






2025深度学习发论文&模型涨点之——动态特征融合
动态特征融合(Dynamic Feature Fusion,DFF)是一种深度学习中的特征融合技术,旨在通过动态学习调整每个特征的重要性,并将它们融合在一起以获得更准确的结果。
-
全局信息提取:通过平均池化(AVGPool)、卷积(Conv)和Sigmoid激活函数等操作提取全局信息,生成用于指导特征融合的权重。
-
特征融合:将输入特征图与生成的权重进行元素级乘法(Element-wise Multiplication)等操作,实现特征的动态融合。
小编整理了一些动态特征融合【论文】合集,以下放出部分,全部论文PDF版皆可领取。
需要的同学
回复“111”即可全部领取
论文精选
论文1:
Dynamic Feature Fusion for Semantic Edge Detection
语义边缘检测中的动态特征融合
方法
-
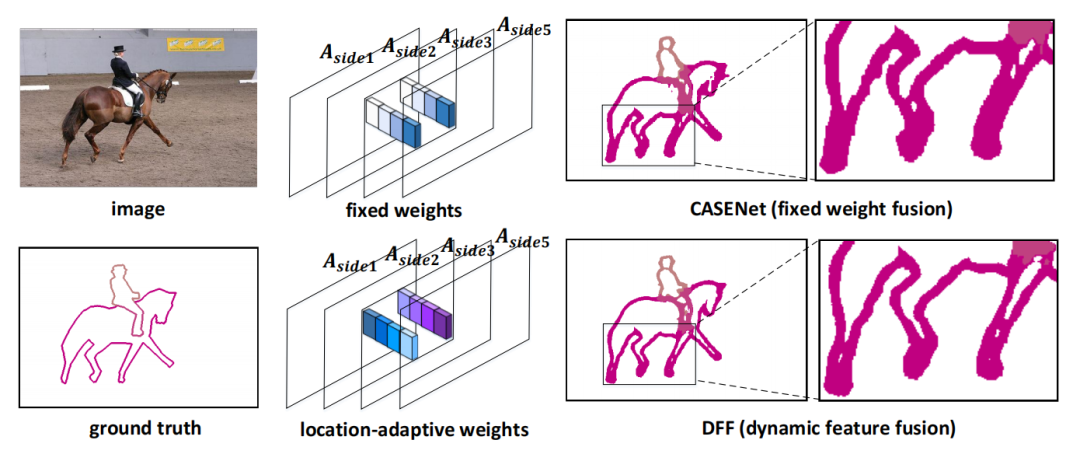
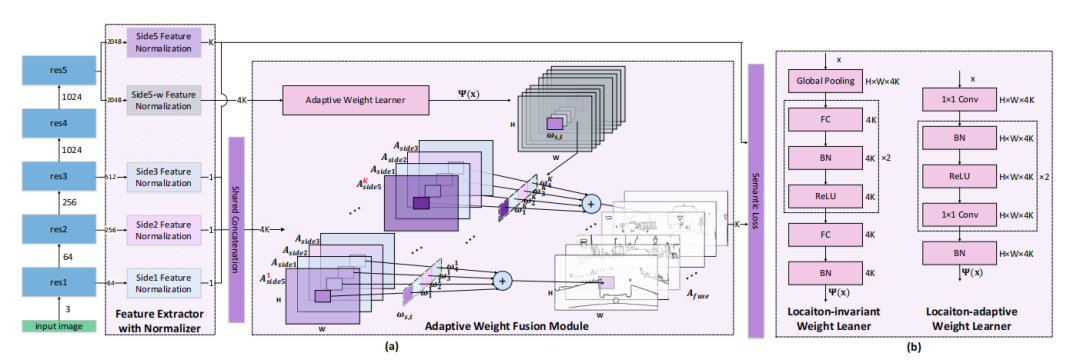
动态特征融合(DFF):提出了一种动态特征融合策略,通过权重学习器为每个输入图像和位置自适应地分配不同的融合权重。
-
特征提取器与归一化:设计了一个特征提取器,用于将多尺度响应归一化到相同的幅度,为下游融合操作做准备。
-
位置自适应权重学习器:通过学习输入图像的内容,为每个位置生成位置特定的融合权重,以更好地利用多尺度特征。
创新点
-
动态权重学习:首次提出基于输入内容动态学习融合权重的方法,显著提高了边缘检测的准确性和锐度(在Cityscapes数据集上,与固定权重融合方法相比,平均F-measure提升了约9.4%)。
-
位置自适应融合:通过位置自适应权重学习器,为每个位置定制融合权重,进一步提升了边缘检测的性能(与位置不变权重融合相比,平均F-measure提升了约2.7%)。
-
归一化处理:通过特征归一化,解决了多尺度特征幅度差异问题,提升了融合效果(在Cityscapes数据集上,归一化处理使平均F-measure提升了约0.3%)。
论文2:
E2ENet Dynamic Sparse Feature Fusion for Accurate and Efficient 3D Medical Image Segmentation
E2ENet:动态稀疏特征融合用于准确高效的3D医学图像分割
方法
-
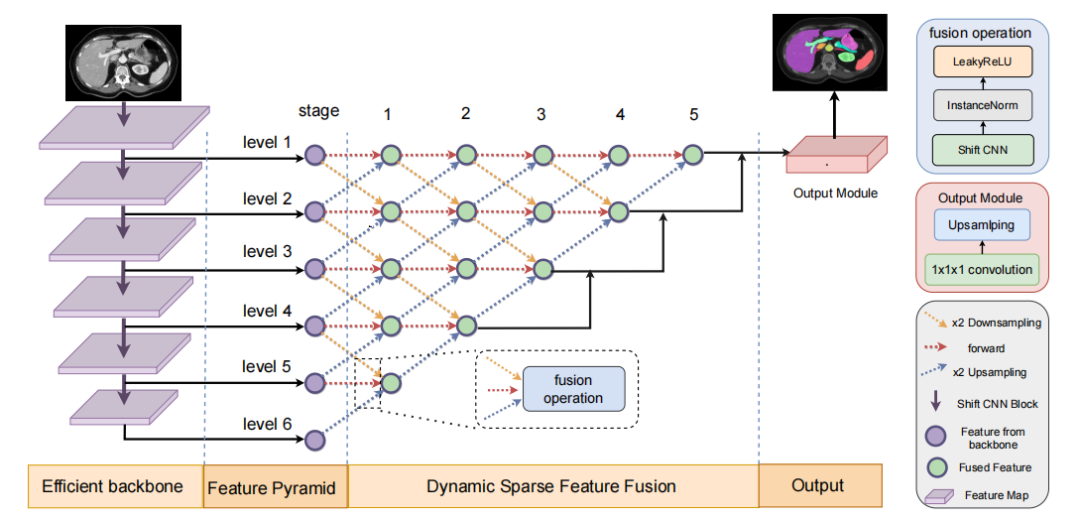
动态稀疏特征融合(DSFF):提出了一种动态稀疏特征融合机制,自适应地融合多尺度特征,同时减少冗余信息。
-
受限深度偏移3D卷积:通过在3D卷积中引入受限深度偏移策略,利用3D空间信息,同时保持计算复杂度与2D方法相当。
-
稀疏训练:采用动态稀疏训练方法,通过在训练过程中动态调整特征连接,优化特征融合。
创新点
-
动态稀疏特征融合:通过自适应选择重要特征并过滤冗余特征,显著减少了计算和内存开销(在AMOS-CT数据集上,与nnUNet相比,参数数量减少了69%,FLOPs减少了29%)。
-
受限深度偏移策略:通过在3D卷积中引入受限深度偏移,实现了与3D卷积相当的分割精度,同时保持了2D卷积的计算效率。
-
性能与效率的平衡:在多个3D医学图像分割挑战中,E2ENet在保持高精度的同时,显著降低了模型大小和计算复杂度(在BTCV挑战中,mDice达到90.1%,参数数量减少了69%,FLOPs减少了29%)。
论文3:
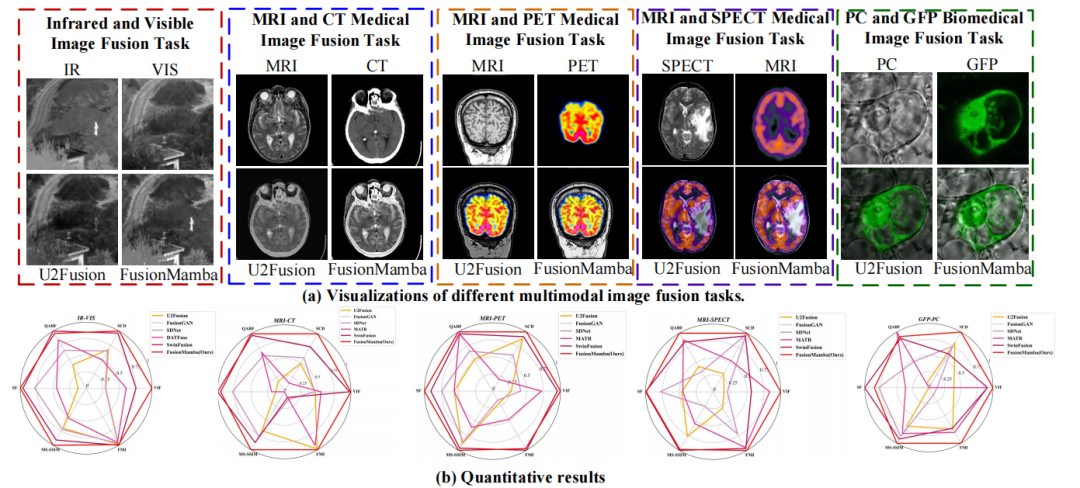
FusionMamba Dynamic Feature Enhancement for Multimodal Image Fusion with Mamba
FusionMamba:基于Mamba的多模态图像融合中的动态特征增强
方法
-
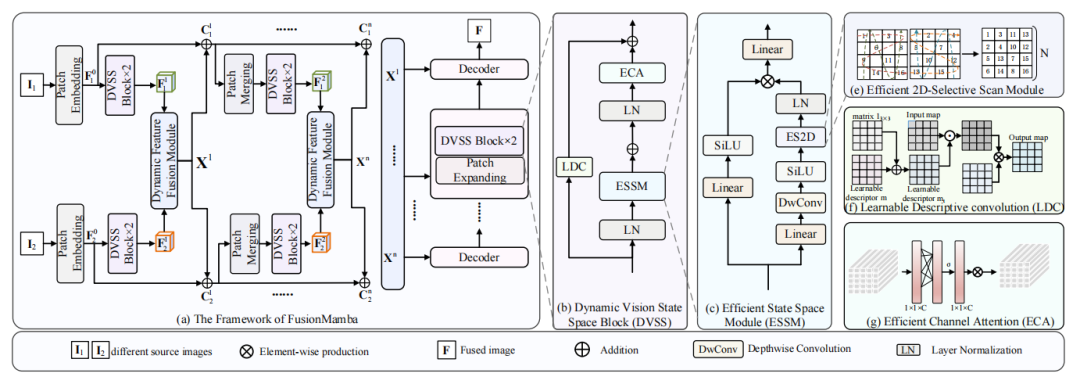
动态视觉状态空间模型(DVSS):提出了一种改进的Mamba模型,结合动态卷积和通道注意力,用于图像融合中的特征提取。
-
动态特征增强模块(DFEM):通过动态差分感知和纹理增强,自适应地增强输入特征,提升细节纹理信息。
-
跨模态融合Mamba模块(CMFM):用于挖掘不同模态之间的相关性,抑制冗余信息,提升融合效果。
创新点
-
改进的Mamba模型:通过动态卷积和通道注意力,显著提升了Mamba模型的特征提取能力和局部特征增强(在CT-MRI融合任务中,VIF指标提升了约0.17)。
-
动态特征增强:通过DFEM模块,自适应地增强纹理细节和模态间差异信息,提升了融合图像的视觉效果(在PET-MRI融合任务中,MS-SSIM指标提升了约0.03)。
-
跨模态融合:通过CMFM模块,有效挖掘不同模态之间的相关性,抑制冗余信息,提升了融合精度(在SPECT-MRI融合任务中,FMI指标提升了约0.01)。
论文4:
Ground-Fusion A Low-cost Ground SLAM System Robust to Corner Cases
Ground-Fusion:一种对角案例鲁棒的低成本地面SLAM系统
方法
-
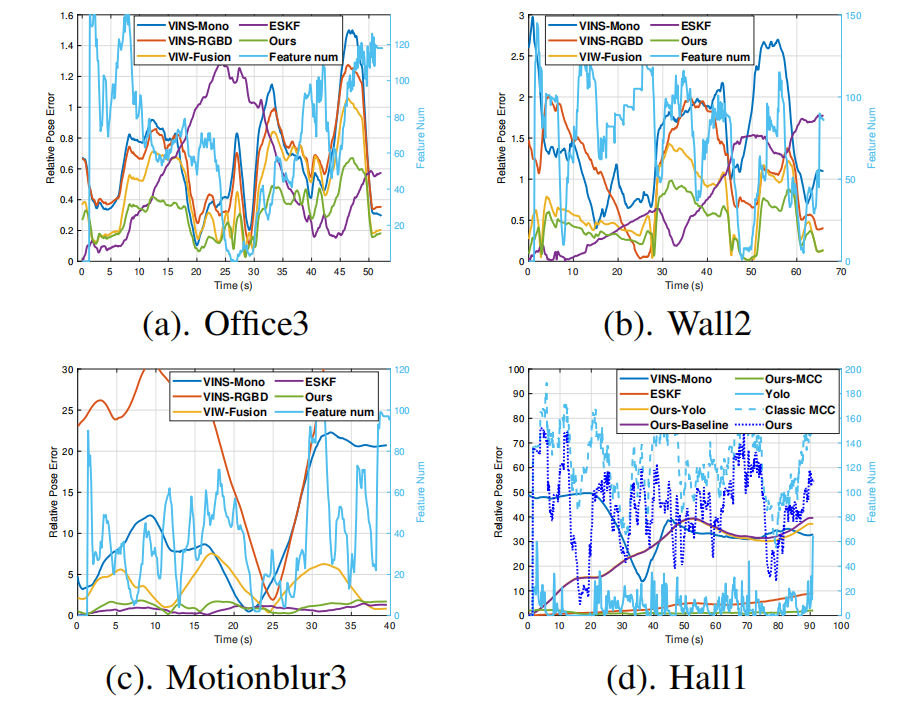
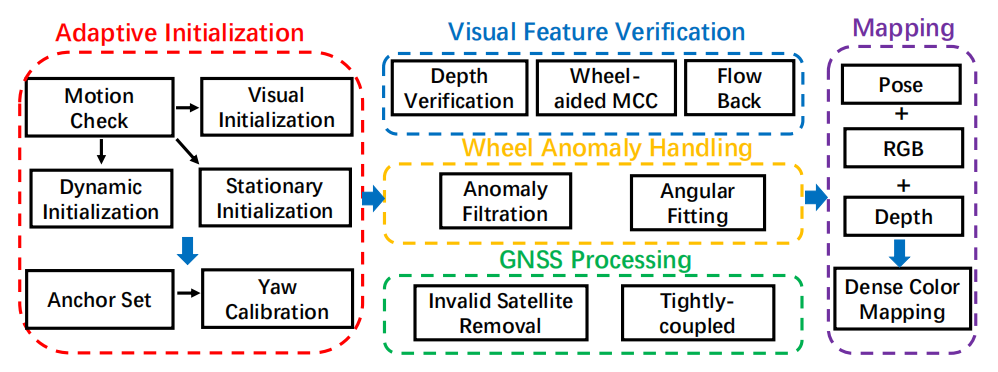
多传感器紧耦合:将RGB-D图像、惯性测量、轮式里程计和GNSS信号紧密集成到因子图中,实现室内外的高精度定位。
-
自适应初始化策略:提出包括静止、视觉和动态三种初始化方法,针对不同场景进行鲁棒初始化。
-
传感器异常检测与处理:开发了针对视觉故障、轮式异常和GNSS退化的检测与处理机制,提升系统的鲁棒性。
创新点
-
自适应初始化:通过三种初始化方法(静止、视觉和动态),在不同场景下实现快速且鲁棒的初始化(在静止场景Static1中,初始化时间仅需1.42秒,ATE RMSE为0.01米)。
-
传感器异常处理:通过检测和处理轮式异常、视觉故障和GNSS退化,显著提升了系统的鲁棒性(在轮式异常序列Anomaly中,ATE RMSE从0.78米降低到0.07米)。
-
计算效率:通过紧耦合多传感器数据,避免了传统方法中的尺度问题,提升了定位精度和计算效率(在Office3序列中,ATE RMSE为0.14米,比其他方法更优)。
小编整理了动态特征融合论文代码合集
需要的同学
回复“111”即可全部领取

















 5955
5955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









