 NERF自己数据集复现步骤及问题解决
NERF自己数据集复现步骤及问题解决




pytorch 代码
NERF 自己数据集复现 完成步骤+遇到问题
完成步骤:
1 数据集跑colmap,生成相机位姿
在此不做赘述,参考我的另一篇文章colmap。步骤大致相同,值得注意的是:
在进行特征提取时候记得选择相机模型,最好不要使用默认的,选择SIMPLE——PINHOLE和PINHOLE均可


结束后点击Processing旁边的Reconstruction,选择Start Reconstruction,等待结束
在完成这一步后我们最好查看一下是否每一张图片都被匹配到了,可能会出现没重建上的情况,这些图片要留意,后面我们要删除。
结束后,点击File,选择Export model,这里一定注意不要直接保存,需要新建两个文件夹(sparse,0),请保持一致 nerf原代码中固定了sparse/0文件夹的名称
结束后检查文件夹中的东西:
sparse/0/有三个bin文件和一个project.ini即可。在根目录下还应该有一个.db文件,这是第一步你创建project时候就生成的。
2 将生成的bin文件通过llff数据集转化成.npz格式
接下来,将获取的位姿等数据转化为llff格式,需要下载llff脚本,(地址:GitHub - Fyusion/LLFF: Code release for Local Light Field Fusion at SIGGRAPH 2019)
下载完成进入LLFF目录下,打开imgs2poses.py文件,新增如下内容,default=‘里面是sparse所在目录的绝对路径’,并将参数’scenedir’修改为是’–scenedir’。

存放照片的文件夹名称必须是images,否则会出错。
运行imgs2poses.py代码(bash):
# 要在imgs2poses.py所在目录执行命令
cd....(文件所在目录)
# 运行
python imgs2poses.py --scenedir D:\colmap.1\nerf\warplane
假如不增加default=‘’。
# 在运行imgs2poses.py代码时,即使有默认值也必须传入路径(与scenedir参数有关)
python imgs2poses.py "XXXX/XXXX/"
按理说在这一步结束后,就应该输出一个有关图像位姿的.npy文件。但在这一步我踩了很多坑:
问题·1
会出现need to run colmap的报错,这通常是因为没办法获取正确的相机参数。
有可能是因为没有正确的创建文件夹,也有可能是因为spares文件下的.bin文件没放对位置。
这些都没问题的话,那就是生成的有问题,很可能就是因为在位姿计算时候你没有处理好数据,参考上文我遇到的问题来看你的图片有问题,请仔细检查。
问题·2
会出现UTF-8编码错误:
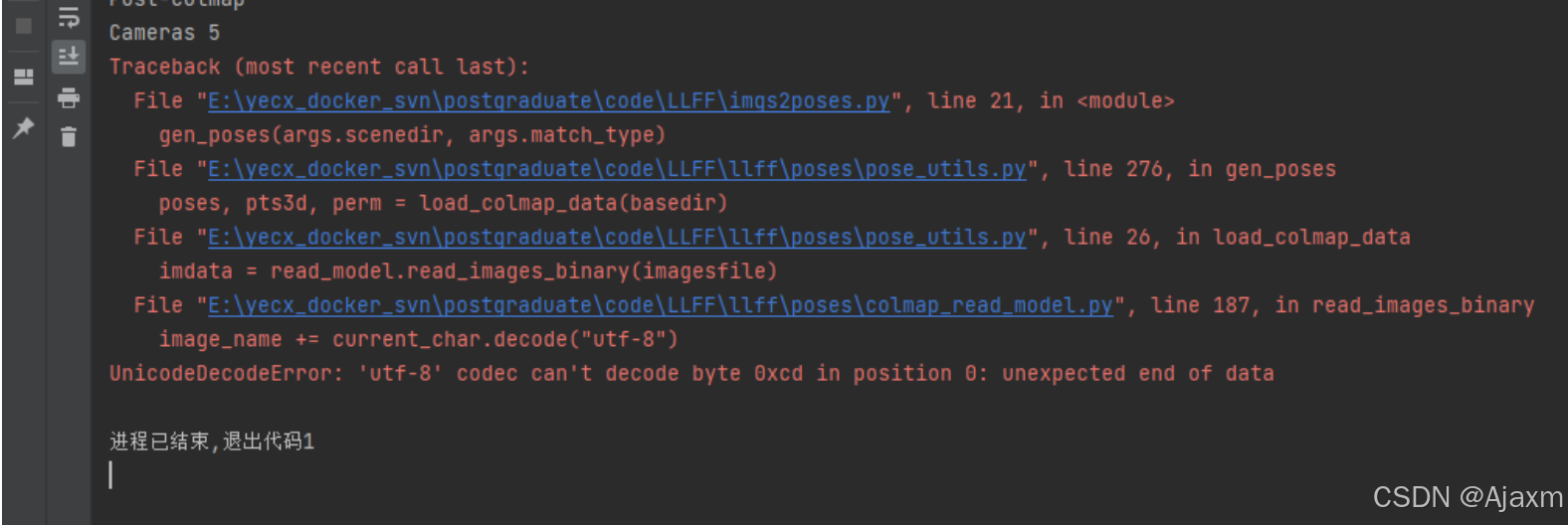
这个问题真的是耗费了博主无数的心血,博主最开始以为是程序的问题,在寻找到了源码的camera.bin文件读取函数修改了其中的编码方式,后面确实是不报错了,但是在最终训练时,无法进行正常训练。
在后面博主排除了是训练文件的问题后又重新把目光聚焦于此,试图寻找是不是数据的问题,于是尝试了很多种相机模型,但还是没有解决。每跑一遍colmap都要耗费掉很长的时间,可以说是心力交瘁。
再后来博主怀疑是不是环境的问题,更换电脑,甚至试了更换系统,都没有解决。
直到去系统查询了几种编码格式的区别,才意识到这很有可能是跟汉字有关,因为如果是纯英文的话,一般不会出现格式的转化,只有出现其他符号,才会有字符编码的转换,比如记事本:
所以,很大概率是因为数据里面出现了非常规字符。首先,图片的特征也好位姿信息也好不可能出现汉语,那只剩下了一种就是图片的名字!果不其然,我的图片因为是从微信传输保存的,所以图片名称中均出现了汉字,再修改后,重新进行位姿计算,解决了问题。
总结一下:原始数据集images里面的图片名称不能有汉语出现,否则在进行后续处理运行imgs2poses时候会出现utf-8编码错误。
另外,因为说到了初始数据的一些问题,顺便提一下:
图片的尺寸必须也得保持一致,也就是分辨率,否则到后面最后一步训练时候就会出现报错信息。
这两点十分重要,可以说是让博主在上面耗费了十分多的心血才解决。
问题3:

这个问题就是前文所说的匹配的位姿和图片数目不同导致的,博主在这里解决这个问题。通过在 LLFF/llff/poses/pose_utils.py 文件的32行左右添加如下代码:
#---------输出匹配到位姿的图片名---------
for i in np.argsort(names):
print(names[i],end=' ')
#---------输出匹配到位姿的图片名---------
添加代码位置如下图所示:

显示出所有匹配到位姿的图片。

仔细查看,然后进入图像保存的目录,删除没有匹配到位姿的图像,再后重新进行 “位姿计算” 这一步骤。
解决所有问题后,执行结果如下图所示:

生成有关图像位姿的npy文件,格式转换步骤完毕。

3 迁移工作文件夹并设置配置文件
将工作文件夹完整迁移至nerf代码的/nerf-pytorch/data/nerf_llff_data/目录下。

复制/nerf-pytorch/configs目录下的fern.txt文件(因为fern同为LLFF格式的数据集),并重命名为自己测试数据的名称,修改如下内容:

至此,所有准备工作都已完成。
4 训练数据
完成后执行
python run_nerf.py --config configs/warplanes.txt(替换成你自己的配置文件)
正常情况:
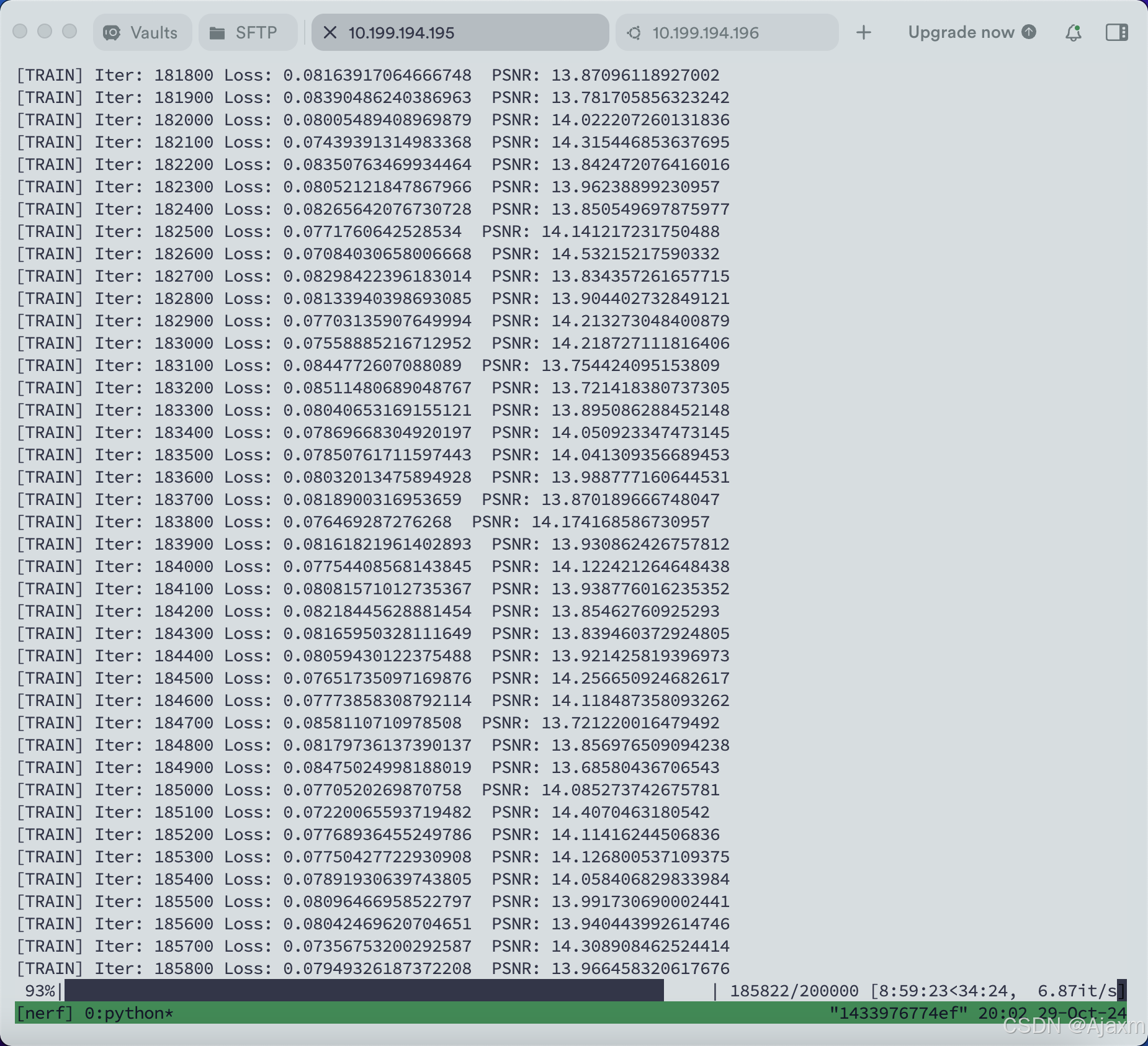
还是一样的,这最后一步也会出现很多问题,也踩了很多坑,我把我遇见的分享出来:
问题·1
如果你是360度环拍的数据集 执行:
python run_nerf.py --config configs/warplanes.txt --spherify --no_ndc
否则无法得到正确的渲染的结果 (渲染的图像中会有黑色的线)
问题·2 imageio函数报错
在执行到 evaluate 时,输出图片出了下面的错误:
envs\NeRFlearning\Lib\site-packages\PIL\Image.py", line 3102, in fromarray raise TypeError(msg) from e TypeError: Cannot handle this data type: (1, 1, 3), <f4
查询后发现是因为 imageio.imwrite 函数需要接收的图像数据类型为 uint8 ,而原始的 pred_rgb 和 gt_rgb 可能是浮点数类型的数据。因此,我们需要将它们乘以255(将范围从0-1转换为0-255),然后使用 astype 函数将它们转换为 uint8 类型
# 将数据类型转换为 uint8
pred_rgb = (pred_rgb * 255).astype(np.uint8)
gt_rgb = (gt_rgb * 255).astype(np.uint8)
# 需要添加以上两行,否则报错
imageio.imwrite(save_path, img_utils.horizon_concate(gt_rgb, pred_rgb))
这里还有一个问题,我发现在已经生成过一张图片后,再次执行到这里,输出的新图片无法覆盖之前的旧图片,所以我加上了时间和当前周期作为扩展名
now = datetime.datetime.now()
now_str = now.strftime('%Y-%m-%d_%Hh%Mm%Ss')
base_name, ext = os.path.splitext(save_path)
save_path = f"{base_name}_{now_str}_epoch_{cfg.train.epoch}{ext}"
这样就会以这样的 res_2024-03-18_09h09m40s_epoch_10.jpg 格式正确输出每次的图像了
问题·3 Evaluate 显存爆炸
在运行 evaluate 模块时,我用模型对一张图片进行推理,发现显存爆炸增长,经过一番寻找之后,找到了问题:
- ~在运行 run.py 的 evaluate 模块时,
evaluator.evaluate(output, batch)这句话没有在torch.no_grad()中导致的。修改只需要加一个缩进即可~
问题·4 训练中迭代到一定次数loss出现NaN
一般来说,出现NaN有以下几种情况:
1.如果在迭代的100轮以内,出现NaN,一般情况下的原因是因为学习率过高。但这个不太可能出现在本项目中,本项目迭代轮次都在两万次左右,在很少次数就出现NaN明显不符合常理。
2.不当的输入
输入中就含有NaN。
现象:每当学习的过程中碰到这个错误的输入,就会变成NaN。观察log的时候也许不能察觉任何异常,loss逐步的降低,但突然间就变成NaN了。
措施:提前进行下采样:
import cv2
import os
def downsample_images(input_dir, output_dir, downsample_factor):
# 确保输出目录存在
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 获取输入目录下的所有.jpg文件
images = [f for f in os.listdir(input_dir) if f.endswith('.jpg')]
# 初始化处理图片计数器和输出图片索引
num = 0
index = 0
# 遍历每一张图片
for image_name in images:
# 构建完整的文件路径
input_image_path = os.path.join(input_dir, image_name)
# 读取原始图片
original_image = cv2.imread(input_image_path)
# 检查是否成功读取图片
if original_image is None:
print(f"警告: 无法读取图片 {input_image_path}")
continue
# 根据下采样因子进行下采样
img_downsampled = original_image
for _ in range(downsample_factor):
img_downsampled = cv2.pyrDown(img_downsampled)
# 构建输出图片的完整路径并保存
output_image_path = os.path.join(output_dir, f"{index}.jpg")
cv2.imwrite(output_image_path, img_downsampled)
# 更新计数器
num += 1
index += 1
print(f"正在为第{num}张图片采样......")
# 设置输入输出目录以及下采样因子
input_directory = r'D:\colmap.1\nerf2\warplane\images'
output_directory = r'D:\colmap.1\nerf2\warplane\images_4'
downsample_factor = 2 # 下采样倍数,例如8倍则设置为3(因为每次pyrDown都是2倍)
# 调用函数执行下采样
downsample_images(input_directory, output_directory, downsample_factor)
经过多次测试,最好是进行8倍和4倍的两次下采样,并将数据保存在images_8和images_4两个文件夹放入你的数据集data里,和images原图处于同一路径下。
5 存疑的问题
psnr 不上升
有时开始训练时的psnr从9左右开始就会导致 psnr 不上升一直徘徊在9左右,loss 正常下降。

尝试了5000次的迭代(10个epoch),测试出来图片是纯黑色的:
目前猜测原因可能是初始化导致的。
2 out of the memory
修改txt文件中的N_rand N_samples N_importance
代表处理光束的数量,普通采样点数量(进入coarse网络的采样点个数),重要性采样点的数量(进入fine网络的采样点个数是sample+importance)




















 2191
2191




 到【灌水乐园】发言
到【灌水乐园】发言









