceph存储环境,已安装cephadm容器,并具备管理第二个ceph存储环境的配置文件
二、实验环境密码
真机foundation0主机:kiosk 账户的密码为 redhat
真机foundation0主机:root 账户的密码为 Asimov
其他虚拟机:root 账户的密码为 redhat,student 账户的密码为 student
foundation0主机为真机,上面所有其他主机均为虚拟机!
在foundation0主机上面管理虚拟机的方法:
[root@foundation0 ~]# rht-vmctl status all #查看所有虚拟机状态
[root@foundation0 ~]# rht-vmctl start classroom #启动classroom虚拟机
[root@foundation0 ~]# rht-vmctl start all #启动所有虚拟机(classroom除外)
[root@foundation0 ~]# rht-vmctl fullreset all #重置所有虚拟机(classroom除外)或者使用虚拟系统管理器,直接管理虚拟机(图形界面)
[root@foundation0 ~]# virt-manager #查看所有虚拟机(需要root权限)三、CEPH介绍
1、传统存储的核心挑战
容量瓶颈
- 数据量年均增长超50%(IDC 2025预测),传统纵向扩展(Scale-Up)架构难以支撑。
成本压力
- 专用硬件溢价(如EMC高端阵列单价超$1M)
- 厂商锁定导致的运维成本占比超总成本40%(Gartner 2024报告)
敏捷性缺失
- 封闭系统交付周期长达6-12个月,无法匹配云原生应用的迭代速度。
📌 典型案例:EMC VMAX系列需专用管理软件,扩容需停机,API兼容性受限。
2、存储类型技术矩阵
| 类型 | 访问协议 | 典型场景 | 性能特点 |
|---|---|---|---|
| 块存储 | iSCSI, FibreChannel | 虚拟机硬盘、数据库 | 低延迟(<1ms) |
| 文件存储 | NFS, SMB/CIFS | 共享文档、开发环境 | 高并发元数据处理 |
| 对象存储 | S3, Swift API | 云存储、AI训练数据湖 | 无限扩展性,EB级容量 |
💡 关键演进:Ceph通过统一架构同时支持三种存储接口,消除数据孤岛。
3、红帽SDS解决方案对比
| 产品 | 架构模型 | 强项场景 | Ceph差异点 |
|---|---|---|---|
| GlusterFS | 无中心元数据 | 非结构化数据(日志/备份) | 简单部署,弱一致性模型 |
| Ceph | CRUSH分布式算法 | 混合云存储、云原生平台 | 强一致性,企业级特性丰富 |
Ceph核心价值:
1)全栈支持
- RBD(块):OpenStack/Kubernetes持久化卷
- CephFS(文件):POSIX兼容的并行文件系统
- RGW(对象):AWS S3完全兼容API
2)云原生集成
- CSI驱动支持K8s动态供给
- 容器化部署(Cephadm管理框架)
Ceph技术架构核心优势:
1)去中心化设计
- CRUSH算法动态计算数据位置,消除元数据瓶颈
- 节点故障自动修复(自愈时间<10分钟/PB级集群)
2)硬件民主化
- 支持异构硬件(SATA SSD/NVMe/HDD混合部署)
- 成本较传统方案低60%(Facebook实际部署报告)
3)企业级特性
- 端到端加密(E2EE)
- 多租户QoS控制
- 跨区域异步复制
建议结合最新文档验证部署方案:Ceph官方文档 | 红帽Ceph Storage
4、Ceph版本演进关键节点
| 版本代号 | 主版本 | 发布时间 | 里程碑特性 |
|---|---|---|---|
| Luminous | 12.x | 2017.12 | BlueStore引擎(性能×3倍) |
| Nautilus | 14.x | 2019.03 | 跨集群灾备,CephFS多活 |
| Pacific | 16.x | 2021.03 | 全栈压缩,RBD即时克隆 |
| Quincy | 17.x | 2022.04 | 安全增强(TLS1.3),NVMe-oF支持 |
| Reef | 18.x | 2023.08 | 自适应缓存,ARM架构深度优化 |
🔥 当前推荐:生产环境应采用Quincy(17.2.7+)或Reef(18.2.0+),获得5年安全更新支持。
四、CEPH架构图
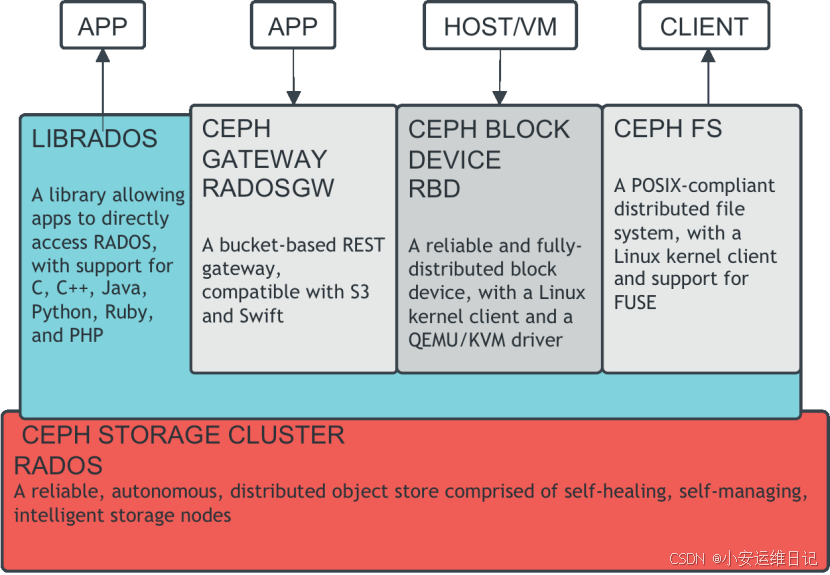
底层是一个名为RADOS的基于对象的存储后端(和正常理解的对象存储还不太一样)
RADOS(Reliable Autonomic Distributed Object Store)可靠的自动分布式对象存储,RADOS是具有自我检查、自我修复的基于软件的对象存储。
访问RADOS的方法很多:
- 通过C,C++,Java,Python,Ruby,PHP调用LIBRADOS库访问
- 通过RGW(RADOSGW)对象存储网关访问,RADOSGW可以提供REST API变成接口(对象存储:Object Storage)
- 通过RBD块方式访问,一般可以为虚拟机提供磁盘镜像文件(块存储:Block Storage)
- 通过POSIX兼容的文件系统方式访问(文件系统存储:Filesystem Storage)
Ceph采用分布式架构设计,提供企业级的软件定义存储解决方案。
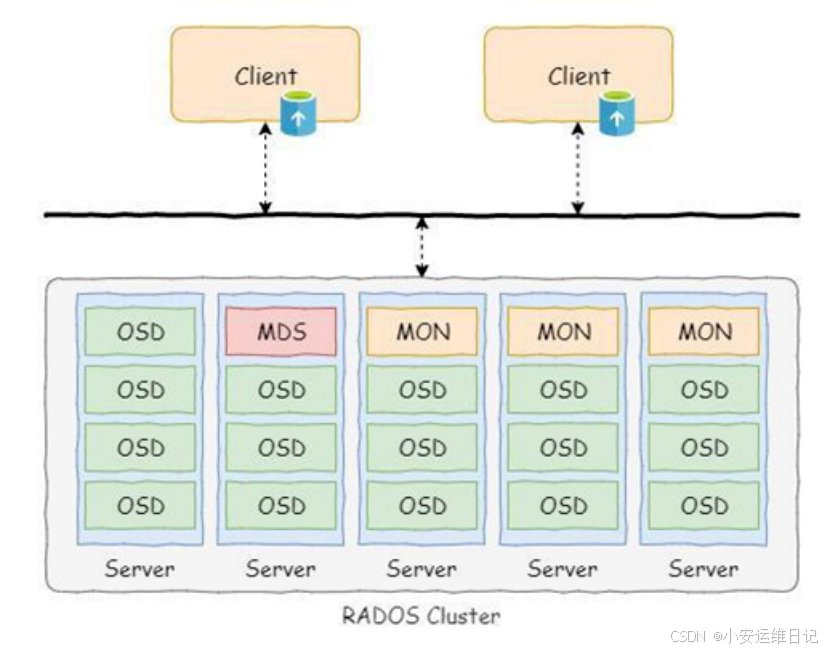
- MON(monitor):集群地图(maps),帮助其他服务器之间的协同(coordinate)。
- OSD(Object Storage Deivces):存储数据(store data)、处理数据复制(data replication)、恢复数据(recovery)、重新平衡数据(rebalancing)。
- MDS(Meta data Servers):为文件系统共享存储元数据,允许客户端POSIX命令访问。
- RGW:对象存储网关,为原始的对象存储提供Rest API接口。
- MGR(Manager):集群管理和监控
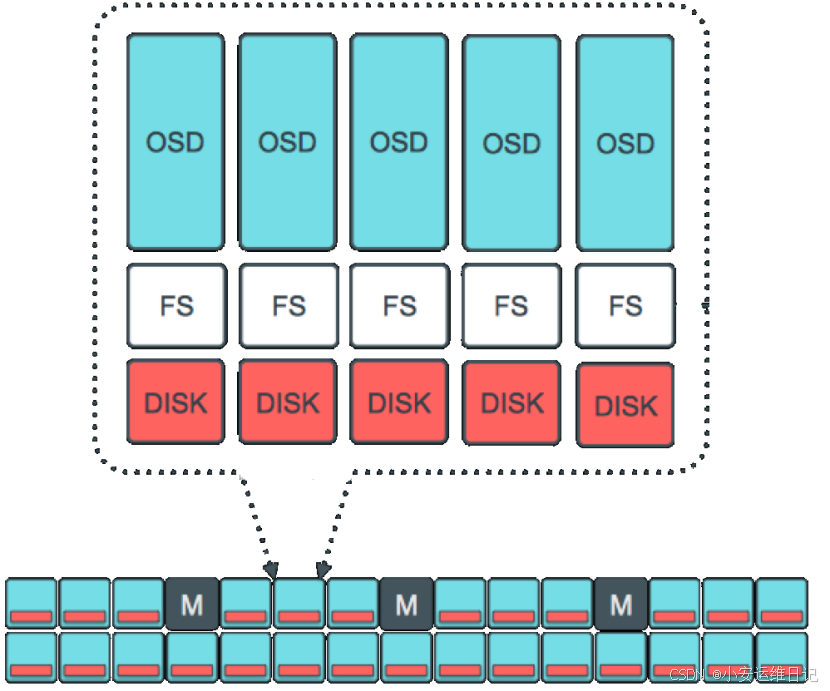
1.Each OSD daemon provides a storage device to the Ceph cluster.
每个OSD进程为ceph集群提供存储设备2.Normally, each storage device is formatted with a normal file system.
通常存储设备都会被格式化为文件系统(新版本不推荐再格式化文件系统)3.RedHat Ceph Storage currently only supports XFS file systems.
目前红帽的Ceph存储仅支持XFS文件系统4.Extended Attributes(xattrs) are used to store information about the internal object state, snapshot metadata,and ceph RADOS gateway Access Control Lists(ACLs).
扩展数据xattrs用来存储对象的状态,快照信息,对象存储网关的访问控制列表等信息。5.Extended attributes are enabled by default on XFS file systems.
attrs是XFS文件系统默认开启的功能。
五、Ceph CRUSH算法基本概念
1、有无中心节点
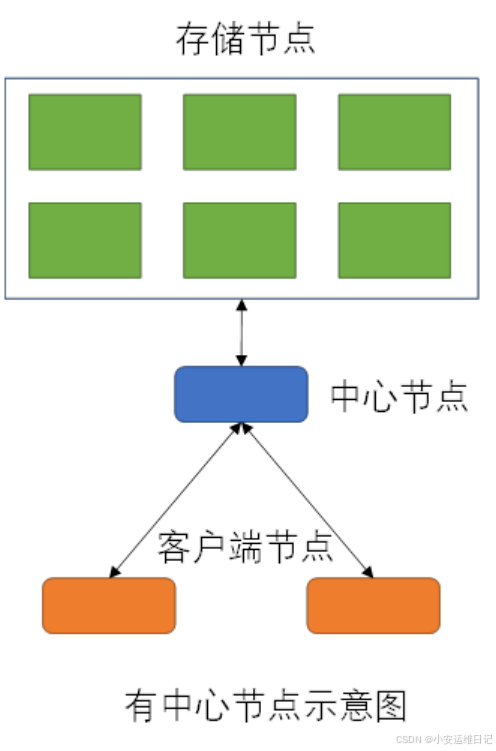
有中心节点:客户端需要通过中心控制器才可以定位数据,有单点故障和性能问题。中心节点需要算法,并记录数据库,客户端是傻瓜式的
无中心节点:客户端自身通过特定的算法,直接读写存储节点中的数据。
2、CRUSH 算法
CRUSH算法:全称是“Controlled Replication Under Scalable Hashing”在动态扩展的hash算法下可控的复制算法;在中心化的分布式存储架构中,一般采用Master节点来存储数据的具体位置信息,这样会有单点故障(SPOF)。而Ceph采用CRUSH算法来计算数据的位置信息,所有节点都是平等的。
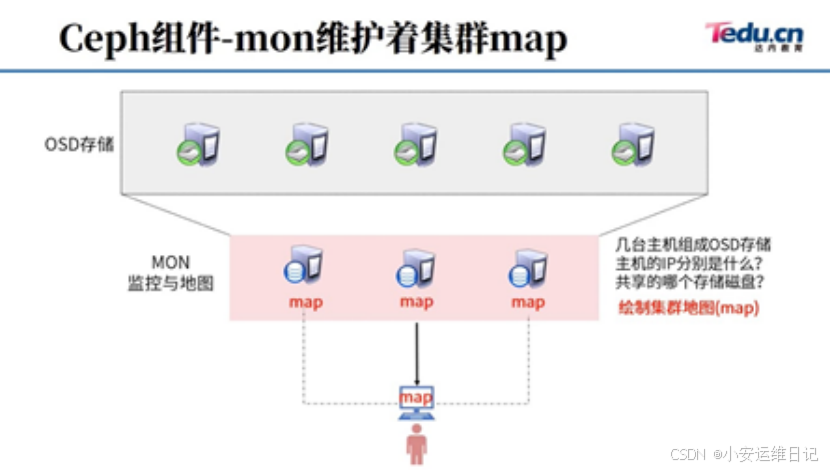
- 安装有MON软件的服务器是MON服务器
- MON服务器手里有整个集群的地图(map)
- 客户端使用集群的第一件事,就是连接MON,下载地图
- 客户端有了地图,客户端就知道整个集群的信息(多少服务器,什么IP,什么端口,多少硬盘,容量多大)
- 客户端下载地图后,就不需要再找MON
- 客户端知道集群信息后,客户端可以根据自己的算法,直接读写数据
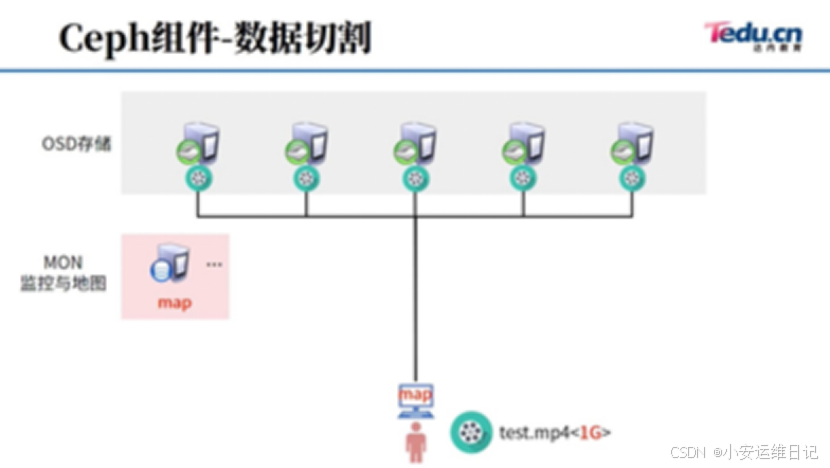
- 客户端如果有一个test.mp4文件,他可以直接连接OSD存储集群
- 为了保障数据的安全,ceph默认3副本,所以最少3台主机,三个OSD(3块硬盘)
- 为了保障地图和集群通信的安全,MON最少3台(MON的设计,使用的是过半原则)
- 当有2台主机做MON,坏1台,剩1/2,没有过半(集群瘫痪)
- 当有3台主机做MON,坏1台,剩2/3,过半了(集群正常)
- 当有3台主机做MON,坏2台,剩1/3,没有过半(集群瘫痪)
- 当有4台主机做MON,坏2台,剩2/4,没有过半(集群瘫痪)
- 当有5台主机做MON,坏2台,剩3/5,过半了(集群正常)
- 所以,使用过半原则设计的集群,服务器个数都是奇数台
1)Ceph会对数据进行切片,然后存储到分布式存储集群中。数据对象如何存储到分布式集群服务呢?假设有一个切片,名称为foo,假设ceph有4台主机集群,每台主机2块硬盘(osd0到osd7:共8个硬盘)
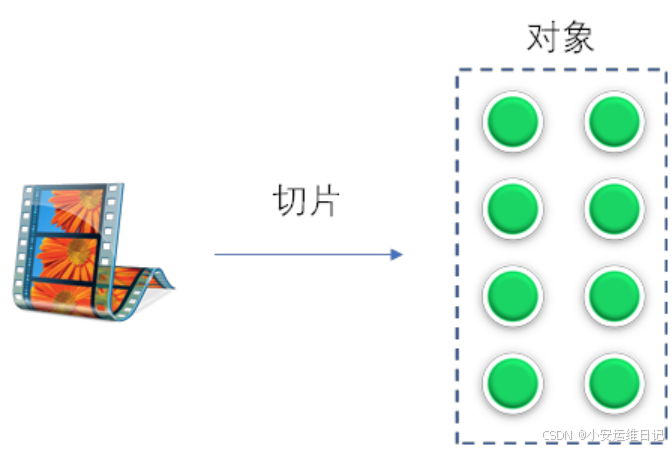
2)使用Hash算法,对foo计算hash值,hash(foo)%8=3(这里为假想计算,也不考虑进制转换的问题),数据直接写入node2节点的第二块共享硬盘(osd3)
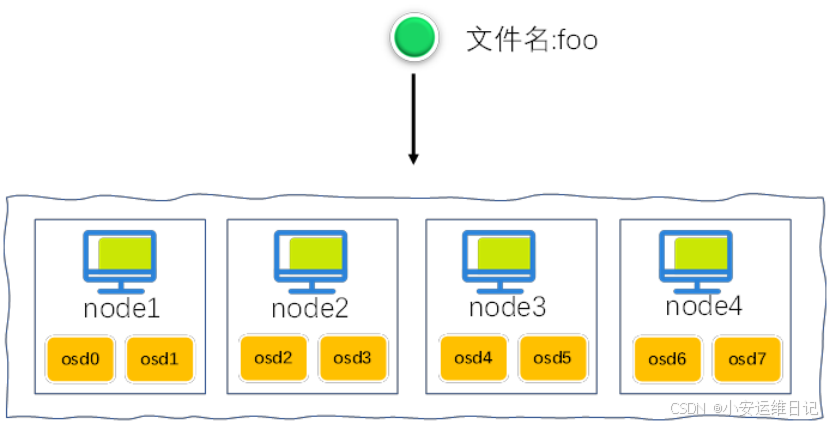
缺点:当增加节点或删除节点,需要对所有数据重新计算HASH值,重新均衡数据(rebalancing),怎么解决呢?接下来提到归置组PG。
3、PG归置组(Placement Group)
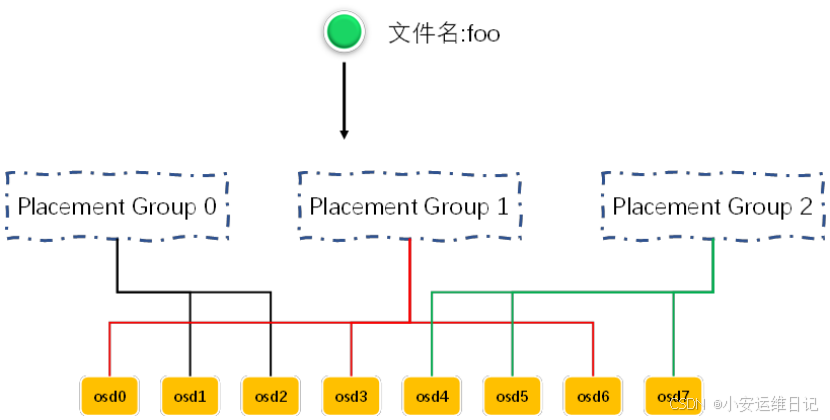
增加PG归置组(可以理解为虚拟节点,逻辑概念)
-
对foo计算hash值,hash(foo)%3=1 #这里为假想计算,也不考虑进制转换的问题
-
数据映射到PG1中(第二个PG),PG1下面对的是OSD0、OSD3、OSD6,其中第一个OSD为主(primary),其他OSD为Second
-
数据写入主OSD,然后自动同步给其他Second OSD,并存在更多PG与OSD的映射关系。
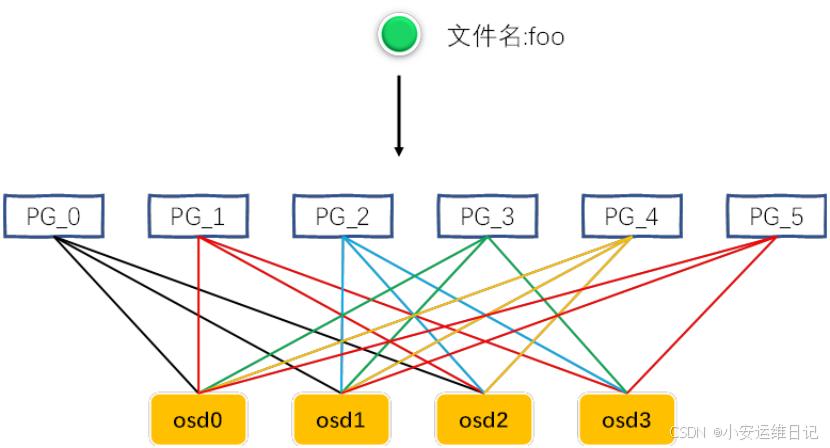
Primary and Secondary OSDs
1)Primary OSD functions:
-
Serve all I/O requests(处理I/O请求)
-
Replicate and protect the data(复制和保护数据)
-
Check data coherence(检查数据一致性)
-
Rebalance the data(重新均衡数据)
-
Recover the data(恢复数据)
2)Secondary OSD functions:
-
Act always unders control of the primary OSD(在主OSD的控制下工作)
-
Can become the primary OSD(有可能成为主OSD)
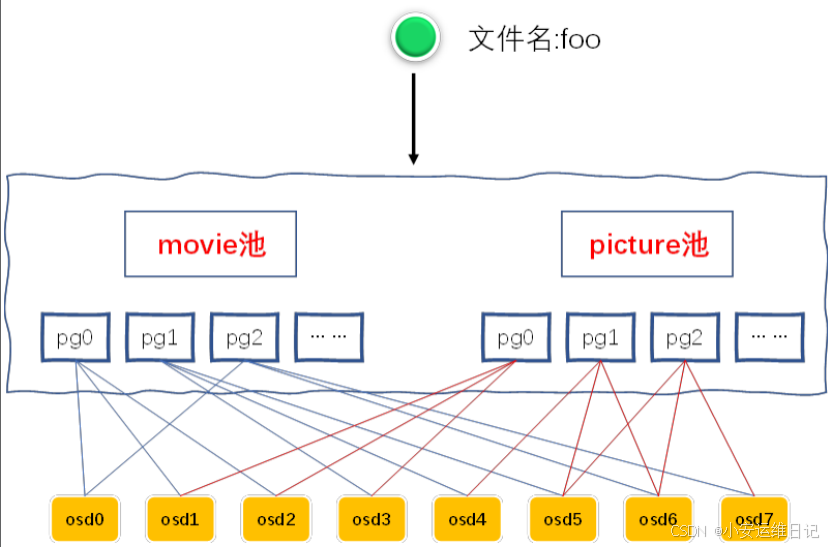
4、存储池
Ceph 存储系统支持“池”的概念,它是存储对象的逻辑分区。
Cluster map:
Ceph客户端和OSDs需要知道集群的整体拓扑,集群包含5个地图,通过地图学习集群拓扑。
- Monitor map
- OSD map
- PG map
- CRUSH map
- MDS map
5、案例介绍
在名称为bar的存储池中,读写一个名称为foo文件的过程。
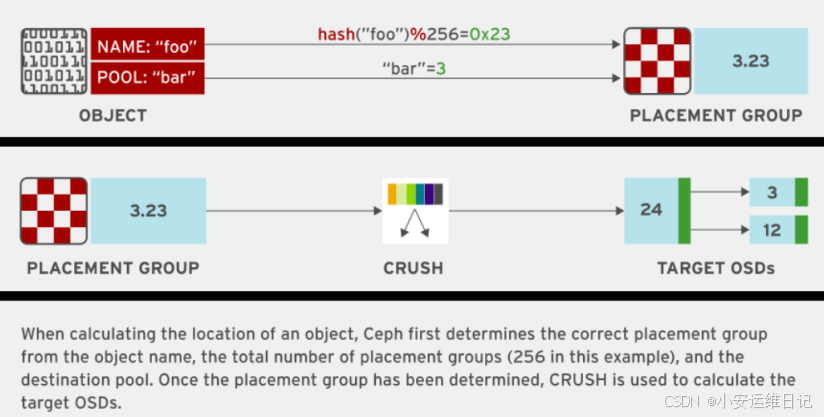
- A Ceph client get the latest copy of the cluster map from monitor;
- This tells it about all the MONs, OSDs, and MDSs in cluster;
- This does not tell it where objects are stored;
- The client must use CRUSH to compute the location of objects it needs to access.
- The client hashes the object ID, and then calculates the hash modulo the number of PGs to get a PG ID.
- The CRUSH algorithm is then used to determine which OSDs are responsible for a placement group(the Acting Set).
- The OSDs in the Acting Set that are curently up are in the Up Set.
- The first OSD in the Up Set is the current primary OSD for the objects's placement group, and all other OSDs in the Up Set are secondary OSDs.
- The Ceph client can then directly work with the primary OSD in order to access the object.
Ceph客户端从监视器(MON)获取集群映射(Map)的最新副本。这告诉它集群中所有的mon、osd和mds;这并没有告诉它对象存储在哪里;客户端必须使用CRUSH来计算需要访问的对象的位置。客户端先对对象ID进行哈希,然后将哈希值与PG个数取模,得到PG ID。然后使用CRUSH算法确定哪个osd负责放置组(代理集)。Acting Set中当前已启动的osd位于up Set中。Up Set中的第一个OSD是对象放置组的当前主OSD, Up Set中的所有其他OSD都是次要OSD。然后Ceph客户端可以直接与主OSD一起工作以访问对象。
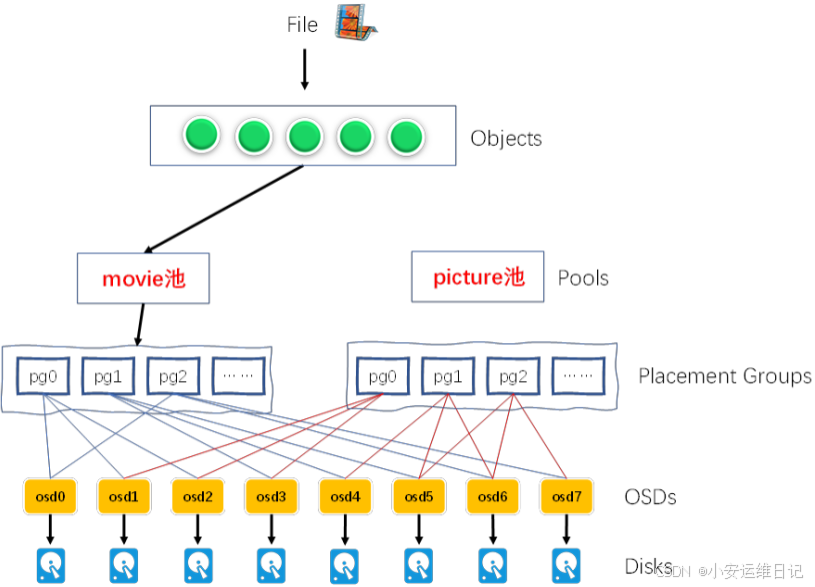
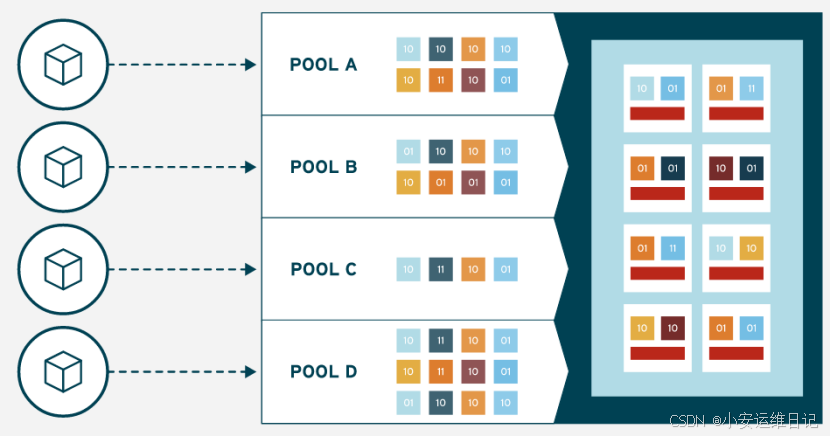
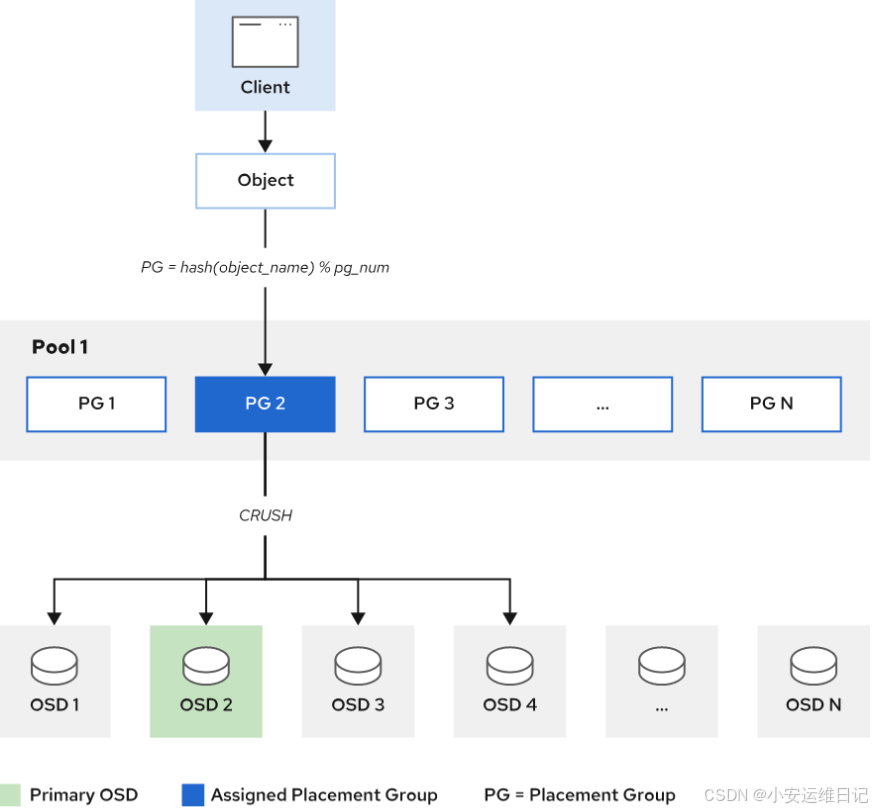
6、PG→OSD映射流程
第一个OSD:
-
hash(pg_id,osd_id,r) =draw #拿pg_id和osd_id以及r求hash值,r为常数
-
draw*osd权重=straw #取最大值,osd权重根据硬盘大小定义,1T权重为1,100G权重为0.1
第二个OSD:
-
r=r+1
-
hash(pg_id,osd_id,r) =draw #r为常数
-
draw*osd权重=straw #取最大值
第三个OSD:
-
r=r+1
-
hash(pg_id,osd_id,r) =draw #r为常数
-
draw*osd权重=straw #取最大值
六、实验环境练习操作
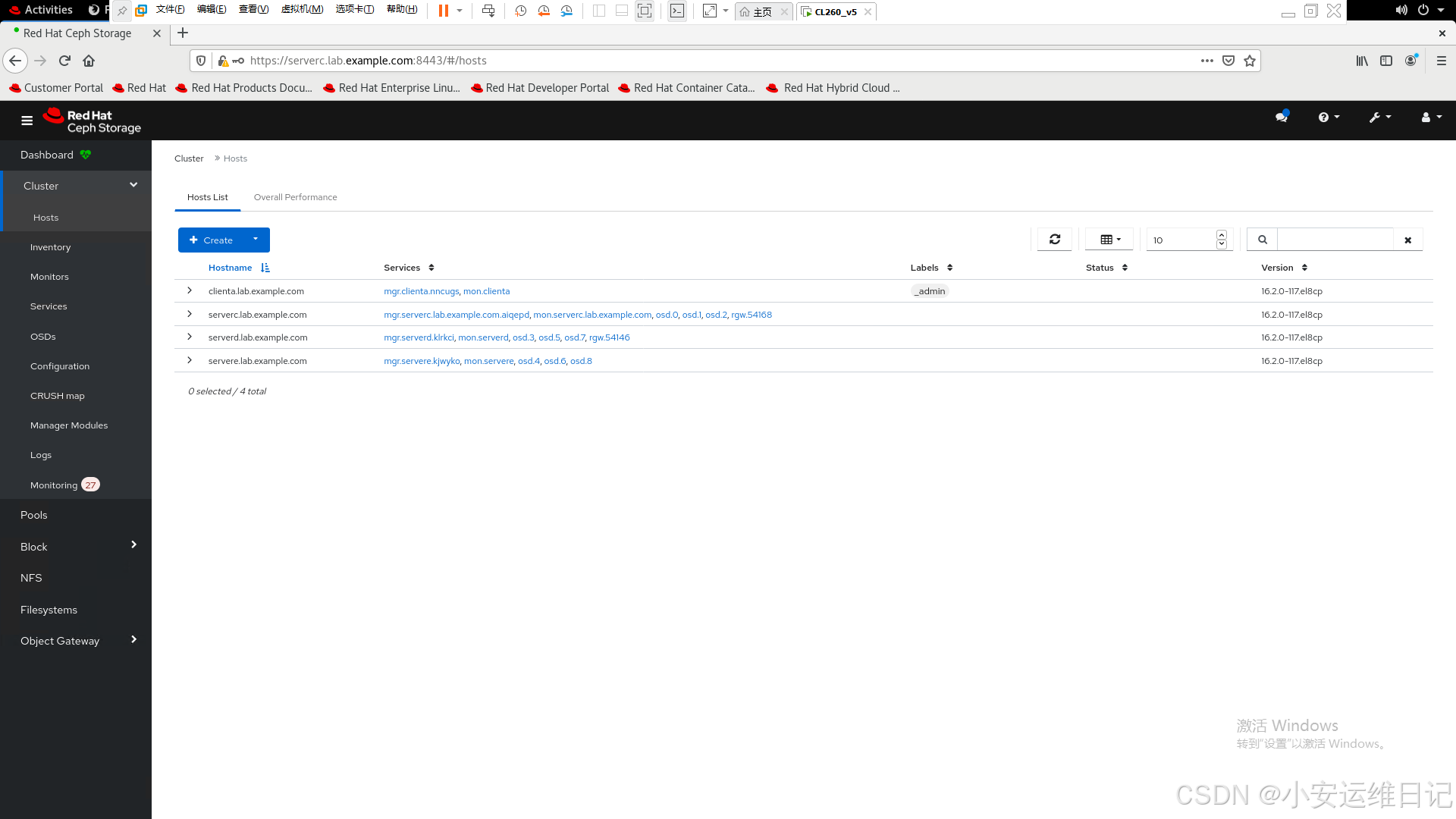
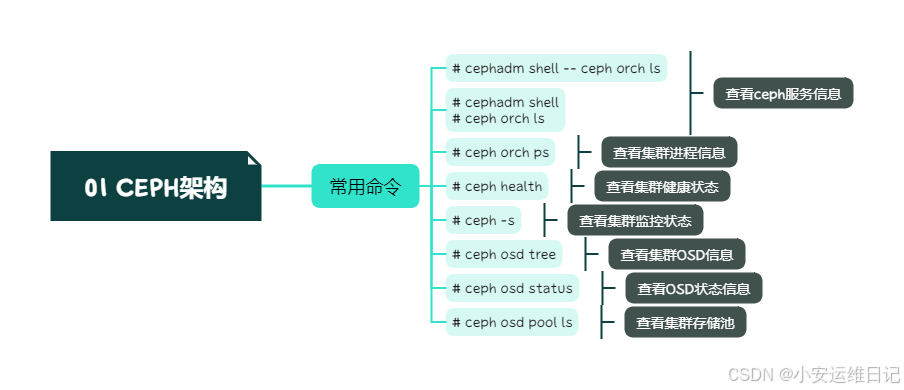
1)通过cephadm shell,执行 ceph orch ls 查看ceph服务信息
[root@foundation0 ~]# ssh root@clienta //远程clienta主机
[root@clienta ~]# cephadm shell -- ceph orch ls
NAME RUNNING REFRESHED AGE PLACEMENT
alertmanager 1/1 5m ago 11M count:1
crash 4/4 5m ago 11M *
grafana 1/1 5m ago 11M count:1
mgr 4/4 5m ago 11M clienta.lab.example.com;serverc.lab.example.com;serverd.lab.example.com;servere.lab.example.com
mon 4/4 5m ago 11M clienta.lab.example.com;serverc.lab.example.com;serverd.lab.example.com;servere.lab.example.com
node-exporter 4/4 5m ago 11M *
osd.default_drive_group 9/12 5m ago 11M server*
prometheus 1/1 5m ago 11M count:1
rgw.realm.zone 2/2 5m ago 10M serverc.lab.example.com;serverd.lab.example.com
cephadmin shell会临时自动启动一个容器,打开一个shell终端
2)查看集群进程信息
[root@clienta ~]# cephadm shell
[ceph: root@clienta /]# ceph orch ps //查看集群进程信息
NAME HOST STATUS REFRESHED AGE PORTS VERSION IMAGE ID CONTAINER ID
alertmanager.serverc serverc.lab.example.com running (119m) 7m ago 11M *:9093 *:9094 0.20.0 4c997545e699 ad48a359a882
crash.clienta clienta.lab.example.com running (5m) 5m ago 5m - 16.2.0-117.el8cp 2142b60d7974 8962d6388fc1
crash.serverc serverc.lab.example.com running (2h) 7m ago 11M - 16.2.0-117.el8cp 2142b60d7974 3d7e1ca31863
crash.serverd serverd.lab.example.com running (2h) 7m ago 11M - 16.2.0-117.el8cp 2142b60d7974 92a57bbcbbd8
crash.servere servere.lab.example.com running (2h) 7m ago 11M - 16.2.0-117.el8cp 2142b60d7974 ce32b6cc8fac
grafana.serverc serverc.lab.example.com running (119m) 7m ago 11M *:3000 6.7.4 09cf77100f6a 2c80c34ed6d9
mgr.clienta.nncugs clienta.lab.example.com running (6m) 5m ago 11M *:8443 *:9283 16.2.0-117.el8cp 2142b60d7974 1b2bac90a619
mgr.serverc.lab.example.com.aiqepd serverc.lab.example.com running (2h) 7m ago 11M *:9283 16.2.0-117.el8cp 2142b60d7974 ec75c4292877
mgr.serverd.klrkci serverd.lab.example.com running (2h) 7m ago 11M *:8443 *:9283 16.2.0-117.el8cp 2142b60d7974 ce59ecdf25e7
mgr.servere.kjwyko servere.lab.example.com running (2h) 7m ago 11M *:8443 *:9283 16.2.0-117.el8cp 2142b60d7974 9609487b05a5
mon.clienta clienta.lab.example.com running (6m) 5m ago 11M - 16.2.0-117.el8cp 2142b60d7974 cce9c0952957
mon.serverc.lab.example.com serverc.lab.example.com running (119m) 7m ago 11M - 16.2.0-117.el8cp 2142b60d7974 b3209a405827
mon.serverd serverd.lab.example.com running (2h) 7m ago 11M - 16.2.0-117.el8cp 2142b60d7974 ac65a44d508c
mon.servere servere.lab.example.com running (2h) 7m ago 11M - 16.2.0-117.el8cp 2142b60d7974 dd6698d5ad63
node-exporter.clienta clienta.lab.example.com running (6m) 5m ago 10M *:9100 0.18.1 68b1be7484d4 84f77ac97da2
node-exporter.serverc serverc.lab.example.com running (119m) 7m ago 11M *:9100 0.18.1 68b1be7484d4 f680a4f2e8c2
node-exporter.serverd serverd.lab.example.com running (2h) 7m ago 10M *:9100 0.18.1 68b1be7484d4 7b13a0dba0bd
node-exporter.servere servere.lab.example.com running (2h) 7m ago 10M *:9100 0.18.1 68b1be7484d4 fceb9e755d6b
osd.0 serverc.lab.example.com running (118m) 7m ago 11M - 16.2.0-117.el8cp 2142b60d7974 1ccfc95b51da
osd.1 serverc.lab.example.com running (118m) 7m ago 11M - 16.2.0-117.el8cp 2142b60d7974 aeec6c41017e
osd.2 serverc.lab.example.com running (118m) 7m ago 11M - 16.2.0-117.el8cp 2142b60d7974 33c62632810b
osd.3 serverd.lab.example.com running (119m) 7m ago 10M - 16.2.0-117.el8cp 2142b60d7974 cafa30469ec2
osd.4 servere.lab.example.com running (119m) 7m ago 10M - 16.2.0-117.el8cp 2142b60d7974 cabd6124b31f
osd.5 serverd.lab.example.com running (119m) 7m ago 10M - 16.2.0-117.el8cp 2142b60d7974 458ef39e1146
osd.6 servere.lab.example.com running (119m) 7m ago 10M - 16.2.0-117.el8cp 2142b60d7974 76d901cd2838
osd.7 serverd.lab.example.com running (119m) 7m ago 10M - 16.2.0-117.el8cp 2142b60d7974 fb2864d13f58
osd.8 servere.lab.example.com running (119m) 7m ago 10M - 16.2.0-117.el8cp 2142b60d7974 6b2d39039851
prometheus.serverc serverc.lab.example.com running (119m) 7m ago 11M *:9095 2.22.2 deca4dcb80bb b016a7bc9506
rgw.realm.zone.serverc.bqwjcv serverc.lab.example.com running (119m) 7m ago 10M *:80 16.2.0-117.el8cp 2142b60d7974 237e0b9eb25e
rgw.realm.zone.serverd.kfmflx serverd.lab.example.com running (2h) 7m ago 10M *:80 16.2.0-117.el8cp 2142b60d7974 9a67ff65591c
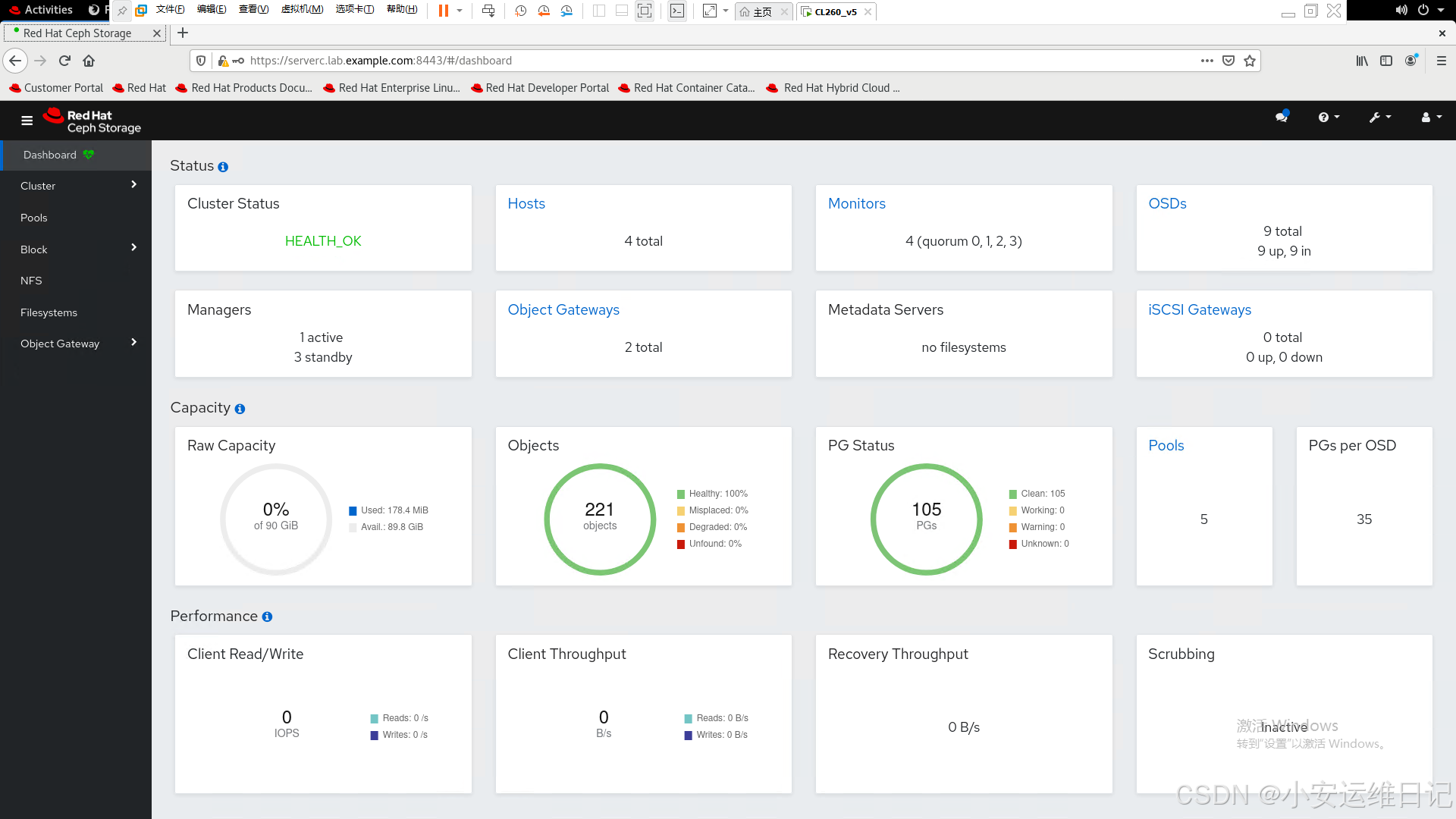
3)查看集群健康状态
[ceph: root@clienta /]# ceph health //查看集群健康状态
HEALTH_OK4)查看集群监控状态
[ceph: root@clienta /]# ceph -s //查看集群监控状态
cluster:
id: 2ae6d05a-229a-11ec-925e-52540000fa0c
health: HEALTH_OK
services:
mon: 4 daemons, quorum serverc.lab.example.com,clienta,serverd,servere (age 8m)
mgr: servere.kjwyko(active, since 9m), standbys: serverd.klrkci, serverc.lab.example.com.aiqepd, clienta.nncugs
osd: 9 osds: 9 up (since 119m), 9 in (since 10M)
rgw: 2 daemons active (2 hosts, 1 zones)
data:
pools: 5 pools, 105 pgs
objects: 221 objects, 4.9 KiB
usage: 194 MiB used, 90 GiB / 90 GiB avail
pgs: 105 active+clean5)查看集群OSD的信息
[ceph: root@clienta /]# ceph osd tree //查看集群OSD的信息
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.08817 root default
-3 0.02939 host serverc
0 hdd 0.00980 osd.0 up 1.00000 1.00000
1 hdd 0.00980 osd.1 up 1.00000 1.00000
2 hdd 0.00980 osd.2 up 1.00000 1.00000
-5 0.02939 host serverd
3 hdd 0.00980 osd.3 up 1.00000 1.00000
5 hdd 0.00980 osd.5 up 1.00000 1.00000
7 hdd 0.00980 osd.7 up 1.00000 1.00000
-7 0.02939 host servere
4 hdd 0.00980 osd.4 up 1.00000 1.00000
6 hdd 0.00980 osd.6 up 1.00000 1.00000
8 hdd 0.00980 osd.8 up 1.00000 1.000006)查看OSD状态信息
[ceph: root@clienta /]# ceph osd status //查看OSD状态信息
ID HOST USED AVAIL WR OPS WR DATA RD OPS RD DATA STATE
0 serverc.lab.example.com 28.9M 9.96G 0 0 0 0 exists,up
1 serverc.lab.example.com 23.1M 9.97G 0 0 0 0 exists,up
2 serverc.lab.example.com 17.9M 9.97G 0 0 0 0 exists,up
3 serverd.lab.example.com 21.6M 9.97G 0 0 0 0 exists,up
4 servere.lab.example.com 20.4M 9.97G 0 0 0 0 exists,up
5 serverd.lab.example.com 24.4M 9.97G 0 0 0 0 exists,up
6 servere.lab.example.com 29.1M 9.96G 0 0 1 0 exists,up
7 serverd.lab.example.com 23.6M 9.97G 0 0 0 0 exists,up
8 servere.lab.example.com 20.3M 9.97G 0 0 0 0 exists,up
7)查看集群存储池
[ceph: root@clienta /]# ceph osd pool ls //查看集群存储池
device_health_metrics
.rgw.root
default.rgw.log
default.rgw.control
default.rgw.meta
[ceph: root@clienta /]# exit //退出cephadmin的shell终端七、Ceph Interfaces(ceph接口)
之前的Ceph版本s 通过ceph-ansible软件提供的Ansible Playbooks部署和管理集群。Red Hat Ceph Storage 5(RHCS5)使用 Cephadm 作为集群管理工具(部署、管理、监控),替代之前的ceph-ansible工具。
Cephadm 作为Manager daemon(MGR)中的一个模块实现,是部署集群要启动的第一个进程。ceph集群核心集成了所有管理任务,当集群启动时,cephadm就可以使用了。
Cephadm是由cephadm软件包提供!我们需要在集群的第一个存储节点作为bootstrap节点。
[root@clienta ~]# rpm -qf /usr/sbin/cephadm //查看哪个软件包,提供了cephadmin命令
cephadm-16.2.0-117.el8cp.noarchRHCS5是基于容器的存储集群版本,这样可以降低复杂度和减少依赖关系。
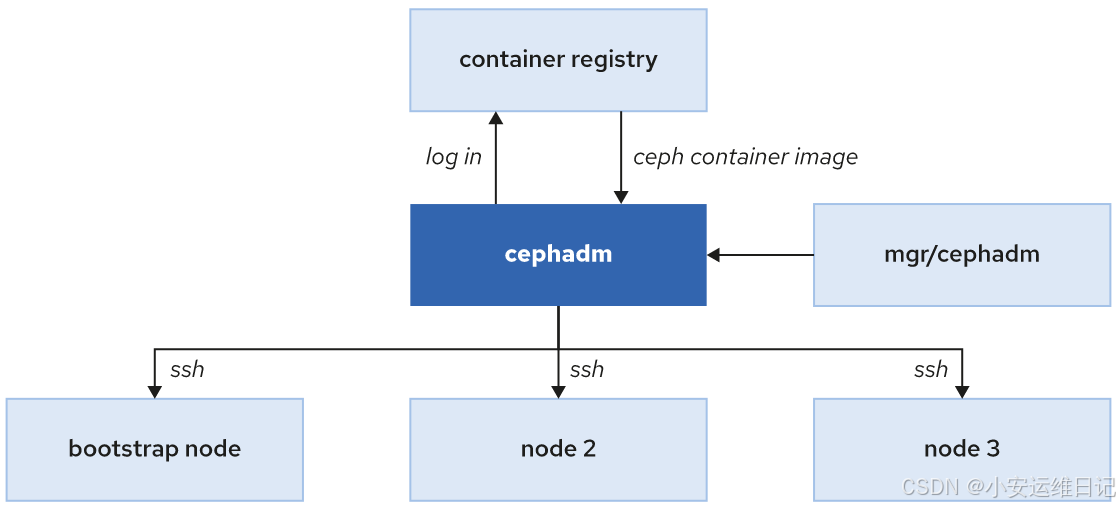
- Cephadm可以登录到容器仓库下载ceph镜像,并使用这些镜像在存储节点上启动相关服务。
- Cephadm通过SSH远程ceph存储节点,通过SSH连接,Cephadm可以添加主机到集群,添加存储设备或者监控这些集群主机。
- 通过容器部署ceph集群,不需要额外的其他软件,我们可以通过bootstrap主机从命令行接口启动存储集群,启动一个最小化的ceph集群,需要至少一台主机,2个进程(monitor和manager进程),我们可以维护和扩容集群,比如添加更多主机或者更多存储设备。
- RHCS5提供了命令行和图形两种管理界面。
- Cephadm可以启动一个容器版本的shell命令终端(容器中已经安装好了ceph相关软件)。运行cephadm shell就可以启动这样一个容器命令终端。
- 另外RHCS5还提供了图形管理界面(Dashboard),Dashboard GUI是ceph-mgr进程的一个模块,该web使用TCP协议监听8443端口。
八、图形界面实验操作
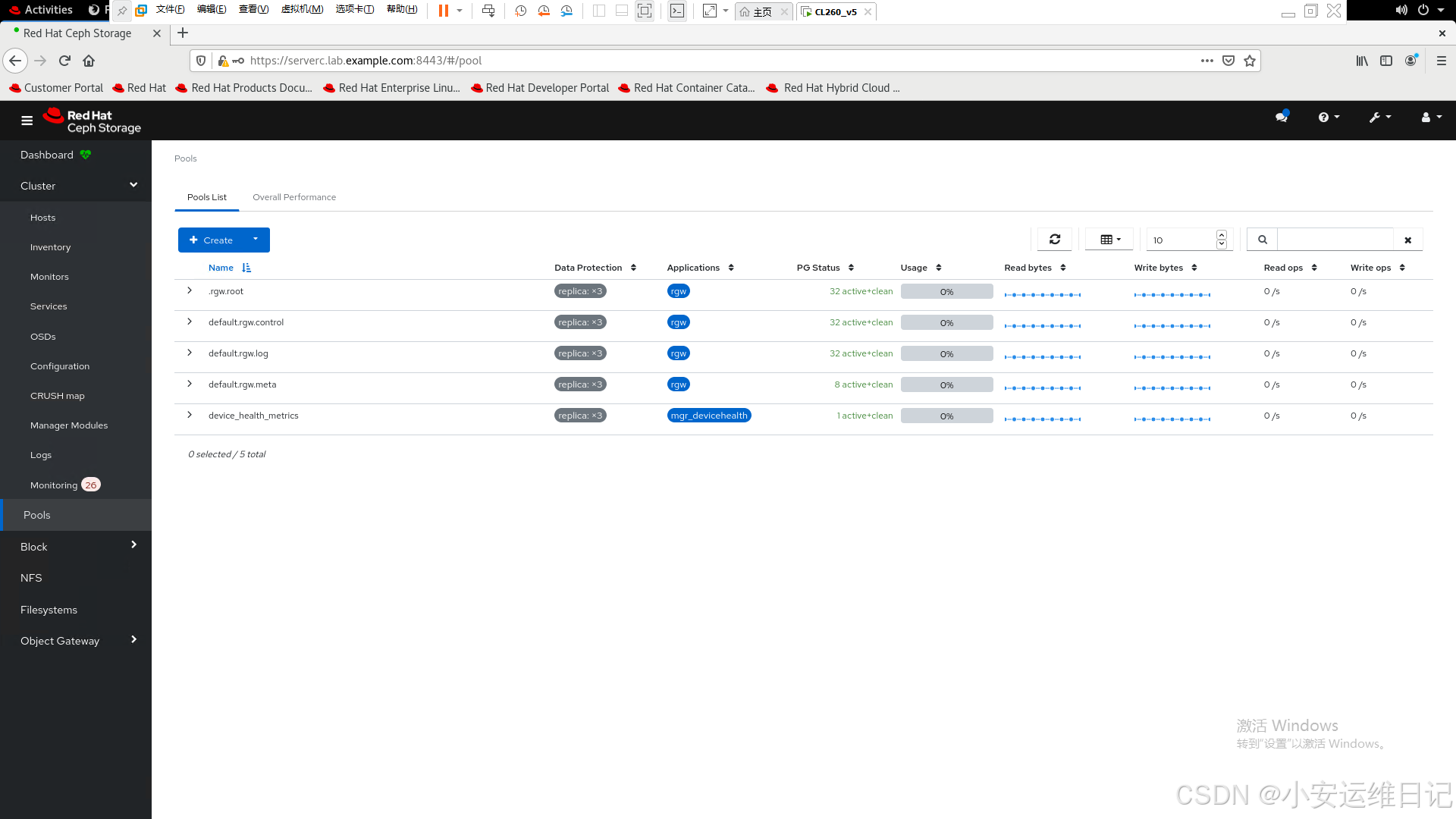
浏览器访问:https://serverc.lab.example.com:8443
用户名为admin,密码为redhat
1)登录界面
2)面板信息
3)主机信息
4)设备清单
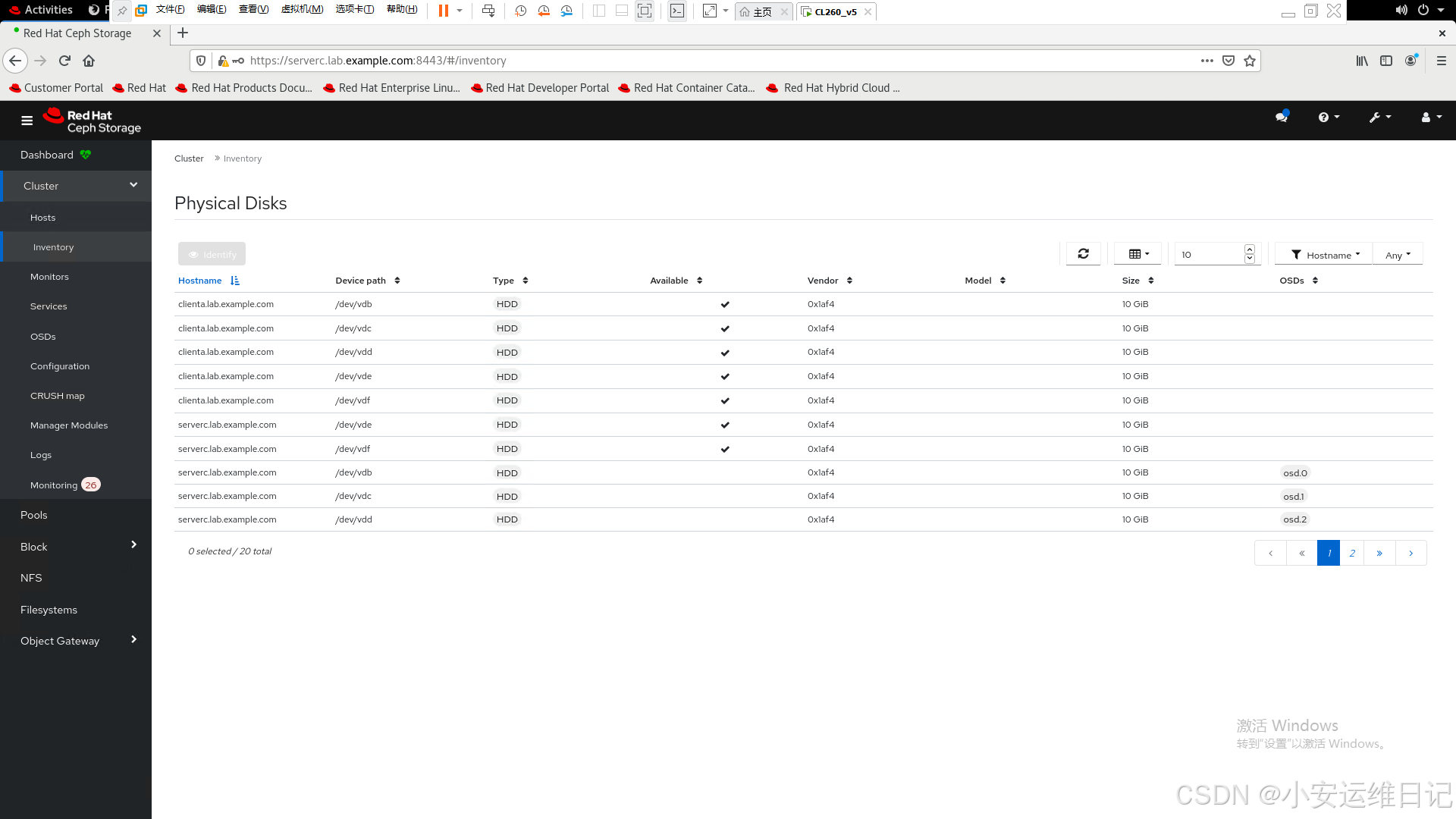
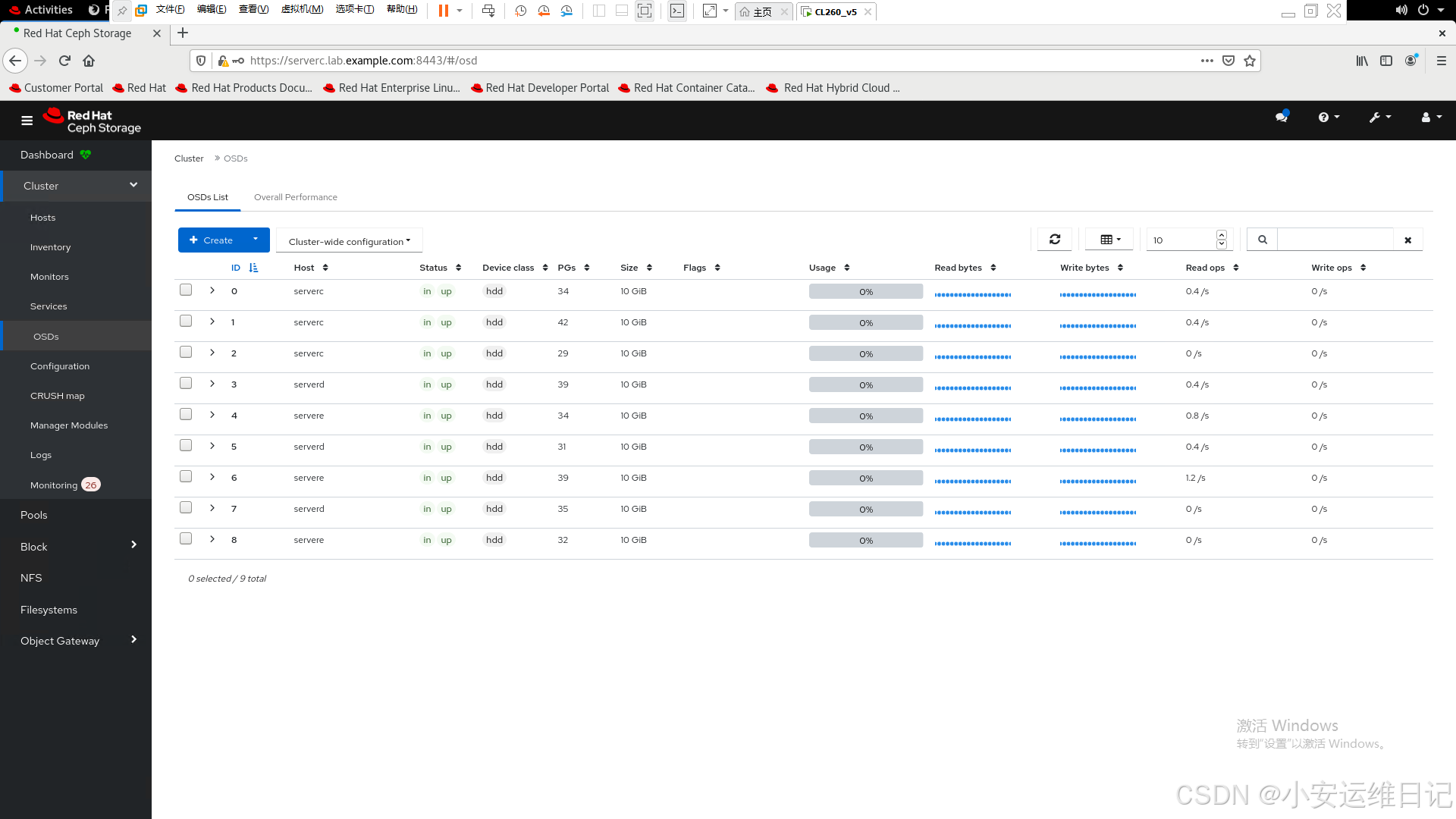
5)OSD列表
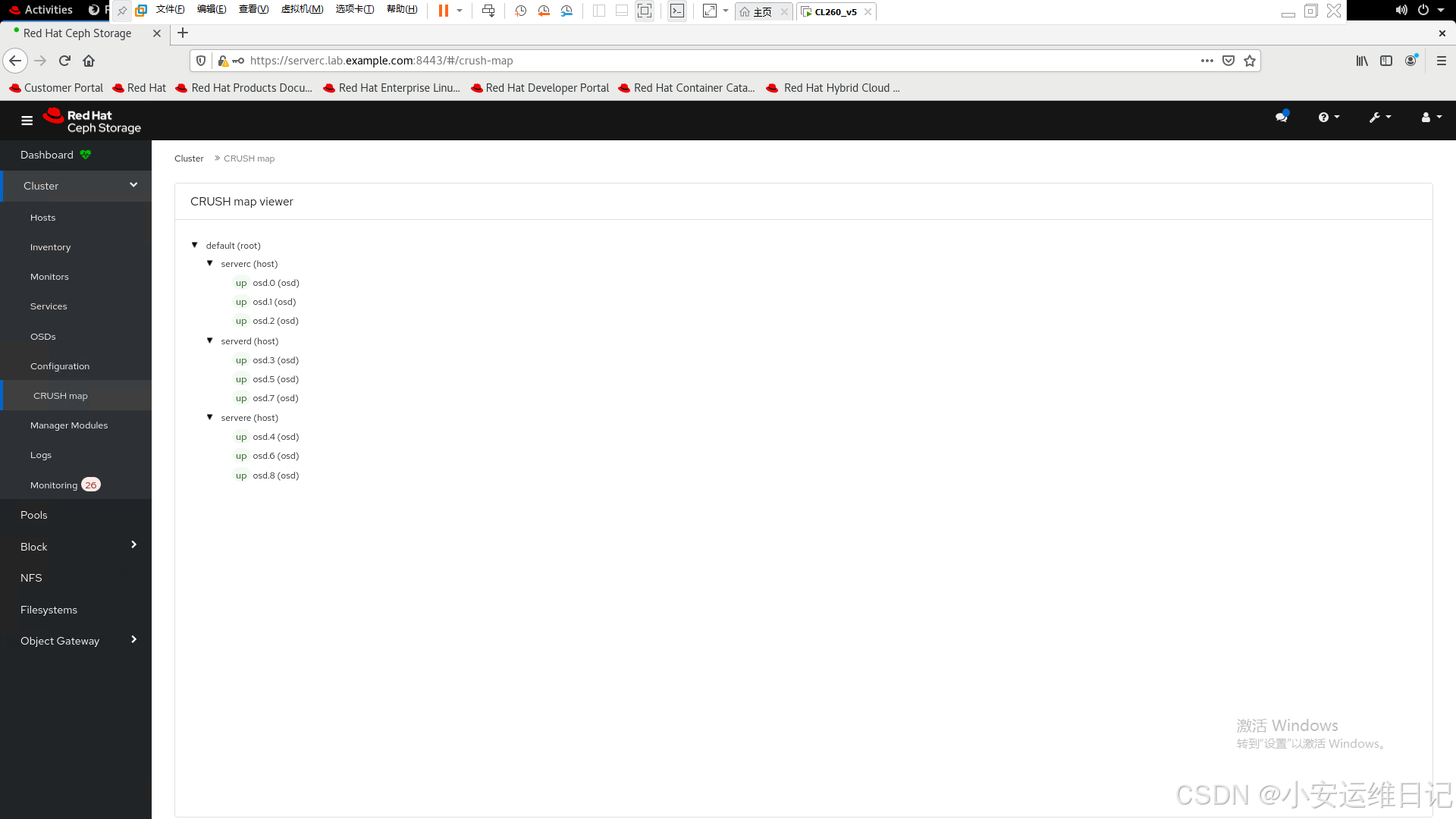
6)映射地图 Crush map
7)日志信息
8)存储池信息
思维导图:
小结:
本篇为 【RHCA认证 - CL260 | Day01:Ceph 架构及环境介绍】的开篇学习笔记,希望这篇笔记可以让您初步了解到 Ceph的架构、Crush算法,不妨跟着我的笔记步伐亲自实践一下吧!
Tip:毕竟两个人的智慧大于一个人的智慧,如果你不理解本章节的内容或需要相关环境、视频,可评论666并私信小安,请放下你的羞涩,花点时间直到你真正的理解。


















 1311
1311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











