




🔥🔥 AllData大数据产品是可定义数据中台,以数据平台为底座,以数据中台为桥梁,以机器学习平台为中层框架,以大模型应用为上游产品,提供全链路数字化解决方案。
✨杭州奥零数据科技官网:http://www.aolingdata.com
✨AllData开源项目:https://github.com/alldatacenter/alldata
✨Gitee组织:https://gitee.com/alldatacenter
摘要:湖仓平台中心基于开源项目Amoro建设,是一款湖仓一体化的数据管理平台,支持批流数据统一存储与计算,融合数据湖灵活性与数据仓库治理能力。内容主要为以下五部分:

2.1 湖仓平台中心基于开源项目Amoro建设:
湖仓平台中心(Amoro)是一款湖仓一体化的数据管理平台,支持批流数据统一存储与计算,融合数据湖灵活性与数据仓库治理能力。其核心功能包括元数据统一管理、数据高效入湖、自优化存储、ACID事务支持及多引擎(Flink/Spark)无缝集成,助力企业构建高性价比、易维护的实时数据底座。
🔹Amoro开源项目:https://github.com/apache/amoro
🔹Amoro文档地址:https://amoro.apache.org/docs/latest/
2.2 湖仓平台中心功能特点:
- 湖仓一体化管理
- 多种格式支持
- 核心架构组件强大
- 生态集成与扩展
- 存储与查询性能优化

💡部署步骤:

3.1 环境准备
🔹操作系统要求:Amoro支持Linux或macOS操作系统。对于Windows用户,建议使用WSL2(Windows Subsystem for Linux 2)以获得更好的兼容性。
🔹Java版本:Amoro使用Java 17版本,确保已安装并配置好Java环境。🔹Maven:用于构建项目,确保已安装并配置好Maven环境。
🔹Git:用于克隆项目代码,确保已安装并配置好Git环境。
🔹数据库:Amoro需要使用关系型数据库(如MySQL)作为元数据存储。确保已安装并配置好数据库,并创建好相应的数据库和用户。
3.2 获得源码
🔹版本选择:建议使用与AllData商业版兼容的Amoro版本。

3.3 编译构建前的关键准备
🔹环境依赖确认
Java环境:确保使用JDK 17,通过java -version验证。
Maven版本:建议Maven 3.8.4+,通过mvn -v验证。
网络配置:若使用私有仓库或需要代理,需提前配置settings.xml。
3.4 核心编译构建步骤
🔹进入项目根目录

🔹执行Maven构建命令
基础构建(跳过测试,快速生成部署包):
作用:清理旧构建文件并编译所有模块,生成target目录下的可执行包(如JAR或ZIP)。
适用场景:首次构建或验证环境。

🔹带测试的完整构建(需确保测试环境可用)
基础构建(跳过测试,快速生成部署包):
注意:测试可能依赖外部服务(如数据库、Kafka),需提前配置。

🔹指定版本参数(可选)
Hadoop版本(如3.3.4):

Flink版本(如1.17.0):

Spark版本(如3.3.2)
适用场景:需与特定大数据组件版本兼容时。

3.5 构建结果验证
🔹检查输出文件构建成功后,在amoro-distribution/target目录下生成amoro--bin.zip或amoro--bin.tar.gz。
🔹验证文章完整性解压后检查关键目录:
bin/:启动脚本(如ams.sh)。conf/:配置文件模板(如config.yaml)。lib/:依赖JAR包。
3.6 高级构建技巧
🔹并行构建加速

🔹生成IDE项目文件–IntelliJ IDEA:

–Eclipse:

🔹自定义构建配置
修改pom.xml中的节点,覆盖默认版本号(如<flink.version>1.18.0</flink.version>)。
3.7 部署及运行配置
🔹解压部署包:
如果构建后得到的是压缩包,需要先解压到指定目录。
🔹配置数据库连接:
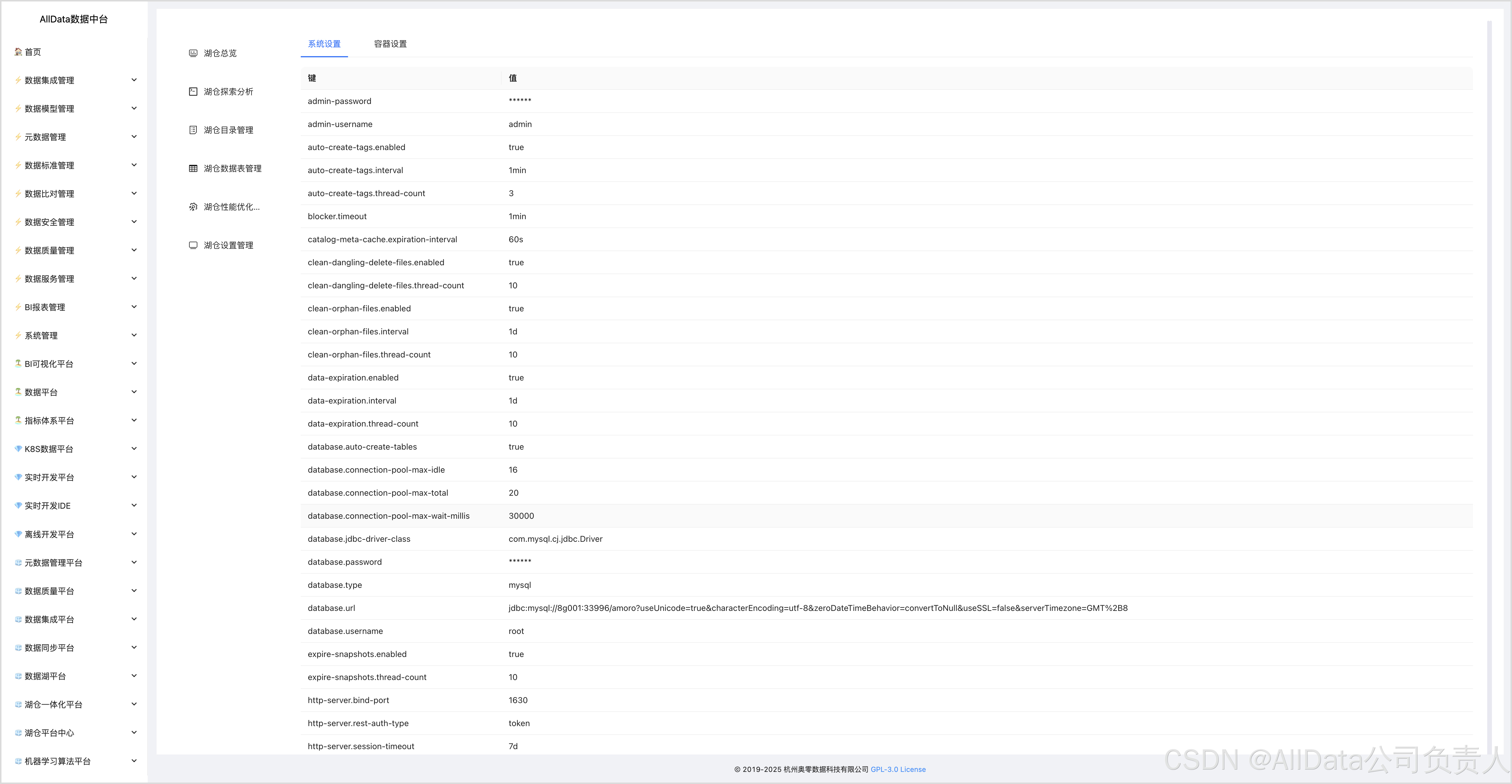
编辑Amoro的配置文件(如conf/config.yaml),配置数据库连接信息,包括数据库类型、JDBC驱动类、URL、用户名和密码等。
🔹配置服务端口:
根据需要,配置Amoro服务的端口号,如管理服务端口、HTTP服务端口等。
🔹配置优化器:
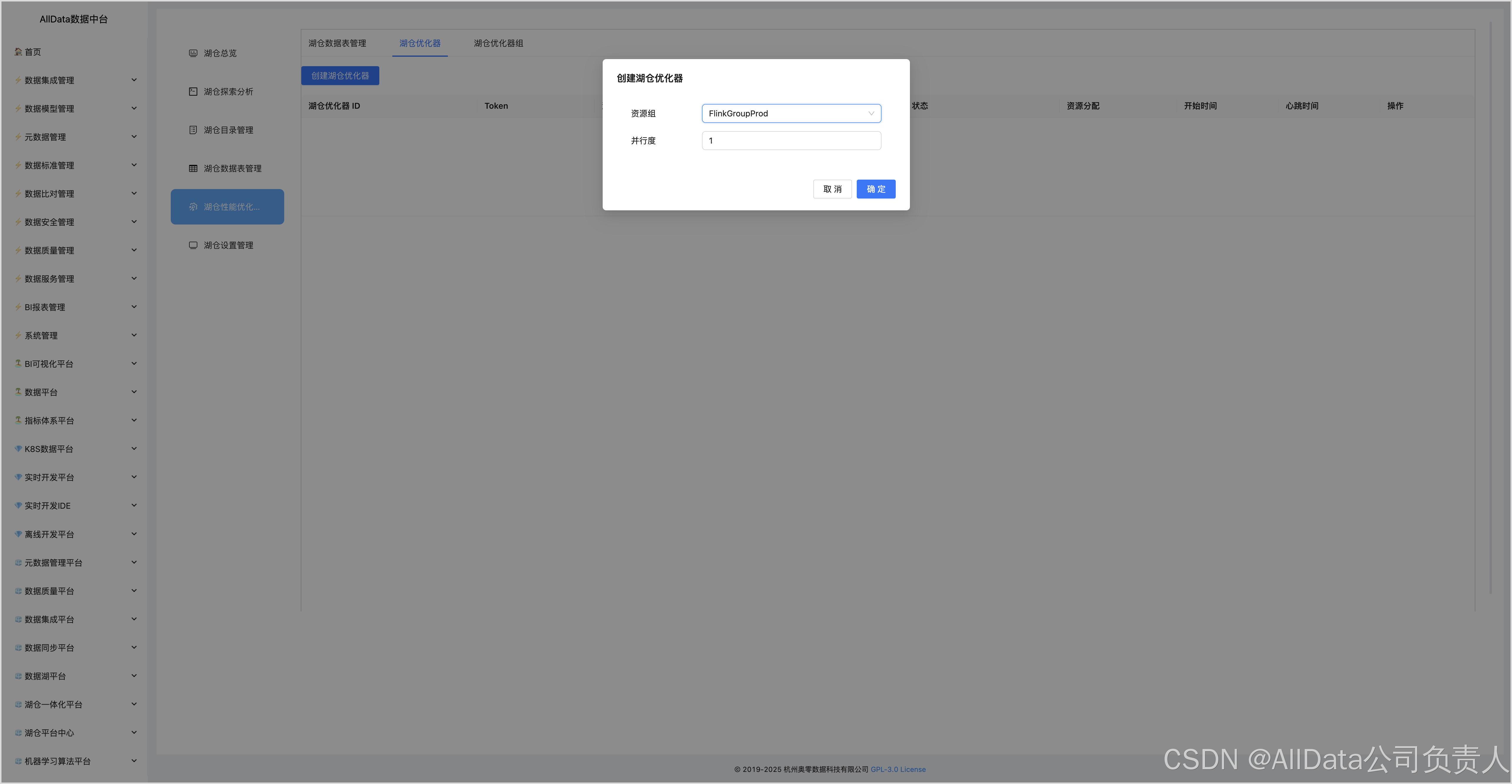
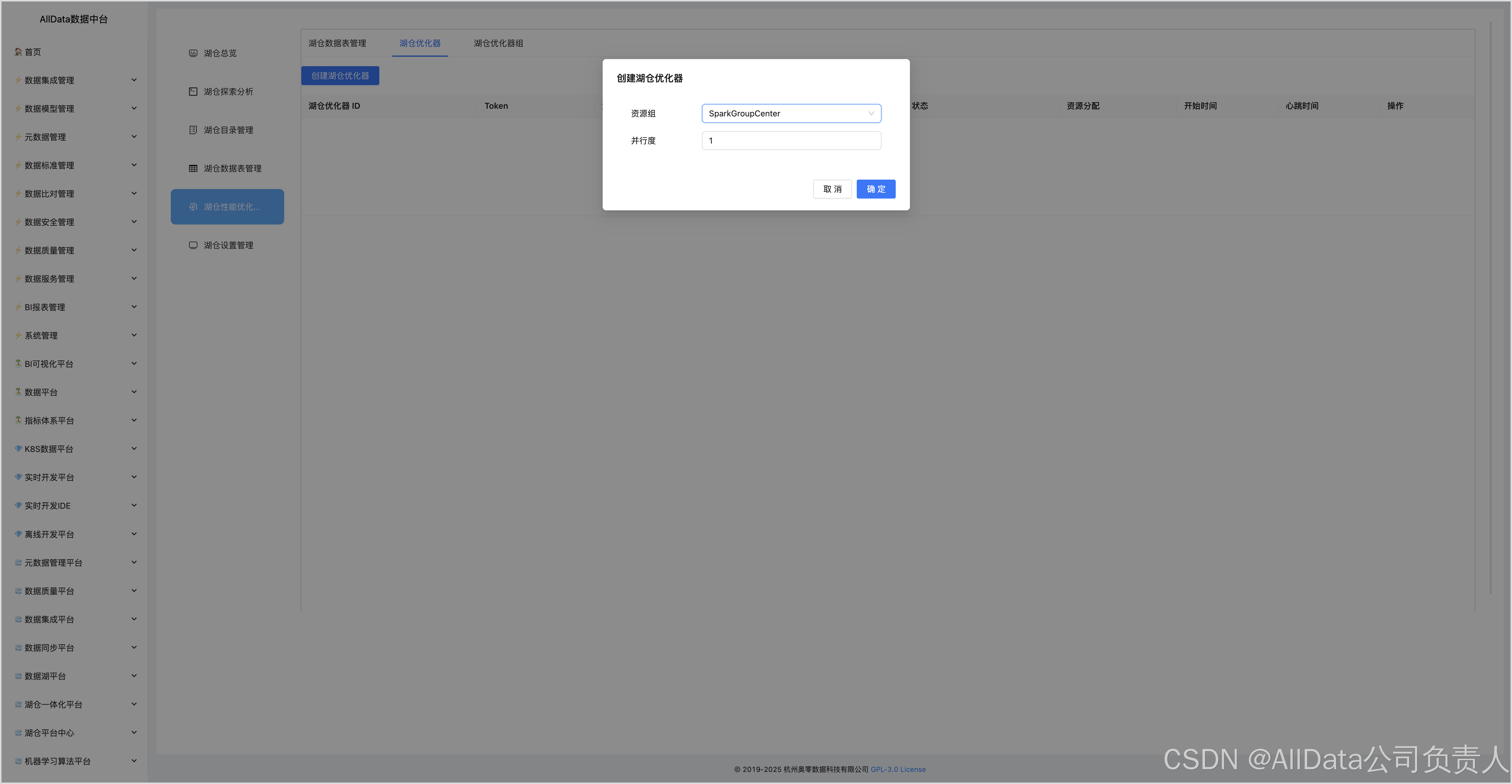
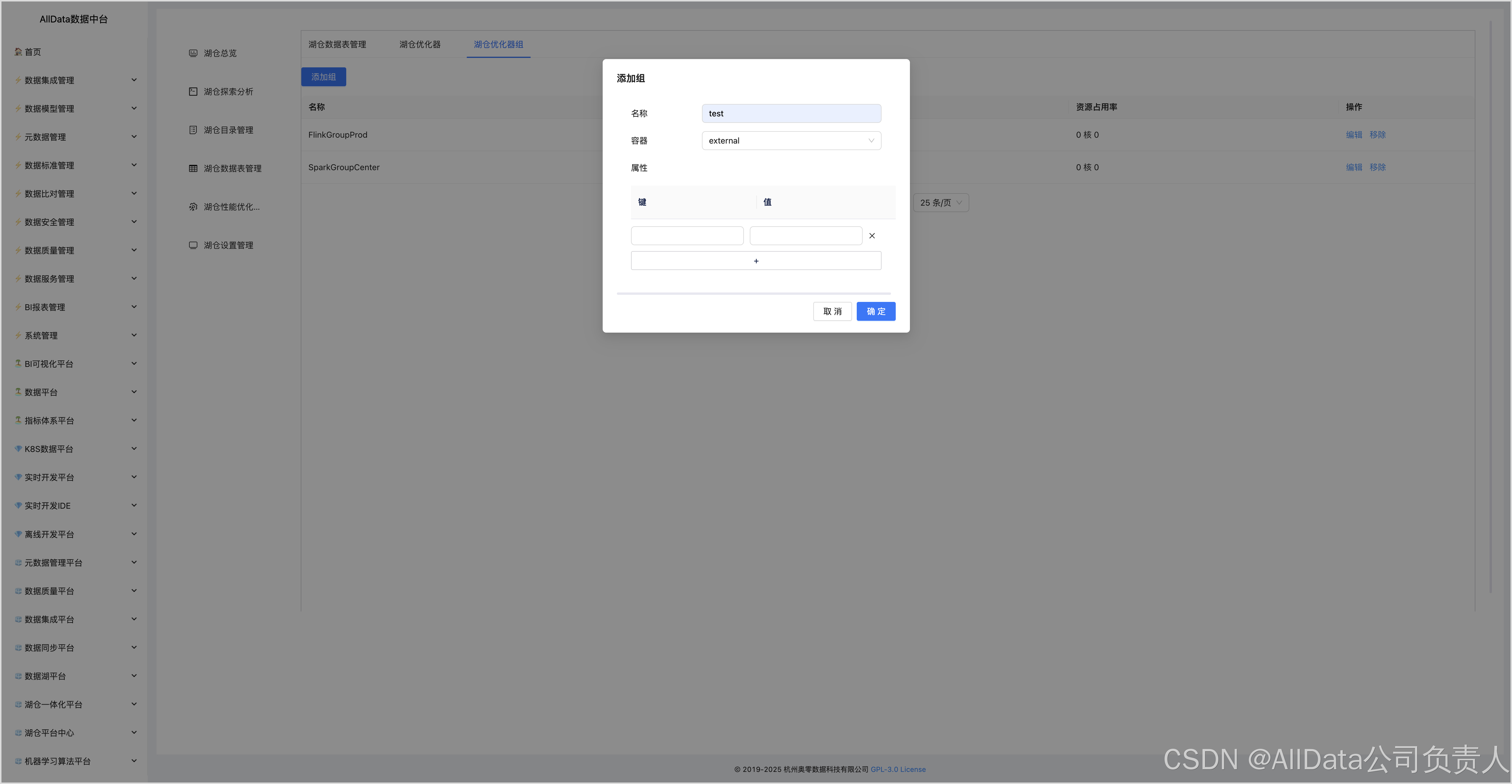
如果需要使用Amoro的自优化功能,需要配置优化器(Optimizer)的相关参数,如优化器组(Optimizer Group)、并行度、内存大小等。
🔹启动服务:
使用Amoro提供的启动脚本(如bin/ams.sh)启动服务。确保启动脚本具有执行权限。
3.8 可选配置
🔹高可用配置:
如果需要实现Amoro的高可用性,可以配置主从模式,并依赖外部Zookeeper集群进行主节点选举。
🔹外部Catalog集成:
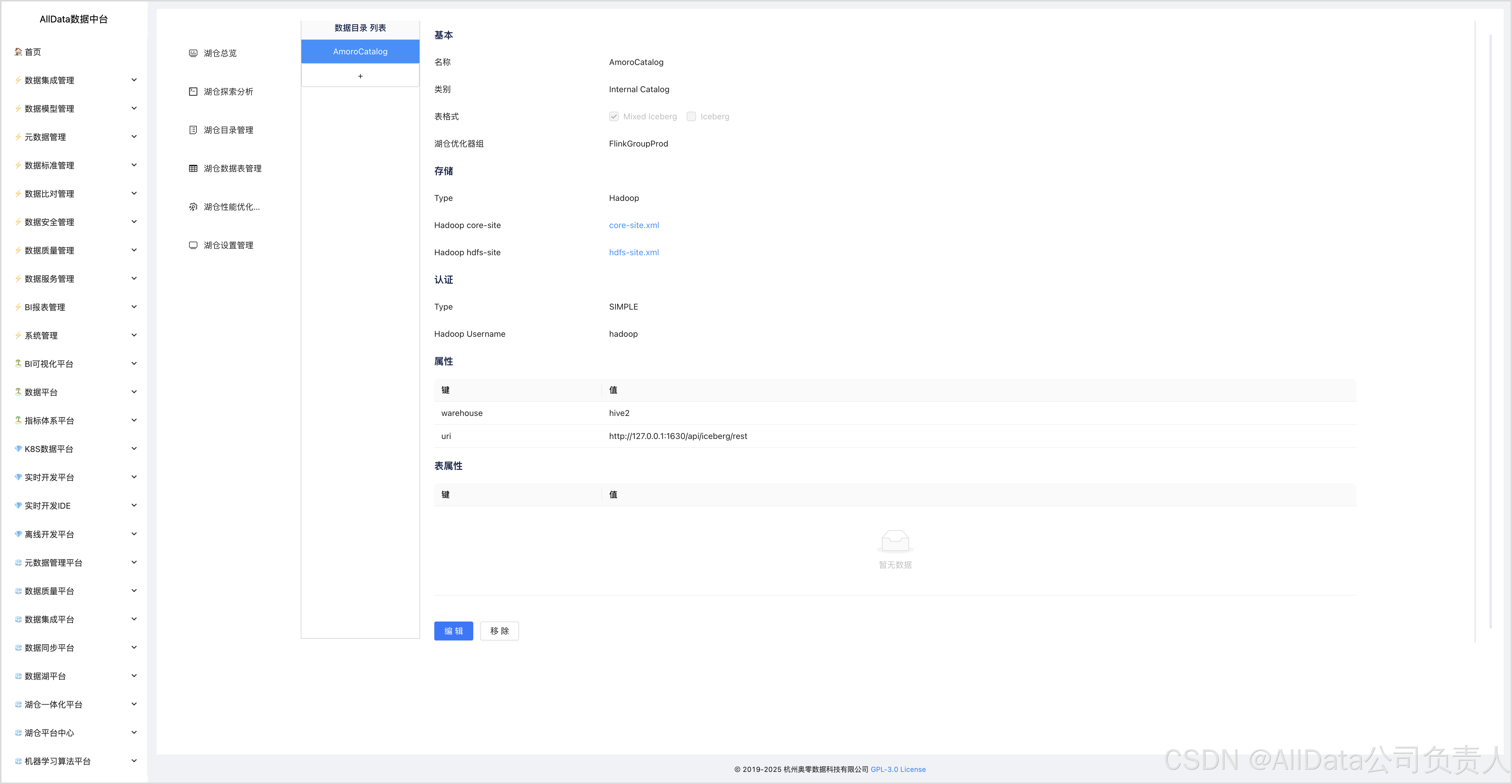
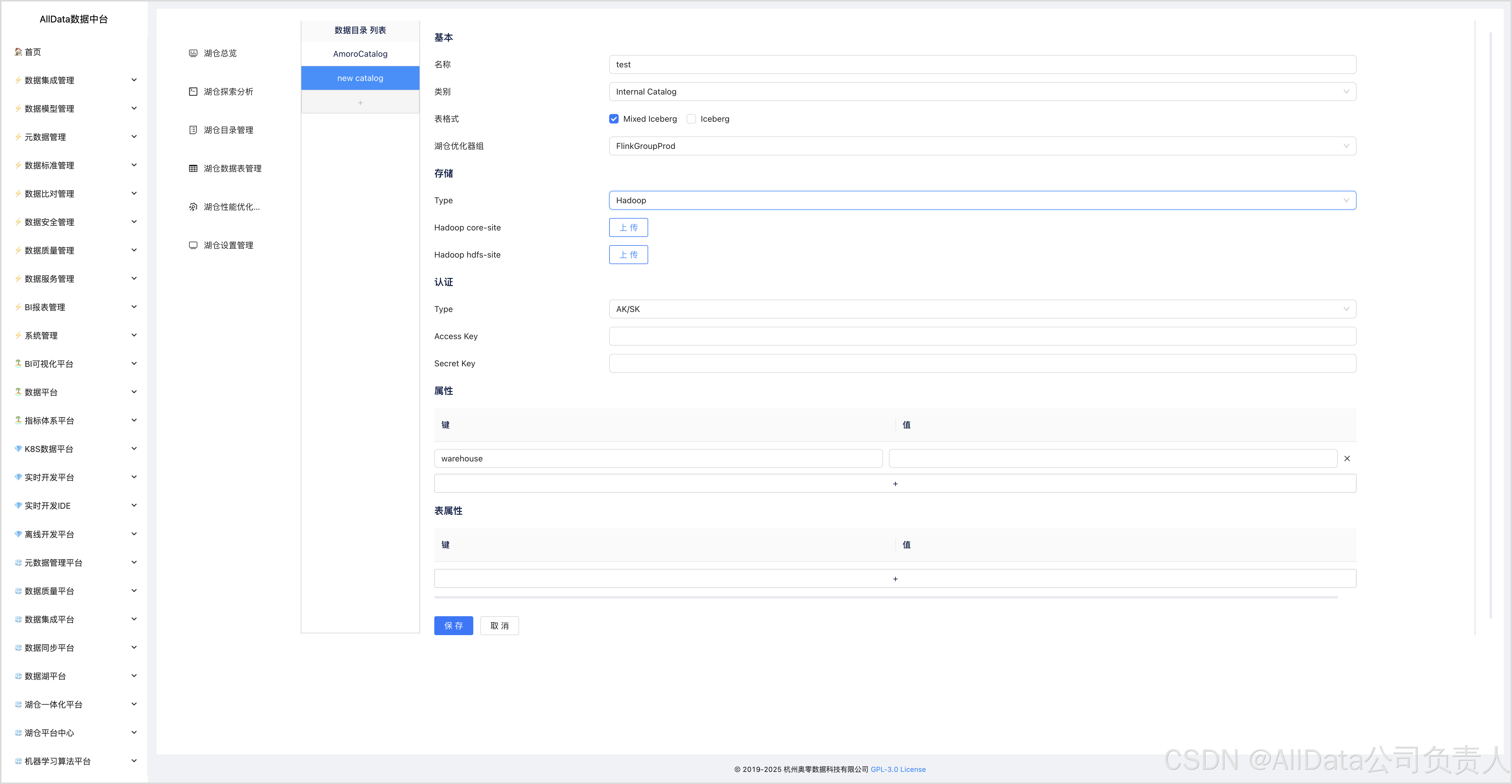
如果需要与外部Catalog服务(如Hive Metastore、AWS Glue Catalog等)集成,需要配置相应的Catalog信息,并上传必要的配置文件(如hive-site.xml)。
🔹存储类型配置:
根据需要,配置存储类型(如Hadoop、S3等),并上传相应的配置文件(如core-site.xml、hdfs-site.xml等)。
🔹认证配置:
如果需要启用认证功能,可以配置认证类型(如SIMPLE、KERBEROS等),并提供相应的认证信息。
3.9 验证与测试
🔹验证服务状态:
使用Amoro提供的Web管理界面或命令行工具验证服务状态,确保服务已成功启动并正常运行。
🔹测试功能:
通过创建表、插入数据、查询数据等操作测试Amoro的功能,确保各项功能正常工作。

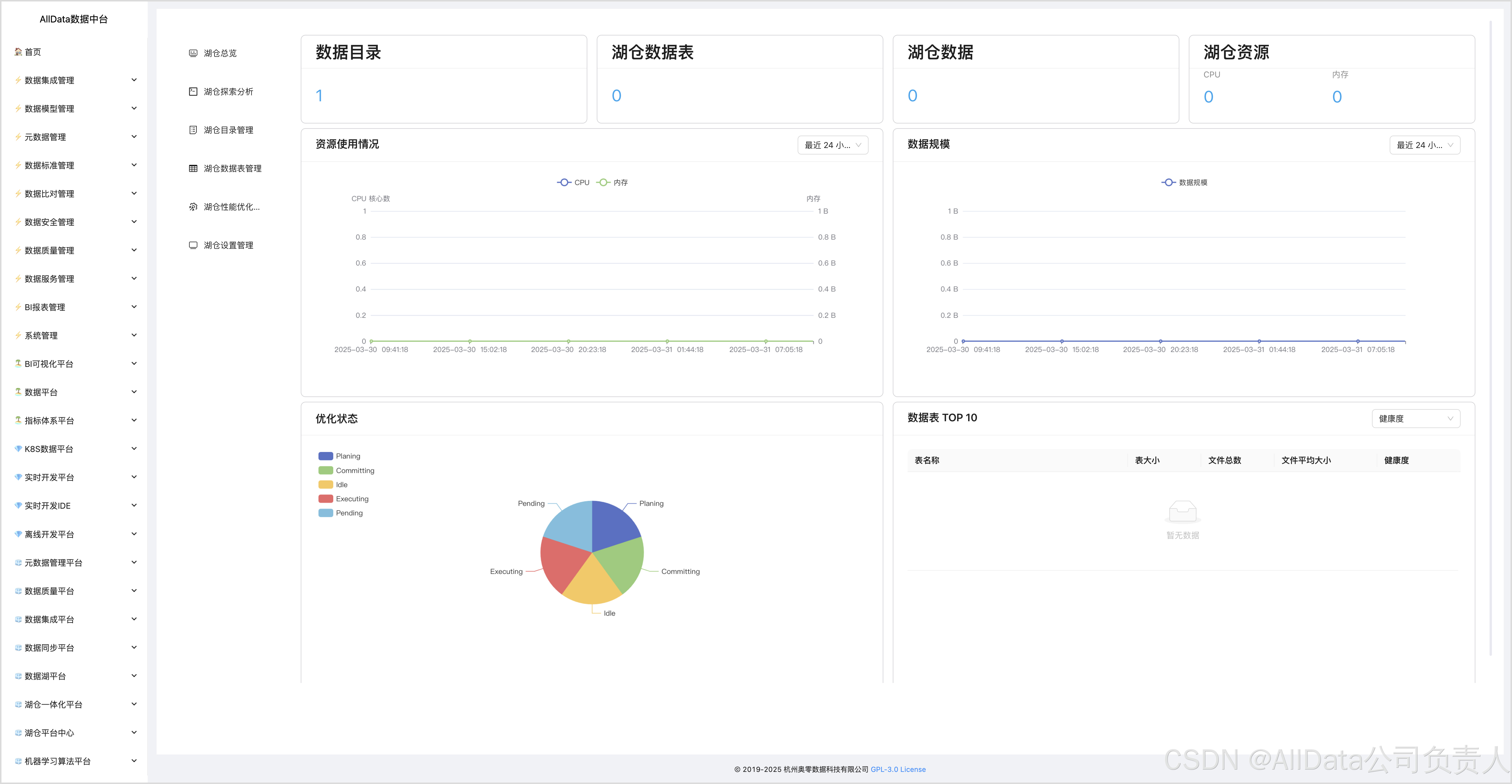
4.1 湖仓平台中心-功能概览
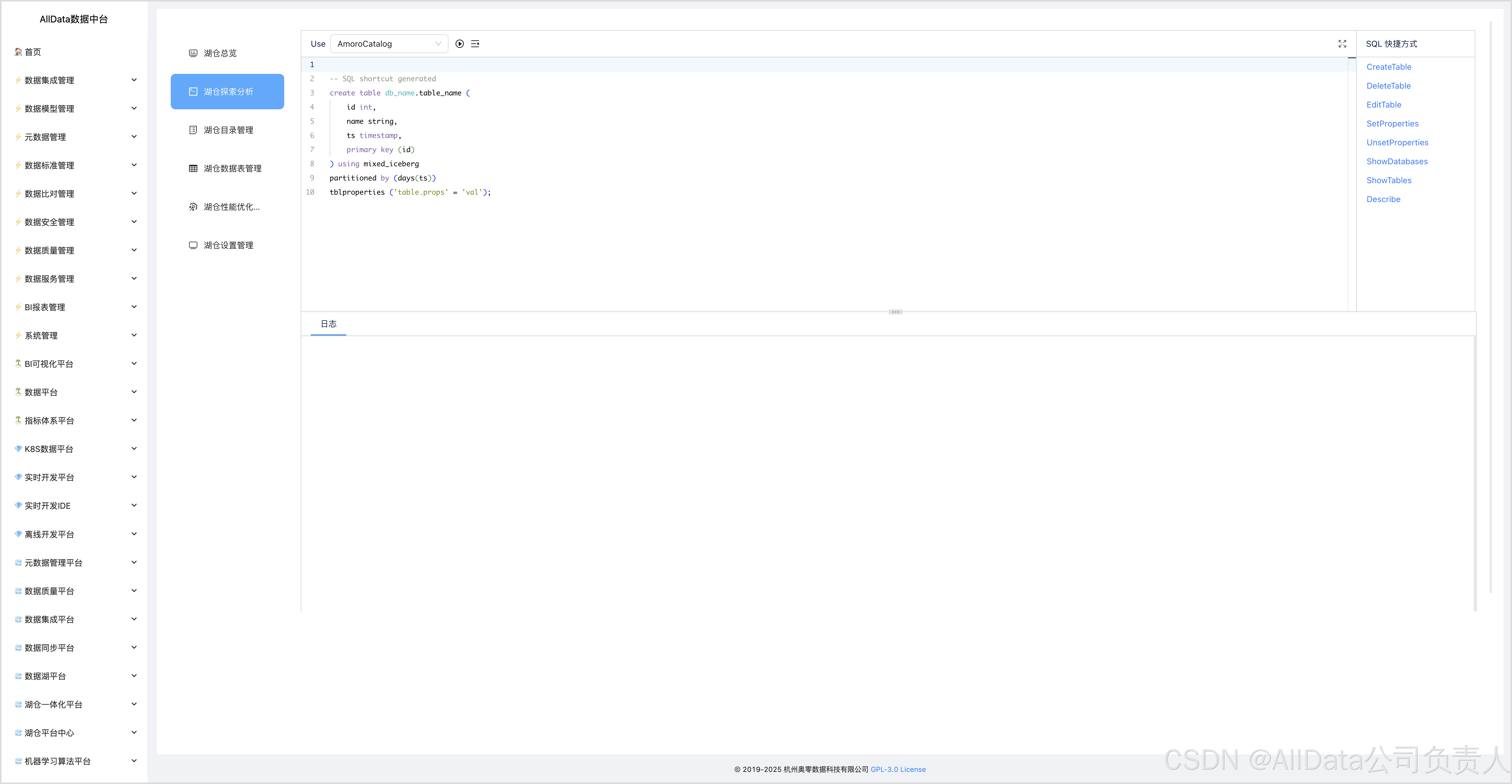
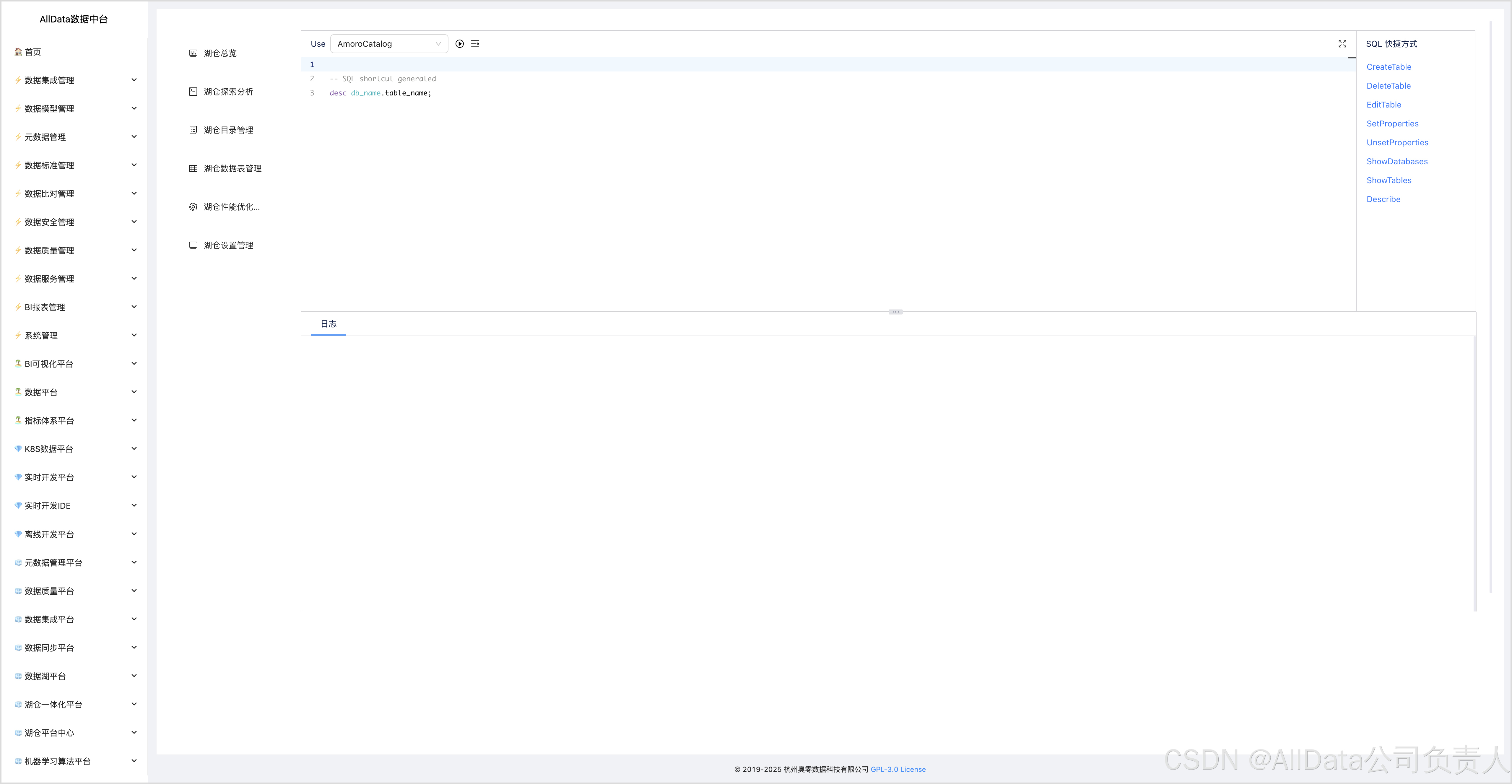
4.2 湖仓探索分析-CreateTable
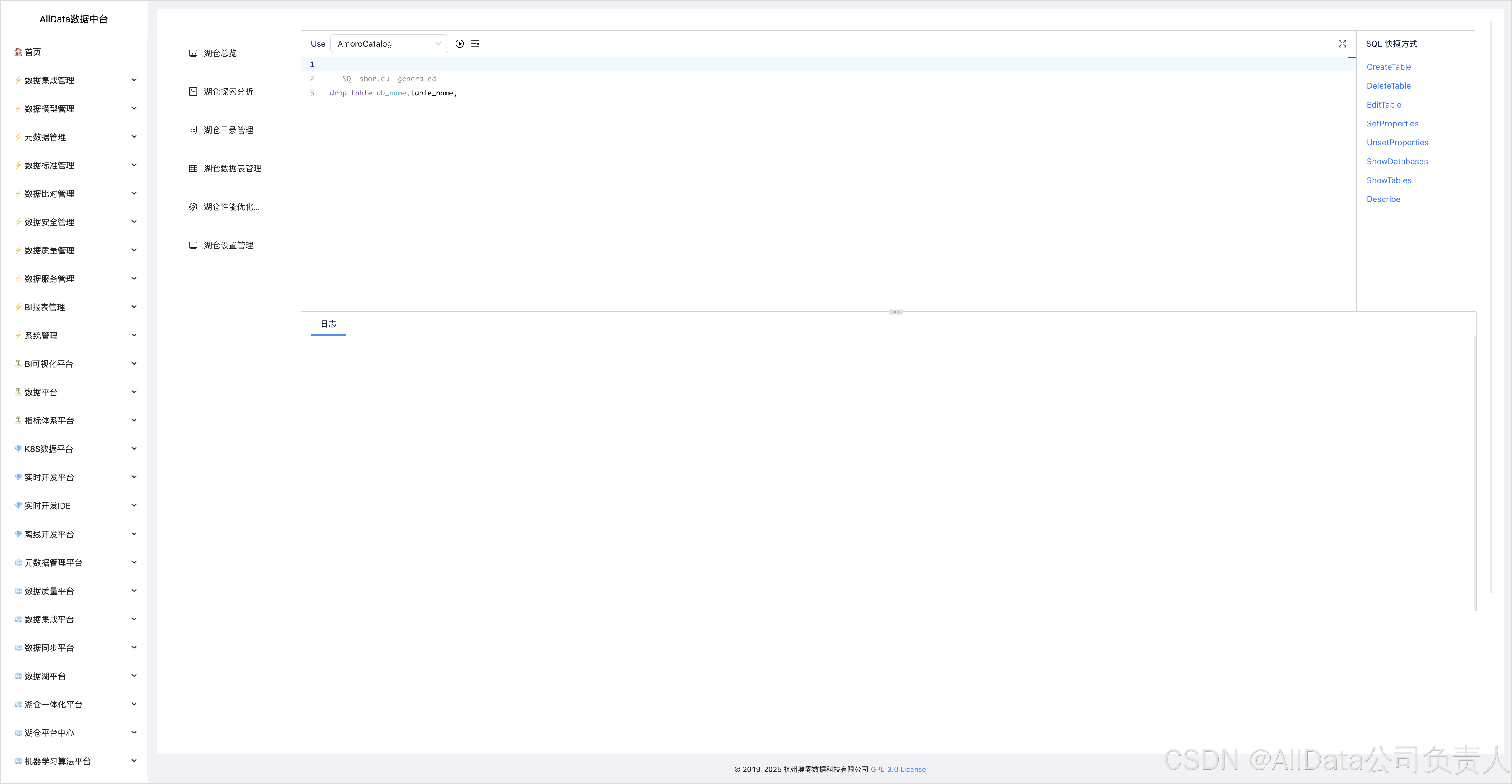
4.3 湖仓探索分析-DeleteTable
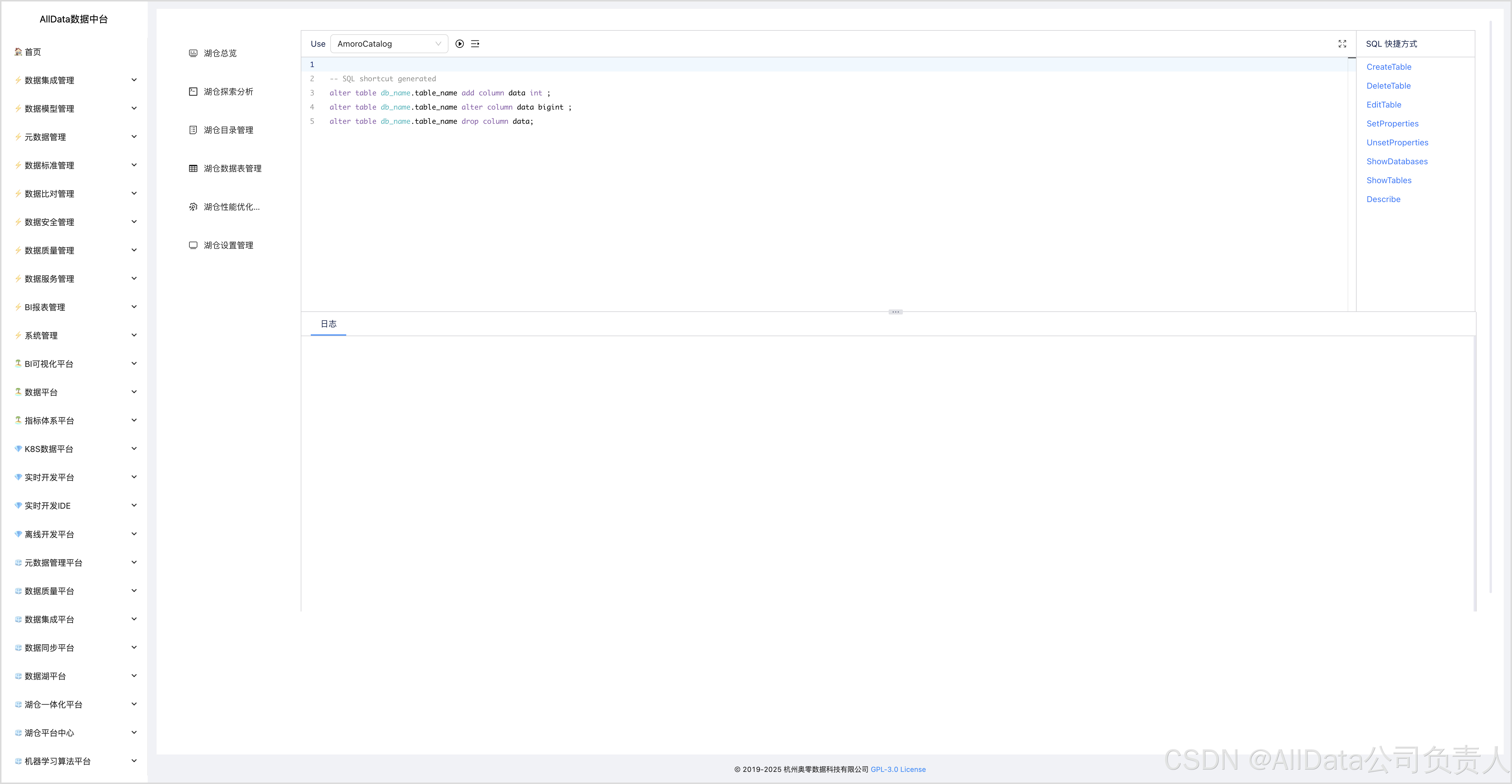
4.4 湖仓探索分析-EditTable
4.5 湖仓探索分析-SetProperties
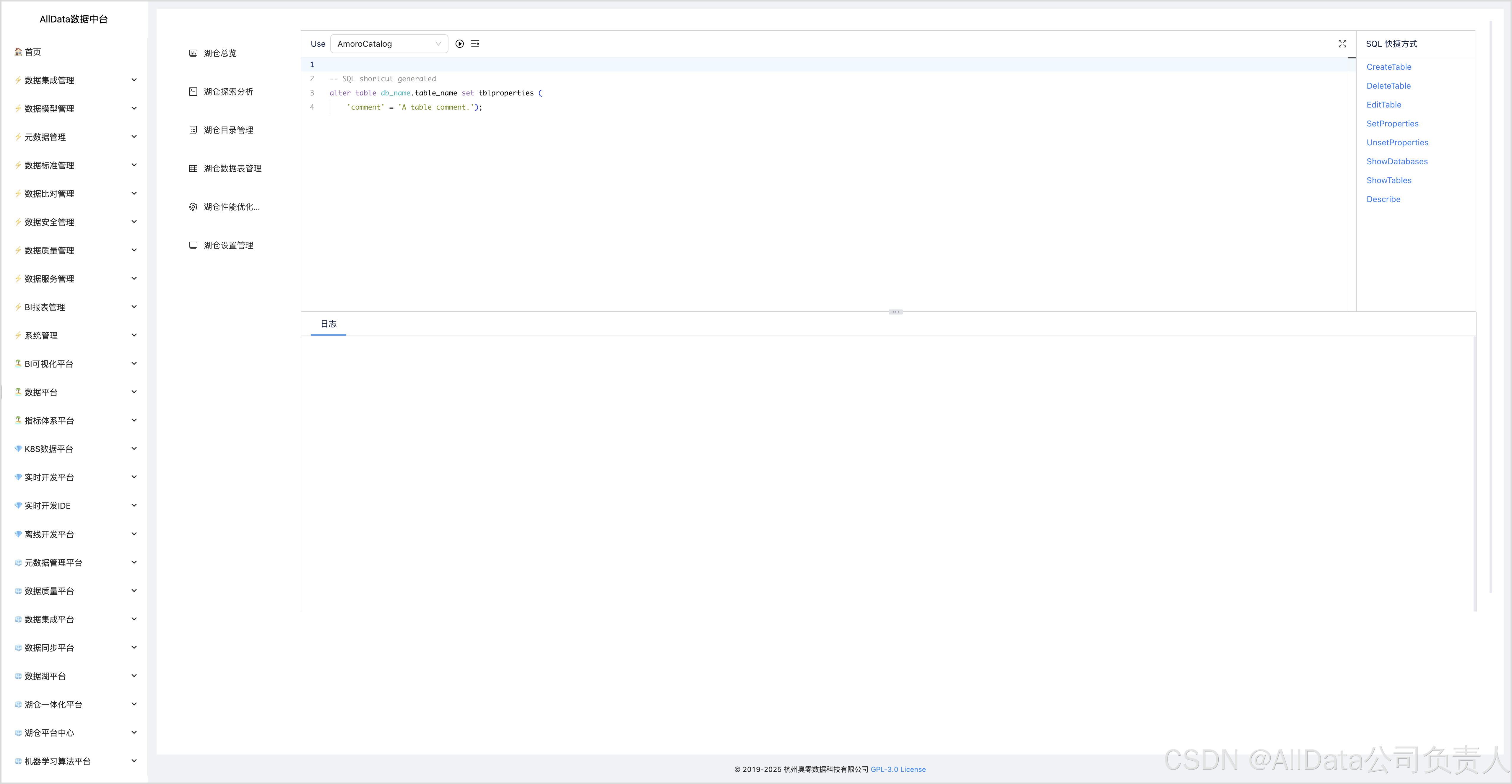
4.6 湖仓探索分析-UnsetProperties
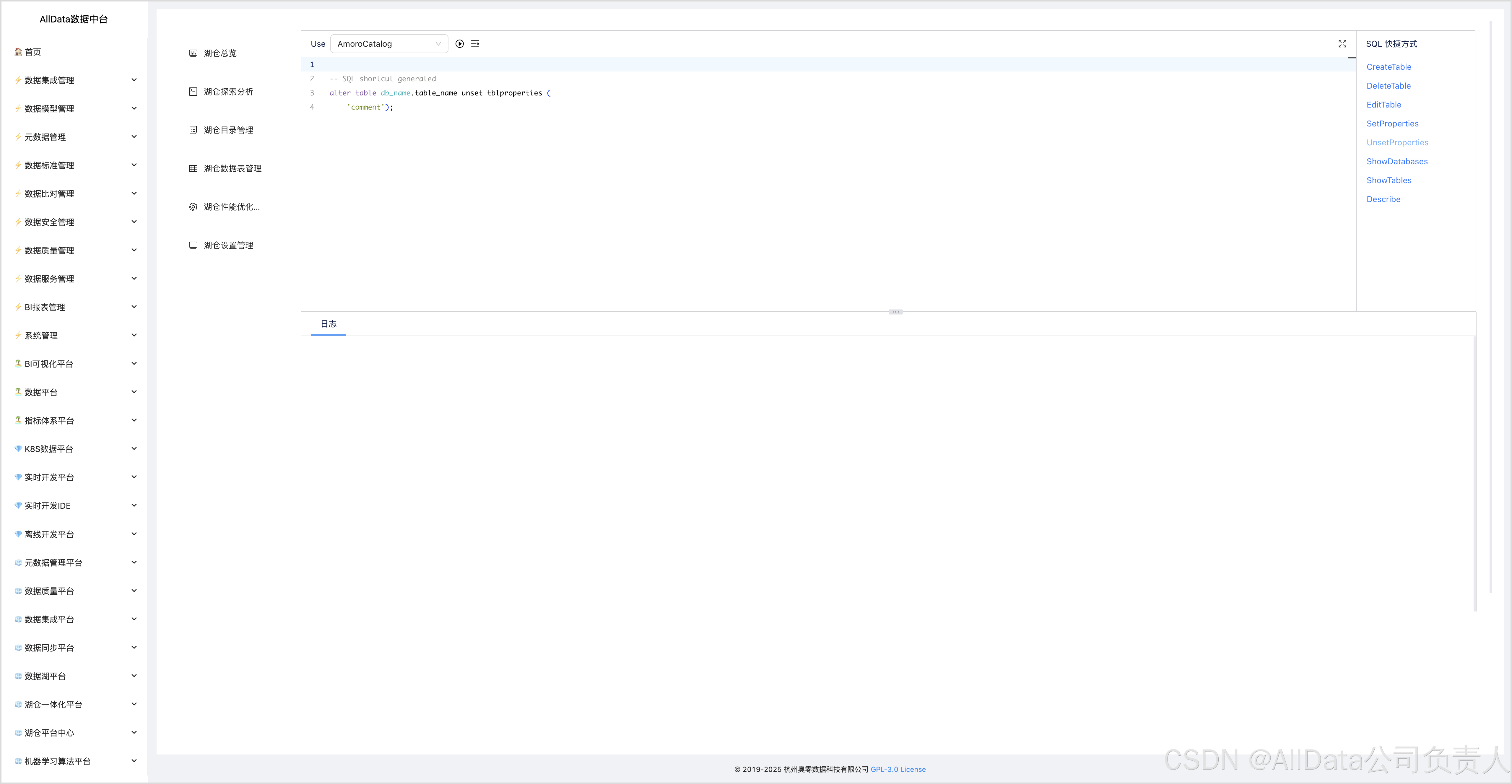
4.7 湖仓探索分析-ShowDatabases
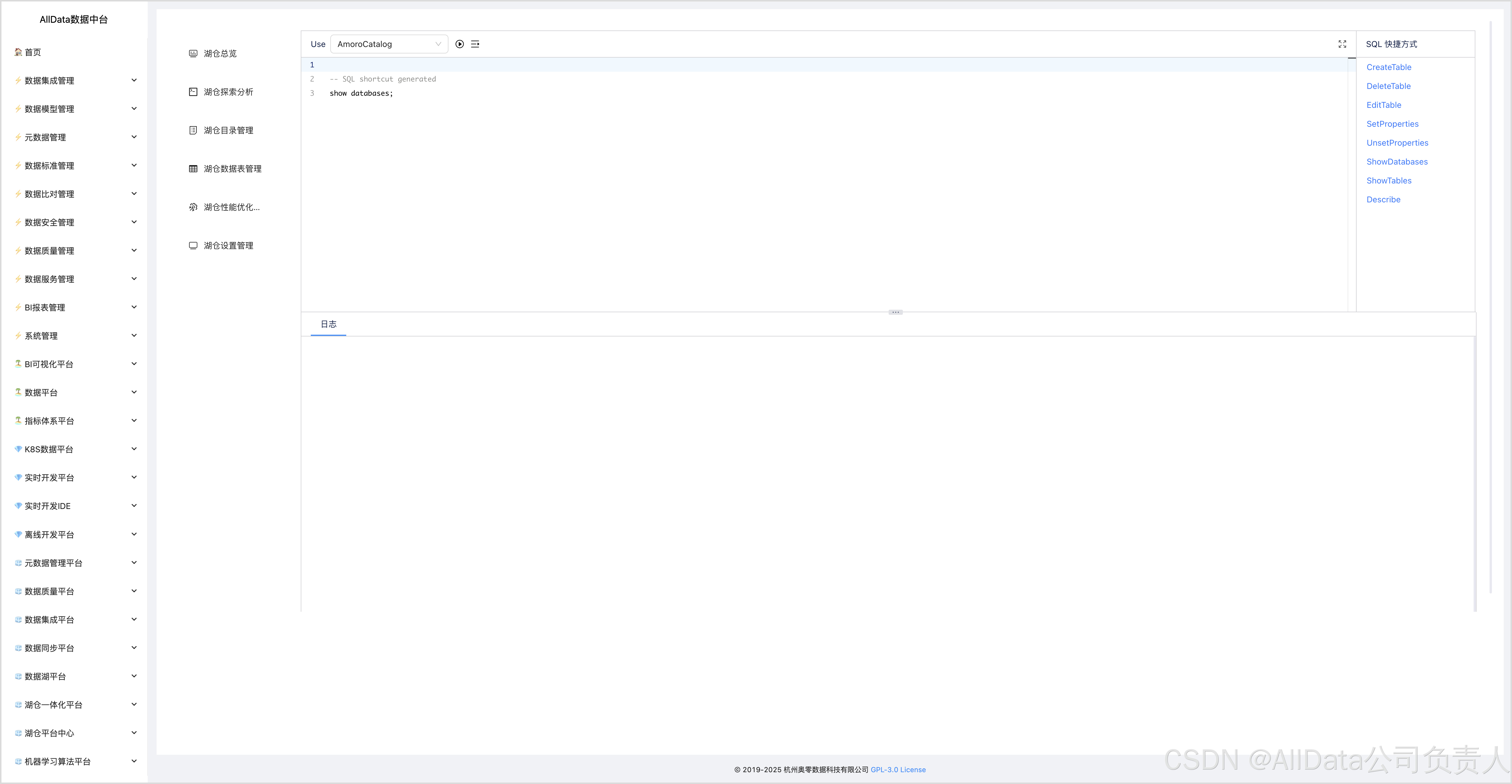
4.8 湖仓探索分析-ShowTables
4.9 湖仓探索分析-Describe
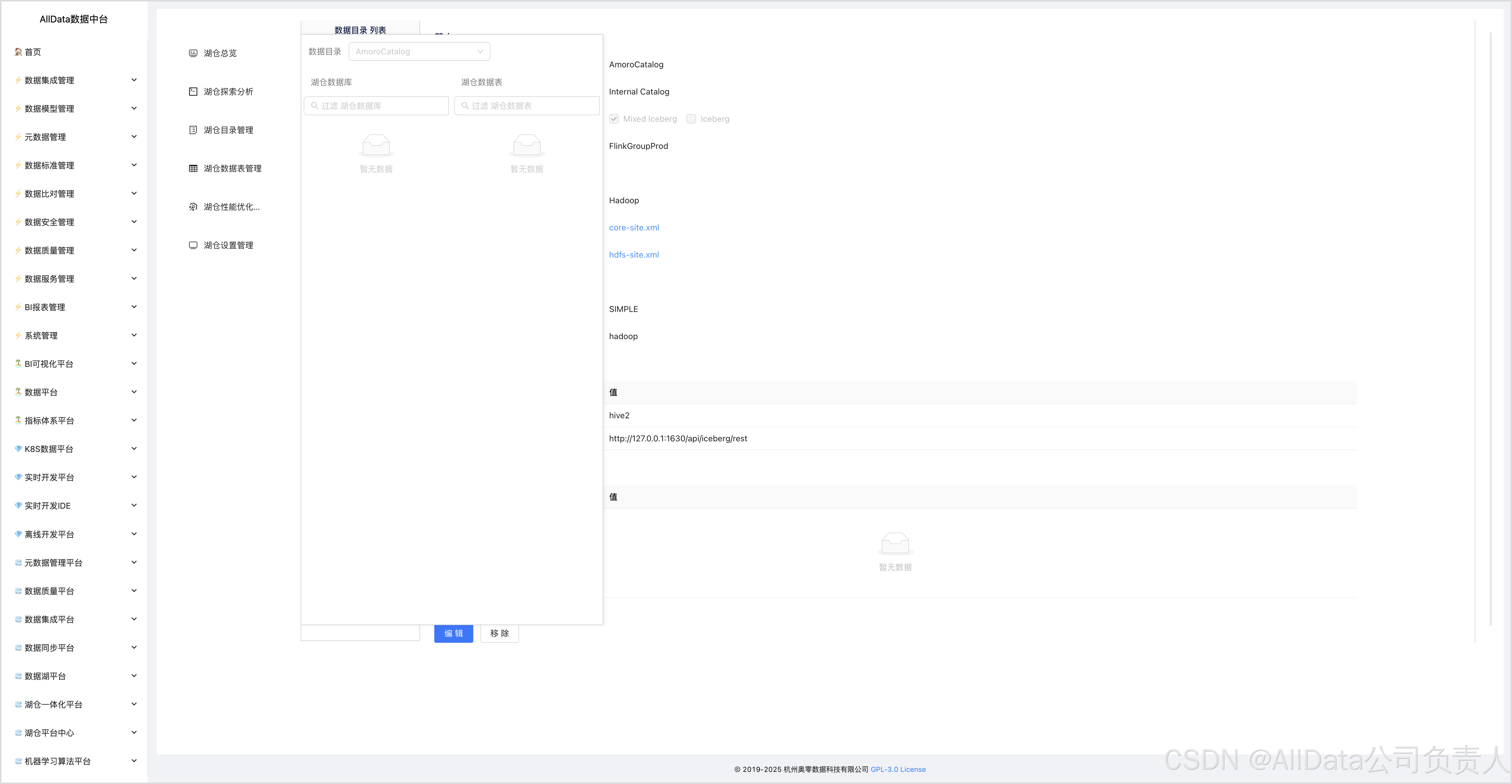
4.10 湖仓目录管理
4.11 新建内外部数据目录
4.12 湖仓数据表管理
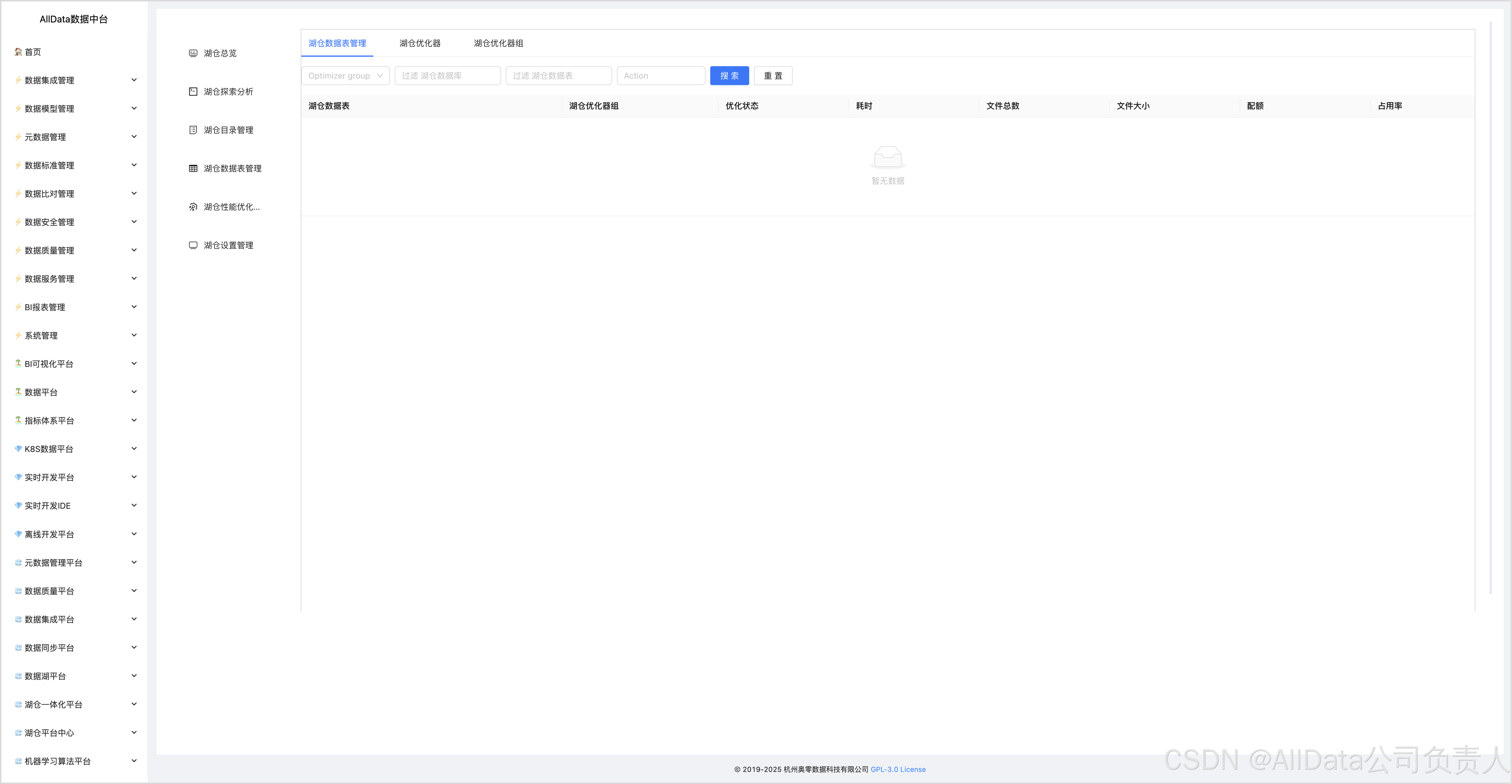
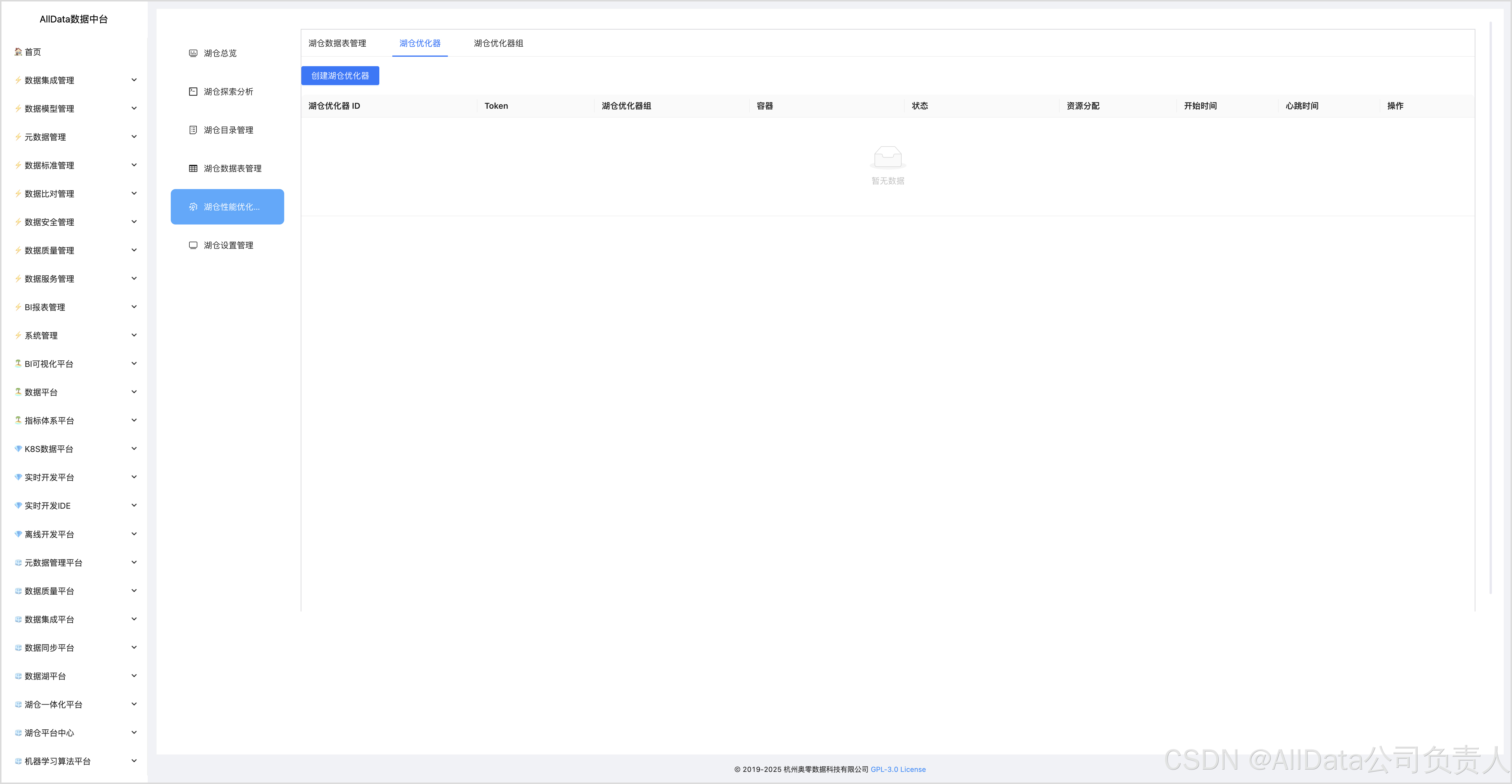
4.13 湖仓优化器
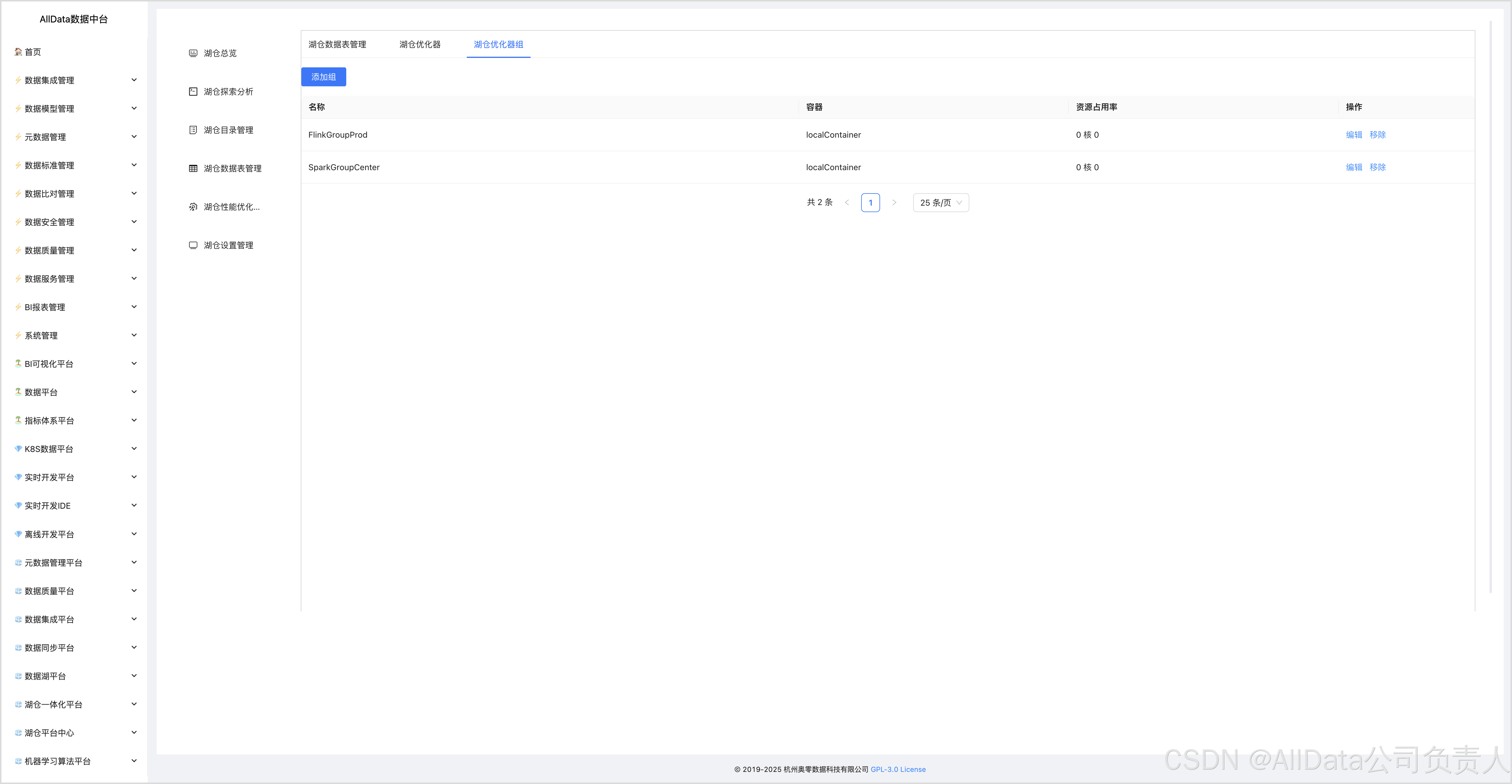
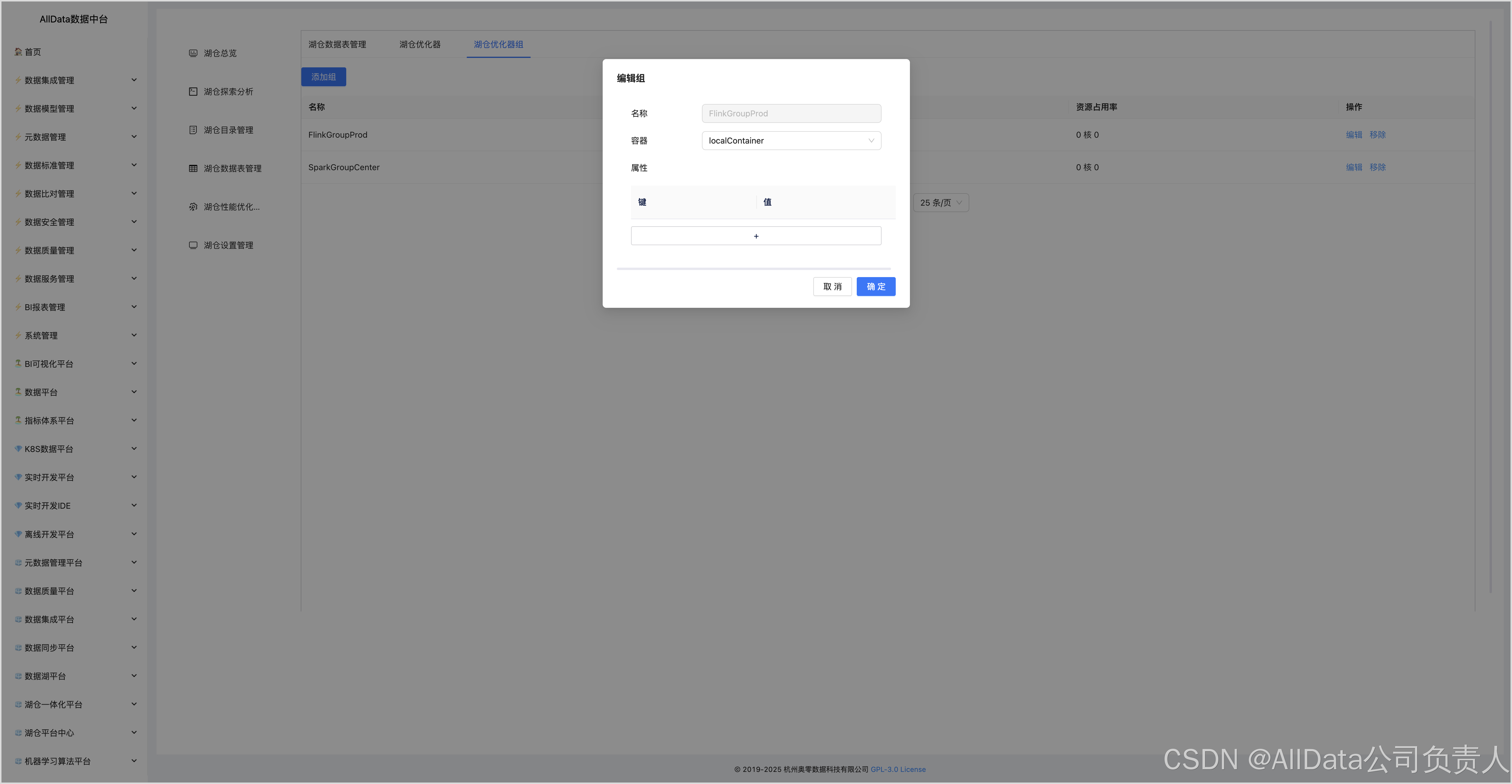
4.14 创建湖仓优化器-FlinkGroupProd
4.15 创建湖仓优化器-SparkGroupCente
4.16 湖仓优化器组
4.17 系统设置
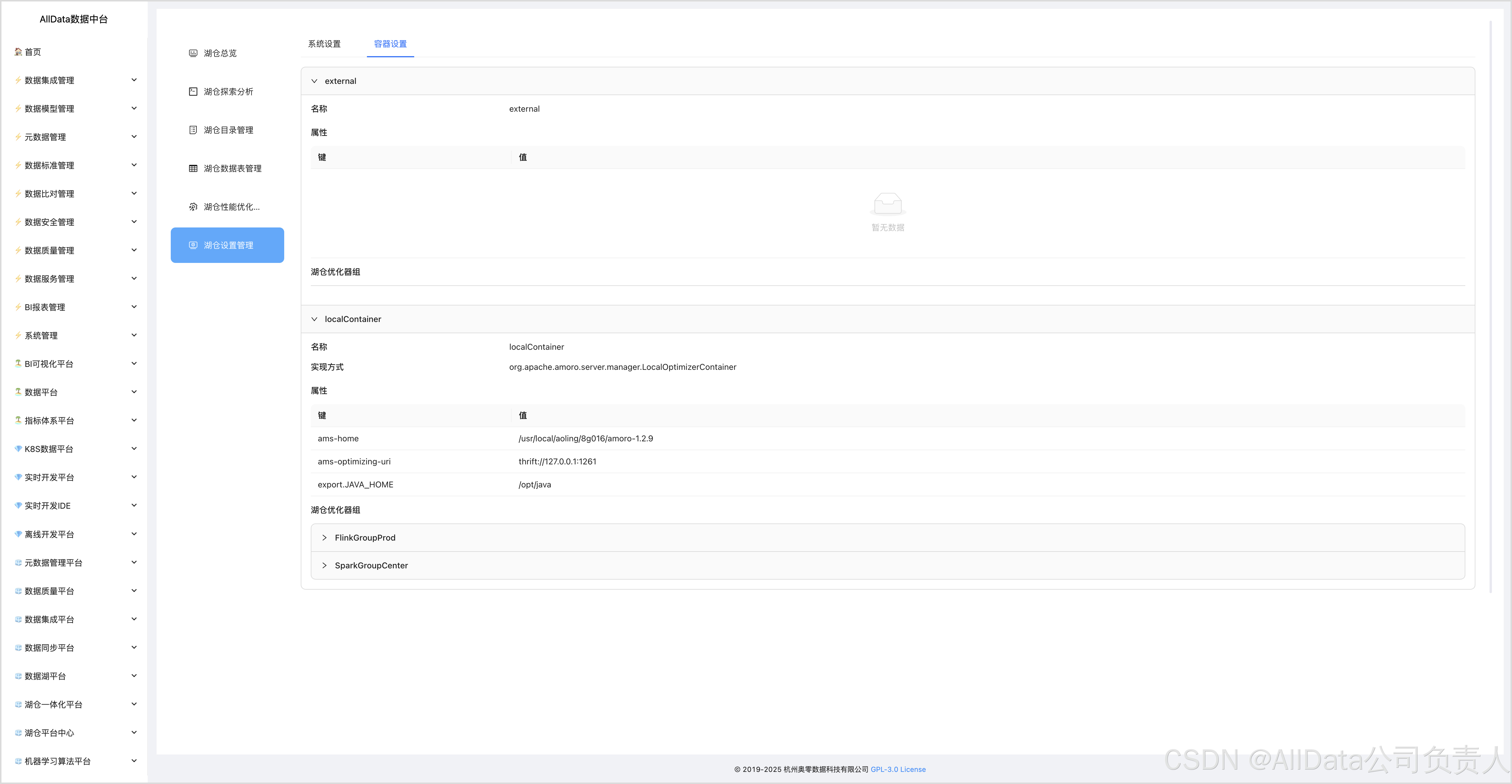
4.18 容器设置

5.1 依赖下载失败
🔹原因:Maven中央仓库或私有仓库不可达。
🔹解决:检查网络连接或配置代理。手动下载依赖并安装到本地仓库(mvn install:install-file)。
5.2 参数用例失败
🔹原因:测试环境未配置或数据不一致。
🔹解决:使用-DskipTests跳过测试。检查测试配置(如src/test/resources下的配置文件)。
5.3 版本冲突
🔹原因:依赖的第三方库版本不兼容。
🔹解决:通过mvn dependency:tree分析依赖树。使用排除冲突依赖。
5.4 内存不足
🔹现象:构建过程中出现OutOfMemoryError。
🔹解决:增加Maven内存:export MAVEN_OPTS=“-Xmx2g -XX:MaxMetaspaceSize=512m”。



















 1547
1547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











