







目录
2.3 Crawl_product_page_info.py
2.4 Crawl_product_page_info_multi_threads.py
申明:本教程仅供学习研究使用,并不作为任何商业用途,若有任何侵权请联系删除!
最终效果:
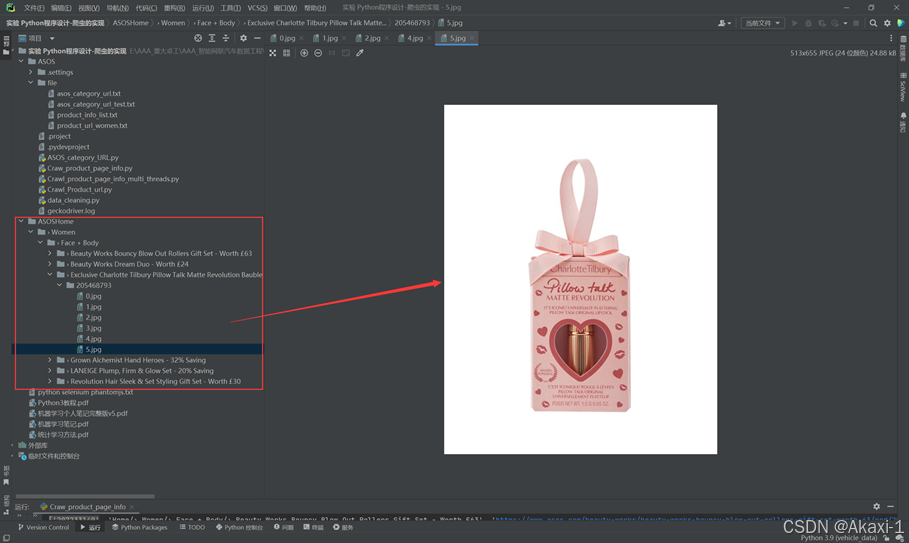
能够实现在本地保存爬取到的图片

能够实现在本地保存爬取到的信息
------------------------全文24585字55图一步一步完成大约耗时1h------------------------
所需软件以及环境:
|
|
|
|
|
| anaconda | pycharm | firefox | edge |
| 创建python环境 | 程序编写与运行 | 程序自动爬取网页 | 使用开发人员工具 |




一、【环境搭建】
1.1 anaconda 创建环境
首先咱得安装anaconda软件,然后使用anaconda软件能够很方便的管理我们的python环境,具体安装教程参考:
【2024年最新】Anaconda3的安装配置及使用教程(超详细),从零基础入门到精通,看完这一篇就够了(附安装包)-优快云博客
然后打开anaconda的navigator软件,创建一个名叫【vehicledata】(任何你喜欢的名字都可以)的环境,用于之后实现实验的Python环境
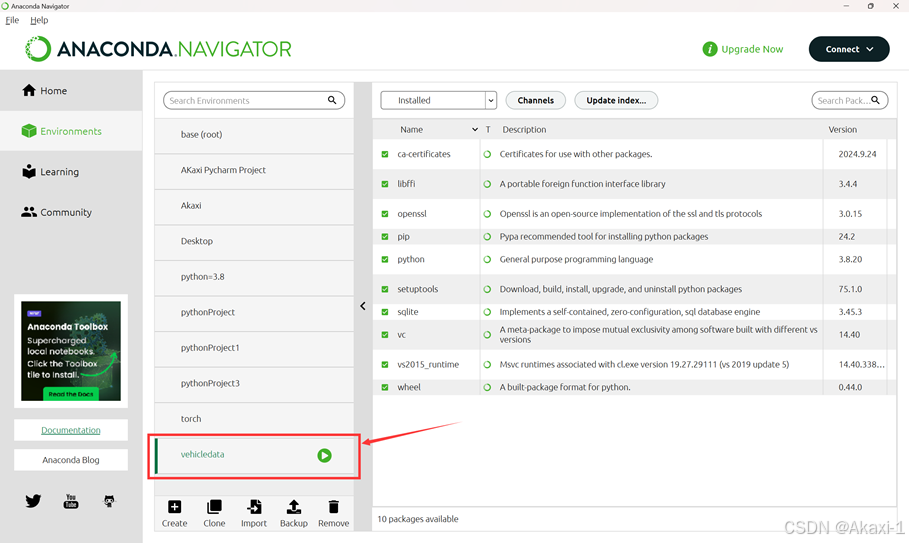
指定python环境版本为3.8
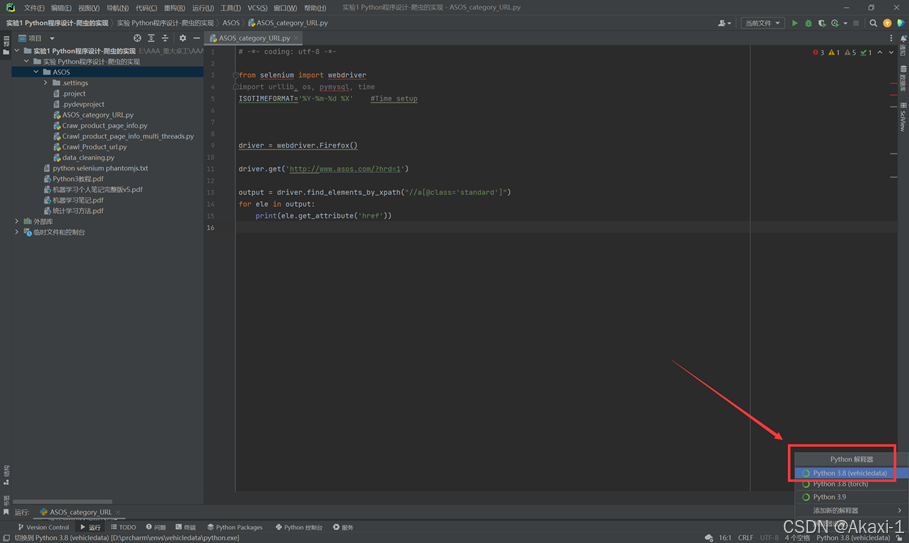
然后打开pycharm,右下角设置python解释器环境为刚刚创建的vehilcledata环境
1.2 Selenium 包安装
由于网页爬取需要使用selenium包,所以在anaconda中搜索selenium包并且下载(注意这里咱使用最新的4.9.1版本的selenium包)
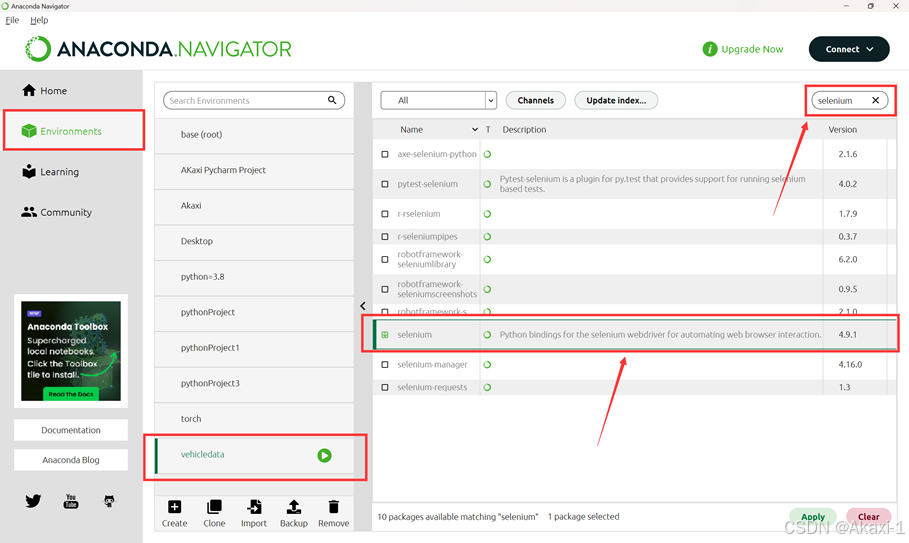
如果需要使用mysql数据库,则需要下载pymysql包
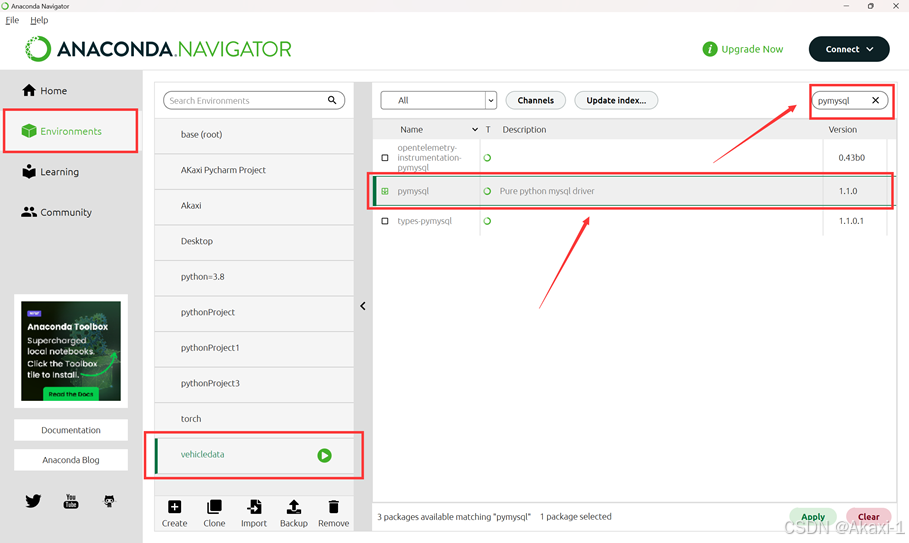
附:如果你想要指定下载selenium==3.8版本的包,可以在anaconda prompt输入指令:
【指令】conda env list # 列出你创建的所有conda环境
【指令】conda activate <你创建的环境> # 激活环境 我的指令就是 conda activate vehicledata
【指令】pip install selenium==3.8.0 -i https://pypi.tuna.tsinghua.edu.cn/simple # 使用pip工具安装3.8版本的selenium包,用的清华源
【指令】pip show selenium # 看看安装成功没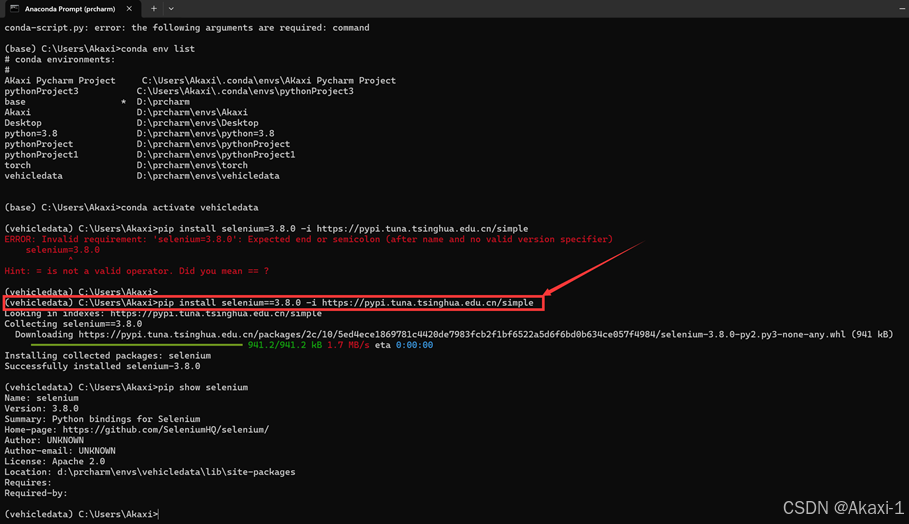
1.3 geckodrver 驱动安装
【驱动下载github链接】https://github.com/mozilla/geckodriver/releases/tag/v0.35.0
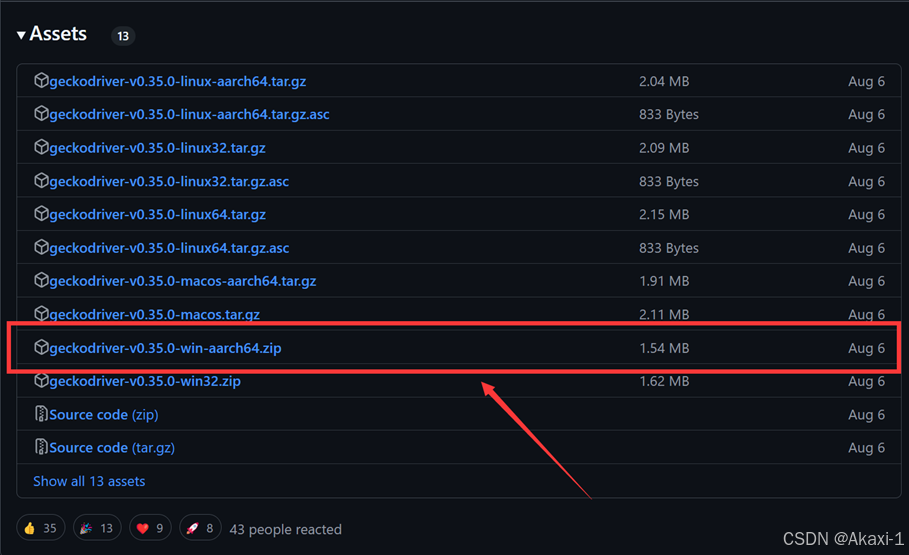
从github下载对应自己电脑系统的压缩包,访问网页可能需要梯子哈~
下载完成后解压可以看到这个exe可执行程序
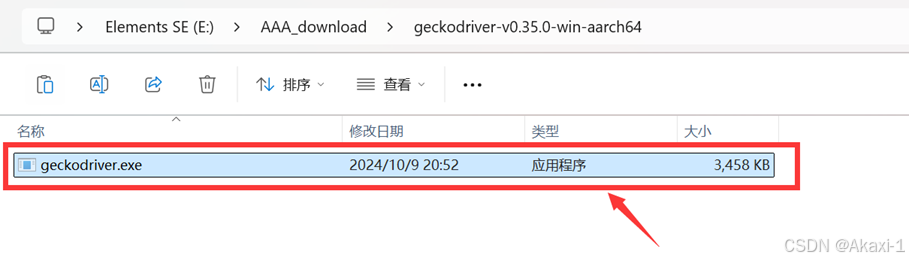
将解压后的可执行程序放在我们1.1创建的python环境文件夹下面,这里我就是放在vehicledata环境,可以使用指令查看conda环境以及位置:
【指令】conda env list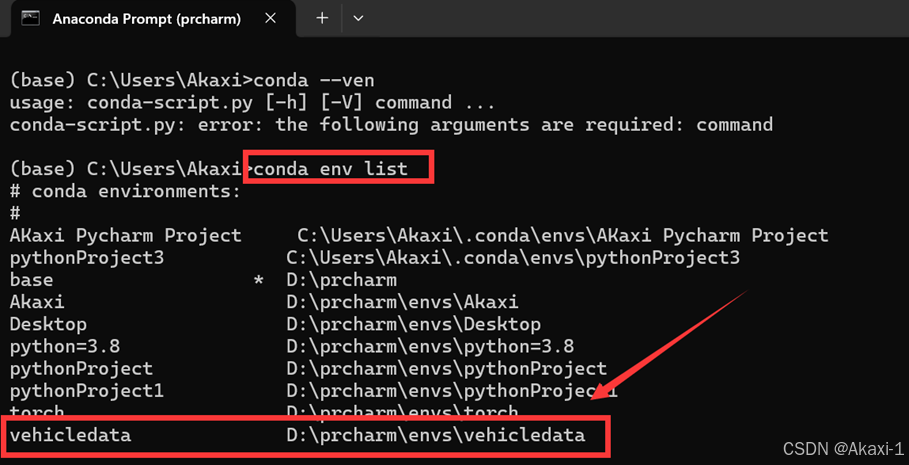
可以看到我的vehicledata环境所在文件目录为:D:\prcharm\envs\vehicledata,按照目录找到对应的文件夹
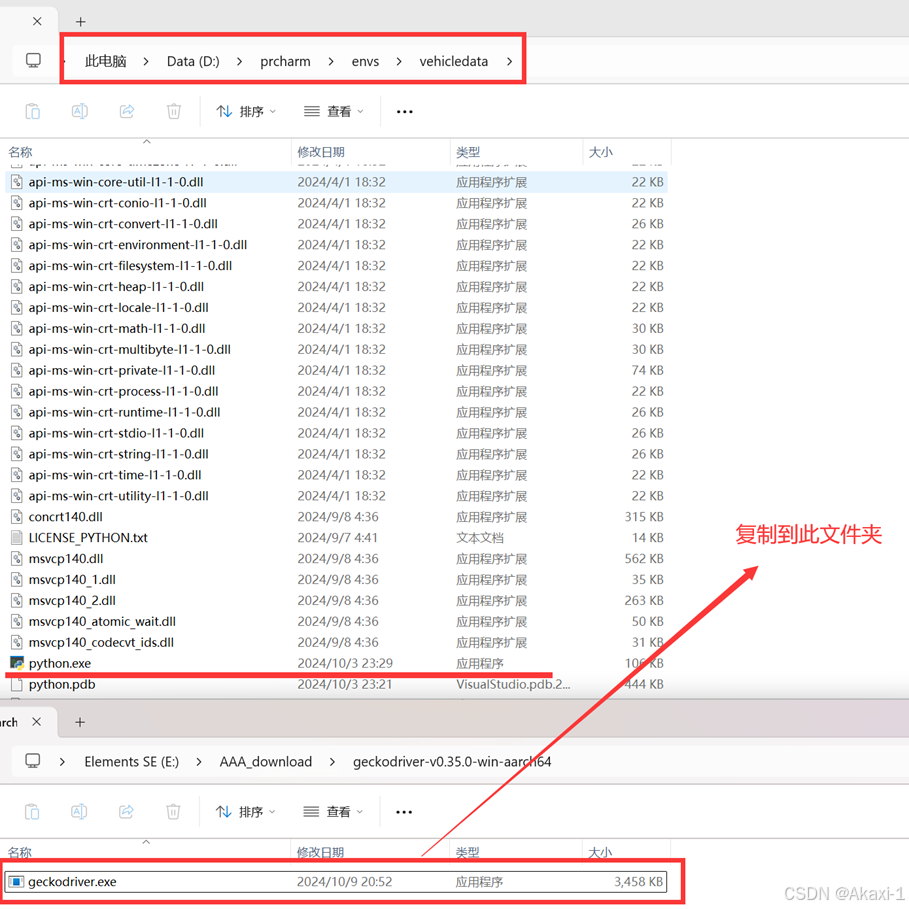
将我们解压后的文件放在vehicledata文件夹下面,这样我们的环境搭建就完成啦!
二、【爬取网页】
目标爬取网站:ASOS
----------------------------------------------------------------------------------------
思路以及代码解释:
1.ASOS_category_URL.py ----爬取网页中的所有产品种类URL(例如爬取shoes类url、skirts类url等)
2.Crawl_Product_url.py ----爬取网页中每类产品下的每一个具体产品(例如爬取shoes类下的各种url等)
3.Crawl_product_page_info.py ----爬取网页中每一个产品具体信息(例如爬取产品价格、大小等)
4.Crawl_product_page_info_multi_threads.py ----多线程爬取网页中每一个产品具体信息(例如爬取产品价格、大小等)
2.1 ASOS_category_URL.py
2.1.1 流程实现 - 获取产品种类URL
我们想要获取每一个种类产品的class属性值,可以这样:
在edge浏览器打开ASOS网页https://www.asos.com/women/
然后按F12键打开【开发人员工具】,或者在edge浏览器右上角三个点-更多工具找到开发人员工具,然后:
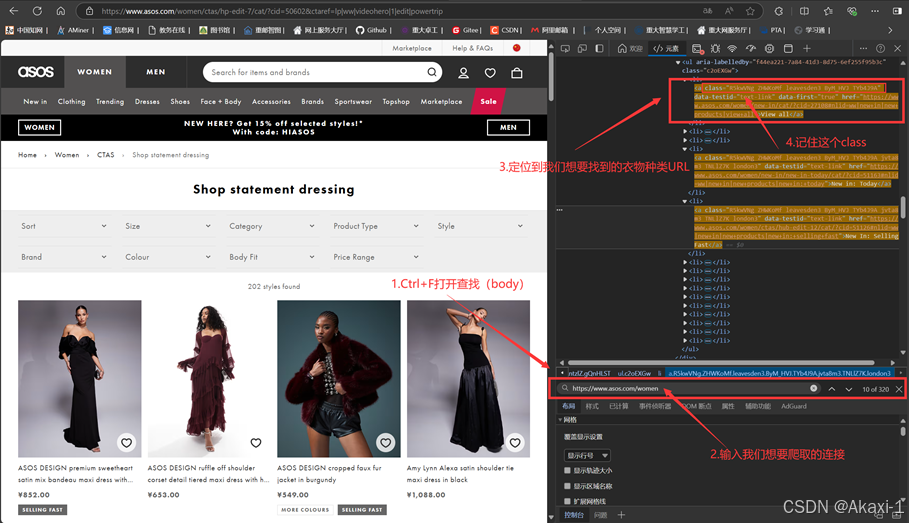
这些就是各种服饰的种类连接处:
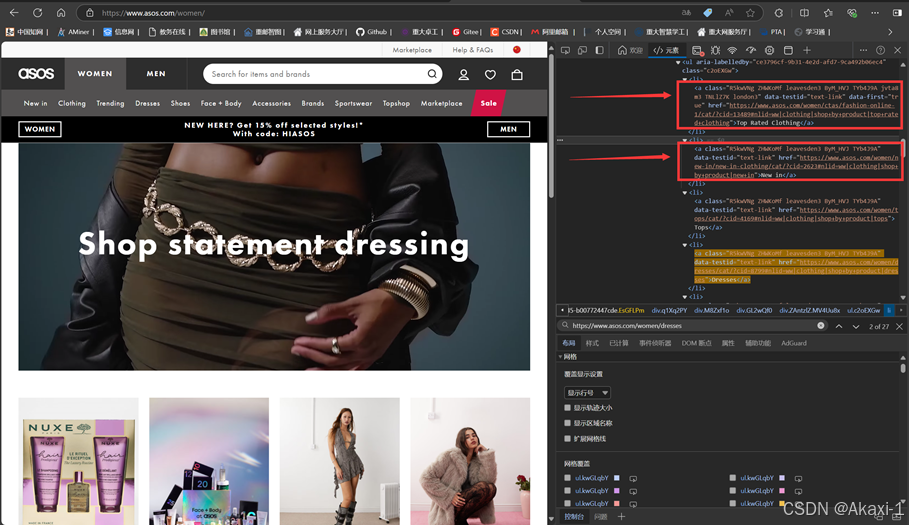
找到class属性后面的这一串特殊字母:
<a class="R5kwVNg ZHWKoMf leavesden3 ByM_HVJ TYb4J9A">将class后面的字符串在代码中进行更改:
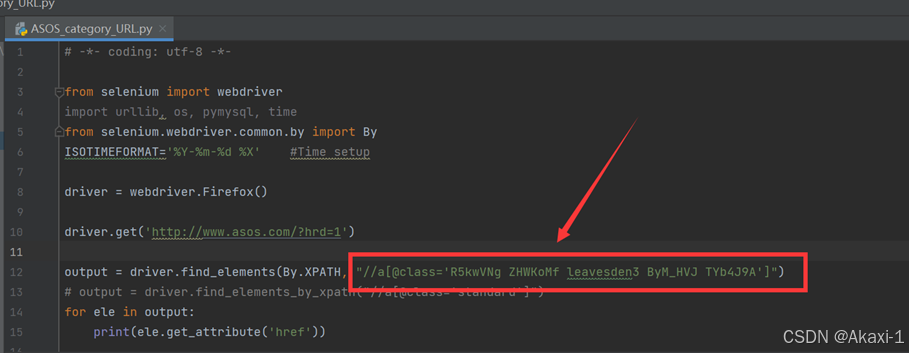
更改完后运行:
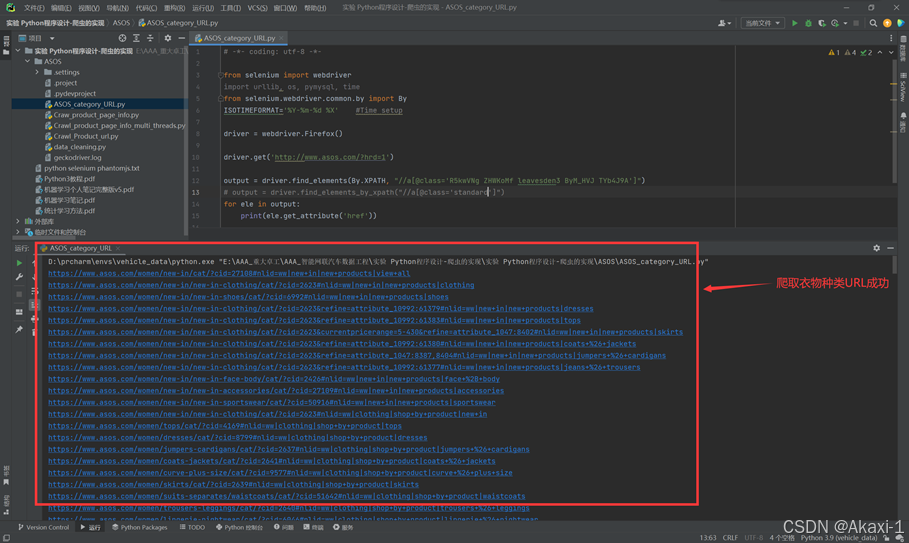
即可看到脚本自动打开火狐浏览器,爬取完网页后,打印各类衣物种类链接,将链接复制,新建一个txt文件,粘贴保存一下衣服种类链接:
保存名为asos_category_url.txt
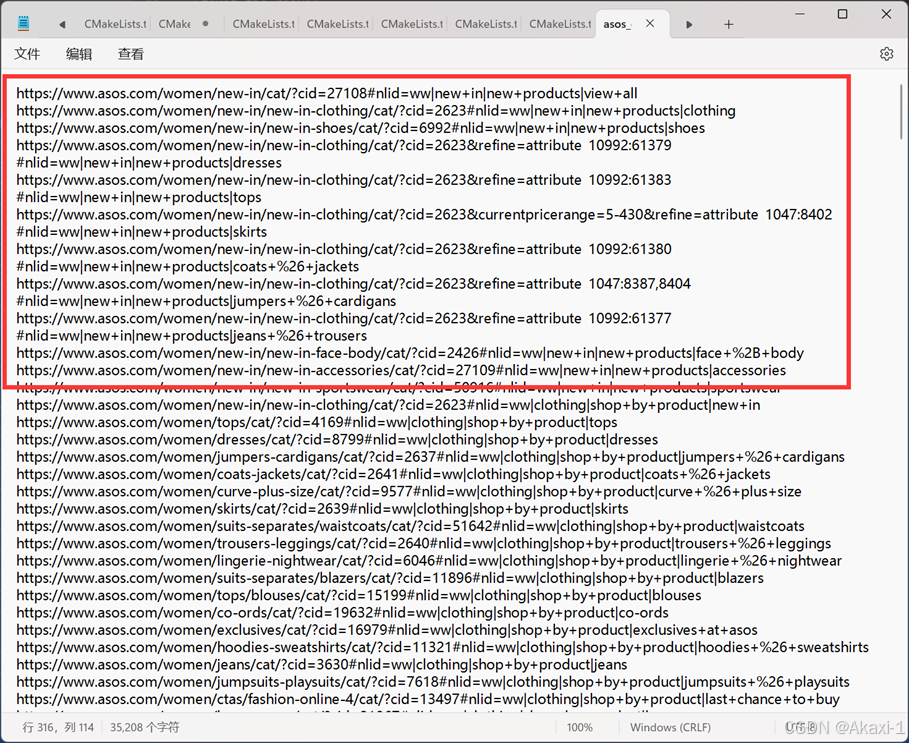
这个txt文本就是咱各类产品的url,成功~~
2.1.2 完整代码
# -*- coding: utf-8 -*-
from selenium import webdriver
import urllib, os, pymysql, time
from selenium.webdriver.common.by import By # 4.0 以上的selenium版本需要引入By
ISOTIMEFORMAT='%Y-%m-%d %X' #Time setup
driver = webdriver.Firefox() # 这里我们是用Firefox火狐浏览器 -- 如果你想用chrome修改一下即可,但是1.3节对应的驱动需要修改
driver.get('http://www.asos.com/?hrd=1')
output = driver.find_elements(By.XPATH, "//a[@class='R5kwVNg ZHWKoMf leavesden3 ByM_HVJ TYb4J9A']")
# output = driver.find_elements_by_xpath("//a[@class='standard']")
for ele in output:
print(ele.get_attribute('href'))2.2 Crawl_Product_url.py
2.2.1 流程实现 - 获取每种产品URL
再新建一个product_url_women.txt文件,用来保存运行后的具体产品文件url
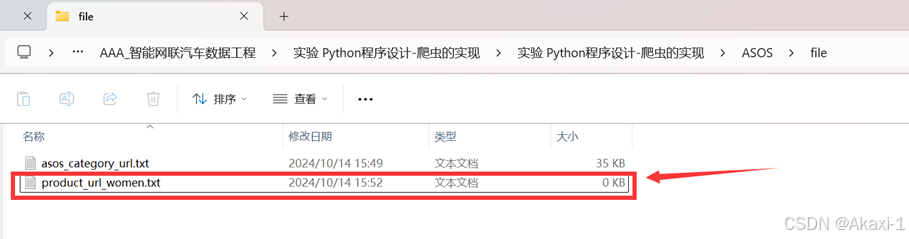
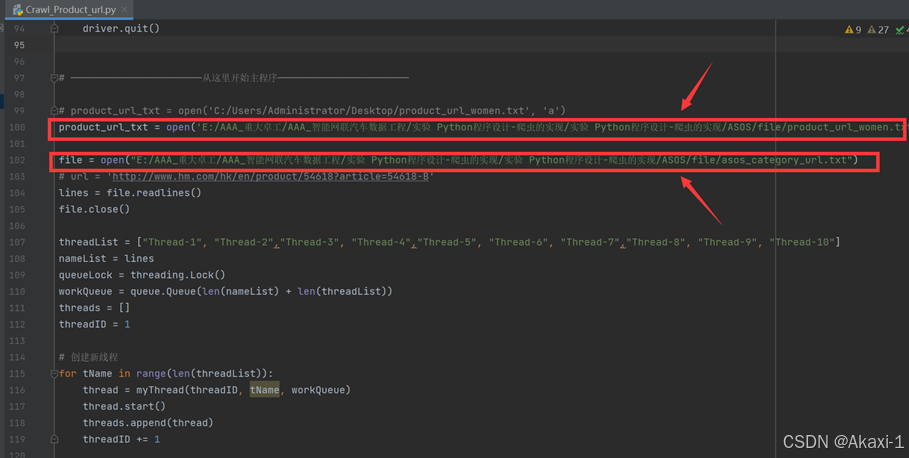
然后对应修改这里的两处文件路径(注意文件路径)
同理进入对应的某一个种类界面,期望爬取这类产品下面的所有具体产品url
就例如在Women's Latest Clothing, Shoes & Accessories | ASOS这个种类URL下面有具体的产品url等:
https://www.asos.com/topshop/topshop-high-rise-jamie-jeans-in-washed-black/prd/201200253#colourWayId-201200254
https://www.asos.com/topshop/topshop-high-rise-jamie-jeans-in-mid-blue/prd/201878023#colourWayId-201878039
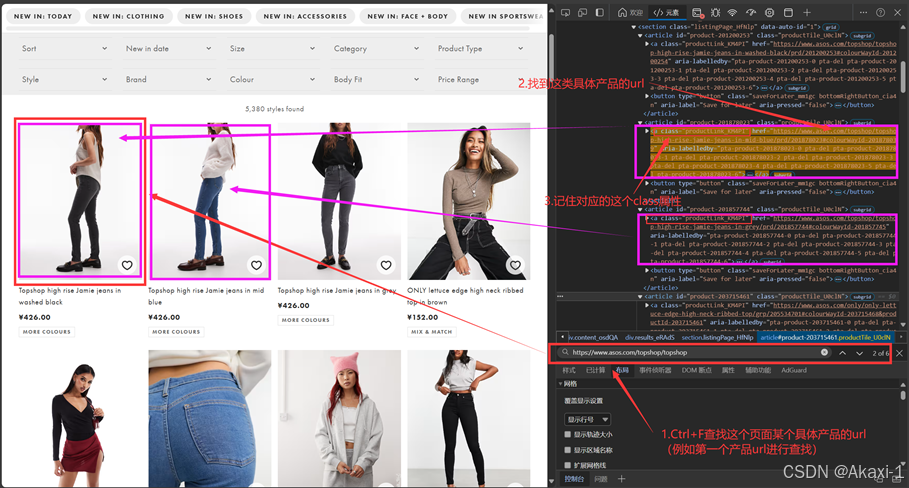
按照之前的步骤进行操作,我们拿到class后面的字符串
class= “productLink_KM4PI"将该字符串修改进代码中
点击运行程序:
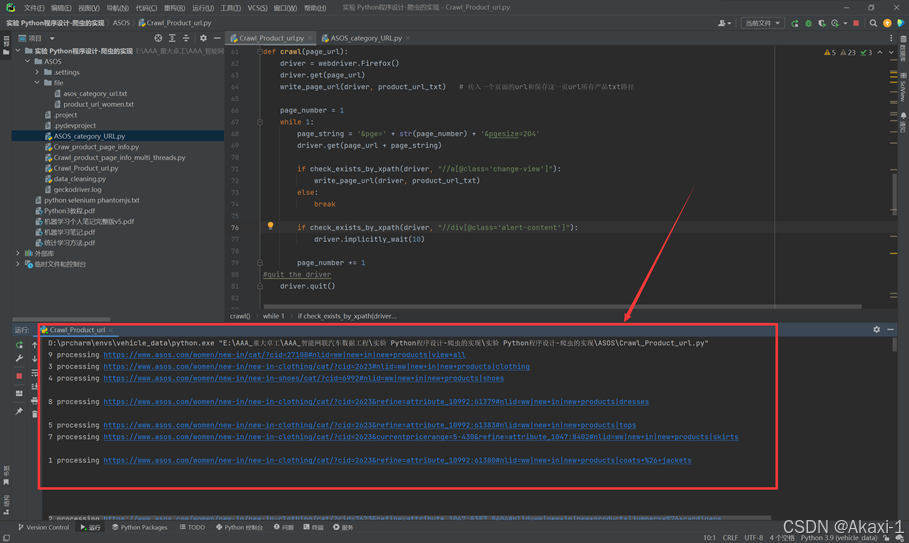
即可开启多线程运行程序
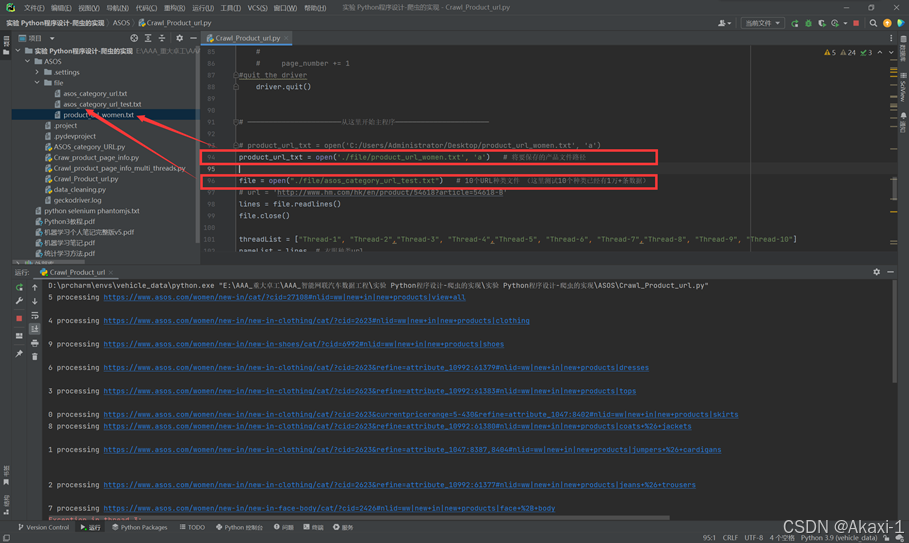
我们这里截取asos_category_url.txt文件里面的10条衣服种类链接名为asos_category_url_test.txt进行测试
经过测试,如果加入种类产品翻页功能,有大概1万+条数据,故我们删除翻页功能(如需保留翻页功能,取消对应代码注释即可,这里是方便测试运行),10类衣服下每种类产品仅爬取一页产品,这样最后大概有700条数据
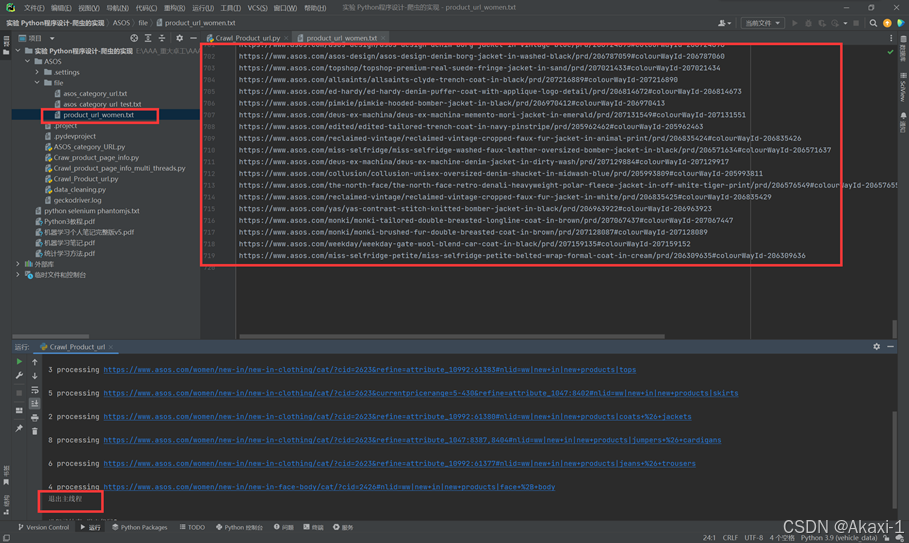
运行程序成功!打开product_url_women.txt即可看到爬取的网页产品链接~撒花~~
2.2.2 完整代码
'''
Created on 2016年10月11日
Crawl product url.
Entrence: the 1st layer of categories.
@author: Administrator
'''
from selenium.webdriver.support.ui import WebDriverWait
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.common.exceptions import NoSuchElementException
# from turtle import __func_body 没用到给取消了
import os, time, queue, urllib
import threading
from selenium.webdriver.common.by import By # 新增
# from selenium.webdriver.firefox.options import Options
ISOTIMEFORMAT='%Y-%m-%d %X' #Time setup
# options = Options()
# options.set_preference("dom.security.https_state", False)
# driver = webdriver.Firefox(options=options)
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, q):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.q = q
def run(self):
# print ("开启线程:" + self.name)
process_data(self.name, self.q) # 线程函数
# print ("退出线程:" + self.name)
def process_data(threadName, q):
while not exitFlag:
queueLock.acquire()
if not workQueue.empty():
data = q.get() # 这里传入衣服种类url
queueLock.release()
print ("%s processing %s" % (threadName, data))
crawl(data) # 这里爬取函数
else:
queueLock.release()
time.sleep(1)
def write_page_url(driver, product_url_txt):
product_list = driver.find_elements(By.XPATH, "//a[@class='productLink_KM4PI']") # 期望爬取具体的所有产品url链接 少了一个下划线
for ele_product_list in product_list:
# 测试打印输出
# print(ele_product_list.get_attribute("href"))
product_url_txt.write(ele_product_list.get_attribute("href") + "\n")
def check_exists_by_xpath(driver, xpath):
try:
driver.find_element(By.XPATH, xpath) # 修改版本兼容代码
except NoSuchElementException:
return False
return True
#start of the main function, the input is the category page url
def crawl(page_url):
driver = webdriver.Firefox()
driver.get(page_url)
write_page_url(driver, product_url_txt) # 传入一个页面的url和保存这一页url所有产品txt路径
# 取消翻页功能 -- 如需使用取消注释即可
# page_number = 1
# while 1:
# page_string = '&pge=' + str(page_number) + '&pgesize=720'
# driver.get(page_url + page_string)
#
# # if check_exists_by_xpath(driver, "//a[@class='change-view']"):
# write_page_url(driver, product_url_txt)
# # else:
# # break
#
# if check_exists_by_xpath(driver, "//a[@class='loadButton_wWQ3F']"): # 修改
# driver.implicitly_wait(10)
#
# page_number += 1
#quit the driver
driver.quit()
# ——————————————————————从这里开始主程序——————————————————————
# product_url_txt = open('C:/Users/Administrator/Desktop/product_url_women.txt', 'a')
product_url_txt = open('./file/product_url_women.txt', 'a') # 将要保存的产品文件路径
file = open("./file/asos_category_url_test.txt") # 10个URL种类文件 (这里测试10个种类已经有1万+条数据)
# url = 'http://www.hm.com/hk/en/product/54618?article=54618-B'
lines = file.readlines()
file.close()
threadList = ["Thread-1", "Thread-2","Thread-3", "Thread-4","Thread-5", "Thread-6", "Thread-7","Thread-8", "Thread-9", "Thread-10"]
nameList = lines # 衣服种类url
queueLock = threading.Lock()
workQueue = queue.Queue(len(nameList) + len(threadList))
threads = []
threadID = 1
# 创建新线程
for tName in range(len(threadList)):
thread = myThread(threadID, tName, workQueue) # 在这里进入线程
thread.start()
threads.append(thread)
threadID += 1
# 填充队列
queueLock.acquire()
for word in nameList: # 遍历衣服种类url中每一行url
workQueue.put(word)
queueLock.release()
# 等待队列清空
while not workQueue.empty():
pass
# 通知线程是时候退出
exitFlag = 1
# 等待所有线程完成
for t in threads:
t.join()
print ("退出主线程")
product_url_txt.close()2.3 Crawl_product_page_info.py
2.3.1 流程实现 - 获取产品具体信息
2.3.1.1 网页国家切换
点击打开我们爬取到的第一条产品具体信息网页界面:
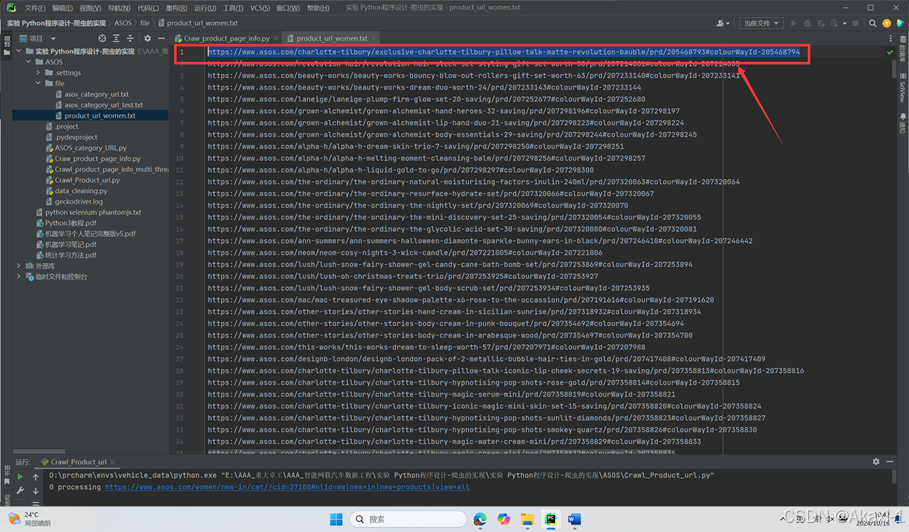
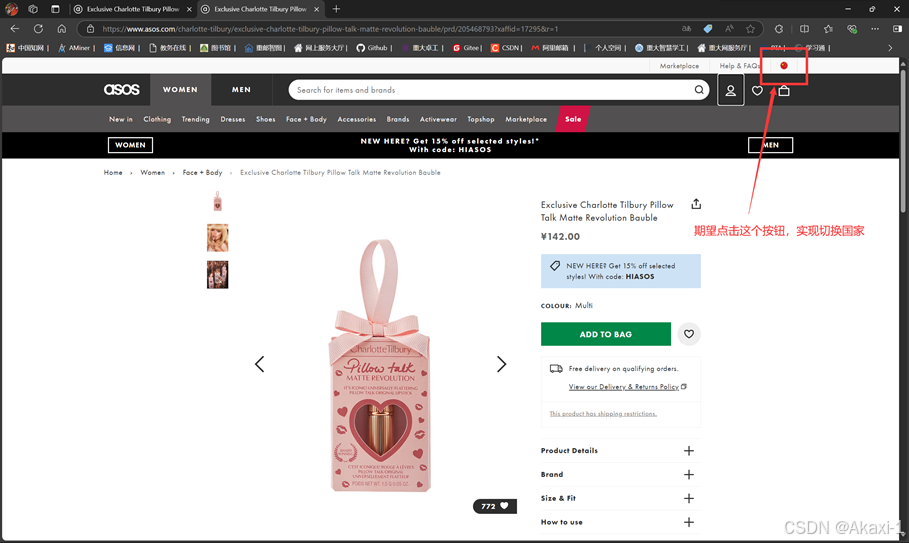
期望实现国家切换,找到右上角的国家图片,右键选择
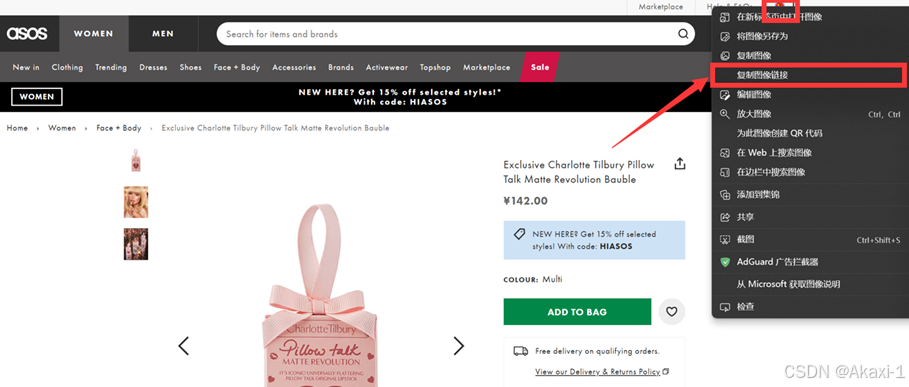
复制图像链接
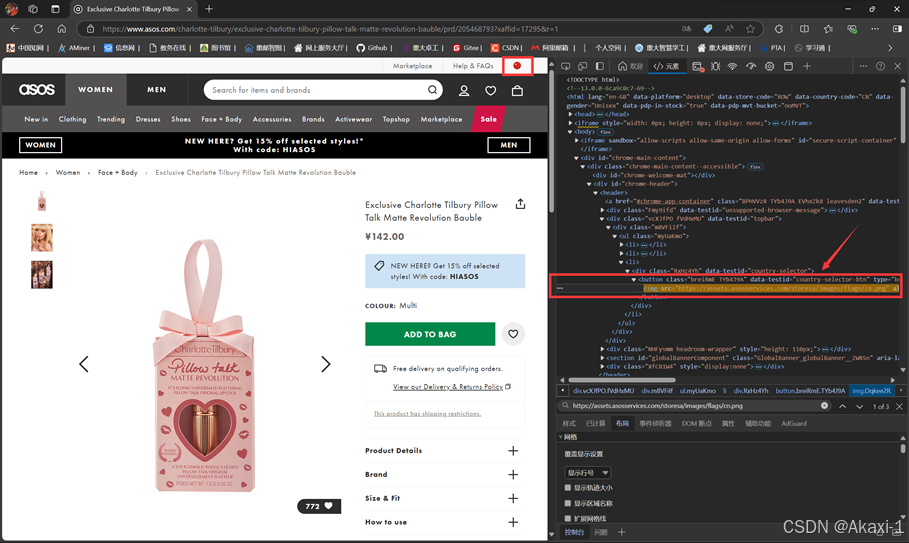
同理打开开发者工具,复制图像链接找到该按钮的所在代码
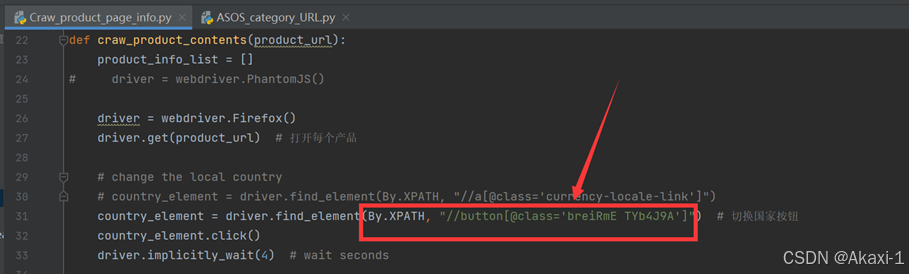
在代码中更新button元素
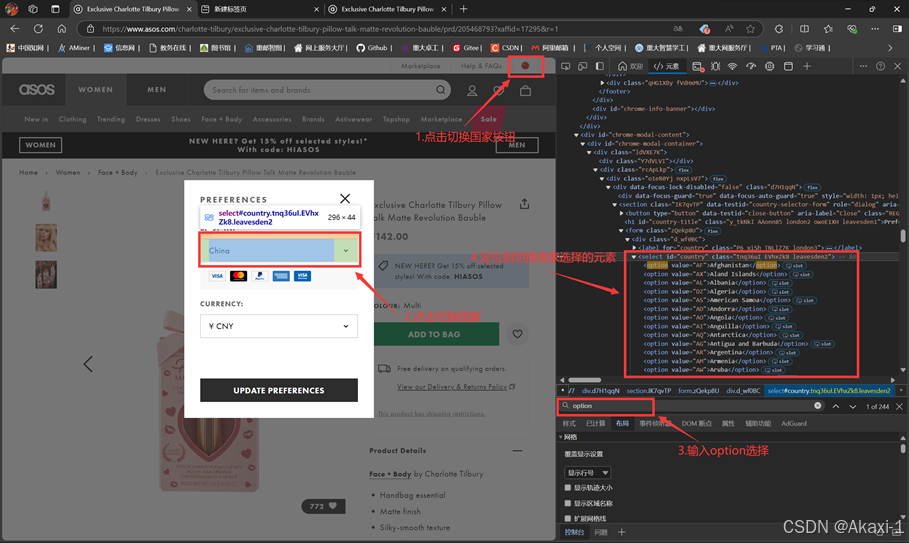
然后我们如图定位国家选项的option元素位置
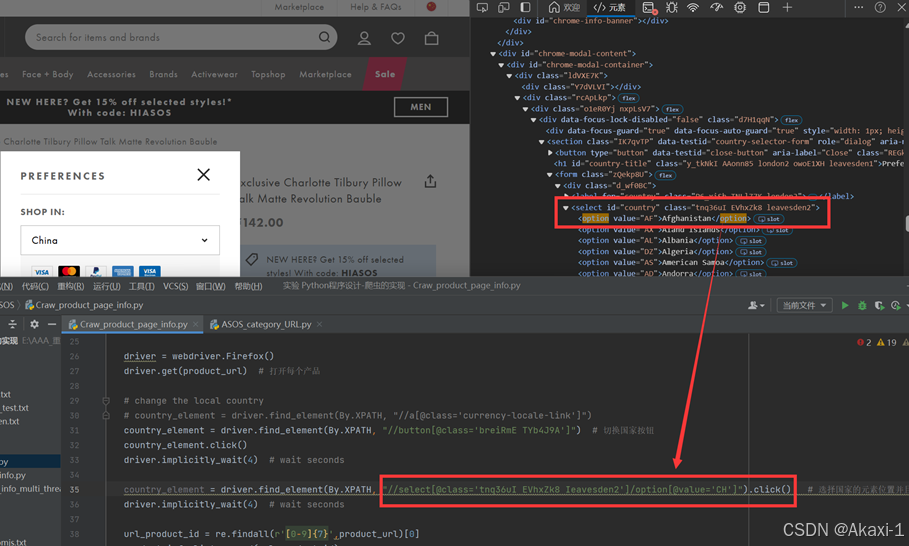
然后对应修改代码
2.3.1.2 获取产品id信息
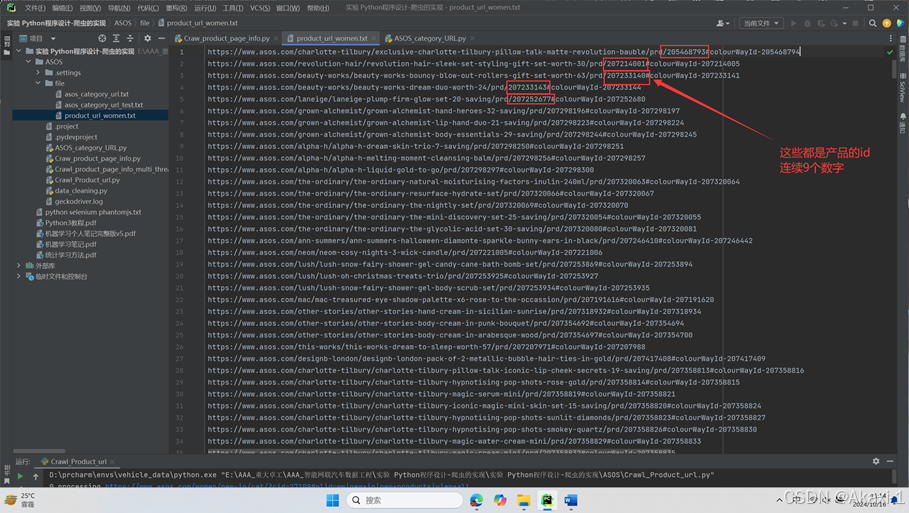
接下来期望提取产品的id信息,在种类url中有连续的9位数字,这即是产品的id
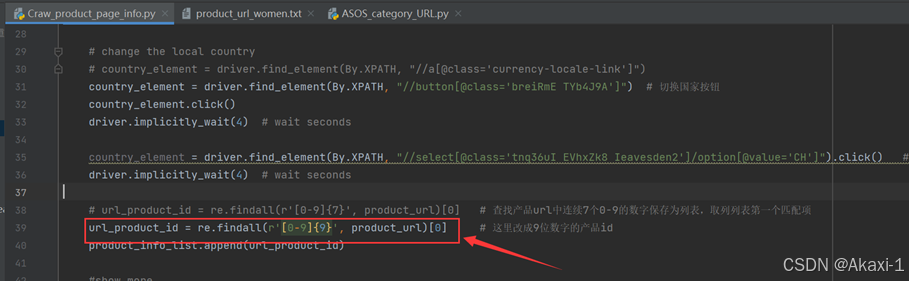
改一下代码
2.3.1.3 获取导航信息
然后是面包屑导航(类似xx>xx>xx这种导航)
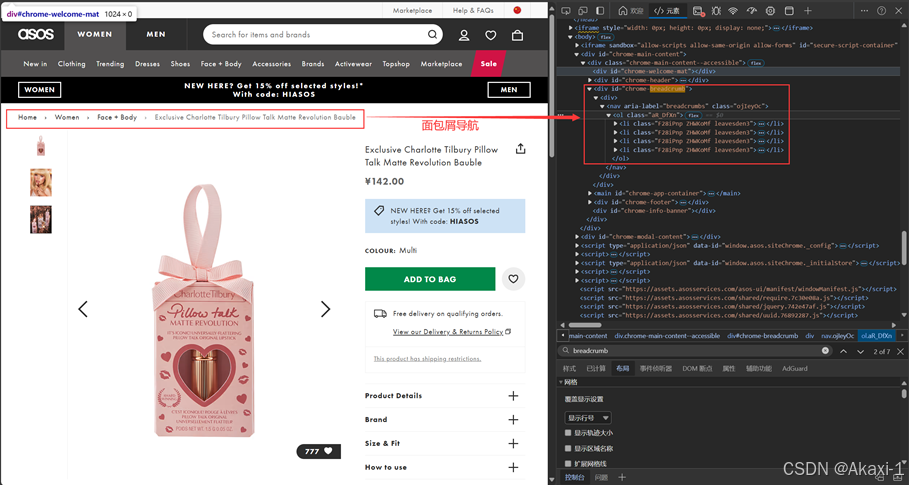
同理输入chrome-breadcrumb查找面包屑导航,记住class信息修改对应代码
2.3.1.4 获取代码信息
然后是产品代码
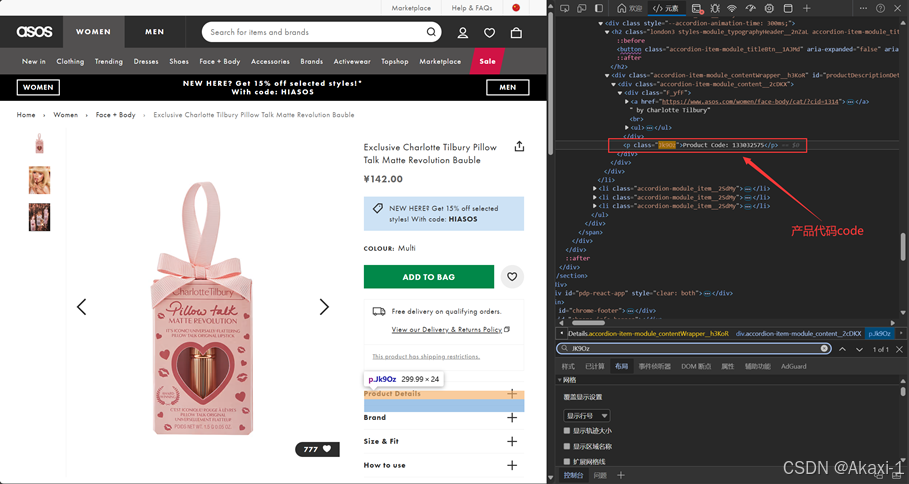
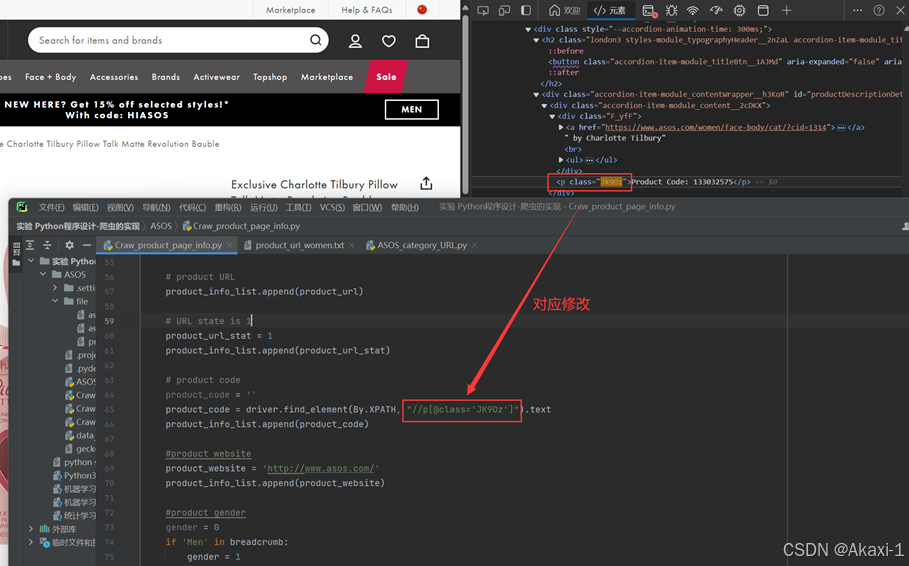
对应修改代码
2.3.1.5 获取标题信息
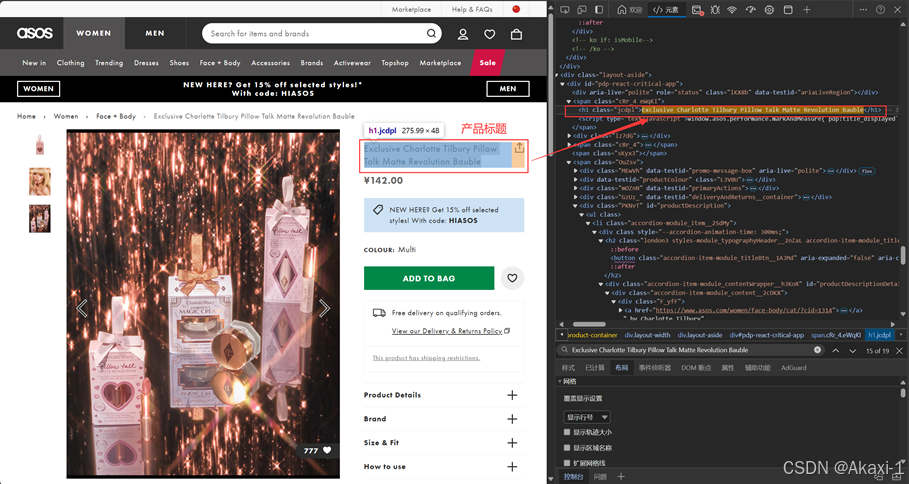
同理输入查找产品的标题,然后记住class=jcdpl,在代码中对应修改
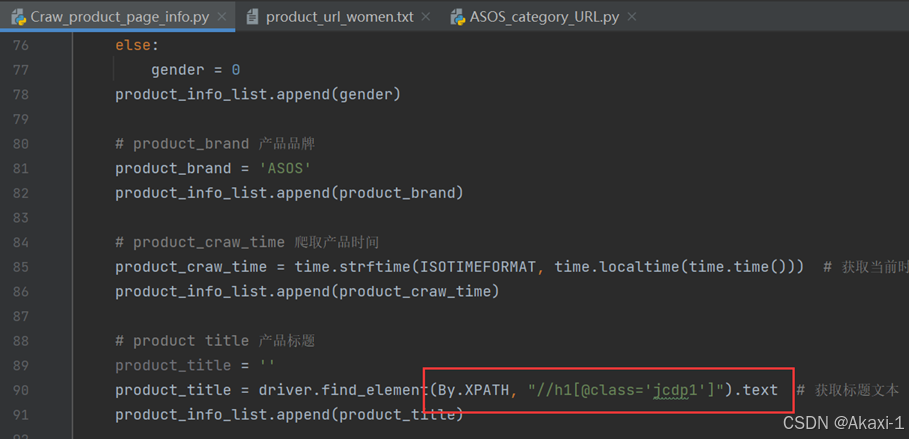
2.3.1.6 获取配送信息
然后是产品的配送:
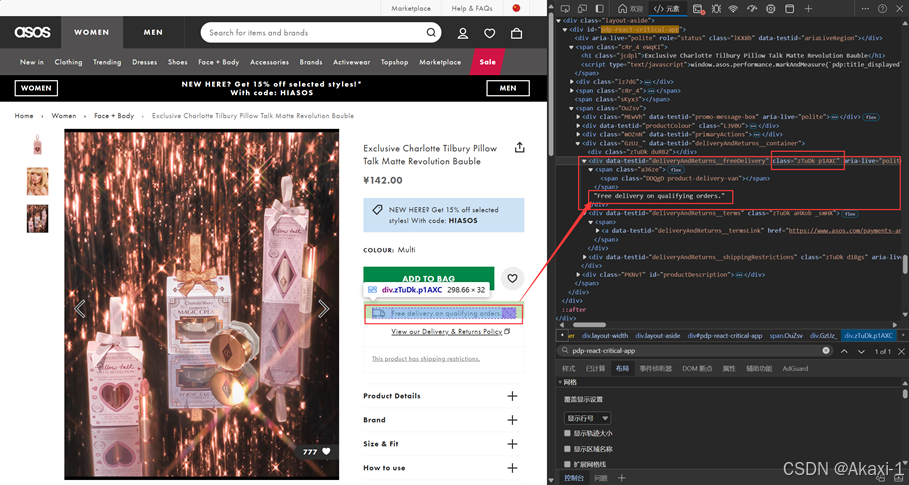
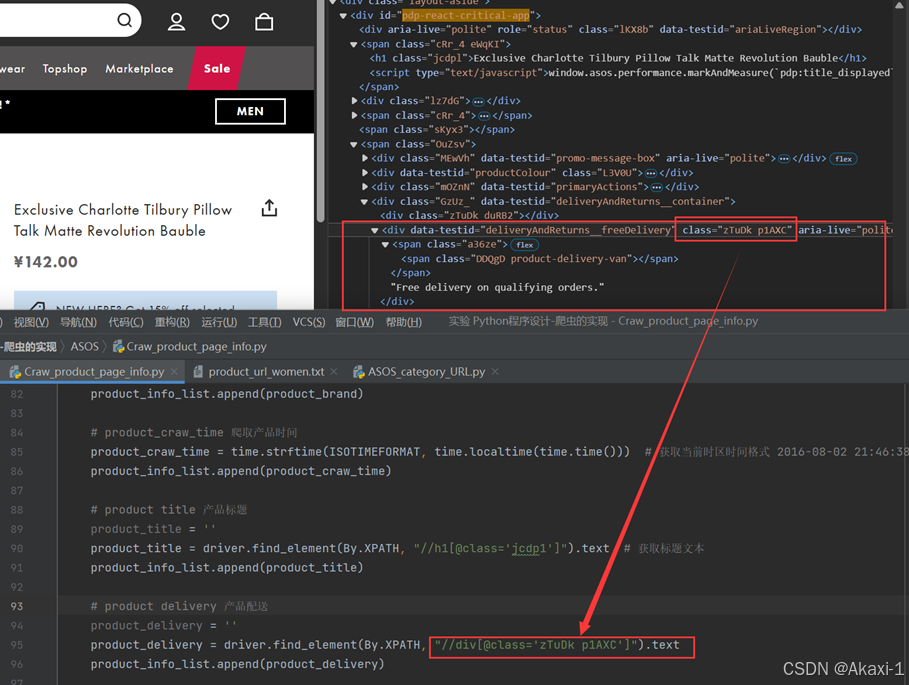
修改对应
2.3.1.7 获取价格信息
然后爬取价格
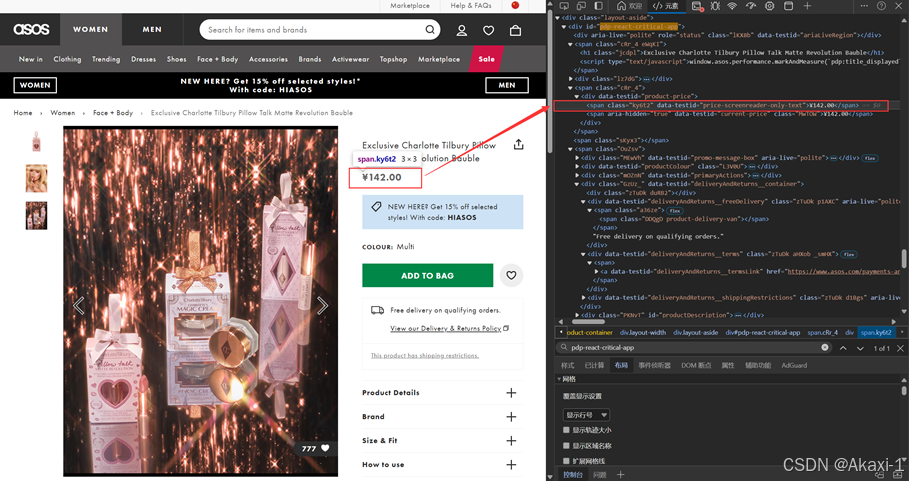
对应修改代码:
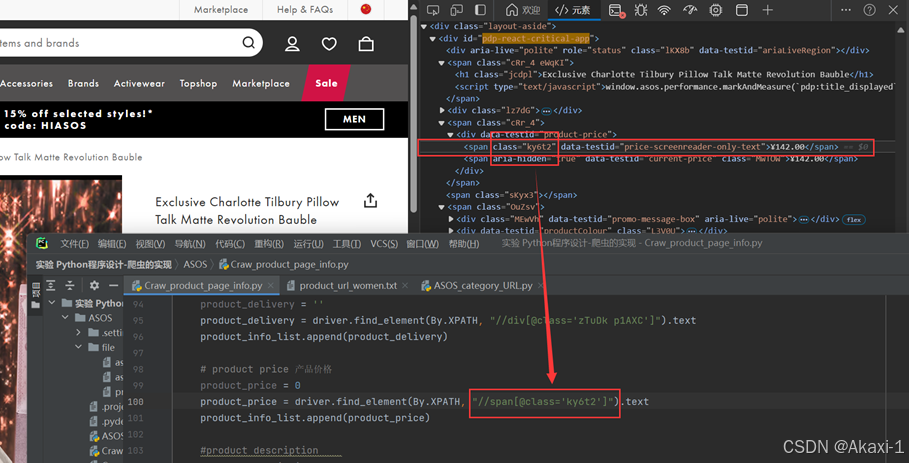
2.3.1.8 获取尺寸信息
爬取产品的可选择大小:
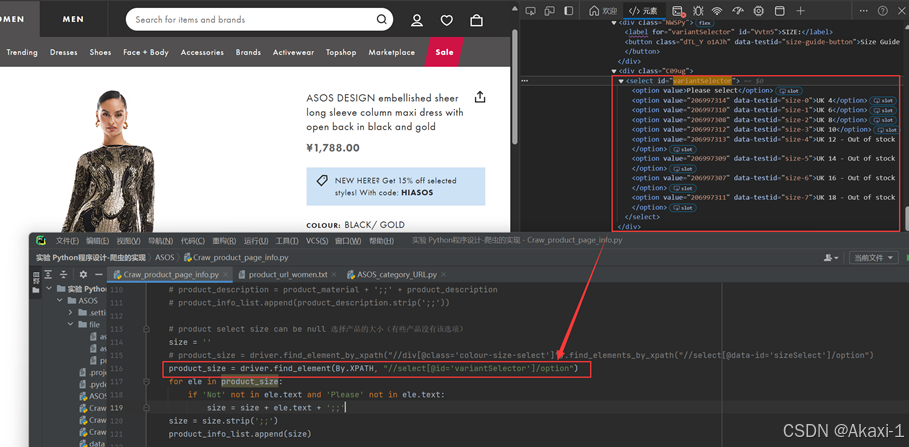
2.3.1.9 获取颜色信息
爬取产品颜色:
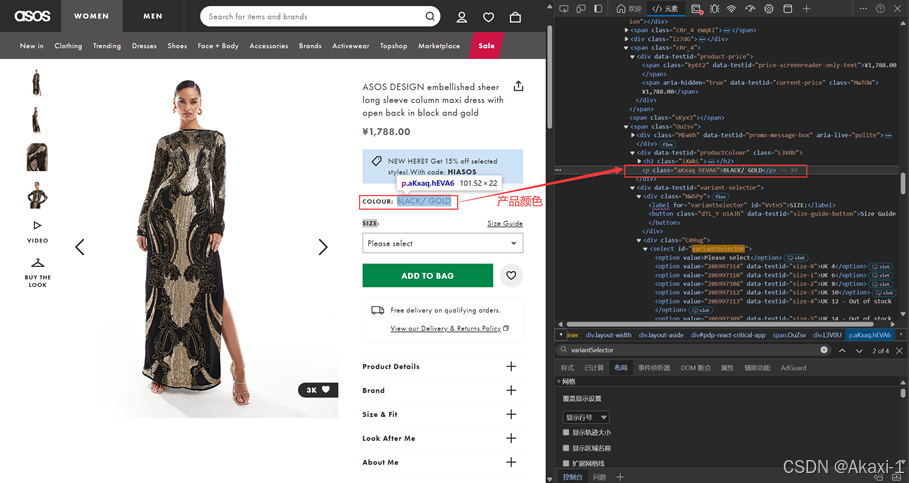
修改代码:
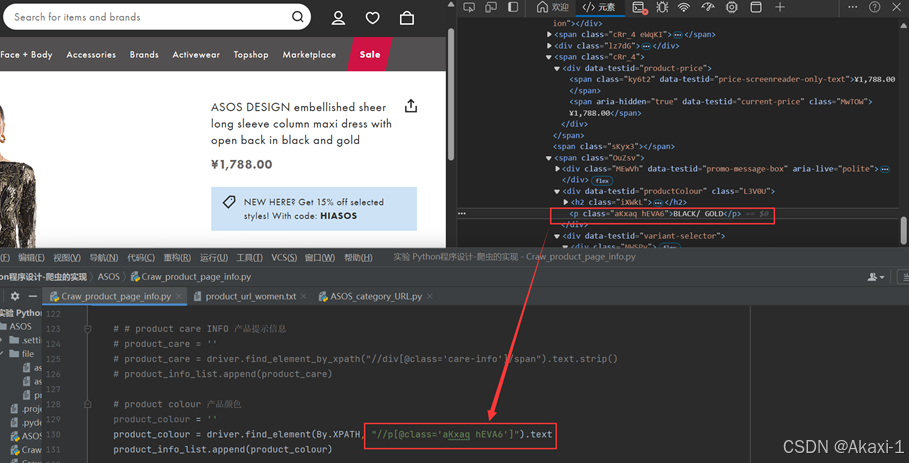
2.3.1.10 获取并保存图片到本地
爬取图片:
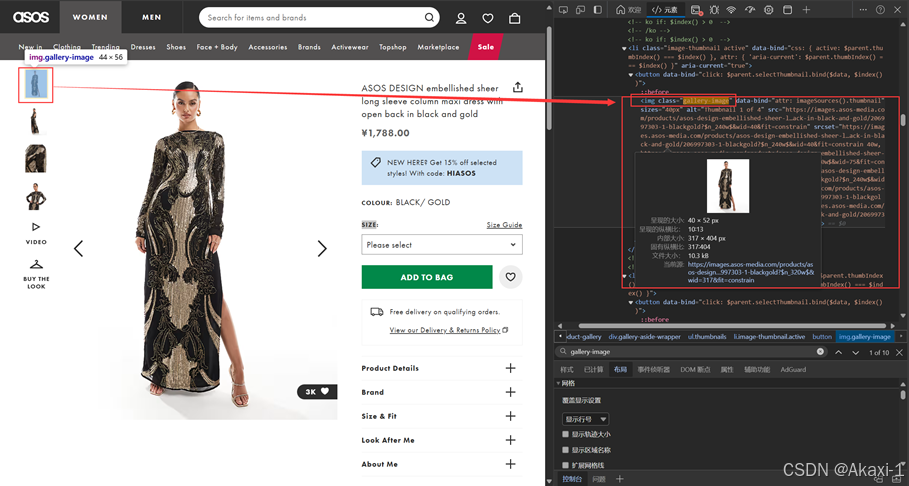
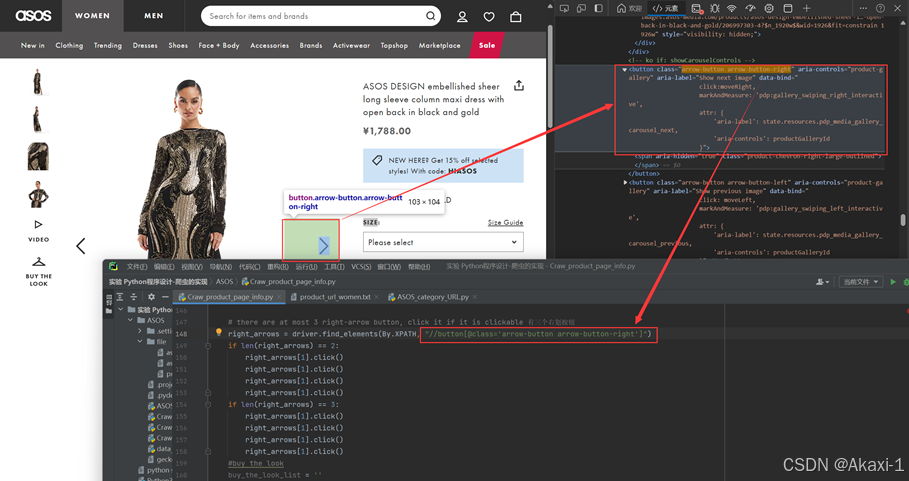
右滑按钮功能:
2.3.1.11 获取相关感兴趣url
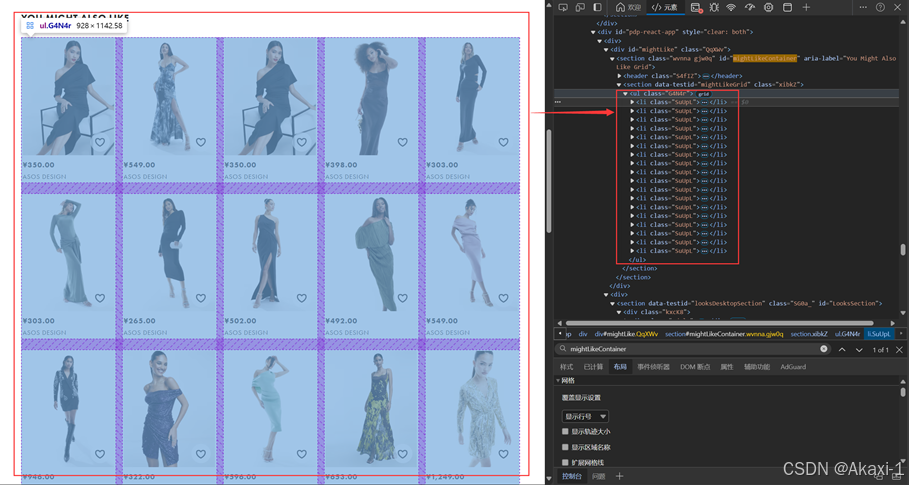
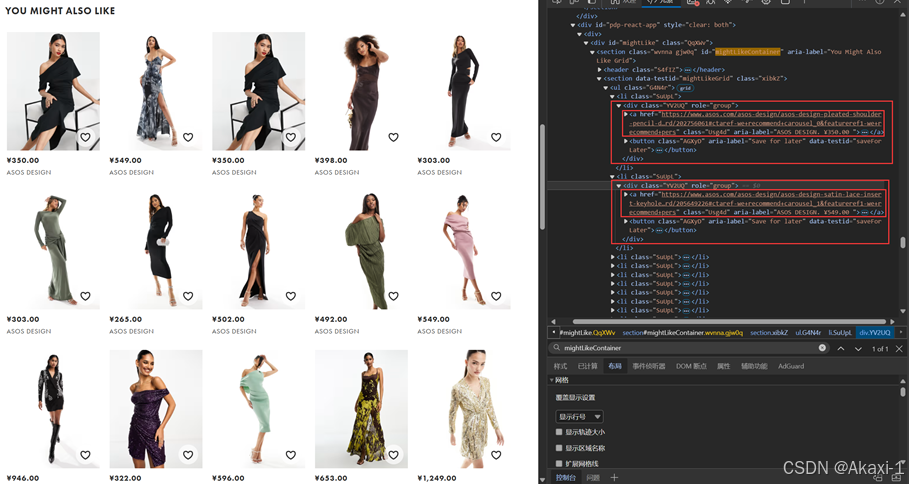
爬取具体的url
最后将所有爬取的信息保存到本地txt文件中,创建名为product_info_list.txt的文件
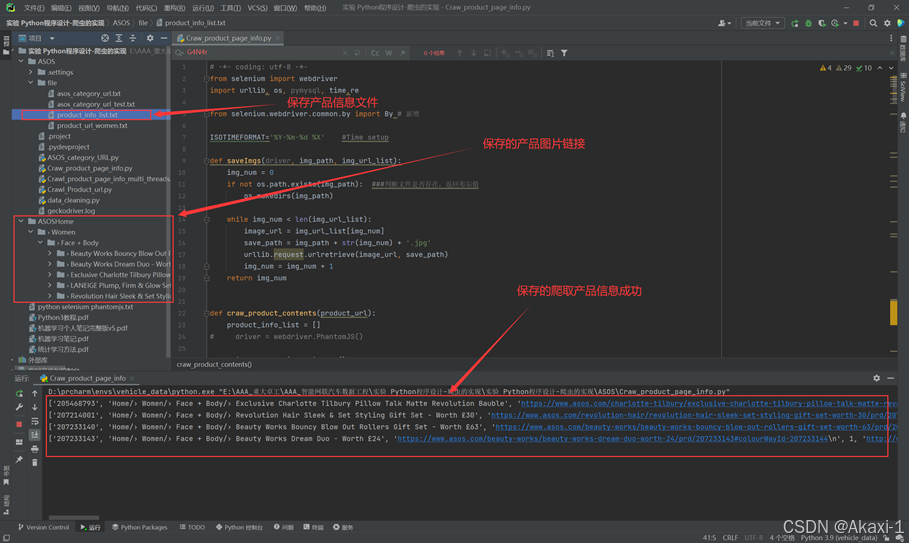
点击运行成功!
打开product_info_list.txt文件可以看到爬取到的产品信息:

点击左边的文件夹,可以看到我们爬取到的产品图片:
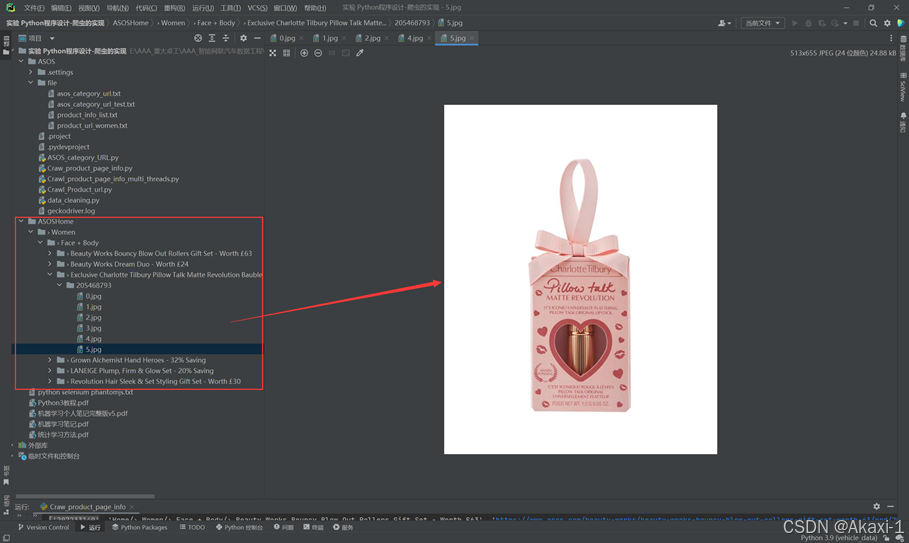
成功!撒花~~~~~~~~~~~~
2.3.2 完整代码
# -*- coding: utf-8 -*-
from selenium import webdriver
import urllib, os, pymysql, time,re
from selenium.webdriver.common.by import By # 新增
ISOTIMEFORMAT='%Y-%m-%d %X' #Time setup
def saveImgs(driver, img_path, img_url_list):
img_num = 0
if not os.path.exists(img_path): ###判断文件是否存在,返回布尔值
os.makedirs(img_path)
while img_num < len(img_url_list):
image_url = img_url_list[img_num]
save_path = img_path + str(img_num) + '.jpg'
urllib.request.urlretrieve(image_url, save_path)
img_num = img_num + 1
return img_num
def craw_product_contents(product_url):
product_info_list = []
# driver = webdriver.PhantomJS()
driver = webdriver.Firefox()
driver.get(product_url) # 打开每个产品
# change the local country
# country_element = driver.find_element(By.XPATH, "//a[@class='currency-locale-link']")
country_element = driver.find_element(By.XPATH, "//button[@class='breiRmE TYb4J9A']") # 切换国家按钮
country_element.click()
driver.implicitly_wait(4) # wait seconds
country_element = driver.find_element(By.XPATH, "//select[@class='tnq36uI EVhxZk8 leavesden2']/option[@value='CH']").click() # 选择国家的元素位置并且点击切换
driver.implicitly_wait(4) # wait seconds
# url_product_id = re.findall(r'[0-9]{7}', product_url)[0] # 查找产品url中连续7个0-9的数字保存为列表,取列列表第一个匹配项
url_product_id = re.findall(r'[0-9]{9}', product_url)[0] # 这里改成9位数字的产品id
product_info_list.append(url_product_id) # product_info_list保存各类产品的id信息
# show more 显示更多,但是并没有在网页中看见这个按钮
# show_more = driver.find_element(By.XPATH, "//a[@class='show']")
# if show_more.is_enabled():
# show_more.click()
# breadcrumb 面包屑导航 就是 xx>xx>xx>xx这种
breadcrumb = ''
# breadcrumb_eles = driver.find_elements(By.XPATH, "//div[@id='breadcrumb']/ul/li")
breadcrumb_eles = driver.find_elements(By.XPATH, "//div[@id='chrome-breadcrumb']/div/nav/ol/li") # 定位到面包屑导航
for breadcrumb_ele in breadcrumb_eles:
breadcrumb = breadcrumb + breadcrumb_ele.text + '/'
breadcrumb = breadcrumb.strip('/')
product_info_list.append(breadcrumb) # 新增面包屑
# product URL
product_info_list.append(product_url)
# URL state is 1
product_url_stat = 1
product_info_list.append(product_url_stat)
# # product code 产品代码
# product_code = ''
# product_code = driver.find_element(By.XPATH, "//p[@class='JK9Oz']").text
# product_info_list.append(product_code)
# product website 产品网页
product_website = 'http://www.asos.com/'
product_info_list.append(product_website)
# product gender 产品男女分类
gender = 0
if 'Men' in breadcrumb:
gender = 1
else:
gender = 0
product_info_list.append(gender)
# product_brand 产品品牌
product_brand = 'ASOS'
product_info_list.append(product_brand)
# product_craw_time 爬取产品时间
product_craw_time = time.strftime(ISOTIMEFORMAT, time.localtime(time.time())) # 获取当前时区时间格式 2016-08-02 21:46:38
product_info_list.append(product_craw_time)
# product title 产品标题
product_title = ''
product_title = driver.find_element(By.XPATH, "//h1[@class='jcdpl']").text # 获取标题文本
product_info_list.append(product_title)
# product delivery 产品配送
product_delivery = ''
product_delivery = driver.find_element(By.XPATH, "//div[@class='zTuDk p1AXC']").text
product_info_list.append(product_delivery)
# product price 产品价格
product_price = 0
product_price = driver.find_element(By.XPATH, "//span[@class='ky6t2']").text
product_info_list.append(product_price)
# # product description 产品描述
# product_description = ''
# product_description = driver.find_element(By.XPATH, "//div[@class='product-description']/span").text.strip()
#
# # product about product material 产品材质
# product_material = ''
# product_material = driver.find_element(By.XPATH, "//div[@class='about-me']/span").text.strip()
# product_description = product_material + ';;' + product_description
# product_info_list.append(product_description.strip(';;'))
# product select size can be null 选择产品的大小(有些产品没有该选项)
size = ''
# product_size = driver.find_element_by_xpath("//div[@class='colour-size-select']").find_elements_by_xpath("//select[@data-id='sizeSelect']/option")
product_size = driver.find_elements(By.XPATH, "//select[@id='variantSelector']/option")
for ele in product_size:
if 'Not' not in ele.text and 'Please' not in ele.text:
size = size + ele.text + ';;'
size = size.strip(';;')
product_info_list.append(size)
# # product care INFO 产品提示信息
# product_care = ''
# product_care = driver.find_element_by_xpath("//div[@class='care-info']/span").text.strip()
# product_info_list.append(product_care)
# product colour 产品颜色
product_colour = ''
product_colour = driver.find_element(By.XPATH, "//p[@class='aKxaq hEVA6']").text
product_info_list.append(product_colour)
# product IMGs 产品图片
img_url_list = []
ele_imgs = driver.find_elements(By.XPATH, "//img[@class='gallery-image']")
for ele in ele_imgs:
img_url_list.append(ele.get_attribute("src")) # 获取图片的源链接
img_url_list = list(set(img_url_list))
img_path = 'Unclassified'
if len(breadcrumb) > 0:
img_path = '/'.join(breadcrumb.split('/')[0:-1])
img_number = saveImgs(driver, ROOTPATH + breadcrumb + '/' + str(url_product_id) + "/", img_url_list) # 爬取图片保存到本地文件夹下
product_info_list.append(img_number)
# there are at most 3 right-arrow button, click it if it is clickable 有三个右划按钮
right_arrows = driver.find_elements(By.XPATH, "//button[@class='arrow-button arrow-button-right']")
if len(right_arrows) == 2:
right_arrows[1].click()
right_arrows[1].click()
right_arrows[1].click()
right_arrows[1].click()
if len(right_arrows) == 3:
right_arrows[1].click()
right_arrows[1].click()
right_arrows[1].click()
right_arrows[1].click()
# # buy the look
# buy_the_look_list = ''
# look_list = []
# buy_the_look_componet = driver.find_element_by_xpath("//div[@class='component buy-the-look']")
# buy_the_look = buy_the_look_componet.find_elements_by_xpath("//div[@class='btl-product-details']/a")
# for ele in buy_the_look:
# if ele.get_attribute('href') is not None and 'complete' in ele.get_attribute('href'):
# if ele.get_attribute('href') not in look_list:
# look_list.append(ele.get_attribute('href'))
# buy_the_look_list = ';;'.join(look_list)
# product_info_list.append(buy_the_look_list)
# you may also like 推荐相关感兴趣的产品url
you_may_also_like_list = ''
like_list = []
you_may_also_like_component = driver.find_element(By.XPATH, "//*[@id='mightLikeContainer']/section/ul")
you_may_also_like = you_may_also_like_component.find_elements(By.XPATH, "//div[@class='YV2UQ']/a")
for ele in you_may_also_like:
if ele.get_attribute('href') is not None and 'recommend' in ele.get_attribute('href'):
if ele.get_attribute('href') not in like_list:
like_list.append(ele.get_attribute('href'))
you_may_also_like_list = ';;'.join(like_list)
product_info_list.append(you_may_also_like_list)
# 保存信息到本地文本
text_content = [repr(str(i)) for i in product_info_list]
with open('./file/product_info_list.txt', 'a', encoding='utf8') as f:
f.write('\t'.join(text_content) + '\n')
# product_details_data = (url_product_id, breadcrumb, product_url, product_url_stat, product_code, product_website,
# gender, product_brand, product_craw_time,
# product_title, product_delivery, product_price, product_description, size,
# product_care, product_colour, img_number, buy_the_look_list, you_may_also_like_list)
# driver.quit()
return product_info_list
def store_in_database(product_data):
#start of database updating
sql_update_content = """\
INSERT INTO testdb.product(
product_breadcrumbs,
product_url,
product_url_stat,
product_sku,
product_website,
product_gender,
product_brand,
product_craw_time,
product_title,
product_estimated_delivery_time,
product_price,
product_desc,
product_stock_hint,
product_size_detail1,
product_size_detail2,
product_img_number,
product_similar,
product_match)
VALUES
(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"""
# cursor.execute(sql_update_content, product_data)
# db.commit()#需要这一句才能保存到数据库中
if __name__ == '__main__':
# product_URLs = open("C:/Users/Administrator/Desktop/product_url.txt")
product_URLs = open("./file/product_url_women.txt") # 保存所有产品的url文件
# ROOTPATH = "C:/Users/Administrator/Desktop/ASOS/" # 根文件路径
ROOTPATH = "E:/AAA_重大卓工/AAA_智能网联汽车数据工程/实验 Python程序设计-爬虫的实现/实验 Python程序设计-爬虫的实现/ASOS"
# db = pymysql.connect("localhost","root","123456","testdb", charset="utf8") 数据库,但是程序并不需要用到
# cursor = db.cursor()
driver = webdriver.Firefox()
# 遍历每一个产品
for product_url in product_URLs:
product_data = craw_product_contents(product_url) # 爬取每一个产品信息
print(product_data)
product_URLs.close()
# db.close()2.3.3 HTML网页源码
想要爬取具体的网页产品信息,整套思路和流程是一样的,在HTML网页源码中找到你想要爬取的信息class属性值,在脚本中对应修改即可~
例如:
xx = driver.find_element(By.XPATH, "//xx[@class='xx']")2.4 Crawl_product_page_info_multi_threads.py
2.4.1 流程实现 - 多线程获取产品具体信息
由于每种产品数据巨大,使用一个程序单线程运行爬取速度太慢,所以我们可以在一个程序中开启多线程,多线程就是前面的单线程加上启动多线程程序,对应修改多线程程序的代码然后运行即可:
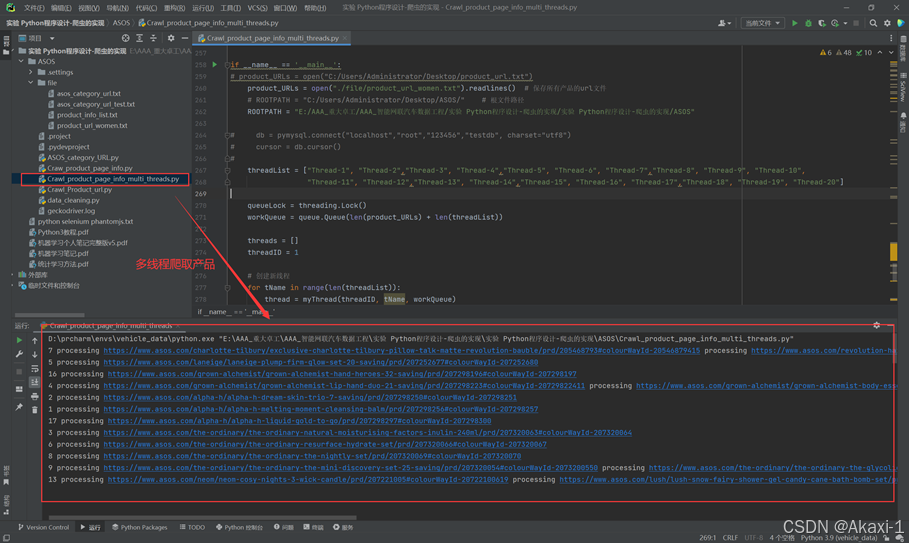
2.4.2 完整代码
# -*- coding: utf-8 -*-
from selenium import webdriver
import urllib, os, pymysql, time,re
import queue
ISOTIMEFORMAT='%Y-%m-%d %X' #Time setup
import threading
from selenium.webdriver.common.by import By # 新增
exitFlag = 0
class myThread(threading.Thread):
def __init__(self, threadID, name, q):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.q = q
def run(self):
# print ("开启线程:" + self.name)
process_data(self.name, self.q)
# print ("退出线程:" + self.name)
def process_data(threadName, q):
while not exitFlag:
queueLock.acquire()
if not workQueue.empty():
data = q.get()
queueLock.release()
print ("%s processing %s" % (threadName, data))
try:
craw_product_contents(data)
except:
print('Error', data)
else:
queueLock.release()
time.sleep(1)
def saveImgs(driver, img_path, img_url_list):
img_num = 0
if not os.path.exists(img_path): ###判断文件是否存在,返回布尔值
os.makedirs(img_path)
while img_num < len(img_url_list):
image_url = img_url_list[img_num]
save_path = img_path + str(img_num) + '.jpg'
urllib.request.urlretrieve(image_url, save_path)
img_num = img_num + 1
return img_num
def craw_product_contents(product_url):
product_info_list = []
# driver = webdriver.PhantomJS()
driver = webdriver.Firefox()
driver.get(product_url) # 打开每个产品
# change the local country
# country_element = driver.find_element(By.XPATH, "//a[@class='currency-locale-link']")
country_element = driver.find_element(By.XPATH, "//button[@class='breiRmE TYb4J9A']") # 切换国家按钮
country_element.click()
driver.implicitly_wait(4) # wait seconds
country_element = driver.find_element(By.XPATH,
"//select[@class='tnq36uI EVhxZk8 leavesden2']/option[@value='CH']").click() # 选择国家的元素位置并且点击切换
driver.implicitly_wait(4) # wait seconds
# url_product_id = re.findall(r'[0-9]{7}', product_url)[0] # 查找产品url中连续7个0-9的数字保存为列表,取列列表第一个匹配项
url_product_id = re.findall(r'[0-9]{9}', product_url)[0] # 这里改成9位数字的产品id
product_info_list.append(url_product_id) # product_info_list保存各类产品的id信息
# show more 显示更多,但是并没有在网页中看见这个按钮
# show_more = driver.find_element(By.XPATH, "//a[@class='show']")
# if show_more.is_enabled():
# show_more.click()
# breadcrumb 面包屑导航 就是 xx>xx>xx>xx这种
breadcrumb = ''
# breadcrumb_eles = driver.find_elements(By.XPATH, "//div[@id='breadcrumb']/ul/li")
breadcrumb_eles = driver.find_elements(By.XPATH, "//div[@id='chrome-breadcrumb']/div/nav/ol/li") # 定位到面包屑导航
for breadcrumb_ele in breadcrumb_eles:
breadcrumb = breadcrumb + breadcrumb_ele.text + '/'
breadcrumb = breadcrumb.strip('/')
product_info_list.append(breadcrumb) # 新增面包屑
# product URL
product_info_list.append(product_url)
# URL state is 1
product_url_stat = 1
product_info_list.append(product_url_stat)
# # product code 产品代码
# product_code = ''
# product_code = driver.find_element(By.XPATH, "//p[@class='JK9Oz']").text
# product_info_list.append(product_code)
# product website 产品网页
product_website = 'http://www.asos.com/'
product_info_list.append(product_website)
# product gender 产品男女分类
gender = 0
if 'Men' in breadcrumb:
gender = 1
else:
gender = 0
product_info_list.append(gender)
# product_brand 产品品牌
product_brand = 'ASOS'
product_info_list.append(product_brand)
# product_craw_time 爬取产品时间
product_craw_time = time.strftime(ISOTIMEFORMAT, time.localtime(time.time())) # 获取当前时区时间格式 2016-08-02 21:46:38
product_info_list.append(product_craw_time)
# product title 产品标题
product_title = ''
product_title = driver.find_element(By.XPATH, "//h1[@class='jcdpl']").text # 获取标题文本
product_info_list.append(product_title)
# product delivery 产品配送
product_delivery = ''
product_delivery = driver.find_element(By.XPATH, "//div[@class='zTuDk p1AXC']").text
product_info_list.append(product_delivery)
# product price 产品价格
product_price = 0
product_price = driver.find_element(By.XPATH, "//span[@class='ky6t2']").text
product_info_list.append(product_price)
# # product description 产品描述
# product_description = ''
# product_description = driver.find_element(By.XPATH, "//div[@class='product-description']/span").text.strip()
#
# # product about product material 产品材质
# product_material = ''
# product_material = driver.find_element(By.XPATH, "//div[@class='about-me']/span").text.strip()
# product_description = product_material + ';;' + product_description
# product_info_list.append(product_description.strip(';;'))
# product select size can be null 选择产品的大小(有些产品没有该选项)
size = ''
# product_size = driver.find_element_by_xpath("//div[@class='colour-size-select']").find_elements_by_xpath("//select[@data-id='sizeSelect']/option")
product_size = driver.find_elements(By.XPATH, "//select[@id='variantSelector']/option")
for ele in product_size:
if 'Not' not in ele.text and 'Please' not in ele.text:
size = size + ele.text + ';;'
size = size.strip(';;')
product_info_list.append(size)
# # product care INFO 产品提示信息
# product_care = ''
# product_care = driver.find_element_by_xpath("//div[@class='care-info']/span").text.strip()
# product_info_list.append(product_care)
# product colour 产品颜色
product_colour = ''
product_colour = driver.find_element(By.XPATH, "//p[@class='aKxaq hEVA6']").text
product_info_list.append(product_colour)
# product IMGs 产品图片
img_url_list = []
ele_imgs = driver.find_elements(By.XPATH, "//img[@class='gallery-image']")
for ele in ele_imgs:
img_url_list.append(ele.get_attribute("src")) # 获取图片的源链接
img_url_list = list(set(img_url_list))
img_path = 'Unclassified'
if len(breadcrumb) > 0:
img_path = '/'.join(breadcrumb.split('/')[0:-1])
img_number = saveImgs(driver, ROOTPATH + breadcrumb + '/' + str(url_product_id) + "/",
img_url_list) # 爬取图片保存到本地文件夹下
product_info_list.append(img_number)
# there are at most 3 right-arrow button, click it if it is clickable 有三个右划按钮
right_arrows = driver.find_elements(By.XPATH, "//button[@class='arrow-button arrow-button-right']")
if len(right_arrows) == 2:
right_arrows[1].click()
right_arrows[1].click()
right_arrows[1].click()
right_arrows[1].click()
if len(right_arrows) == 3:
right_arrows[1].click()
right_arrows[1].click()
right_arrows[1].click()
right_arrows[1].click()
# # buy the look
# buy_the_look_list = ''
# look_list = []
# buy_the_look_componet = driver.find_element_by_xpath("//div[@class='component buy-the-look']")
# buy_the_look = buy_the_look_componet.find_elements_by_xpath("//div[@class='btl-product-details']/a")
# for ele in buy_the_look:
# if ele.get_attribute('href') is not None and 'complete' in ele.get_attribute('href'):
# if ele.get_attribute('href') not in look_list:
# look_list.append(ele.get_attribute('href'))
# buy_the_look_list = ';;'.join(look_list)
# product_info_list.append(buy_the_look_list)
# you may also like 推荐相关感兴趣的产品url
you_may_also_like_list = ''
like_list = []
you_may_also_like_component = driver.find_element(By.XPATH, "//*[@id='mightLikeContainer']/section/ul")
you_may_also_like = you_may_also_like_component.find_elements(By.XPATH, "//div[@class='YV2UQ']/a")
for ele in you_may_also_like:
if ele.get_attribute('href') is not None and 'recommend' in ele.get_attribute('href'):
if ele.get_attribute('href') not in like_list:
like_list.append(ele.get_attribute('href'))
you_may_also_like_list = ';;'.join(like_list)
product_info_list.append(you_may_also_like_list)
# 保存信息到本地文本
text_content = [repr(str(i)) for i in product_info_list]
with open('./file/product_info_list.txt', 'a', encoding='utf8') as f:
f.write('\t'.join(text_content) + '\n')
# product_details_data = (url_product_id, breadcrumb, product_url, product_url_stat, product_code, product_website,
# gender, product_brand, product_craw_time,
# product_title, product_delivery, product_price, product_description, size,
# product_care, product_colour, img_number, buy_the_look_list, you_may_also_like_list)
# driver.quit()
return product_info_list
def store_in_database(product_data):
#start of database updating
sql_update_content = """\
INSERT INTO testdb.product(
product_breadcrumbs,
product_url,
product_url_stat,
product_sku,
product_website,
product_gender,
product_brand,
product_craw_time,
product_title,
product_estimated_delivery_time,
product_price,
product_desc,
product_stock_hint,
product_size_detail1,
product_size_detail2,
product_img_number,
product_similar,
product_match)
VALUES
(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"""
# cursor.execute(sql_update_content, product_data)
# db.commit()#需要这一句才能保存到数据库中
if __name__ == '__main__':
# product_URLs = open("C:/Users/Administrator/Desktop/product_url.txt")
product_URLs = open("./file/product_url_women.txt").readlines() # 保存所有产品的url文件
# ROOTPATH = "C:/Users/Administrator/Desktop/ASOS/" # 根文件路径
ROOTPATH = "E:/AAA_重大卓工/AAA_智能网联汽车数据工程/实验 Python程序设计-爬虫的实现/实验 Python程序设计-爬虫的实现/ASOS"
# db = pymysql.connect("localhost","root","123456","testdb", charset="utf8")
# cursor = db.cursor()
#
threadList = ["Thread-1", "Thread-2","Thread-3", "Thread-4","Thread-5", "Thread-6", "Thread-7","Thread-8", "Thread-9", "Thread-10",
"Thread-11", "Thread-12","Thread-13", "Thread-14","Thread-15", "Thread-16", "Thread-17","Thread-18", "Thread-19", "Thread-20"]
queueLock = threading.Lock()
workQueue = queue.Queue(len(product_URLs) + len(threadList))
threads = []
threadID = 1
# 创建新线程
for tName in range(len(threadList)):
thread = myThread(threadID, tName, workQueue)
thread.start()
threads.append(thread)
threadID += 1
# 填充队列
queueLock.acquire()
for product_url in product_URLs:
workQueue.put(product_url.strip('\n'))
queueLock.release()
# 等待队列清空
while not workQueue.empty():
pass
# 通知线程是时候退出
exitFlag = 1
# 等待所有线程完成
for t in threads:
t.join()
print ("退出主线程")
product_URLs.close()
# db.close()三、【更多信息】
感谢周老师提供的源代码,感谢同组的同学提供的帮助,参考了该仓库的代码:Rainbow0498/Data Engineering Test1 (gitee.com)
参考链接
Selenium自动化-Firefox浏览器驱动(GeckoDriver)下载_geckodriver下载-优快云博客
【爬虫】python+selenium+firefox使用与部署详解_selenium firefox-优快云博客
----------------------------------------------------------------------------------------------------
相信读到这里的朋友,一定是坚持且优秀的
给博主一个免费的赞👍吧
扫描二维码进博主交流群,问题交流 | 吹吹水 | 一起变得更加优秀

2024.10.17
两江重大卓工院


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











