




一、使用过滤器处理变量
1. Ansible过滤器
1)过滤器的使用格式
在Ansible的Playbook和模板中,变量通过Jinja2表达式进行引用和处理。具体表现为:当使用双大括号{{ }}包裹变量名时,系统会将该变量替换为其对应的值。
{{ variable_name }} 这样的Jinja2表达式最终会被解析为变量variable_name存储的实际值
在Ansible中,Jinja2表达式不仅支持变量引用,还提供了强大的过滤器(filters)功能,用于对变量值进行转换和处理,从而为Playbook和模板生成更符合需求的数据格式。
过滤器来源:
- 基础过滤器:由Jinja2模板语言原生提供
- 扩展过滤器:红帽Ansible自动化平台(AAP)通过插件形式提供
- 自定义过滤器:用户可自行开发(注:此功能不在本课程讨论范围内)
要在Jinja2表达式中使用过滤器,请在变量名或值后添加管道(|)字符,然后编写过滤器或过滤器表达式。可以连续指定多个过滤器,每个过滤器或过滤器表达式都以管道符分隔。
{{ variable_name | filter1 | filter2(arg1,arg2) }}
过滤器本质上类似编程语言中的函数,目的是为前面的变量做进一步的操作(如修改默认值、过滤、计算、转换格式等),类似函数:max(1,4,7) 等价于 {{ [1,4,7] | max }}
2)提供默认的变量值
default 过滤器主要用于以下两种场景:
-
忽略未定义的变量:防止因变量未定义而导致 Playbook 报错(如 undefined variable)。
-
为未定义变量提供默认值:当变量不存在时,自动使用指定的默认值,确保任务正常执行。
典型错误示例:如果直接引用未定义的变量(如 shell),Ansible 会报错
FAILED! => {"msg": "The task includes an option with an undefined variable. The error was: 'dict object' has no attribute 'shell'"}
如果使用default过滤器,就可以避免这样的错误。
{{ variable_name | default(默认值) }}
以下这个常见任务中,使用了 ansible.builtin.user 模块来管理 user_list 变量中定义的用户。列表中的每个用户都必须定义name这个属性,另外还可以选择性地定义groups、system、shell、state和remove这些属性。对于这些可选的属性就可以使用default过滤器,请参阅模块文档,以确定模块所需的键名及默认值。
---
- name: Manage users
ansible.builtin.user:
name: "{{ item['name'] }}" # 必须定义的属性
groups: "{{ item['groups'] | default(omit) }}" # 未定义时忽略
system: "{{ item['system'] | default(false) }}" # 默认值 false
shell: "{{ item['shell'] | default('/bin/bash') }}" # 默认 /bin/bash
state: "{{ item['state'] | default('present') }}" # 默认 present(创建用户)
remove: "{{ item['remove'] | default(false) }}" # 默认 false(不彻底删除)
loop: "{{ user_list }}" # 遍历用户列表针对item项中的成员变量,其中,
-
未定义groups属性,使用 omit 忽略该参数(不报错,且不传递 groups 给模块)。
-
未定义system属性,使用 false 作为默认值(当需要创建一个系统用户账号时,应该传递true值)
-
未定义shell属性,使用 /bin/bash 作为默认值(当需要创建一个系统用户账号时,可以传递/bin/nologin值)
-
未定义state属性,使用 present 作为默认值,表示添加用户(当需要删除用户时,应该传递absent值)
-
未定义remove属性,使用 false 作为默认值(当需要彻底删除一个用户时,应该传递true值,相当于执行userdel -r命令)
(1) omit 特殊值
用途:显式告知 Ansible 忽略该参数(不传递到模块)。
场景:适用于模块的可选参数(如 groups),避免因未定义变量导致模块报错。
(2) 默认值设计原则
安全优先:如 remove: false 防止误删用户数据。
符合模块约定:参考模块文档(如 ansible.builtin.user)的默认行为。
(3) 变量优先级
若变量已定义,则使用实际值(覆盖默认值)。
若变量未定义,则使用 default 指定的值。
使用模块时,Ansible必须决定在任务中用到模块的哪些键。可以一开始手动指定某个键的初始值,也可以通过后续任务传递的变量来为某个键设置新的值。由于未定义的变量会导致剧本运行出错,因此可以用default过滤器来忽略未定义的参数或为未定义的参数提供值。
个别场景,当变量值为 空字符串 或 布尔值 false 时,可通过 default(..., true) 强制启用默认值替换。
{{ variable_name | default(默认值, boolean) }}
- name: Default filter examples
hosts: localhost
tasks:
- name: Default filter examples
vars:
pattern: "some text" # 注:不包含 'test' 子串
ansible.builtin.debug:
msg: "{{ item }}"
loop:
# 场景1:regex_search 未匹配时返回空字符串,default 不生效
- "{{ pattern | regex_search('test') | default('MESSAGE') }}"
# 场景2:regex_search 返回空字符串,但 default(..., true) 强制生效
- "{{ pattern | regex_search('test') | default('MESSAGE', true) }}"
# 场景3:非空字符串转布尔值为 true,default 不生效
- "{{ pattern | bool | default('MESSAGE') }}"
# 场景4:即使 bool 转换结果为 false,default(..., true) 仍强制生效
- "{{ pattern | bool | default('MESSAGE', true) }}"针对loop循环列表项,其中,
-
第1个列表项,当在变量pattern中找不到匹配结果时,regex_search过滤器会返回一个空字符串,后面的default过滤器不会被使用
-
第2个列表项,尽管regex_search过滤器也可能返回一个空字符串,但会使用default过滤器,因为它包含true
-
第3个列表项,由于字符串的计算结果为布尔值false,因此后面的default过滤器也不会被使用
-
第4个列表项,尽管字符串的计算结果也返回false,但会使用default过滤器,因为它包含true
在某些适当的情况下,还可以先使用default过滤器,然后再传递给其他过滤器。
关键规则总结:
默认行为
default('X') 仅在变量 未定义(undefined) 时替换为 'X',以下情况 不触发:
- 空字符串 ("")
- 布尔值 false
- 其他 falsy 值(如空列表 [])
严格模式
default('X', true) 会在以下情况强制替换:
- 变量未定义
- 变量值为空字符串
- 变量值为布尔值 false
2. 变量类型
1)变量基础类型
要了解过滤器,就必须首先了解Ansible如何处理变量值。
Ansible将运行时的数据保存在变量中,数据的确切类型由YAML结构或值的内容决定。下表列出了一些值类型(如表所示)
| 类型 | 描述 | 示例 |
| Strings | 字符串 | "Hello", '123' |
| Numbers | 数值 | 42, 3.14 |
| Booleans | true或false | enable: true |
| Dates | ISO-8601日历日期 | 2023-10-05T14:30:00Z |
| Null | 变量变成未定义的状态 | null, ~ |
| lists or Arrays | 有序的列表或数组 | ["a", "b"] |
| Dictionaries | 字典(键值对) | {name: "Alice", age: 30} |
2)类型转换过滤器
有时,你可能需要先使用 int 过滤器把一个值转换为整数,或者使用 float 过滤器把值转为浮点数。当需要强制转换变量类型时,需使用以下过滤器:
-
数值转换
int:转换为整数
{{ "42" | int }} → 42
float:转换为浮点数
{{ "3.14" | float }} → 3.14
例如,以下Jinja2表达式用来将字符串格式的小时数转为整数后做加法(当前时刻的小时值加1)
{{ (ansible_facts['date_time']['hour'] | int) + 1 }}
其中cansible_facts['date_time']['hour'] 的小时值是一个字符串类型的系统指标,而不是整数,如果不先转换为数值,就无法实现加1运算。
-
数学运算过滤器
对数值做数学运算时,可以用到 log、pow、root、abs和round 等各种过滤器。
| 过滤器 | 功能 | 示例 | 结果 |
| abs | 绝对值 | {{ -5 | abs }} | 5 |
| round | 四舍五入 | {{ 3.14159 | round(2) }} | 3.14 |
| pow | 幂运算 | {{ 3 | pow(2) }} | 9 |
| root | 平方根 | {{ 1764 | root }} | 42 |
| log | 对数(默认自然对数) | {{ 100 | log(10) }} | 2.0 |
3. 列表操作
要分析和操作列表数据,可以使用多种过滤器。
1)数值列表计算
对于数值类型的列表,可以使用 max、min、sum 过滤器分别计算最大值、最小值、和。
| 功能 | 过滤器 | 示例 | 结果 |
| 数值计算 | max | {{ [2, 4, 6, 8, 10, 12] | max }} | 12 |
| min | {{ [2, 4, 6, 8, 10, 12] | min }} | 2 | |
| sum | {{ [2, 4, 6, 8, 10, 12] | sum }} | 42 |
2)提取列表元素
可以从列表中提取某个元素,例如 first 过滤器取第一个元素或 last 过滤器取最后一个元素,或者 length 过滤器取列表的长度,random 取随机一个元素。
| 功能 | 过滤器 | 示例 | 结果 |
| 元素提取 | first | {{ [2, 4, 6, 8, 10, 12] | first }} | 2 |
| last | {{ [2, 4, 6, 8, 10, 12] | last }} | 12 | |
| length | {{ [2, 4, 6, 8, 10, 12] | length }} | 6 | |
| random | {{ ['Douglas', 'Marvin', 'Arthur'] | random }} | 随机一个名字 |
3)调整列表元素的顺序
可以使用以下方法对列表的元素进行排序。
-
sort 排序:返回一个列表,该列表按元素的自然/正常顺序排序
-
reverse 反序:返回一个列表,其中的顺序与原始的顺序相反
-
shuffle 洗牌:返回一个列表,其中的顺序是随机的
| 功能 | 过滤器 | 描述 | 示例 | 结果 |
| 调整列表顺序 | sort | 按元素自然顺序排序 | {{ [4,8,10,6,2] | sort }} | [2,4,6,8,10] |
| reverse | 反转列表顺序 | {{ [2,4,6,8,10] | reverse }} | [10,8,6,4,2] | |
| shuffle | 随机打乱顺序 | {{ [2,4,6,8,10] | shuffle }} | 随机顺序(如[6,2,10,4,8]) |
- name: reversing and sorting lists
ansible.builtin.assert:
that:
- "{{ [ 2, 4, 6, 8, 10 ] | reverse }} is eq( [ 10, 8, 6, 4, 2] )"
- "{{ [ 4, 8, 10, 6, 2 ] | sort }} is eq( [ 2, 4, 6, 8, 10 ] )"4)合并列表元素
有时,将多个列表合并为一个列表可以简化迭代。flatten 扁平化过滤器能够递归获取输入的列表值中的任何内部列表,并将内部值添加到外部的列表中。
| 功能 | 过滤器 | 描述 | 示例 | 结果 |
| 扁平化合并 | flatten | 递归合并嵌套列表 | {{ [2,[4,[6,8]],10] | flatten }} | [2,4,6,8,10] |
- name: Flatten turns nested lists on the left to list on the right
ansible.builtin.assert:
that:
- "{{ [ 2, [4, [6, 8]], 10 ] | flatten }} is eq( [ 2, 4, 6, 8, 10] )"5)将列表作为集合处理
使用 unique 唯一过滤器可确保列表中没有重复的元素。如果你正在处理已收集的一份系统指标列表,例如可能有重复条目的用户名或主机名,unique过滤器非常有用。
| 功能 | 过滤器 | 描述 | 示例 | 结果 |
| 去重 | unique | 移除重复元素 | {{ [1,1,2,2,3,4,4] | unique }} | [1,2,3,4] |
- name: The 'unique' filter Neaves unique elements ansible.builtin.assert:
that:
- "{{ [ 1, 1, 2, 2, 2, 3, 4, 4 ] | unique }} is eq( [ 1, 2, 3, 4 ] )"针对两个不雷同的列表,可以使用集合理论来运算。
-
union 并集过滤器:返回一个集合,其中包含来自两个输入集合的元素
-
intersect 交集过滤器:返回一个集合,其中包含两个集合共有的元素
-
difference 差别过滤器:返回一个集合,其中包含在第一集合中有但第二集合中没有的元素
| 功能 | 过滤器 | 描述 | 示例 | 结果 |
| 并集 | union | 合并两个列表的所有元素 | {{ [1,2] | union([2,3]) }} | [1,2,3] |
| 交集 | intersect | 获取两个列表共有元素 | {{ [1,2,3] | intersect([2,3,4]) }} | [2,3] |
| 差集 | difference | 获取第一个列表独有的元素 | {{ [2,4,6,8,10] | difference([2,4,6,16]) }} | [8,10] |
- name: The 'difference' filter provides elements not in specified set
ansible.builtin.assert:
that:
- "{{ [2, 4, 6, 8, 10] | difference([2, 4, 6, 16]) }} is eq( [8, 10] )"4. 字典操作
与列表不同,字典不按任何方式排序,而只是键值对的集合。你可以使用过滤器来构造字典,也可以将这些字典转换成列表,反过来也一样。
1)字典合并
使用 combine 过滤器可连接两个字典。如果两个字典中有相同的键,则后一个字典中的键具有高优先级
| 功能 | 过滤器 | 描述 | 示例 | 结果 |
| 字典合并 | combine | 合并两个字典,相同键时后者优先级更高 | {{ {'A':1,'B':2} | combine({'B':4,'C':5}) }} | {'A':1,'B':4,'C':5} |
例如以下任务:
- name: The 'combine' filter combines two dictionaries into one
vars:
expected:
A: 1
B: 4
C: 5
ansible.builtin.assert:
that:
- "{{ {'A':1,'B':2} | combine({'B':4,'C':5}) }} is eq( expected )"2)转换字典
使用 dict2items 过滤器可将字典转换成列表;使用 items2dict 过滤器将列表转换成字典。
| 功能 | 过滤器 | 描述 | 示例 | 结果 |
| 字典转换 | dict2items | 将字典转换为键值对列表 | {{ {'Douglas':'Human','Marvin':'Robot'} | dict2items }} | [ {"key":"Douglas","value":"Human"}, {"key":"Marvin","value":"Robot"} ] |
| items2dict | 将键值对列表转回字典 | {{ [ {"key":"Arthur","value":"Human"}, {"key":"Marvin","value":"Robot"} ] | items2dict }} | {'Arthur':'Human','Marvin':'Robot'} |
---
- name: converting between dictionaries and lists
vars:
characters_dict:
Douglas: Human
Marvin: Robot
Arthur: Human
characters_items:
- key: Douglas
value: Human
- key: Marvin
value: Robot
- key: Arthur
value: Human
ansible.builtin.assert:
that:
- "{{ characters_dict | dict2items }} is eq( characters_items )"
- "{{ characters_items | items2dict }} is eq( characters_dict )"5. 字符串操作
对于文本类型的值,也可以使用各种过滤器来处理。可以计算校验和、创建密码哈希,以及将文本转换为Base64编码和从Base64编码转换文本,这是很多应用程序可能用到的。
1)哈希和加密字符串
| 功能 | 过滤器 | 描述 | 示例 | 结果 |
| 哈希与加密 | hash | 生成字符串的哈希值(支持多种算法) | {{ 'Arthur' | hash('sha1') }} | 8bae3f7d0a461488ced07b3e10ab80d018eb1d8c |
| password_hash | 生成加密的密码字符串(用于用户管理) | {{ 'secret_password' | password_hash('sha512') }} | $6$rounds=656000$hnQwHfDkFZ4Pq$X5... |
hash 哈希过滤器使用哈希算法返回输入的字符串的哈希值。
- name: the string's SHA-1 hash
vars:
expected: '8bae3f7d0a461488ced07b3e10ab80d018eb1d8c'
ansible.builtin.assert:
that:
- "'{{ 'Arthur' | hash('sha1') }}' is eq( expected )"password_hash 密码哈希过滤器用来生成加密的密码字符串(用在user模块管理用户)。
{{ 'secret_password' | password_hash('sha512') }}
2)编码字符串
| 功能 | 过滤器 | 描述 | 示例 | 结果 |
| 字符串编码与安全处理 | b64encode | 将二进制数据转换为Base64编码 | {{ 'âÉïôú' | b64encode }} | w6LDicOvw7TDug== |
| b64decode | 将Base64编码数据转换回原始格式 | {{ 'w6LDicOvw7TDug==' | b64decode }} | âÉïôú | |
| quote | 为字符串添加引号(防止Shell注入) | {{ 'Hello $USER' | quote }} | 'Hello $USER' |
使用 b64encode 过滤器将二进制数据转换为Base64,或使用b64decode过滤器将Base64编码的数据转换回二进制数据。
- name: Base64 encoding and decoding of values
ansible.builtin.assert:
that:
- "'{{ 'âÉïôú' | b64encode }}' is eq( 'w6LDicOvw7TDug==' )"
- "'{{ 'w6LDicOvw7TDug==' | b64decode }}' is eq( 'âÉïôú' )"在将字符串发送到底层shell之前,为了避免解析或代码注入问题,最好使用 quota 过滤器来净化字符串(加引号)。
- name: Put quotes around 'my_string'
shell: echo {{ my_string | quote }}3)格式化文本
使用 lower、upper、capitalize 过滤器可以实现字符串的全大写、全小写、首字母大写的格式化转换。
| 功能 | 过滤器 | 描述 | 示例 | 结果 |
| 文本格式化 | lower | 将字符串转为全小写 | {{ 'Marvin' | lower }} | marvin |
| upper | 将字符串转为全大写 | {{ 'Marvin' | upper }} | MARVIN | |
| capitalize | 将字符串首字母大写 | {{ 'marvin' | capitalize }} | Marvin |
- name: Change case of characters
ansible.builtin.assert:
that:
- "'{{ 'Marvin' | lower }}' is eq( 'marvin' )"
- "'{{ 'Marvin' | upper }}' is eq( 'MARVIN' )"
- "'{{ 'marvin' | capitalize }}' is eq( 'Marvin' )"4)替换文本
| 功能 | 过滤器 | 描述 | 示例 | 结果 |
| 文本替换 | replace | 简单字符串替换 | {{ 'marvin, arthur' | replace('ar','**') }} | m**vin, **thur |
| regex_search | 正则表达式匹配 | {{ 'marvin, arthur' | regex_search('ar\S*r') }} | arthur | |
| regex_replace | 正则表达式替换 | {{ 'arthur up' | regex_replace('ar(\S*)r','\\1mb') }} | thumb up |
使用 replace 过滤器可以实现字符串的字串替换。
- name: Replace 'ar' with asterisks
ansible.builtin.assert:
that:
- "'{{ 'marvin, arthur' | replace('ar','**') }}' is eq( 'm**vin, **thur' )"使用 regex_search 和 regex_replace 过滤器可以实现基于正则表达式的更复杂的字符串检索及替换操作.
- name: Test results of regex search and search-and-replace
ansible.builtin.assert:
that:
- "'{{ 'marvin, arthur' | regex_search('ar\S*r') }}' is eq( 'arthur' )"
- "'{{ 'arthur up' | regex_replace('ar(\S*)r','\\1mb') }}' is eq( 'thumb up' )"1. regex_search('ar\S*r')
正则表达式 ar\S*r 解析
- - ar:匹配字母 "ar"(必须按顺序出现)。
- - \S:匹配任意非空白字符(\S = 非 \s,即非空格、制表符等)。
- - *:表示前一个字符 (\S)可以重复 0 次或多次。
- - r:最后匹配字母 "r"。
匹配过程
"marvin, arthur" 中有两处可能的匹配:
- - "marv"(mar开头的部分,但后面没有 r 结尾,不匹配)
- - "arthur"(匹配 ar + thu(\S*) + r)
2. regex_replace('ar(\S*)r', '\\1mb')
正则表达式 ar(\S*)r 解析
- - ar:匹配 "ar"。
- - (\S*):捕获组(() 表示捕获),匹配任意数量的非空白字符并记录(\S* 相当于前面的 \S 加上 *)。
- - r:匹配最后的 "r"。
替换模式 \\1mb 解析
- - \\1:引用第一个捕获组(即 \S* 匹配到的内容)。
6. 结构化数据操作
Ansible 广泛使用 JSON 格式处理结构化数据,其与 YAML 高度兼容。通过 JSON 过滤器可以高效操作 API 返回的复杂数据结构。
1)查询结构化数据
可以将selectattr与map过滤器结合使用,从结构化的Ansible数据中提取信息
-
利用selectattr过滤器,可以根据列表中对象的某种属性来选择一系列对象;
-
利用map过滤器,可以将字典列表转换为基于给定属性的简单列表。
| 过滤器 | 作用 | 示例片段 |
| selectattr | 根据属性值筛选列表中的字典 | selectattr('name', '==', 'Control Plane Execution Environment') |
| map | 提取字典列表中指定属性的值生成新列表 | map(attribute='id') → 将匹配项的id字段提取为列表 |
| first | 从结果列表中提取第一个元素(避免返回单元素列表) | first → 直接返回ID值而非 [id]列表 |
看看下面剧本示例:用来查询位于/api/v2/execution_environments/的API端点并显示Control Plane Execution Environment自动化控制器资源的ID。
---
- name: Query automation controller execution environments # 查询自动化控制器执行环境
hosts: localhost
gather_facts: false
tasks:
- name: Query EEs # 发送API请求
vars:
username_password: "admin:redhat"
ansible.builtin.uri:
url: https://controller.lab.example.com/api/v2/execution_environments/
method: GET
headers:
Authorization: Basic {{ username_password | string | b64encode }}
validate_certs: false
register: query_results # 注册API返回结果
- name: Show execution environment ID # 显示执行环境ID
ansible.builtin.debug:
msg: "{{ query_results['json']['results'] | selectattr('name', '==', 'Control Plane Execution Environment') | map(attribute='id') | first }}"query_results['json']['results'] 变量是一个列表,包含了每个执行环境资源的条目。因为每个条目都定义了一个name键,所以可以使用 selectattr筛选器 为Control Plane Execution Environment资源选择条目。选择到正确的条目后,可以使用 map过滤器 显示该条目中任何键的值,例如id键的值。由于selectattr过滤器与map过滤器相结合经常会创建一个由一个项目组成的列表,因此可以使用 first过滤器 来选择这个项目。
数据处理流程模拟:
{
"json": {
"results": [
{"name": "Automation Hub Default execution environment", "id": 101},
{"name": "Control Plane Execution Environment", "id": 102},
{"name": "Automation Hub Ansible Engine 2.9 execution environment", "id": 103}
]
}
}过滤器链式操作:
query_results['json']['results']
→ 原始列表
| selectattr('name', '==', 'Control Plane Execution Environment')
→ [{"name": "Control Plane...", "id": 102}] # 筛选后列表
| map(attribute='id')
→ [102] # 提取ID值
| first
→ 102 # 最终输出selectattr 参数 技术细节说明
语法:selectattr('属性名', '操作符', '对比值')
支持的操作符:==(等于)、!=(不等于)、match(正则匹配)等
剧本可能会产生以下输出,以指示Control Plane Execution Environment资源的ID为102:
PLAY [Query automation controller EEs] *****************************************
TASK [Query projects] **********************************************************
ok: [localhost]
TASK [Show execution environment ID] *******************************************
ok: [localhost] => {
"msg": "102"
}
PLAY RECAP *********************************************************************
localhost : ok=2 changed=0 unreachable=0 failed=0 ...类似地,可以传递 query_results['json']['results'] 变量到map过滤器来列出所有的执行环境的名称。
- name: Show execution environment names
ansible.builtin.debug:
msg: "{{ query_results['json']['results'] | map(attribute='name') }}"将此任务添加到上一个剧本会生成以下附加输出:
TASK [Show execution environment names] ****************************************
ok: [localhost] => {
"msg": [
"Control Plane Execution Environment",
"Automation Hub Default execution environment",
"Automation Hub Ansible Engine 2.9 execution environment",
]
}可以将selectattr和map过滤器与JSON和YAML数据结构一起使用。
2)结构化数据转换
将结构化的数据转换为文本 和 从文本转换成结构化的数据,对于自动化任务的调试和通信非常有用。
-
结构化的数据可以通过to_json和to_yaml过滤器转换为JSON或YAML格式。
-
使用to_nice_json和to_nice_yaml过滤器可以获得格式化的、更易读的输出。
| 过滤器 | 作用 | 示例 | 结果 |
| to_json | 将数据结构转为紧凑JSON字符串 | {{ hosts | to_json }} | {"name":"bastion","ip":["172.25.250.254","172.25.252.1"]} |
| to_nice_json | 生成带缩进的易读JSON | {{ hosts | to_nice_json }} | { "name": "bastion", "ip": [ "172.25.250.254", "172.25.252.1" ] } |
| to_yaml | 转为紧凑YAML格式 | {{ hosts | to_yaml }} | name: bastion\nip:\n- 172.25.250.254\n- 172.25.252.1 |
| to_nice_yaml | 生成标准缩进YAML | {{ hosts | to_nice_yaml }} | name: bastion ip: - 172.25.250.254 - 172.25.252.1 |
- name: Convert between JSON and YAML format
vars:
hosts:
- name: bastion
ip:
- 172.25.250.254
- 172.25.252.1
hosts_json: '[{"name": "bastion", "ip": ["172.25.250.254", "172.25.252.1"]}]'
ansible.builtin.assert:
that:
- "'{{ hosts | to_json }}' is eq( hosts_json )"后续章节还会介绍一些其他的过滤器。
查看Ansible和Jinja2的官方文档,可以了解更多有用的过滤器。
7. 课堂练习:使用过滤器处理变量
开始练习(部署环境):
以用户student登入workstation虚拟机,使用lab命令来构建案例环境。
[student@workstation ~]$ lab start data-filters步骤说明:
1)克隆项目到/home/student/git-repos目录,并创建exercise分支。此练习无需更改deploy_haproxy.yml剧本或haproxy角色
创建目录/home/student/git-repos/并进入此目录:
[student@workstation ~]$ mkdir -p ~/git-repos
[student@workstation ~]$ cd ~/git-repos克隆项目,并进入克隆后的项目目录:
[student@workstation git-repos]$ git clone https://git.lab.example.com/student/data-filters.git
[student@workstation git-repos]$ cd data-filters检出exercise分支:
[student@workstation data-filters]$ git checkout -b exercise运行deploy_haproxy.yml剧本来部署负载均衡器
[student@workstation data-filters]$ ansible-navigator run -m stdout deploy_haproxy.yml
[student@workstation data-filters]$ curl servera
<html><body><h1>503 Service Unavailable</h1>
No server is available to handle this request.
</body></html>由于还没有部署web服务器,当访问servera站点时会返回503的HTTP状态码:
2)分析apache角色的任务列表及变量设置
检查apache角色 roles/apache/tasks/main.yml 的任务列表。
[student@workstation data-filters]$ cat roles/apache/tasks/main.yml
---
# tasks file for apache
- name: Calculate the package list
ansible.builtin.set_fact:
# TODO: Combine the apache_base_packages and
# apache_optional_packages variables into one list.
apache_package_list: "{{ apache_base_packages }}"
- name: Ensure httpd packages are installed
ansible.builtin.yum:
name: "{{ apache_package_list }}"
state: present
# TODO: omit the 'enablerepo' directive
# below if the apache_enablerepos_list is empty;
# otherwise use the list as the value for the
# 'enablerepo' directive.
# enablerepo: "{{ apache_enablerepos_list }}"
- name: Ensure SELinux allows httpd connections to a remote database
seboolean:
name: httpd_can_network_connect_db
state: true
persistent: true
- name: Ensure httpd service is started and enabled
ansible.builtin.service:
name: httpd
state: started
enabled: true-
分析1:变量 apache_package_list 必须是安装httpd服务所需的基本包和可选包的组合列表。你可以在后面的步骤中编辑并更正这个变量的定义。apache_base_packages角色的变量定义为一个列表,其中包含httpd包。为了防止被主机组变量覆盖,在 roles/apache/vars/main.yml 文件中定义了这个变量。
[student@workstation data-filters]$ cat roles/apache/vars/main.yml
apache_base_packages:
- httpd-
分析:2:角色文件 roles/apache/defaults/main.yml 中将apache_optional_packages变量定义为空列表。
[student@workstation data-filters]$ cat roles/apache/defaults/main.yml
apache_optional_packages: []
apache_enablerepos_list: []-
分析:3:变量 apache_enabledrepos_list 包含Yum仓库ID的列表。为了安装必要的软件包,这个列表中的任何仓库都会临时启用。默认值是一个空列表,如roles/apache/defaults/main.yml文件中所定义:
3)修正apache角色第一个任务中的apache_package_list变量的Jinja2表达式,为主机组web_servers定义apache_optial_packages变量,包含git、php和php-mysqlnd值。删除第一个任务的TODO注释部分
编辑角色文件 roles/apache/tasks/main.yml,使用union过滤器将apache_base_packages和apache_option_packages变量合并成单个列表。删除TODO注释部分,保存文件内容。
第一个任务应包括以下内容:
[student@workstation data-filters]$ vim roles/apache/tasks/main.yml
- name: Calculate the package list
ansible.builtin.set_fact:
apache_package_list: "{{ apache_base_packages | union(apache_optional_packages) }}"新建文件 group_vars/web_servers/apache.yml,用来定义apache_optional_packages变量,包括三个包的列表:git、php和php-mysqlnd。这个变量将覆盖分析2中 roles/apache/defaults/main.yml 角色变量的默认值。
group_vars/web_servers/apache.yml文件应包含以下内容:
[student@workstation data-filters]$ vim group_vars/web_servers/apache.yml
apache_optional_packages:
- git
- php
- php-mysqlnd4)从apache角色的第二个任务中删除enablerepo指令中的注释。如果变量的布尔值为false,请编辑指令的Jinja2表达式以使用default过滤器忽略此指令。删除第二个任务的TODO注释部分
编辑角色文件 roles/apache/tasks/main.yml,使用default过滤器为 apache_enablerepos_list 添加默认值,因为默认是空列表。删除TODO注释部分,保存文件内容。
第二项任务应包括以下内容:
[student@workstation data-filters]$ vim roles/apache/tasks/main.yml
- name: Ensure httpd packages are installed
ansible.builtin.yum:
name: "{{ apache_package_list }}"
state: present
enablerepo: "{{ apache_enablerepos_list | default(omit, true) }}"apache_enablerepos_list:是一个变量,预期包含需要临时启用的 YUM 仓库名称列表(如 ['epel', 'remi'])。如果未定义该变量,则触发后续的默认值处理。
default(omit, true):
omit:Ansible 的特殊值,表示「忽略此参数」,最终不会向 yum 模块传递 enablerepo 参数。
true:启用严格模式,当变量值为以下情况时也视为「未定义」:空字符串 ""、空列表 []、布尔值 false、null 或 None
当变量有效时(如 apache_enablerepos_list: ['epel']):enablerepo: "epel" # 实际传递给yum模块的参数
当变量无效时(未定义/空列表/空字符串等):# 完全省略enablerepo参数,yum模块将使用系统默认仓库
最后完成的 roles/apache/tasks/main.yml 文件应当包含如下内容:
---
# tasks file for apache
- name: Calculate the package list
ansible.builtin.set_fact: # 合并基础包和可选包列表
apache_package_list: "{{ apache_base_packages | union(apache_optional_packages) }}"
- name: Ensure httpd packages are installed
ansible.builtin.yum:
name: "{{ apache_package_list }}" # 安装合并后的软件包列表
state: present # 确保已安装
enablerepo: "{{ apache_enablerepos_list | default(omit, true) }}" # 动态启用所需的YUM仓库(未定义时自动忽略该参数)
- name: Ensure SELinux allows httpd connections to a remote database
seboolean:
name: httpd_can_network_connect_db # SELinux布尔值名称
state: true # 启用该权限
persistent: true # 永久生效(重启后保持)
- name: Ensure httpd service is started and enabled
ansible.builtin.service:
name: httpd
state: started
enabled: true5)使用导航器结合-v选项来运行deploy_apache.yml剧本并显示详细信息,确认apache_package_list指标中包含了可选包。
[student@workstation data-filters]$ ansible-navigator run -m stdout deploy_apache.yml -v
...output omitted...
TASK [apache : Calculate the package list] *********************************** ok: [webserver_01] => {"ansible_facts": {"apache_package_list": ["httpd", "git","php", "php-mysqlnd"]}, "changed": false}
...output omitted...6)查看webapp角色的任务列表和变量定义。webapp角色确保每个主机上都存在正确的web应用内容。正确实现后,该角色将从web根目录中删除不属于web应用的内容
编辑Web应用程序角色中具有TODO注释的三个任务。使用过滤器来实现每个注释中指示的功能。
整体流程总结
-
初始化内容:确保 index.html 存在(带版本信息)。
-
查找文件:获取服务器现有文件列表。
-
路径处理:规范化路径格式(绝对 → 相对)。
-
差异对比:计算需要删除的文件(不在 webapp_file_list 中的文件)。
-
清理:删除多余文件。
关键变量关系

查看修改前的 roles/webapp/tasks/main.yml 文件中的任务:
[student@workstation data-filters]$ cat roles/webapp/tasks/main.yml
---
# tasks file for webapp
- name: Ensure stub web content is deployed # 部署临时网页内容
ansible.builtin.copy:
content: "{{ webapp_message }} (version {{ webapp_version }})\n" # 动态生成内容
dest: "{{ webapp_content_root_dir }}/index.html" # 目标路径
# 功能:创建包含版本号的基础页面
- name: Find deployed webapp files # 扫描已部署的Web应用文件
ansible.builtin.find:
paths: "{{ webapp_content_root_dir }}" # 扫描目录
recurse: true # 递归查找子目录
register: webapp_find_files # 注册结果到变量
- name: Compute webapp file list # 计算Web应用文件列表(待实现)
ansible.builtin.set_fact:
# TODO: Use the map filter to extract the 'path' attribute of each entry in the 'webapp_find_files' variable 'files' list.
# TODO: 需使用map过滤器从 webapp_find_files.files 列表中提取path属性
webapp_deployed_files: []
- name: Compute relative webapp file list # 计算相对路径文件列表(待实现)
ansible.builtin.set_fact:
# TODO: Use the 'map' filter, along with the 'relpath' filter, to create the 'webapp_rel_deployed_files' variable from the 'webapp_deployed_files' variable.
# Files in the 'webapp_rel_deployed_files' variable should have a path relative to the 'webapp_content_root_dir' variable.
# TODO: 需结合relpath过滤器和 webapp_content_root_dir 生成相对路径
webapp_rel_deployed_files: []
- name: Remove Extraneous Files # 清理多余文件(待实现)
ansible.builtin.file:
path: "{{ webapp_content_root_dir }}/{{ item }}" # 文件路径
state: absent
# TODO: Loop over a list of files that are in the 'webapp_rel_deployed_files' list, but not in the 'webapp_file_list' list.
# Use the difference filter.
# TODO: 需使用difference过滤器比较两个列表
loop: [] # 当前为空(待补全)-
webapp_content_root_dir 变量定义了每个web服务器上web应用程序的目录位置,默认值为/var/www/html。
-
在 roles/webapp/vars/main.yml 文件中定义了 webapp_file_list 变量(是预定义的合法文件列表),用来指明web应用程序的文件清单(当前这个版本,唯一的文件是index.html)。
第一部分:Ensure stub web content is deployed(确保部署初始 Web 内容)
动态注入 webapp_message(可能来自变量,如品牌信息)和 webapp_version(当前版本号),便于部署时追踪版本。
- name: Ensure stub web content is deployed
ansible.builtin.copy:
content: "{{ webapp_message }} (version {{ webapp_version }})\n"
dest: "{{ webapp_content_root_dir }}/index.html"创建一个最简单的 index.html 文件,内容是:{{ webapp_message }} (version {{ webapp_version }});目标路径是:/var/www/html/index.html(默认)
第二部分:Find deployed webapp files(查找已部署的 Web 文件)
使用 find 模块递归扫描 webapp_content_root_dir(默认 /var/www/html)下的所有文件。将结果存入变量 webapp_find_files(包含文件路径、大小、权限等元数据)。
- name: Find deployed webapp files
ansible.builtin.find:
paths: "{{ webapp_content_root_dir }}"
recurse: true //递归扫描
register: webapp_find_files输出结构示例:
# {
# "files": [
# {"path": "/var/www/file1", "isdir": false},
# {"path": "/var/www/sub/file2", "isdir": false}
# ]
# }
第三部分:Compute the webapp file list(计算 Web 文件列表)
需要从 webapp_find_files.files 列表中提取每个文件的完整路径。结果存入新变量 webapp_deployed_files
- name: Compute the webapp file list
ansible.builtin.set_fact:
webapp_deployed_files: "{{ webapp_find_files['files'] | map(attribute='path') | list }}"定义一个Jinja2表达式空列表 webapp_deployed_files变量。从webapp_find_files['files']变量开始,先用map过滤器,再用list过滤器。为map过滤器提供attribute=“path”的参数,以从列表中的每个条目检索路径属性。删除TODO注释。
第四部分:Compute the relative webapp file list(计算相对路径列表)
使用 relpath 过滤器,将绝对路径转换为 相对于 webapp_content_root_dir 的相对路径,结果存入 webapp_rel_deployed_files。
例如 /var/www/html/index.html → index.html
- name: Compute the relative webapp file list
ansible.builtin.set_fact:
webapp_rel_deployed_files: "{{ webapp_deployed_files | map('relpath', webapp_content_root_dir) | list }}"-
map 过滤器:对 webapp_deployed_files 列表中的 每个元素应用 relpath 方法。类似于 Python 的 map(function, iterable),逐个处理列表中的路径。
-
relpath 功能:计算 相对路径(Relative Path)。
-
参数:webapp_content_root_dir 是基准目录(如 "/var/www/html")。对每个绝对路径,计算其相对于基准目录的相对路径。
-
定义一个Jinja2表达式空列表 webapp_rel_deployed_files变量。从webapp_deployed_files变量开始,先用map过滤器,再用list过滤器。map过滤器的第一个参数是relpath字符串,它对webapp_deployed_files列表的每个项执行relpath函数。map函数的第二个参数是webapp_content_root_dir变量,这个变量作为参数传递给relpath函数。删除TODO注释。
第五部分:Remove Extraneous Files(清理多余文件)
找出实际存在但配置中不需要的文件(webapp_file_list 是预定义的合法文件列表),确保服务器上只保留当前版本需要的文件,删除旧版本残留文件,减少安全风险和混乱。
- name: Remove Extraneous Files
ansible.builtin.file:
path: "{{ webapp_content_root_dir }}/{{ item }}"
state: absent
loop: "{{ webapp_rel_deployed_files | difference(webapp_file_list) }}"使用 difference 过滤器找出 已部署但不在 webapp_file_list 中的文件:
-
例如 webapp_rel_deployed_files = ["index.html", "test.html"]
-
webapp_file_list = ["index.html"]
-
结果:difference(...) → ["test.html"]
遍历这些文件,用 file 模块将其删除(state: absent)。
将webapp角色中第五个任务中的空循环列表替换为Jinja2表达式。从webapp_rel_deployed_files变量开始,使用difference差异过滤器,将webapp_file_list变量作为此过滤器的参数。删除TODO注释。
保存对roles/webapp/tasks/main.yml文件的更改,最终修改完毕的内容如下:
---
# tasks file for webapp
- name: Ensure stub web content is deployed
ansible.builtin.copy:
content: "{{ webapp_message }} (version {{ webapp_version }})\n"
dest: "{{ webapp_content_root_dir }}/index.html"
- name: Find deployed webapp files
ansible.builtin.find:
paths: "{{ webapp_content_root_dir }}"
recurse: true
register: webapp_find_files
- name: Compute the webapp file list
ansible.builtin.set_fact:
webapp_deployed_files: "{{ webapp_find_files['files'] | map(attribute='path') | list }}"
- name: Compute the relative webapp file list
ansible.builtin.set_fact:
webapp_rel_deployed_files: "{{ webapp_deployed_files | map('relpath', webapp_content_root_dir) | list }}"
- name: Remove Extraneous Files
ansible.builtin.file:
path: "{{ webapp_content_root_dir }}/{{ item }}"
state: absent
loop: "{{ webapp_rel_deployed_files | difference(webapp_file_list) }}"7)使用导航器结合-v选项来运行deploy_webapp.yml剧本。验证剧本是否标识了webserver_01上的非应用程序文件并将其删除
[student@workstation data-filters]$ ansible-navigator run -m stdout deploy_webapp.yml -v
...output omitted...
TASK [webapp : Compute the webapp file list] *********************************
ok: [webserver_01] => {"ansible_facts": {"webapp_deployed_files": ["/var/www/html/test.html", "/var/www/html/index.html"]}, "changed": false}
ok: [webserver_02] => {"ansible_facts": {"webapp_deployed_files": ["/var/www/html/index.html"]}, "changed": false}
TASK [webapp : Compute the relative webapp file list] ************************
ok: [webserver_01] => {"ansible_facts": {"webapp_rel_deployed_files":
["test.html", "index.html"]}, "changed": false}
ok: [webserver_02] => {"ansible_facts": {"webapp_rel_deployed_files": ["index.html"]}, "changed": false}
TASK [webapp : Remove Extraneous Files] **************************************
changed: [webserver_01] => (item=test.html) => {"ansible_loop_var": "item", "changed": true, "item": "test.html", "path": "/var/www/html/test.html", "state": "absent"}
PLAY RECAP *******************************************************************
webserver_01 : ok=5 changed=2 unreachable=0 failed=0 skipped=0 ...
webserver_02 : ok=4 changed=1 unreachable=0 failed=0 skipped=1 ...webserver_01主机最初在/var/www/html目录中部署了两个文件:test.html和index.html。有权访问这个主机的人可能在web服务器上安装了临时测试页。这个剧本从web根目录中删除任何不属于实际web应用程序的web服务器文件。
结束练习(清理环境):
在workstation虚拟机上,切换到student用户主目录,使用lab命令来清理案例环境,确保先前练习的资源不会影响后续的练习。
[student@workstation ~]$ lab finish data-filters二、使用查找插件处理外部数据
1. Lookup函数查找插件及调用
查找插件是 Ansible 对 Jinja2 模板语言的扩展,属于插件体系中的一类特殊组件。它们使 Ansible 能够从 外部数据源(如文件、环境变量、数据库或 API)动态获取数据,并将其注入到 Playbook 或模板中使用。
通过以下两个 Jinja2 函数调用查找插件,语法类似过滤器:
| 函数 | 语法示例 | 关键区别 |
| lookup | {{ lookup('file', '/path/to/file.txt') }} | - 返回原始数据(可能含特殊字符) - 适用于直接操作(如读取文件内容) |
| query | {{ query('env', 'HOME') }} | - 返回标准化数据结构 - 推荐用于大多数场景(Ansible 2.5+) |
指定函数的名称,并在括号中指定要调用的查找插件的名称以及插件所需的任何参数。
例如,以下变量定义使用 file查找插件 将/etc/hosts文件的内容放到hosts变量中:
vars:
hosts: "{{ lookup('ansible.builtin.file', '/etc/hosts') }}"
使用file插件时,可以包含多个文件名。通过lookup函数调用file插件时,每个文件的内容在结果值中用逗号分隔。考虑以下Jinja2模板表达式:
vars:
hosts: "{{ lookup('ansible.builtin.file', '/etc/hosts', '/etc/issue') }}"
这个lookup表达式产生以下结构(合并为一个整体):
hosts: "127.0.0.1 localhost localhost.localdomain localhost4
localhost4.localdomain4\n::1 localhost localhost.localdomain localhost6
localhost6.localdomain6\n\n,\\S\nKernel \\r on an \\m (\\l)"
在Ansible 2.5及更高版本中,可以使用query函数或其缩写q代替lookup来调用查找插件。两者的区别在于,query总是返回一个列表,而不是以逗号分隔返回的值,这样更容易解析和使用。
你可以使用以下命令调用前面的示例:
vars:
hosts: "{{ query('ansible.builtin.file', '/etc/hosts', '/etc/issue') }}"
这个query表达式产生以下结构(每个文件内容一整行):
hosts:
- "127.0.0.1 localhost localhost.localdomain localhost4
localhost4.localdomain4\n::1 localhost localhost.localdomain localhost6
localhost6.localdomain6\n\n"
- "\\S\nKernel \\r on an \\m (\\l)"
2. 选择合适的Lookup查找插件
Ansible默认提供大量的插件:
-
使用 ansible-navigator doc --mode stdout -t lookup -l :获得一个查询插件列表
-
使用 ansible-navigator doc --mode stdout -t lookup PLUGIN_NAME:了解某个插件的用途和使用方法
1)读取文件内容(file插件)
Ansible使用file插件将本地文件的内容加载到变量中。如果提供的是一个相对路径,插件会在剧本的files子目录中查找文件。
下面例子读取用户的公钥文件的内容,并通过ansible.posix.authorized_key模块将授权密钥添加到受管主机。
- name: Add authorized keys
hosts: all
vars: # 声明一个列表变量 users,包含两个用户名 fred 和 naoko
users:
- fred
- naoko
tasks:
- name: Add authorized keys
ansible.posix.authorized_key:
user: "{{ item }}" # 动态指定目标用户,item 是循环变量,依次取值为 fred 和 naoko
key: "{{ lookup('ansible.builtin.file', item + '.key.pub') }}" # 通过 lookup 插件从本地文件读取公钥内容。
loop: "{{ users }}" # 对 users 列表进行循环,分别为 fred 和 naoko 执行任务这个示例使用了loop循环和+运算符来拼装字符串,以查找这两个用户的files/fred.key.pub和files/naoko.key.pub文件(这两个文件已经包含在files目录下)。
1)遍历用户列表 users(fred 和 naoko)。
2)对于每个用户:
- 从控制节点读取对应的 .key.pub 公钥文件(如 fred.key.pub)。
- 将公钥内容写入目标主机上该用户的 ~/.ssh/authorized_keys 文件中。
最终效果:用户 fred 和 naoko 可以通过对应的私钥无密码登录所有目标主机。
关键注意事项:
① 公钥文件路径:
确保 fred.key.pub 和 naoko.key.pub 文件存在于 Ansible 控制节点的正确路径下。如果文件不存在,任务将失败。
② 用户家目录:
假设目标主机上已存在用户 fred 和 naoko,且家目录已创建。如果用户不存在,需先使用 user 模块创建用户。
③ 权限问题:
authorized_key 模块会自动创建 .ssh 目录并设置正确的权限(700 目录权限,600 文件权限)。
④ 幂等性:
如果公钥已存在于 authorized_keys 中,模块不会重复添加,确保操作安全。
file插件可以使用 from_yaml 或 from_json 过滤器将YAML和JSON格式的文件解析为正确的结构化数据。
my_yaml: "{{ lookup('ansible.builtin.file', '/path/to/my.yaml') | from_yaml }}"
注意:file插件读取执行环境中的文件,而不是控制节点或受管主机上的文件。
关于 file 插件与文件路径的差异:
默认情况下(如使用 ansible-playbook 或 ansible-navigator --ee false):
- file 插件会从 Ansible 控制节点(运行 Playbook 的主机)上读取文件(如 fred.key.pub)。
使用执行环境(Execution Environment, EE)时(如默认的 ansible-navigator):
- file 插件会从 执行环境容器内部 读取文件,而非控制节点或受管主机。需确保文件在构建执行环境时已嵌入容器内(例如通过 COPY 指令)。
如果你不是想要执行环境或项目目录中的文件的内容,需直接读取 受管主机 上的文件(如 /home/user/.ssh/id_rsa.pub),应改用 ansible.buildin.slurp 模块,而不是直接用查找插件。
下面这个例子使用受管主机上/home/user/.ssh/id_rsa.pub文件的内容设置pub_key变量。
- name: 读取受管主机上的公钥
ansible.builtin.slurp:
src: /home/user/.ssh/id_rsa.pub
register: pub_key
- name: 添加公钥到目标用户
ansible.posix.authorized_key:
user: "{{ item }}"
key: "{{ pub_key.content | b64decode }}"
loop: "{{ users }}"slurp 会将文件内容以 Base64 编码返回,需用 b64decode 过滤器解码。
2)使用模板处理数据(template插件)
与file插件一样,两者都会读取指定文件的内容,并将其作为字符串返回。不同之处在于,template插件希望提供的文件内容是Jinja2模板,并在处理内容之前评估该模板。如果提供的模板文件是一个相对路径,插件会在剧本的templates目录中来查找。
| 特性 | file插件 | template插件 |
| 文件处理方式 | 直接返回原始文件内容 | 先解析文件中的Jinja2 模板语法,再返回渲染后的内容 |
| 文件路径查找 | 默认从控制节点或执行环境读取 | 优先在 Playbook 的templates/目录查找(若路径为相对路径) |
| 适用场景 | 静态文件(如公钥、配置文件) | 动态模板(如变量替换、条件逻辑) |
下面这个例子处理templates/my.template.js2模板。
{{ lookup('ansible.builtin.template', 'my.template.j2') }}
例如,假设这个模板包含如下内容:
Hello {{ name }}.
则下面的任务会显示字符串“Hello class.”:
- name: Print "Hello class."
vars:
name: class
ansible.builtin.debug:
msg: "{{ lookup('ansible.builtin.template', 'my.template.j2') }}"template插件还接受一些额外的参数,例如定义开始和结束的标记序列。如果输出字符串是YAML值,convert_data 选项将解析该字符串以提供结构化数据。
| 参数 | 说明 | 示例 |
| template_vars | 向模板传递额外变量(覆盖现有变量) | template_vars={"custom_var": "value"} |
| jinja2_native | 是否使用 Jinja2 原生类型(如False时字符串化所有输出) | jinja2_native=True |
| variable_start_string variable_end_string | 自定义 Jinja2 变量标记(默认{{和}}) | variable_start_string="[%" variable_end_string="%]" |
| comment_start_string comment_end_string | 自定义注释标记(默认{#和#}) | comment_start_string=" " |
| convert_data | 若输出是 YAML/JSON,自动解析为结构化数据(如字典、列表) | convert_data=True |
注意不要将template查找插件与template模块混淆了。
# 使用查找插件(返回内容给变量)
- name: 生成动态 SQL 查询
set_fact:
sql_query: "{{ lookup('ansible.builtin.template', 'query.sql.j2') }}"# 使用模块(写入文件到受管主机)
- name: 部署 Nginx 配置
ansible.builtin.template:
src: nginx.conf.j2
dest: /etc/nginx/nginx.conf3)在执行环境中读取命令输出
pipe管道和lines线路插件都可以在执行环境中运行命令并返回输出。pipe插件返回执行命令后生成的原始输出;lines插件则将命令的输出拆分为行。
例如,以下Jinja2表达式会将ls返回的原始输出作为字符串返回:
{{ query('ansible.builtin.pipe', 'ls files') }}
如果改用lines插件,则会生成一个列表,其中将ls返回的每一行输出都作为列表项:
{{ query('ansible.builtin.lines', 'ls files') }}
你可以使用line插件从一组命令中检索输出结果的第一行(或任何特定行):
- name: Prints the first line of some files
ansible.builtin.debug:
msg: "{{ item[0] }}"
loop:
- "{{ query('ansible.builtin.pipe', 'cat files/my.file') }}"
- "{{ query('ansible.builtin.lines', 'cat files/my.file.2') }}"当然,实际上可以使用head命令来完成这个任务,可能会更有效率。
4)从URL获取内容
与file插件从文件中获取内容的方式类似,url插件从给定的url网址中获取内容。
{{ lookup('ansible.builtin.url', 'https://my.site.com/my.file') }}
有许多选项可用于控制身份验证、选择web代理或将返回的内容拆分为行。
使用url插件的一个好处是,你可以将返回的数据用作变量中的值,必要时还可以根据需要先使用过滤器进行处理。
5)从Kubernetes API获取信息
kubernetes.core.k8s插件通过openshift模块提供了对kubernetes API的完全访问。要获取Kubernetes对象,必须使用kind选项来指定对象类型。如果能提供额外的关于对象的详细信息,例如namespace或label_selector选项,会更有利于筛选结果。
{{ lookup('kubernetes.core.k8s', kind='Deployment', namespace='ns', resource_name='my_res') }}
注意,kubernetes.core.k8s插件是一个查找插件。它的主要目的是从Kubernetes集群中提取信息,而不是更新它。要管理Kubernete集群请使用kubernetes.core.k8s模块。
6)使用自定义查找插件
插件实际上是Python脚本。你可以开发自定义的插件,并在你的剧本中使用这些插件。
要让Ansible找到这些自定义的查找插件,请将它们复制到以下位置之一:
-
在自定义的内容集中,将查找插件脚本复制到 ./plugins/lookup/ 目录
-
在自定义的角色中,将查找插件脚本复制到 ./filter_plugins目录
-
在Ansible项目中,将查找插件脚本复制到剧本同级的 ./lookup_plugins目录
Ansible团队建议使用集合来分发自定义插件,插件开发在本课程中不做详细讨论。
3. Lookup 插件的错误处理机制 (errors 参数)
在 Ansible 中,大多数插件(如模块) 在遇到错误(例如文件不存在、权限不足等)时会直接中止 Playbook 的执行。但 lookup 插件 的行为不同,因为它是委托给其他插件(如 file、template) 执行具体操作的,而这些底层插件可能不需要强制中断流程。例如,如果找不到文件,file插件可能不需要中止剧本,而是在恢复后继续执行剧本。
为了适应不同的插件需求,lookup 插件通过 errors 参数 控制错误处理方式,可选值包括:
| 选项 | 行为 | 适用场景 |
| strict(默认) | 错误时中止 Playbook | 需要严格校验的场景(如关键配置缺失) |
| ignore | 静默忽略错误,返回空值("") | 可跳过非关键文件(如可选配置文件) |
| warn | 显示警告但继续执行 | 记录问题但仍允许任务继续 |
-
errors选项的默认值是strict。这意味着如果底层脚本失败,lookup插件将引发致命错误。
-
如errors选项的值为ignore,则lookup插件会自动忽略该错误并返回一个空字符串或列表。
-
如errors选项的值为warn,则当基础脚本失败并返回空字符串(或空列表)时,lookup插件会记录一个警告。
1)忽略缺失的文件
- name: 尝试读取可选配置文件(忽略错误)
debug:
msg: "{{ lookup('ansible.builtin.file', '/path/to/optional.conf', errors='ignore') }}"若文件不存在,返回空字符串而非报错。
2)仅警告不中断
- name: 检查日志文件(仅警告)
debug:
msg: "{{ lookup('ansible.builtin.file', '/var/log/app.log', errors='warn') }}"文件缺失时输出警告,但 Playbook 继续执行。
3)默认严格模式
- name: 读取必需密钥文件(严格模式)
debug:
msg: "{{ lookup('ansible.builtin.file', '/etc/ssl/key.pem') }}" # 等效于 errors='strict'文件不存在时立即中止 Playbook。
注意:非所有插件支持:仅 lookup 插件及其委托的插件(如 file、template)支持此参数。
4. 课堂练习:使用查找插件处理外部数据
开始练习(部署环境):
以用户student登入workstation虚拟机,使用lab命令来构建案例环境。
[student@workstation ~]$ lab start data-lookups步骤说明:
1)从https://git.lab.example.com/student/data-lookups.git仓库克隆项目到/home/student/Git repos目录,并创建exercise分支
创建/home/student/git-repos目录,并进入此目录:
[student@workstation ~]$ mkdir -p ~/git-repos/
[student@workstation ~]$ cd ~/git-repos/克隆https://git.lab.example.com/student/data-lookups.git项目,并进入项目目录:
[student@workstation git-repos]$ git clone https://git.lab.example.com/student/data-lookups.git
[student@workstation git-repos]$ cd data-lookups检出exercise分支:
[student@workstation data-lookups]$ git checkout -b exercise2)为site.yml剧本编写任务,使用来自groups.yml文件的YAML格式的内容创建组账号
观察groups.yml文件内容:
[student@workstation data-lookups]$ cat groups.yml
---
- name: devs
members:
- user1
- user2
- name: ops
members:
- user3读取YAML格式的文件内容可以采取多种方法
对于site.yml剧本中的"load group information"任务,可使用ansible.builtin.file查询插件来读取,再使用from_yaml过滤器将数据加载到结构化的user_groups系统指标中
"{{ lookup('ansible.builtin.file', 'groups.yml') | from_yaml }}"
编写好的task内容如下:
- name: load group information
ansible.builtin.set_fact:
user_groups: "{{ lookup('ansible.builtin.file', 'groups.yml') | from_yaml }}"完成“Create groups”任务,用来创建user_groups指标中YAML数据指定的每个组
任务必须使用ansible.buildin.group模块,针对user_groups指标循环。通过 item.name 指定每次循环要创建的组的组名。编写好的task还应包括以下内容:
- name: Create groups
ansible.builtin.group:
name: "{{ item['name'] }}" # 调用 groups.yml 中的组名称(devs、ops)
state: present
loop: "{{ user_groups }}"3)完成“Create users”任务
观察users.txt文件
[student@workstation data-lookups]$ cat users.txt
user1
user2
user3使用lines插件来读取users.txt文件中的用户信息:
"{{ query('ansible.builtin.lines', 'cat users.txt') }}"
lines插件将cat users.txt命令的输出结果作为独立的一行,而query的功能确保这个数据是一个列表。配置这个task根据用户信息执行loop循环操作。
- name: Create users
ansible.builtin.debug:
msg: "To be done"
loop: "{{ query('ansible.builtin.lines', 'cat users.txt') }}"创建用户时,也要创建一个随机密码。password插件用来生成随机密码,并可选择将密码保存到本地文件中。上一步骤根据来自users.txt文件的用户名列表上添加了一个循环;你可以使用相同的item变量为每个用户生成关联的文件。
ansible.builtin.password lookup插件的完整参数格式是:"文件路径 + 空格 + 参数键值对"
格式:lookup('ansible.builtin.password', '文件路径 参数1=值1 参数2=值2')
"{{ lookup('ansible.builtin.password', 'credentials/' + item + ' length=9') }}"
注意:将密码存储到任务变量中,确保在“length=9”参数的第一个单引号后面包含空格。
使用空格将路径credentials/{{ item }}和参数length=9明确分开。没有空格时,Ansible会认为整个字符串是路径。路径=credentials/{{ item }},参数=length=9
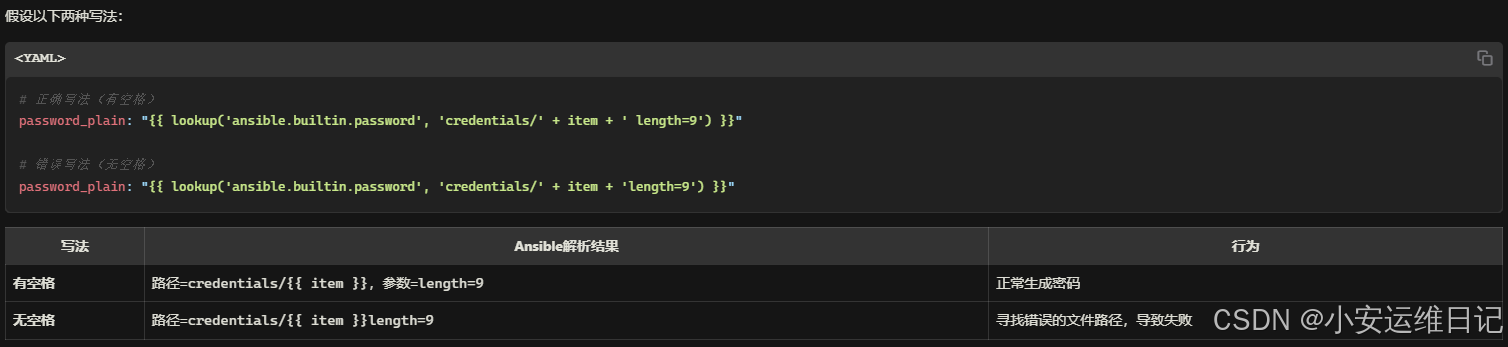
现在,任务应该包括以下内容:
- name: Create users
vars:
password_plain: "{{ lookup('ansible.builtin.password', 'credentials/' + item + ' length=9') }}"
ansible.builtin.debug:
msg: "To be done"
loop: "{{ query('ansible.builtin.lines', 'cat users.txt') }}"使用ansible.builtin.user模块替换掉ansible.builtin.debug模块,新的密码需要hash处理后才能使用,还需要设置update_password: on_create来实现只在创建新的用户时更新密码(对已有的用户无需更新密码,也避免在剧本重复运行时再次更新密码)。
- name: Create users
vars:
password_plain: "{{ lookup('ansible.builtin.password', 'credentials/' + item + ' length=9') }}"
ansible.builtin.user:
name: "{{ item }}"
password: "{{ password_plain | password_hash('sha512') }}"
update_password: on_create
state: present
loop: "{{ query('ansible.builtin.lines', 'cat users.txt') }}"最后一个任务使用 subelements过滤器 来把用户添加到附加组,无需使用查询插件。确认修改后的剧本包含以下内容:
- name: Populate users and groups
hosts: all
gather_facts: false
tasks:
- name: load group information
ansible.builtin.set_fact:
user_groups: "{{ lookup('ansible.builtin.file', 'groups.yml') | from_yaml }}"
- name: Create groups
ansible.builtin.group:
name: "{{ item['name'] }}"
state: present
loop: "{{ user_groups }}"
- name: Create users
vars:
password_plain: "{{ lookup('ansible.builtin.password', 'credentials/' + item + ' length=9') }}"
ansible.builtin.user:
name: "{{ item }}"
password: "{{ password_plain | password_hash('sha512') }}"
update_password: on_create
state: present
loop: "{{ query('ansible.builtin.lines', 'cat users.txt') }}"
- name: Add users to groups
ansible.builtin.user:
name: '{{ item[1] }}'
groups: "{{ item[0]['name'] }}"
append: true
loop: "{{ user_groups | subeletments('members', 'skip_missing=true') }}"4)运行剧本,确认用户、组和组成员都能正确配置
使用ansible-navigator run命令来运行剧本:
[student@workstation data-lookups]$ ansible-navigator run -m stdout site.yml
PLAY [PopuNate users and groups] ***********************************************
TASK [load group information] **************************************************
ok: [serverf.lab.example.com]
TASK [Create groups] ***********************************************************
changed: [serverf.lab.example.com] => (item={'name': 'devs', 'members': ['user1','user2']})
changed: [serverf.lab.example.com] => (item={'name': 'ops', 'members': ['user3']})
TASK [Create users] ************************************************************
changed: [serverf.lab.example.com] => (item=user1)
changed: [serverf.lab.example.com] => (item=user2)
changed: [serverf.lab.example.com] => (item=user3)
TASK [Add users to groups] *****************************************************
changed: [serverf.lab.example.com] => (item=[{'name': 'devs', 'members': ['user1','user2']}, 'user1'])
changed: [serverf.lab.example.com] => (item=[{'name': 'devs', 'members': ['user1', 'user2']}, 'user2'])
changed: [serverf.lab.example.com] => (item=[{'name': 'ops', 'members': ['user3']}, 'user3'])
PLAY RECAP *********************************************************************确认在serverf主机上创建了相应的用户:
[student@workstation data-lookups]$ ssh serverf "tail -n3 /etc/passwd"
user1:x:1002:1004::/home/user1:/bin/bash
user2:x:1003:1005::/home/user2:/bin/bash
user3:x:1004:1006::/home/user3:/bin/bash确认相关的组也已经存在,并且有正确的成员用户:
[student@workstation data-lookups]$ ssh serverf "tail -n5 /etc/group"
devs:x:1002:user1,user2
ops:x:1003:user3
user1:x:1004:
user2:x:1005:
user3:x:1006:结束练习(清理环境):
在workstation虚拟机上,切换到student用户主目录,使用lab命令来清理案例环境,确保先前练习的资源不会影响后续的练习。
[student@workstation ~]$ lab finish data-lookups三、 实现高级循环
1. loop循环与lookup查询插件
使用 loop循环语句可以针对平展的列表项实现循环操作,从而简化Ansible剧本。与lookup查询插件一起使用时,可以为循环构建更复杂的列表数据。
在Ansible 2.5版本之前,迭代任务是通过使用以with_开头、以查询插件名称结尾的关键字来实现的。对于简单的列表项,等效于循环的是with_list用法。对于Ansible 2.5及之后的版本,使用loop是最简单的方法。
例如,以下三种语法具有相同的结果(首选第一种):
- name: using loop
ansible.builtin.debug:
msg: "{{ item }}"
loop: "{{ mylist }}"
- name: using with_list
ansible.builtin.debug:
msg: "{{ item }}"
with_list: "{{ mylist }}"
- name: using lookup plugin
ansible.builtin.debug:
msg: "{{ item }}"
loop: "{{ lookup('ansible.builtin.list', mylist) }}"通过搭配查询插件和过滤器的适当组合,可以重构with_*迭代任务以使用loop循环。
使用loop关键字代替with_*循环有以下好处:
-
不用记忆或找到某个with_*风格的关键字,而是使用插件和过滤器来按需调整任务
-
重点学习Ansible中可用的插件和过滤器,它们具有更广泛的适用性
-
使用 ansible-navigator doc --mode stdout -t lookup -l 命令,可以访问查询插件的文档,方便查找合适的插件,有助于设计和使用合适的场景
2. 迭代场景示例
下面这些例子展示了使用Jinja2表达式、过滤器、lookup查询插件和with_*语法构建更复杂循环的一些方法。
1)处理列表的列表
with_items关键字提供了一种迭代复杂列表的方法。例如,假定一个剧本设置了如下任务:
- name: Remove build files
ansible.builtin.file:
path: "{{ item }}"
state: absent
with_items:
- "{{ app_a_tmp_files }}"
- "{{ app_b_tmp_files }}"
- "{{ app_c_tmp_files }}"其中 app_a_tmp_files、app_b_tmp_file和app_c_tmp_files变量都包含一个临时文件列表,通过使用with_items关键字将这三个列表组合为一个列表(列表的成员也是列表),它会自动对列表执行一级展平。
若要重构with_items任务以使用loop关键字,请使用flatten扁平化过滤器。flatten过滤器会递归搜索嵌入的列表项,使用找到的所有值创建单个列表。
flatten过滤器接受levels参数,用来指定搜索嵌入列表的数字级别。比如levels=1参数指定只在初始列表中搜索一层,这与with_items默认的一级扁平化相同。
若要重构with_items任务以使用loop关键字,还必须使用 flatten(levels=1) 过滤器:
- name: Remove build files
ansible.builtin.file:
path: "{{ item }}"
state: absent
loop: "{{ list_of_lists | flatten(levels=1) }}"
vars:
list_of_lists:
- "{{ app_a_tmp_files }}"
- "{{ app_b_tmp_files }}"
- "{{ app_c_tmp_files }}"注意,因为loop语句不执行这种隐含的一级扁平化,所以它不完全等同于with_items。但是,如果传递给循环的列表只是一个简单的列表,那么loop和with_items是相同的。只在要使用嵌套列表时,这种区别才重要。
2)处理嵌套的列表
来自变量文件、Ansible系统指标和外部服务的数据通常是由结构化数据(如列表和字典)组成的。看看下面这个例子中的users变量:
users:
- name: paul
password: "{{ paul_pass }}"
authorized:
- keys/paul_key1.pub
- keys/paul_key2.pub
mysql:
hosts:
- "%"
- "127.0.0.1"
- "::1"
- "localhost"
groups:
- wheel
- name: john
password: "{{ john_pass }}"
authorized:
- keys/john_key.pub
mysql:
password: other-mysql-password
hosts:
- "utility"
groups:
- wheel
- devopsusers变量是一个列表,列表中的每个条目都是一个字典,其中包含name、password、authorized、mysql和groups这些键。其中name和password键使用简单的字符串值,而authorized和groups使用列表值。mysql键引用另一个字典,其中包含每个用户的mysql相关元数据。
subelements子元素过滤器可以从具有嵌套列表的列表中创建单个列表。这个过滤器主要处理字典列表,每个字典都包含一个引用列表的键。若要使用subelements过滤器,必须提供与列表相对应的每个字典上的键的名称。
例如,原始列表{{ users }},有一个成员:
users:
- name: zhsan
city:
- beijing
- shanghai转换后的 {{ users | subelements('city')}},有2个成员(因为选定的city子元素在原始列表中有2个项):
-
- name: zhsan
city:
- beijing
- shanghai
- beijing
-
- name: zhsan
city:
- beijing
- shanghai
- shanghai在 subelements过滤器 创建的新列表中,每个项目本身是一个双元素列表。第一个元素是对原始users变量中每个用户的引用;第二个元素是所选择子元素项city的列表中的单个条目的引用。
为了进行说明,可再次考虑前面的users变量定义。subelements过滤器允许对变量中定义的所有用户及其授权密钥文件进行迭代:
- name: Set authorized ssh key
ansible.posix.authorized_key:
user: "{{ item[0]['name'] }}"
key: "{{ lookup('ansible.builtin.file', item[1]) }}"
loop: "{{ users | subelements('authorized') }}"subelements过滤器 根据users变量的数据创建一个新列表,这个新列表中的每个成员项目都包含两个元素,其中第一个元素包含对每个用户的引用;第二个元素包含对该用户列表中每个授权文件条目的引用所以会变成3条数据。
-
- name: paul
password: "{{ paul_pass }}"
authorized:
- keys/paul_key1.pub
- keys/paul_key2.pub
mysql:
hosts:
- "%"
- "127.0.0.1"
- "::1"
- "localhost"
groups:
- wheel
- keys/paul_key1.pub
-
- name: paul
password: "{{ paul_pass }}"
authorized:
- keys/paul_key1.pub
- keys/paul_key2.pub
mysql:
hosts:
- "%"
- "127.0.0.1"
- "::1"
- "localhost"
groups:
- wheel
- keys/paul_key2.pub
-
- name: john
password: "{{ john_pass }}"
authorized:
- keys/john_key.pub
mysql:
password: other-mysql-password
hosts:
- "utility"
groups:
- wheel
- devops
- keys/john_key.pub3)处理字典
被组织为一组键值对的数据,在Ansible社区中通常被称为字典,而不是被组织为列表。例如,以下users变量的定义:
users:
demo1:
name: Demo User 1
mail: demo1@example.com
demo2:
name: Demo User 2
mail: demo2@example.com
...output omitted...
demo200:
name: Demo User 200
mail: demo200@example.com在Ansible 2.5之前,必须使用with_dict关键字才能迭代该字典的键值对。对于每个迭代,item变量都有两个属性:key和value。key属性包含其中一个字典键的值,value属性包含与字典键关联的数据:
- name: Iterate over Users
ansible.builtin.user:
name: "{{ item['key'] }}"
comment: "{{ item['value']['name'] }}"
state: present
with_dict: "{{ users }}"或者,可以使用dict2items过滤器将字典转换为列表,这可能更容易理解。下面这个列表中的项目的结构与with_dict关键字生成的项目相同:(loop循环不能直接使用字典)
- name: Iterate over Users
ansible.builtin.user:
name: "{{ item['key'] }}"
comment: "{{ item['value']['name'] }}"
state: present
loop: "{{ users | dict2items }}"4)按通配符匹配文件(获取文件清单)
可以构造一个循环来处理由fileglob查找插件提供的文件列表(可使用通配符提供)。例如,下面这个剧本:
- name: Test
hosts: localhost
gather_facts: false
tasks:
- name: Test fileglob lookup plugin
ansible.builtin.debug:
msg: "{{ lookup('ansible.builtin.fileglob', '~/.bash*') }}"上面的fileglob查询插件的输出结果是一个逗号分隔的文件字符串,通过双引号括起来提供给msg变量输出。
PLAY [Test] ******************************************************************
TASK [Test fileglob lookup plugin] *******************************************
ok: [localhost] => {
"msg": "/home/student/.bash_logout,/home/student/.bash_profile,/home/student/.bashrc,/home/student/.bash_history"
}
PLAY RECAP *******************************************************************
localhost : ok=1 changed=0 unreachable=0 failed=0 ...若要使lookup查询插件返回值的列表而不是值组合成的字符串,请使用query关键字而不是lookup关键字。上一个剧本示例可以修改如下:
- name: Test
hosts: localhost
gather_facts: false
tasks:
- name: Test fileglob lookup plugin
ansible.builtin.debug:
msg: "{{ query('fileglob', '~/.bash*') }}"修改后的剧本的输出可表明msg关键字引用了一个文件列表,因为数据被括在括号中:
PLAY [Test] ******************************************************************
TASK [Test fileglob lookup plugin] *******************************************
ok: [localhost] => {
"msg": [
"/home/student/.bash_logout",
"/home/student/.bash_profile",
"/home/student/.bashrc",
"/home/student/.bash_history"
]
}
PLAY RECAP *******************************************************************
localhost : ok=1 changed=0 unreachable=0 failed=0 ...要在循环中使用由lookup或query查找插件的数据,请确保处理后的数据是一个列表(而不只是字符串)。以下剧本中的两个任务都针对由通配符~/.bash*匹配的文件进行迭代:
- name: Both tasks have the same result
hosts: localhost
gather_facts: false
tasks:
- name: Iteration Option One
ansible.builtin.debug:
msg: "{{ item }}"
loop: "{{ query('fileglob', '~/.bash*') }}"
- name: Iteration Option Two
ansible.builtin.debug:
msg: "{{ item }}"
with_fileglob: "~/.bash*"前面这种情况下,首选with_fileglob任务,因为它更简洁。
5)任务重试
通常情况下,一个play在满足你指定的条件一直被运行,使用until指令可以实现这种场景下的循环。例如,在blue-green蓝绿部署场景下(蓝色阶段为开发、测试阶段,绿色阶段为试行阶段),必须等到blue主机的状态良好后,才能在green主机上继续部署。
- name: Perform smoke test
ansible.builtin.uri:
url: "https://{{ blue }}/status"
return_content: true
register: smoke_test
until: "'STATUS_OK' in smoke_test['content']"
retries: 12
delay: 10每10秒查询一次blue这台web服务器的状态页面,如果没有查询成功,则在尝试12次后任务失败。
3. 课堂练习:实现高级循环
开始练习(部署环境):
以用户student登入workstation虚拟机,使用lab命令来构建案例环境。
[student@workstation ~]$ lab start data-loops步骤说明:
1)使用带dict2items过滤器的循环将rgroups变量转换成列表
查看~/data-loops/group_vars/all/my_vars.yml文件中定义的rgroups变量:
[student@workstation ~]$ cat ~/data-loops/group_vars/all/my_vars.yml
### Group variables ###
rgroups:
accounts:
name: accounts
gid: 7001
development:
name: development
gid: 7002
...output omitted...在这个结构中(rgroups变量字典,嵌套字典,再嵌套字典)
-
rgroups 变量是一个字典
-
字典中的每一个key代表一个组的名称,而对应这个键的value是包含这个组的元数据的另一个字典
-
每个组的元数据包括两个键:name和gid
查看 ~/data-loops/add-groups.yml 剧本,这个剧本为受管主机添加一个组账号:
[student@workstation ~]$ cat ~/data-loops/add-groups.yml
- name: First task
hosts: servera.lab.example.com
gather_facts: false
become: true
tasks:
- name: Add groups
ansible.builtin.group:
name: accounts
gid: 7001
state: present修改这个剧本,使用loop与dict2items过滤器一起实现循环操作,就像这样:
[student@workstation data-lookups]$ vim ~/data-loops/add-groups.yml
---
- name: First task
hosts: servera.lab.example.com
gather_facts: false
become: true
tasks:
- name: Add groups
ansible.builtin.group:
name: "{{ item['key'] }}"
gid: "{{ item['value']['gid'] }}"
state: present
loop: "{{ rgroups | dict2items }}"运行add-groups.yml剧本来添加组账号:
[student@workstation ~]$ cd ~/data-loops/
[student@workstation data-loops]$ ansible-navigator run -m stdout add-groups.yml
PLAY [First task] **************************************************************
TASK [Add groups] **************************************************************
changed: [servera.lab.example.com] => (item={'key': 'accounts', 'value': {'name': 'accounts', 'gid': 7001}})
changed: [servera.lab.example.com] => (item={'key': 'development', 'value': {'name': 'development', 'gid': 7002}})
changed: [servera.lab.example.com] => (item={'key': 'manufacturing', 'value': {'name': 'manufacturing', 'gid': 7003}})
changed: [servera.lab.example.com] => (item={'key': 'marketing', 'value': {'name': 'marketing', 'gid': 7004}})
PLAY RECAP *********************************************************************
servera.lab.example.com : ok=1 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=02)使用带subelements过滤器的嵌套循环将my_users和my_groups转换成列表
查看~/data-loops/group_vars/all/my_vars.yml文件中定义的my_users变量:
[student@workstation ~]$ cat ~/data-loops/group_vars/all/my_vars.yml
### User variables ###
my_users:
john:
name: john
my_groups:
- accounts
- development
jane:
name: jane
my_groups:
- manufacturing
- marketing
...output omitted...在这个结构中(my_users变量字典,嵌套字典,再嵌套字典,再嵌套列表)
-
my_users变量是一个字典
-
字典中的每一个键本身也是一个字典,包含name和my_groups
-
my_groups键指向一个组的列表。例如,用户john是account组和development组的成员
-
-
查看~/data-loops/add-users.yml剧本,这个剧本添加一个用户账号并将其加入到正确的组:
[student@workstation ~]$ cat ~/data-loops/add-users.yml
- name: Second task
hosts: servera.lab.example.com
gather_facts: false
become: true
tasks:
- name: Add users and put them in the right groups
ansible.builtin.user:
name: john
append: true
groups: accounts
state: present修改这个剧本,使用loop与subelements过滤器一起实现循环操作,就像这样:
[student@workstation data-loops]$ vim ~/data-loops/add-users.yml
- name: Second task
hosts: servera.lab.example.com
gather_facts: false
become: true
tasks:
- name: Add users and put them in the right groups
ansible.builtin.user:
name: "{{ item[0]['name'] }}"
append: true
groups: "{{ item[1] }}"
state: present
loop: "{{ my_users | subelements('my_groups') }}"运行add-users.yml剧本来添加用户账号:
[student@workstation data-loops]$ ansible-navigator run -m stdout add-users.yml
PLAY [Second task] *************************************************************
TASK [Add users and put them in the right groups] ******************************
changed: [servera.lab.example.com] => (item=[{'name': 'john', 'my_groups': ['accounts', 'development']}, 'accounts'])
changed: [servera.lab.example.com] => (item=[{'name': 'john', 'my_groups': ['accounts', 'development']}, 'development'])
changed: [servera.lab.example.com] => (item=[{'name': 'jane', 'my_groups': ['manufacturing', 'marketing']}, 'manufacturing'])
changed: [servera.lab.example.com] => (item=[{'name': 'jane', 'my_groups': ['manufacturing', 'marketing']}, 'marketing'])
changed: [servera.lab.example.com] => (item=[{'name': 'tom', 'my_groups': ['accounts', 'marketing']}, 'accounts'])
changed: [servera.lab.example.com] => (item=[{'name': 'tom', 'my_groups': ['accounts', 'marketing']}, 'marketing'])
changed: [servera.lab.example.com] => (item=[{'name': 'lisa', 'my_groups': ['development', 'manufacturing']}, 'development'])
changed: [servera.lab.example.com] => (item=[{'name': 'lisa', 'my_groups': ['development', 'manufacturing']}, 'manufacturing'])
PLAY RECAP *********************************************************************
servera.lab.example.com : ok=1 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=03)针对group_vars/all/my_vars.yml文件中定义的public_keys_lists变量使用循环。使用map过滤器、flatten过滤器,生成一个用于所有开发人员SSH公钥文件的简单列表(方便这些用户远程SSH免密登录)。修改任务的key关键字以包含每个迭代项的文件内容
查看~/data-loops/group_vars/all/my_vars.yml文件中定义的public_keys_lists变量:
[student@workstation ~]$ cat ~/data-loops/group_vars/all/my_vars.yml
### Public key variables ###
public_key_lists:
- username: john
public_keys:
- pubkeys/john/id_rsa.pub
- pubkeys/john/laptop_rsa.pub
- username: jane
public_keys:
- pubkeys/jane/id_rsa.pub
...output omitted...在这个结构中(public_key_lists变量字典,嵌套列表,列表嵌套字典,字典嵌套列表)
-
public_key_lists变量是一个字典
-
列表中的每个条目都是一个包含public_keys和username的字典
-
public_keys键指向给定用户的公钥文件列表。例如,johnd用户有两个公钥文件:pubkeys/johnd/id_rsa.pub和pubkeys/johnd/laptop_rsa.pub。文件名的路径相对于剧本所在的目录
查看~/data-loops/add-keys.yml剧本,这个剧本为用户developer配置公钥:
[student@workstation ~]$ cat ~/data-loops/add-keys.yml
- name: Third task
hosts: servera.lab.example.com
gather_facts: false
become: true
tasks:
- name: Set up authorized keys
ansible.posix.authorized_key:
user: developer
state: present
key: pubkeys/john/id_rsa.pub修改这个剧本来执行以下任务:
-
在末尾添加一个map过滤器以提取public_keys属性。它创建一个列表的列表;列表中的每个条目都是某个特定用户的SSH公钥文件的列表
-
在map过滤器之后添加一个flatten过滤器,以创建一个展平的文件列表
-
使用file查询插件,读取每个迭代项的文件内容,配置给key参数
add-keys.yml剧本应包括以下内容:
[student@workstation data-loops]$ vim ~/data-loops/add-keys.yml
- name: Third task
hosts: servera.lab.example.com
gather_facts: false
become: true
tasks:
- name: Set up authorized keys
ansible.posix.authorized_key:
user: developer
state: present
key: "{{ lookup('ansible.builtin.file', item) }}"
loop: "{{ public_key_lists | map(attribute='public_keys') | flatten }}"4)安装ansible.posix集合,因为ansible.posix.authorized_key模块需要此集合
在workstaton主机上,从浏览器访问hub.lab.example.com。用户名student、密码redhat123。导航到 Collections > API token,然后单击load Token。将令牌复制并粘贴到~/data-loops/ansible.cfg文件末尾的token变量中。安装集合。
[student@workstation data-loops]$ vim ansible.cfg
token=11a7e652f253870377c7ddaba61e1d08141c0232
[student@workstation data-loops]$ ansible-galaxy collection install -r collections/requirements.yml -p collections/5)运行add-keys.yml剧本来添加密钥
[student@workstation data-loops]$ ansible-navigator run -m stdout add-keys.yml
PLAY [Third task] **************************************************************
TASK [Set up authorized keys] **************************************************
changed: [servera.lab.example.com] => (item=pubkeys/john/id_rsa.pub)
changed: [servera.lab.example.com] => (item=pubkeys/john/laptop_rsa.pub)
changed: [servera.lab.example.com] => (item=pubkeys/jane/id_rsa.pub)
changed: [servera.lab.example.com] => (item=pubkeys/tom/id_rsa.pub)
changed: [servera.lab.example.com] => (item=pubkeys/lisa/id_rsa.pub)
PLAY RECAP *********************************************************************
servera.lab.example.com : ok=1 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0结束练习(清理环境):
在workstation虚拟机上,切换到student用户主目录,使用lab命令来清理案例环境,确保先前练习的资源不会影响后续的练习。
[student@workstation ~]$ lab finish data-loops四、 使用过滤器处理网络地址
1. 收集和处理网络信息
需要为受管主机配置网络设备时,有很多种过滤器和查询插件可以用来收集系统指标,以及针对收集的网络信息做必要的处理。默认情况下,在剧本任务开始时会由标准的setup模块自动从受管主机收集各种系统指标。
ansible_facts['interfaces']指标是系统上所有网络接口名称的列表。可以使用此列表检查系统上每个网络接口的详细信息。例如,网卡enp11s0对应的指标为ansible_facts['enp11s0'],这是一个字典,包含MAC地址、IPv4和IPv6地址、内核模块等接口信息。
有些常用的系统指标建议记住(如表所示)
| 指标名称 | 描述 |
| ansible_facts['dns']['nameservers'] | 受管主机使用的DNS域名服务器 |
| ansible_facts['domain'] | 受管主机所在的DNS域 |
| ansible_facts['all_ipv4_addresses'] | 受管主机已配置的所有IPv4地址 |
| ansible_facts['all_ipv6_addresses'] | 受管主机已配置的所有IPv4地址 |
| ansible_facts['fqdn'] | 受管主机已配置的FQDN地址 |
| ansible_facts['hostname'] | 受管主机的主机名 |
下面这个剧本展示了使用网络相关系统指标的示例:
---
- name: Set up web servers
hosts: web_servers
become: true
tasks:
- name: Configure web server status page
ansible.builtin.copy:
content: "Server: {{ ansible_facts['fqdn'] }} at {{ ansible_facts['default_ipv4']['address'] }}"
dest: /var/www/html/status.html
owner: apache
group: apache
mode: '0444'
- name: Ensure httpd is installed
ansible.builtin.yum:
name: httpd
state: installed
- name: Start and enable webserver
ansible.builtin.service:
name: httpd
state: started
enabled: true
- name: Notify root of server provisioning
community.general.mail:
subject: >
System {{ ansible_facts['hostname'] }} has been successfully provisioned.2. 网络信息过滤器
使用ansible.utils.ipaddr过滤器可以验证及操作存储在变量和系统指标中的相关网络数据。例如检查IP地址的语法、筛选出错误的地址、从VLSM子网掩码转换为CIDR子网前缀表示、执行子网计算,或者查找网络中的下一个可用地址。
1)校验IP地址
在最简单的用法中,不带参数的 ansible.utils.ipaddr 过滤器只接受一个值。
-
如果提供的值是一个IP地址,则返回这个IP地址;
-
如果这个值不是IP地址,则会返回false;
-
如果这个值是一个列表,则返回其中有效的IP地址,而不是无效的IP地址。
-
如果所有项目都无效,则将返回一个空列表。
{{ my_hosts_list | ansible.utils.ipaddr }}
还可以向ansible.utils.ipaddr过滤器提供参数,以便根据输入的数据来返回不同的结果。
2)过滤数据
下面是一些使用ansible.utils.ipaddr过滤器的示例。
- name: Filter example
ansible.builtin.debug:
msg: "{{ listips | ansible.utils.ipaddr }}"示例中用到的listips变量包含以下列表:
listips:
- 192.168.2.1
- 10.0.0.128/25
- 172.24.10.0/255.255.255.0
- 172.24.10.0/255.255.255.255
- ff02::1
- ::1
- 2001::1/64
- 2001::/64
- www.redhat.com-
netmask:msg中的ipaddr过滤器请替换为具体的地址选项表达式。例如,以下用法会检索出给定地址的网络掩码(netmask):
msg: "{{ listips | ansible.utils.ipaddr('netmask') }}"-
host:只提取有效的单个的IP地址,带有正确的CIDR前缀:
msg: "{{ listips | ansible.utils.ipaddr('host') }}"
"msg": [
"192.168.2.1/32",
"172.24.10.0/32",
"ff02::1/128",
"::1/128",
"2001::1/64"
]-
net:只提取有效的网络地址,必要时将网络掩码转换为CIDR前缀:
msg: "{{ listips | ansible.utils.ipaddr('net') }}"
"msg": [
"10.0.0.128/25",
"172.24.10.0/24",
"2001::/64"
]-
private:只提取有效的私有地址,包括RFC 1918地址空间和IPv6站点本地地址:
msg: "{{ listips | ansible.utils.ipaddr('private') }}"
"msg": [
"192.168.2.1",
"10.0.0.128/25",
"172.24.10.0/255.255.255.0",
"172.24.10.0/255.255.255.255"
]-
public:只提取有效的公有地址,本示例中没有有效的IPv4公网地址:
msg: "{{ listips | ansible.utils.ipaddr('public') }}"
"msg": [
"2001::1/64",
"2001::/64"
]ansible.utils.ipwrap过滤器用来为看似IPv6地址的地址部分加上方括号,其他值保持不变。这对于某些要求IPv6地址语法的配置文件的模板非常有用。
msg: "{{ listips | ansible.utils.ipwrap }}"
"msg": [
"192.168.2.1",
"10.0.0.128/25",
"172.24.10.0/255.255.255.0",
"172.24.10.0/255.255.255.255",
"[ff02::1]",
"[::1]",
"[2001::1]/64",
"[2001::]/64",
"www.redhat.com"
]3)处理IP地址
可以使用多种ansible.utils.ipaddr选项来格式化IPv4或IPv6地址的网络信息。
以下是一些例子:
-
获取IP地址部分,192.0.2.1:
"{{ '192.0.2.1/24' | ansible.utils.ipaddr('address') }}"
-
获取变长子网掩码, 255.255.255.0:
"{{ '192.0.2.1/24' | ansible.utils.ipaddr('netmask') }}"
-
获取CIDR前缀,24:
"{{ '192.0.2.1/24' | ansible.utils.ipaddr('prefix') }}"
-
获取一个网络的广播地址,192.0.2.255:
"{{ '192.0.2.1/24' | ansible.utils.ipaddr('broadcast') }}"
-
获取一个网络的网络地址,192.0.2.0:
"{{ '192.0.2.1/24' | ansible.utils.ipaddr('network') }}"
-
获取一个IP地址的反向DNS解析记录,1.2.0.192.in-addr.arpa.:
"{{ '192.0.2.1/24' | ansible.utils.ipaddr('revdns') }}"
当你将一个项目列表传递给ansible.utils.ipaddr过滤器时,它会尝试转换看起来是有效地址的项目,并过滤掉不是有效地址的项目。
注意,上面这些选项中,broadcast选项不要用在IPv6地址上,因为IPv6协议不分配广播地址。其他的选项应该对IPv6地址也一样适用。
4)重新格式化或计算网络信息
-
通过向ansible.utils.ipaddr过滤器传递一个整数,可以显示给定网络上的IP地址。以下内容返回192.0.2.0/24网络上的第五个地址(192.0.2.5/24)。
"{{ '192.0.2.0/24' | ansible.utils.ipaddr(5) }}"
-
使用range_usable选项可计算可用的主机地址范围。以下示例返回192.0.2.1-192.0.2.254:
"{{ '192.0.2.0/24' | ansible.utils.ipaddr('range_usable') }}"
-
使用 next_usable选项可以在网络上找到下一个主机地址。以下示例返回192.0.2.6/24住址:
"{{ '192.0.2.5/24' | ansible.utils.ipaddr('next_usable') }}"
如果已经到达网络的末端时,它会返回一个空值。
如果提供一个网络地址给ansible.utils.network_in_usable过滤器,则可以指定一个特定的IP地址作为选项,用来判断这个地址在这个网络中是否是可用的主机地址(而不是广播地址等)。以下示例返回布尔值true:
"{{ '192.0.2.0/24' | ansible.utils.network_in_usable('192.0.2.5') }}"
如果将192.0.2.5替换为192.0.2.255(保留的广播地址)或192.0.3.2(不在这个网络上),则返回布尔值false。
还可使用 ansible.utils.cidr_merge 过滤器将子网和单个主机的列表聚合为最小表示形式。例如,针对这个列表:
mynetworks:
- 10.0.1.0/24
- 10.0.2.0/24
- 10.0.3.0/24
- 10.0.100.0/24
- 2001:db8::/64
- 2001:db8:0:1::/64可以使用 "{{ mynetworks | ansible.utils.cidr_merge }}" 表达式来返回下面的结果:
"msg": [
"10.0.1.0/24",
"10.0.2.0/23",
"10.0.100.0/24",
"2001:db8::/63"
]ansible.utils集合中还提供了更多的过滤器,以及前面这些过滤器的更多选项。
有关ansible.utils.ipaddr过滤器的更多信息,请参阅详细文档:
https://docs.ansible.com/ansible/6/collections/ansible/utils/docsite/filters_ipaddr.html
3. 课堂练习:使用过滤器处理网络地址
开始练习(部署环境):
以用户student登入workstation虚拟机,使用lab命令来构建案例环境。
[student@workstation ~]$ lab start data-netfilters步骤说明:
1)lab命令提供了/home/student/data-netfilters/default_ipv4.yml剧本,
进入~/data-netfilters目录,查看default_ipv4.yml剧本:
[student@workstation ~]$ cd ~/data-netfilters/
[student@workstation data-netfilters]$ cat default_ipv4.yml
- name: Display the default ipv4 address facts
hosts: servera.lab.example.com
become: false
tasks:
- name: Print the default ipv4 address facts
ansible.builtin.debug:
msg: "{{ ansible_default_ipv4 }}"运行~/data-netfilters/default_ipv4.yml剧本来列出ansible_default_ipv4系统指标:
[student@workstation data-netfilters]$ ansible-navigator run -m stdout default_ipv4.yml
PLAY [Display the default ipv4 address facts] **********************************
TASK [Gathering Facts] *********************************************************
ok: [servera.lab.example.com]
TASK [Print the default ipv4 address facts] ************************************
ok: [servera.lab.example.com] => {
"msg": {
"address": "172.25.250.10",
"alias": "eth0",
"broadcast": "172.25.250.255",
"gateway": "172.25.250.254",
"interface": "eth0",
"macaddress": "52:54:00:00:fa:0a",
"mtu": 1500,
"netmask": "255.255.255.0",
"network": "172.25.250.0",
"prefix": "24",
"type": "ether"
}
}
PLAY RECAP *********************************************************************
servera.lab.example.com : ok=2 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=02)~/data-netfilters/filtering_data.yml文件包含有不完整的任务,这些任务使用带有各种选项的ansible.utils.ipaddr过滤器,编辑此文件,将系统指标定义中出现的任何#FIXME#替换为预期值
示例listips变量包含以下列表:
[student@workstation data-netfilters]$ cat ~/data-netfilters/filtering_data.yml
listips:
- 192.168.2.1
- 10.0.0.128/25
- 172.24.10.0/255.255.255.0
- 172.24.10.0/255.255.255.255
- ff02::1
- ::1
- 2001::1/64
- 2001::/64
- www.redhat.com第一个示例使用ansible.utils.ipaddr,但没有任何选项来输出列表中的有效IP地址或网络项。此任务无需更改。
- name: 1) Display all addresses
ansible.builtin.debug:
msg: "{{ listips | ansible.utils.ipaddr }}"使用host选项来提取有效的IP地址(标注正确的CIDR前缀):
- name: 2) Use host
ansible.builtin.debug:
msg: "{{ listips | ansible.utils.ipaddr('host') }}"使用net选项来提取有效的网络地址:
- name: 3) Use net
ansible.builtin.debug:
msg: "{{ listips | ansible.utils.ipaddr('net') }}"使用private选项来提取有效的私有地址:
- name: 4) Use private
ansible.builtin.debug:
msg: "{{ listips | ansible.utils.ipaddr('private') }}"使用public选项来提取有效的公有地址:
- name: 5) Use public
ansible.builtin.debug:
msg: "{{ listips | ansible.utils.ipaddr('public') }}"使用ansible.utils.ipwrap过滤器来为IPv6地址添加方括号:
- name: 6) Use ipwrap
ansible.builtin.debug:
msg: "{{ listips | ansible.utils.ipwrap }}"除了ansible.utils.ipwrap以外,上面的大多数过滤器都去掉了www.redhat.com这一条,因为这个列表项不是IP地址。以下示例先使用ansible.utils.ipaddr过滤器,再使用ansible_utils.ipwrap过滤器,这样可以排除www.redhat.com条目。
- name: 7) Use ipaddr and ipwrap
ansible.builtin.debug:
msg: "{{ listips | ansible.utils.ipaddr | ansible.utils.ipwrap }}"检查确认,已完成的filtering_data.yml剧本包含如下内容:
[student@workstation data-netfilters]$ vim ~/data-netfilters/filtering_data.yml
# Complete each task by setting the fact as the expected value.
# Replace FIXME by the appropriate filter usage.
- name: First play for netfilter exercise
hosts: servera.lab.example.com
become: false
vars:
listips:
- 192.168.2.1
- 10.0.0.128/25
- 172.24.10.0/255.255.255.0
- 172.24.10.0/255.255.255.255
- ff02::1
- ::1
- 2001::1/64
- 2001::/64
- www.redhat.com
tasks:
- name: 1) Display all addresses
ansible.builtin.debug:
msg: "{{ listips | ansible.utils.ipaddr }}"
- name: 2) Use host
ansible.builtin.debug:
msg: "{{ listips | ansible.utils.ipaddr('host') }}"
- name: 3) Use net
ansible.builtin.debug:
msg: "{{ listips | ansible.utils.ipaddr('net') }}"
- name: 4) Use private
ansible.builtin.debug:
msg: "{{ listips | ansible.utils.ipaddr('private') }}"
- name: 5) Use public
ansible.builtin.debug:
msg: "{{ listips | ansible.utils.ipaddr('public') }}"
- name: 6) Use ipwrap
ansible.builtin.debug:
msg: "{{ listips | ansible.utils.ipwrap }}"
- name: 7) Use ipaddr and ipwrap
ansible.builtin.debug:
msg: "{{ listips | ansible.utils.ipaddr | ansible.utils.ipwrap }}"运行filtering_data.yml剧本,确认任务输出结果:
[student@workstation data-netfilters]$ ansible-navigator run -m stdout filtering_data.yml
PLAY [First play for netfilter exercise] ***************************************
TASK [Gathering Facts] *********************************************************
ok: [servera.lab.example.com]
TASK [1) Display all addresses] ************************************************
ok: [servera.lab.example.com] => {
"msg": [
"192.168.2.1",
"10.0.0.128/25",
"172.24.10.0/24",
"172.24.10.0/32",
"ff02::1",
"::1",
"2001::1/64",
"2001::/64"
]
}
TASK [2) Use host] *************************************************************
ok: [servera.lab.example.com] => {
"msg": [
"192.168.2.1/32",
"172.24.10.0/32",
"ff02::1/128",
"::1/128",
"2001::1/64"
]
}
TASK [3) Use net] **************************************************************
ok: [servera.lab.example.com] => {
"msg": [
"10.0.0.128/25",
"172.24.10.0/24",
"2001::/64"
]
}
TASK [4) Use private] **********************************************************
ok: [servera.lab.example.com] => {
"msg": [
"192.168.2.1",
"10.0.0.128/25",
"172.24.10.0/255.255.255.0",
"172.24.10.0/255.255.255.255"
]
}
TASK [5) Use public] ***********************************************************
ok: [servera.lab.example.com] => {
"msg": [
"2001::1/64",
"2001::/64"
]
}
TASK [6) Use ipwrap] ***********************************************************
ok: [servera.lab.example.com] => {
"msg": [
"192.168.2.1",
"10.0.0.128/25",
"172.24.10.0/255.255.255.0",
"172.24.10.0/255.255.255.255",
"[ff02::1]",
"[::1]",
"[2001::1]/64",
"[2001::]/64",
"www.redhat.com"
]
}
TASK [7) Use ipaddr and ipwrap] ************************************************
ok: [servera.lab.example.com] => {
"msg": [
"192.168.2.1",
"10.0.0.128/25",
"172.24.10.0/24",
"172.24.10.0/32",
"[ff02::1]",
"[::1]",
"[2001::1]/64",
"[2001::]/64"
]
}
PLAY RECAP *********************************************************************
servera.lab.example.com : ok=8 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=03)也可以使用ansible-navigator来交互式地运行filtering_data.yml剧本,以单独查看这些任务的结果
[student@workstation data-netfilters]$ ansible-navigator run filtering_data.yml按0(如图-1所示)查看First play for netfilter exercise这个play的详情。

按2(如图-2所示)查看Use host这个任务的详情。
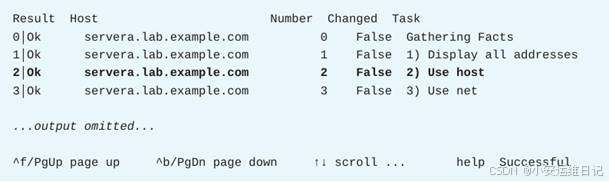
在结果中查看筛选出来的IP地址(如图-3所示)。
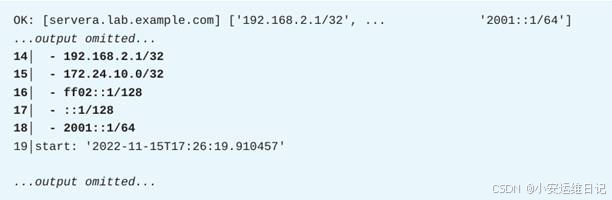
按3次Esc键退出ansible-navigator命令。
4)修改~/data-netfilters/site.yml剧本。其中第一组任务由set_fact任务组成,使用ansible.utils.ipaddr过滤器来完成;第二组任务由debug任务组成,用来输出你设置的系统指标中包含的信息
使用ansible.utils.ipadd过滤器确保ipv4_addr变量包含正确的IP地址:
- name: Set facts derived from ipv4_addr and ipv4_subnet
ansible.builtin.set_fact:
server_address: "{{ ipv4_addr | ansible.utils.ipaddr }}"使用revdns选项获取IP地址的DNS反向解析记录名称:
- name: Set facts derived from ipv4_addr and ipv4_subnet
ansible.builtin.set_fact:
server_address: "{{ ipv4_addr | ansible.utils.ipaddr }}"
ptr_record: "{{ ipv4_addr | ansible.utils.ipaddr('revdns') }}"使用network/prefix选项获取网络地址及CIDR前缀:
- name: Set facts derived from net_mask
ansible.builtin.set_fact:
cidr: "{{ net_mask | ansible.utils.ipaddr('network/prefix') }}"使用broadcast选项获取广播地址:
- name: Set facts derived from net_mask
ansible.builtin.set_fact:
cidr: "{{ net_mask | ansible.utils.ipaddr('network/prefix') }}"
broadcast: "{{ net_mask | ansible.utils.ipaddr('broadcast') }}"使用一开始设置的cidr变量,将网络及其CIDR前缀作为ansible.utils.ipaddr过滤器的选项,以便返回的列表中仅包括该网络上的IP地址。
- name: Print addresses on {{ cidr }} from this task's list
ansible.builtin.debug:
msg: "{{ item | ansible.utils.ipaddr(cidr) }}"
loop:上面这个例子中,注意cidr不要加引号,因为它是在前面定义的必须展开的变量,而不是过滤器的选项。
确认修改完成的site.yml剧本包含以下内容:
# Complete each task by setting the fact as the expected value.
# Replace FIXME by the appropriate filter usage.
# Tasks make use of the gathered fact 'default_ipv4', and its keys 'address', and 'netmask'.
- name: Second play for netfilter exercise
hosts: servera.lab.example.com
become: false
tasks:
- name: Set address and network facts
ansible.builtin.set_fact:
ipv4_addr: "{{ ansible_facts['default_ipv4']['address'] }}"
ipv4_subnet: "{{ ansible_facts['default_ipv4']['netmask'] }}"
- name: Set facts derived from ipv4_addr and ipv4_subnet
ansible.builtin.set_fact:
server_address: "{{ ipv4_addr | ansible.utils.ipaddr }}"
ptr_record: "{{ ipv4_addr | ansible.utils.ipaddr('revdns') }}"
net_mask: "{{ ipv4_addr }}/{{ ipv4_subnet }}"
- name: Set facts derived from net_mask
ansible.builtin.set_fact:
cidr: "{{ net_mask | ansible.utils.ipaddr('network/prefix') }}"
broadcast: "{{ net_mask | ansible.utils.ipaddr('broadcast') }}"
- name: Display server_address
ansible.builtin.debug:
msg: server_address is {{ server_address }}
- name: Display PTR record form for server_address
ansible.builtin.debug:
msg: ptr_record is {{ ptr_record }}
- name: Display address and netmask in VLSM notation ansible.builtin.debug:
msg: net_mask is {{ net_mask }}
- name: Display address and prefix in CIDR notation
ansible.builtin.debug:
msg: cidr is {{ cidr }}
- name: Display broadcast address for {{ cidr }}
ansible.builtin.debug:
msg: broadcast is {{ broadcast }}
- name: Print addresses on {{ cidr }} from this task's list
ansible.builtin.debug:
msg: "{{ item | ansible.utils.ipaddr(cidr) }}"
loop:
- 172.16.0.1
- 172.25.250.4
- 192.168.122.20
- 192.0.2.55运行site.yml剧本,确认输出结果:
[student@workstation data-netfilters]$ ansible-navigator run -m stdout site.yml
PLAY [Second play for netfilter exercise] **************************************
TASK [Gathering Facts] *********************************************************
ok: [servera.lab.example.com]
TASK [Set address and network facts] *******************************************
ok: [servera.lab.example.com]
TASK [Set facts derived from ipv4_addr and ipv4_subnet] ************************
ok: [servera.lab.example.com]
TASK [Set facts derived from net_mask] *****************************************
ok: [servera.lab.example.com]
TASK [Display server_address] **************************************************
ok: [servera.lab.example.com] => {
"msg": "server_address is 172.25.250.10"
}
TASK [Display PTR record form for server_address] ******************************
ok: [servera.lab.example.com] => {
"msg": "ptr_record is 10.250.25.172.in-addr.arpa."
}
TASK [Display address and netmask in VLSM notation] ****************************
ok: [servera.lab.example.com] => {
"msg": "net_mask is 172.25.250.10/255.255.255.0"
}
TASK [Display address and prefix in CIDR notation] *****************************
ok: [servera.lab.example.com] => {
"msg": "cidr is 172.25.250.0/24"
}
TASK [Display broadcast address for 172.25.250.0/24] ***************************
ok: [servera.lab.example.com] => {
"msg": "broadcast is 172.25.250.255"
}
TASK [Print addresses on 172.25.250.0/24 from this task's list] ****************
ok: [servera.lab.example.com] => (item=172.16.0.1) => {
"msg": ""
}
ok: [servera.lab.example.com] => (item=172.25.250.4) => {
"msg": "172.25.250.4"
}
ok: [servera.lab.example.com] => (item=192.168.122.20) => {
"msg": ""
}
ok: [servera.lab.example.com] => (item=192.0.2.55) => {
"msg": ""
}
PLAY RECAP *********************************************************************
servera.lab.example.com : ok=10 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0使用ansible-navigator命令以交互模式运行site.yml剧本,以便单独查看这些任务的结果:
[student@workstation data-netfilters]$ ansible-navigator run site.yml参考第3)步中的操作查看具体的结果。
结束练习(清理环境):
在workstation虚拟机上,切换到student用户主目录,使用lab命令来清理案例环境,确保先前练习的资源不会影响后续的练习。
[student@workstation ~]$ lab finish data-netfilters五、 综合实验:使用过滤器和插件转换数据
开始实验(部署环境):
以用户student登入workstation虚拟机,使用lab命令来构建案例环境。
[student@workstation ~]$ lab start data-review解决方案:
1. 从https://git.lab.example.com/student/data-review.git仓库可控项目到/home/student/git-repos目录,然后创建exercise分支
创建/home/student/git-repos目录,并进入此目录:
[student@workstation ~]$ mkdir -p ~/git-repos/
[student@workstation ~]$ cd ~/git-repos/从Git仓库克隆项目,并进入项目目录:
[student@workstation git-repos]$ git clone https://git.lab.example.com/student/data-review.git
[student@workstation git-repos]$ cd data-review检出exercise分支:
[student@workstation data-review]$ git checkout -b exercise2. 检查~/git-repos/data-review项目目录中的防火墙角色
文件roles/firewall/tasks/main.yml包含三个使用firewalld模块的任务,用于配置firewall_rules变量定义的防火墙规则。
编辑任务文件,使其使用过滤器为未设置的三个任务中的每个任务中的变量设置默认值,如下所示:
-
对于state选项,如果未设置item['state']项,则默认情况下将其设置为enabled
-
对于zone选项,如果未设置item['zone'],则省略zone选项
-
在“Ensure Firewall Port Configuration”任务中,对于firewalld模块的port选项,如果未设置item['protocol']项,则将其设置为tcp。还要使用lower过滤器来确保item['protocol']选项的值是小写的
1)修改roles/firewall/tasks/main.yml文件,针对三个firewalld任务中的state条目,为Jinjia2表达式 item['state'] 添加 default('enabled') 过滤器,就像这样:
[student@workstation data-review]$ vim roles/firewall/tasks/main.yml
- name: Ensure Firewall Sources Configuration
ansible.posix.firewalld:
source: "{{ item['source'] }}"
zone: "{{ item['zone'] }}"
immediate: true
permanent: true
state: "{{ item['state'] | default('enabled') }}"
loop: "{{ firewall_rules }}"
when: item['source'] is defined
- name: Ensure Firewall Service Configuration
ansible.posix.firewalld:
service: "{{ item['service'] }}"
zone: "{{ item['zone'] }}"
immediate: true
permanent: true
state: "{{ item['state'] | default('enabled') }}"
loop: "{{ firewall_rules }}"
when: item['service'] is defined
- name: Ensure Firewall Port Configuration
ansible.posix.firewalld:
port: "{{ item['port'] }}/{{ item['protocol'] }}"
zone: "{{ item['zone'] }}"
immediate: true
permanent: true
state: "{{ item['state'] | default('enabled') }}"
loop: "{{ firewall_rules }}"
when: item['port'] is defined2)继续修改roles/firewall/tasks/main.yml文件,针对三个firewalld任务中的zone条目,为Jinjia2表达式 item['zone'] 添加 default(omit) 过滤器,就像这样:
- name: Ensure Firewall Sources Configuration
ansible.posix.firewalld:
source: "{{ item['source'] }}"
zone: "{{ item['zone'] | default(omit) }}"
immediate: true
permanent: true
state: "{{ item['state'] | default('enabled') }}"
loop: "{{ firewall_rules }}"
when: item['source'] is defined
- name: Ensure Firewall Service Configuration
ansible.posix.firewalld:
service: "{{ item['service'] }}"
zone: "{{ item['zone'] | default(omit) }}"
immediate: true
permanent: true
state: "{{ item['state'] | default('enabled') }}"
loop: "{{ firewall_rules }}"
when: item['service'] is defined
- name: Ensure Firewall Port Configuration
ansible.posix.firewalld:
port: "{{ item['port'] }}/{{ item['protocol'] }}"
zone: "{{ item['zone'] | default(omit) }}"
immediate: true
permanent: true
state: "{{ item['state'] | default('enabled') }}"
loop: "{{ firewall_rules }}"
when: item['port'] is defined3)再继续修改roles/firewall/tasks/main.yml文件,在第三个firewalld任务Ensure Firewall Port Configuration中,将 {{ item['protocol'] }} 替换成 {{ item['protocol'] | default('tcp') | lower }},就像这样:
..output omitted...
- name: Ensure Firewall Port Configuration
ansible.posix.firewalld:
port: "{{ item['port'] }}/{{ item['protocol'] | default('tcp') | lower }}"
zone: "{{ item['zone'] | default(omit) }}"
immediate: true
permanent: true
state: "{{ item['state'] | default('enabled') }}"
loop: "{{ firewall_rules }}"
when: item['port'] is defined最终修改剧本,可参考:
---
# tasks file for firewall
- name: Ensure Firewall Sources Configuration
ansible.posix.firewalld:
source: "{{ item['source'] }}"
zone: "{{ item['zone'] | default(omit) }}"
immediate: true
permanent: true
state: "{{ item['state'] | default('enabled') }}"
loop: "{{ firewall_rules }}"
when: item['source'] is defined
- name: Ensure Firewall Service Configuration
ansible.posix.firewalld:
service: "{{ item['service'] }}"
zone: "{{ item['zone'] | default(omit) }}"
immediate: true
permanent: true
state: "{{ item['state'] | default('enabled') }}"
loop: "{{ firewall_rules }}"
when: item['service'] is defined
- name: Ensure Firewall Port Configuration
ansible.posix.firewalld:
port: "{{ item['port'] }}/{{ item['protocol'] | default('tcp') | lower }}"
zone: "{{ item['zone'] | default(omit) }}"
immediate: true
permanent: true
state: "{{ item['state'] | default('enabled') }}"
loop: "{{ firewall_rules }}"
when: item['port'] is defined3. 运行test_firewall_role.yml剧本来测试roles/firewall/tasks/main.yml角色文件,剧本将运行而不会出现错误
[student@workstation data-review]$ ansible-navigator run -m stdout test_firewall_role.yml
PLAY [Test Firewall Role] ******************************************************
TASK [Gathering Facts] *********************************************************
ok: [serverc.lab.example.com]
ok: [serverb.lab.example.com]
TASK [firewall : Ensure Firewall Sources Configuration] ************************
skipping: [serverb.lab.example.com] => (item={'port': 8008, 'protocol': 'TCP', 'zone': 'internal'})
skipping: [serverc.lab.example.com] => (item={'port': 8008, 'protocol': 'TCP', 'zone': 'internal'})
changed: [serverb.lab.example.com] => (item={'zone': 'internal', 'source': '172.25.250.10'})
skipping: [serverb.lab.example.com] => (item={'service': 'ftp', 'state': 'disabled'})
changed: [serverc.lab.example.com] => (item={'zone': 'internal', 'source': '172.25.250.10'})
skipping: [serverc.lab.example.com] => (item={'service': 'ftp', 'state': 'disabled'})
TASK [firewall : Ensure Firewall Service Configuration] ************************
skipping: [serverb.lab.example.com] => (item={'port': 8008, 'protocol': 'TCP', 'zone': 'internal'})
skipping: [serverb.lab.example.com] => (item={'zone': 'internal', 'source': '172.25.250.10'})
skipping: [serverc.lab.example.com] => (item={'port': 8008, 'protocol': 'TCP', 'zone': 'internal'})
skipping: [serverc.lab.example.com] => (item={'zone': 'internal', 'source': '172.25.250.10'})
ok: [serverb.lab.example.com] => (item={'service': 'ftp', 'state': 'disabled'})
ok: [serverc.lab.example.com] => (item={'service': 'ftp', 'state': 'disabled'})
TASK [firewall : Ensure Firewall Port Configuration] ***************************
changed: [serverc.lab.example.com] => (item={'port': 8008, 'protocol': 'TCP', 'zone': 'internal'})
skipping: [serverc.lab.example.com] => (item={'zone': 'internal', 'source': '172.25.250.10'})
skipping: [serverc.lab.example.com] => (item={'service': 'ftp', 'state': 'disabled'})
changed: [serverb.lab.example.com] => (item={'port': 8008, 'protocol': 'TCP', 'zone': 'internal'})
skipping: [serverb.lab.example.com] => (item={'zone': 'internal', 'source': '172.25.250.10'})
skipping: [serverb.lab.example.com] => (item={'service': 'ftp', 'state': 'disabled'})
PLAY RECAP *********************************************************************
serverb.lab.example.com : ok=4 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
serverc.lab.example.com : ok=4 changed=2 unreachable=0 failed=0 skipped=0 rescued=0 ignored=04. 检查deploy_apache.yml剧本。它调用apache角色以确保部署Apache HTTP Server,而Apache HTTP Server本身调用firewall角色。这个剧本还定义了firewall_rules变量,以确保firewalld的http服务和负载平衡器的IPv4地址(172.25.250.10)都在内部区域中启用firewalld
修改deploy_apache.yml剧本,将firewall_rules变量的值更改为Jinja2表达式,该表达式使用template查询插件从apache_firewall_rules.yml.j2模板动态生成变量的设置。
需要在Jinja2表达式中使用from_yaml过滤器,将字符串结果值转换为YAML结构的数据。
修改后的deploy_apache.yml 剧本,可参考以下内容:
[student@workstation data-review]$ vim deploy_apache.yml
- name: Ensure Apache is deployed
hosts: web_servers
force_handlers: true
gather_facts: false
roles:
# Use the apache_firewall_rules.yml.j2 template to
# generate the firewall rules.
- role: apache
firewall_rules: "{{ lookup('ansible.builtin.template', 'apache_firewall_rules.yml.j2') | from_yaml }}"5. 检查templates/apache_firewall_rules.yml.j2模板,你的剧本使用这个模板文件设置firewall_rules变量
对于第一条规则,apache_port 变量由group_vars目录中的文件设置。该模板包含一个Jinja2格式的for循环,用来为lb_servers组中的每个主机创建一个规则,根据 load_balancer_IP_addr 变量的值设置源IP地址。
这不是最好的解决方案,因为它要求你将load_balancer_ip_addr设置为lb_servers组中每个负载平衡器的主机变量。要避免这个手动维护的操作,请使用从这些主机收集的系统指标来设置这个值。
编辑 templates/apache_firewall_rules.yml.j2模板,将for循环中的load_balancer_ip_addr主机变量替换为hostvars[server]['anable_facts']['default_ipv4']['address']系统指标。
完成的templates/apache_firewall_rules.yml.j2模板应该包含以下内容:
[student@workstation data-review]$ vim templates/apache_firewall_rules.yml.j2
- port: {{ apache_port }}
protocol: TCP
zone: internal
{% for server in groups['lb_servers'] %}
- zone: internal
source: "{{ hostvars[server]['ansible_facts']['default_ipv4']['address'] }}"
{% endfor %}6. 运行site.yml剧本来测试,剧本将正确运行而不会出现错误
[student@workstation data-review]$ ansible-navigator run site.yml -m stdout
...output omitted...
[student@workstation data-review]$ echo $?
07. 确保从workstation能通过访问负载均衡器servera看到网页内容,如果直接访问后端的serverb或serverc(的TCP 80或8008端口)会被拒绝
[student@workstation data-review]$ curl servera
This is serverb. (version v1.0)
[student@workstation data-review]$ curl servera
This is serverc. (version v1.0)
[student@workstation data-review]$ curl serverb; curl serverb:8008
curl: (7) Failed to connect to serverb port 80: No route to host
curl: (7) Failed to connect to serverb port 8008: No route to host
[student@workstation data-review]$ curl serverc; curl serverc:8008
curl: (7) Failed to connect to serverc port 80: No route to host
curl: (7) Failed to connect to serverc port 8008: No route to host8. 保存你的工作,然后使用Git提交并推送更改
[student@workstation data-review]$ git status
On branch exercise
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: deploy_apache.yml
modified: roles/firewall/tasks/main.yml
modified: tempLates/apache_firewall_rules.yml.j2
no changes added to commit (use "git add" and/or "git commit -a")
[student@workstation data-review]$ git add deploy_apache.yml roles/firewall/tasks/main.yml templates/apache_firewall_rules.yml.j2
[student@workstation data-review]$ git commit -m "Added Filters and Plug-ins"
[student@workstation data-review]$ git push -u origin exercise
Password for 'https://student@git.lab.example.com': Student@123结束实验(清理环境):
在workstation虚拟机上,切换到student用户主目录,使用lab命令来清理案例环境,确保先前练习的资源不会影响后续的练习。
[student@workstation ~]$ lab finish data-review思维导图:
小结:
本篇为 【RHCA认证 - DO374 | Day07:使用过滤器和插件转换数据】的学习笔记,希望这篇笔记可以让您初步了解如何使用过滤器处理变量、使用查找插件处理外部数据、 实现高级循环、使用过滤器处理网络地址、综合实验:使用过滤器和插件转换数据等,不妨跟着我的笔记步伐亲自实践一下吧
Tip:毕竟两个人的智慧大于一个人的智慧,如果你不理解本章节的内容或需要相关环境、视频,可评论666并私信小安,请放下你的羞涩,花点时间直到你真正的理解。


















 1035
1035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











