




第一部分: ConvNeXt 出现背景
简单来说,ConvNeXt是一个纯粹的卷积神经网络(CNN)。
CNN我们都学过,从LeNet、AlexNet到ResNet、DenseNet,已经非常成熟了,为什么还要提出一个新的CNN架构?
这里的关键在于Vision Transformer (ViT)。自2020年ViT问世以来,它在各大计算机视觉任务(图像分类、目标检测、图像分割)上一骑绝尘,性能全面超越了传统的CNN模型,一时间“CNN已死,Transformer当立”的论调甚嚣尘上。
ConvNeXt的作者们对此提出了一个问题:Vision Transformer的成功,究竟是因为其核心的自注意力(Self-Attention)机制更好,还是因为它在训练方法、宏观/微观架构设计上采用了更现代化的技巧?
为了回答这个问题,他们进行了一场实验:完全不使用任何Transformer的注意力机制,而是将一个标准的CNN模型(ResNet)作为“小白鼠”,一步步地用Vision Transformer的设计理念和训练技巧对其进行现代化改造,看看一个纯粹的CNN到底能达到什么样的高度。
最终的产物,就是ConvNeXt。实验结果震惊了学术界:一个纯粹的CNN,在不使用注意力机制的情况下,性能全面超越了当时的SOTA(State-of-the-Art)模型Swin Transformer。
所以,可以这样理解ConvNeXt:
它是一个披着CNN外衣,却拥有Transformer架构设计哲学的强大网络。它的诞生证明了,精良的架构设计和训练方法,比某个特定的组件(如自注意力)更为重要。
第二部分:ConvNeXt架构设计与创新
我们先学习convnext的架构设计与激活函数使用,再进行实例化教学
宏观架构设计 (Macro Design)
1.改变阶段计算比例
这是原ResNet网络架构:
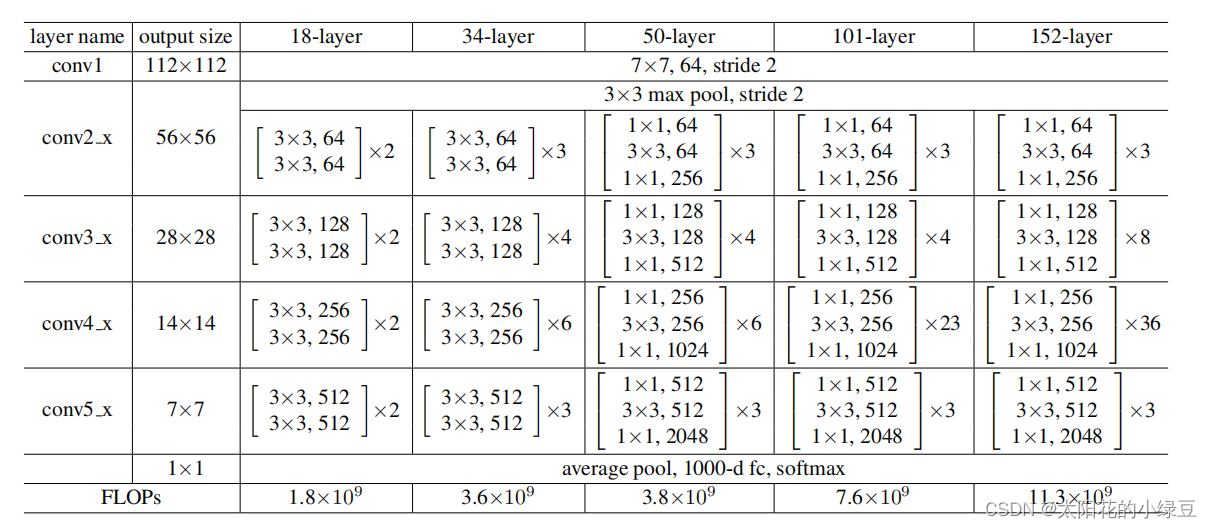
我们发现CONV4_X一般堆叠更多,在18层下,从CONV2_X到5_X的比例为:1:1:1:1,在34层情况下,为:3:4:6:3,由此可见,第4层其实堆叠比例并不太高,但是swin-T,他的第四层堆叠比例为:1:1:9:1,所以,我们也要把第4层提升,最终选择(3, 3, 9, 3),这样提高了一些准确率
这说明,如何分配计算量和参数量在不同深度的层级上,对性能有直接影响。
2.“Patchify” 输入层 (Patchify Stem):
ResNet 的输入层(Stem)是一个 7x7 的大卷积核,步长为2,后面再跟一个最大池化。
ViT 处理输入图像的方式是将其切成一个个不重叠的“patch”,然后通过一个线性层映射。这在CNN里等价于一个大的、不重叠的卷积。
于是,作者将ResNet的输入层换成了一个 4x4 的卷积核,步长为4。 准确率从 79.4% 提升到 79.5%。这个改动让网络在最开始就以一种更“Transformer-like”的方式来处理图像。
微观模块设计 (Micro Design)
以下看不懂也没关系,后面我会实例化教学讲解,让大家能够看懂
1.深度可分离卷积 (Depthwise Separable Convolution):
这是现代化CNN的一个关键组件(例如MobileNet)。它的计算量远小于常规卷积。
作者发现,Swin Transformer中的自注意力计算在某种程度上也和深度可分离卷积很像:它也是在每个通道(channel)上独立进行空间信息混合的。
改造: 将ResNet Bottleneck中的3x3卷积换成3x3的深度可分离卷积。
效果: 准确率提升到 80.5%,同时计算量(FLOPs)也降低了。
2.倒置瓶颈结构 (Inverted Bottleneck):
ResNet 的瓶颈块是“两头宽,中间窄”(1x1降维 -> 3x3卷积 -> 1x1升维)。
Transformer 的MLP模块和很多现代CNN(如MobileNetV2)都采用“两头窄,中间宽”的倒置瓶颈结构 (1x1升维 -> dxd深度卷积 -> 1x1降维)。
改造: 将网络结构改为倒置瓶颈。
效果: 准确率提升到 80.6%。
核心改进部分:
1.增大卷积核尺寸 (Large Kernel Sizes):
ViT的核心优势之一是自注意力机制具有全局感受野。而传统CNN的感受野受限于卷积核大小(通常是3x3)。
为了弥补这一点,作者大胆地增大了深度卷积的核尺寸。
改造: 他们将3x3的深度卷积核逐步增加到5x5,7x7,9x9... 发现7x7是一个甜点。同时,他们把深度卷积层在block中的位置上移,放到了1x1层之前,这样更高效。
效果: 准确率从 80.6% (3x3) 提升到 81.3% (7x7)。这是至关重要的一步,证明了大的卷积核对于CNN性能的巨大价值。
2.层级间的微小调整
激活函数: 将ReLU换成GELU。GELU在Transformer中被广泛使用。
减少激活函数和归一化层: 作者发现Transformer的Block中激活函数和归一化层用得更少。他们仿照这个设计,在ConvNeXt Block中只保留了升维1x1层之后的一个GELU激活函数,并减少了归一化层的使用。
归一化层: 将BatchNorm (BN) 换成 LayerNorm (LN)。BN在CNN中是标配,但它有一些副作用且在Transformer中不常用。LN是Transformer的标配。
效果: 这些“小修小补”共同将准确率从 81.3% 提升到了 82.0%。
经过以上所有步骤,一个纯粹的CNN模型,在同样的训练配置下,已经达到了 82.0% 的准确率,超越了当时精心设计的Swin-T(81.3%)。
ConvNeXt 架构最终形态:
总结一下,最终的ConvNeXt Block长什么样?
它是一个倒置瓶颈块,其数据流如下:
输入 x
经过一个 7x7 的深度卷积 (Depthwise Conv),步长为1,填充为3。
经过一次 Layer Normalization。
经过一个 1x1 的卷积,将通道数扩大4倍(升维)。
经过 GELU 激活函数。
经过另一个 1x1 的卷积,将通道数恢复原状(降维)。
与输入的 x 进行残差连接 (shortcut connection)。
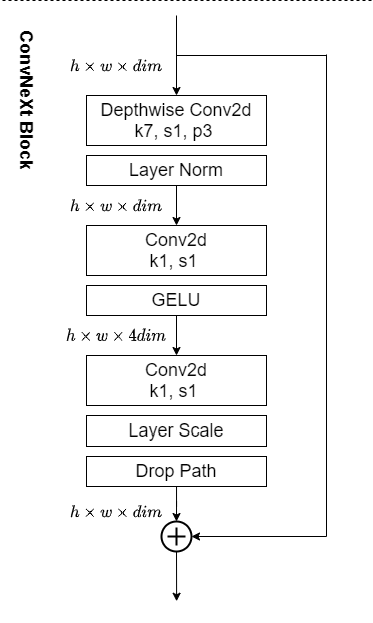
整个网络由4个Stage组成,每个Stage堆叠若干个这样的ConvNeXt Block。
第三部分:实例化部署教学,一步步搞定
我刚才讲了ConvNeXt Block的理论结构,现在我就用一个具体的数据实例,一步一步地“手算”一遍,看看数据在这个模块中是如何流动和变化的。
输入数据确定
为了方便计算和理解,我会用一个极度简化的例子。
1. 输入数据 (Input Tensor):
假设我们有一个从前一个网络层传来的特征图 (Feature Map)。为了简单,我们设定它的尺寸为:
高度 (H): 4
宽度 (W): 4
通道数 (C): 2
批次大小 (Batch Size): 1 (我们只看一个样本)
所以,我们的输入 x 是一个 1x2x4x4 的张量。我们可以想象成两张 4x4 的图。
输入 x 的通道1 (x_c1):
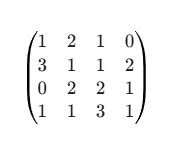
输入 x 的通道2 (x_c2):

2. 简化的ConvNeXt Block参数:
真实的ConvNeXt用7x7卷积核和4倍通道扩展。为了手算方便,我们简化一下:
深度卷积核尺寸 (Kernel Size): 3x3
通道扩展比例 (Expansion Ratio): 2倍 (真实的为4倍)
输入/输出通道数: 2
数据实例教学:一步步过一遍ConvNeXt Block
第1步: 深度卷积 (Depthwise Convolution)
这是ConvNeXt Block的第一个核心操作。它对输入的每一个通道独立地进行卷积。
我们有一个 3x3 的卷积核,但是这个核是“深度”的,意味着它有两个 3x3 的部分,分别对应输入的两个通道。
卷积核 (Kernel_dw):
k1 (用于通道1):
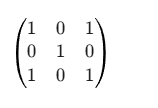
k2 (用于通道2):
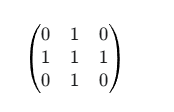
操作: k1 只在 x_c1 上滑动计算,k2 只在 x_c2 上滑动计算。为了保持4x4的尺寸不变,我们需要使用 padding=1 的策略(在原始特征图周围补一圈0)。
计算 (以通道1的左上角为例): 原始左上角 3x3 区域(加上padding后)为:
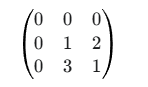
-
与
k1进行点乘求和:(0*1 + 0*0 + 0*1) + (0*0 + 1*1 + 2*0) + (0*1 + 3*0 + 1*1) = 0 + 1 + 1 = 2。 所以输出特征图的左上角第一个值为2。 -
输出 (Output_dw): 计算完成后,我们得到一个新的
1x2x4x4的张量。假设计算结果如下(为清晰起见,这里是示意值):
通道1输出 (out_c1):
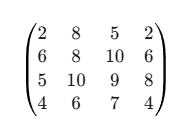
通道2输出 (out_c2):

关键点: 注意,此时通道之间没有信息交换。每个通道还是在独立存在
第2步: 层归一化 (Layer Normalization)
目的: 对上一步的输出进行归一化,稳定训练。与BatchNorm不同,LayerNorm是在每个样本内部,对所有通道的所有像素值一起进行归一化。
操作:
1.计算 Output_dw 这个 2x4x4 张量中所有 2 * 4 * 4 = 32 个值的均值 (mean) 和标准差 (std)。
2.对这32个值中的每一个应用公式: value' = (value - mean) / std。
输出 (Output_ln): 得到一个 1x2x4x4 的归一化后的张量。它的均值接近0,方差接近1。数值会变得很小,这里就不写出具体值了,我们用符号 x_ln 表示。
第3步: 1x1 卷积 (升维)
这是信息在通道间流动的关键一步,也是“倒置瓶颈”的第一步。
-
目的: 将通道数从2扩展到
2 * 2 = 4。 -
卷积核 (Kernel_pw1): 这是一个
1x1的卷积,但它的“深度”非常关键。它有 2个输入通道 和 4个输出通道。所以这个核的尺寸是(in_channels, out_channels, 1, 1),即(2, 4, 1, 1)。 -
操作: 对于特征图上的每一个像素位置,
1x1卷积都做一次“全连接”操作。例如,对于位置(i, j),它拿该位置上所有通道的值[c1_val, c2_val],然后通过一个权重矩阵(2x4的权重)计算出4个新的通道值[new_c1, new_c2, new_c3, new_c4]。 -
输出 (Output_pw1): 我们得到一个
1x4x4x4的张量,通道数成功扩展。我们称之为x_expanded。
第4步: GELU 激活函数
-
操作: 对
x_expanded张量中的每一个元素应用GELU函数。GELU是一个平滑的激活函数,可以看作是ReLU的优化版本。 -
输出 (Output_gelu): 尺寸不变,仍然是
1x4x4x4。负值被平滑地抑制,正值基本保留。我们称之为x_activated。
第5步: 1x1 卷积 (降维)
“倒置瓶颈”的收缩步骤。
-
目的: 将通道数从4个“压缩”回原始的2个。
-
卷积核 (Kernel_pw2): 同样是
1x1卷积,但这次的权重尺寸是(in_channels, out_channels, 1, 1),即(4, 2, 1, 1)。 -
操作: 与升维类似,但在每个像素位置上,它将4个通道的值映射回2个通道的值。
-
输出 (Output_pw2): 得到一个
1x2x4x4的张量。我们称之为x_projected。
第6步: 残差连接 (Residual Connection)
这是ResNet的精髓,ConvNeXt也保留了下来。
-
操作: 将第5步的输出
x_projected与我们最开始的输入x按元素相加。Final_Output = x + x_projected -
输出 (Final_Output): 最终得到一个
1x2x4x4的张量,作为这个ConvNeXt Block的输出,它将被送入下一个Block。
总结数据流
一个 1x2x4x4 的数据 x 进入模块:
-
x-> (3x3 深度卷积) ->Output_dw(1x2x4x4) -
Output_dw-> (LayerNorm) ->x_ln(1x2x4x4) -
x_ln-> (1x1 卷积, 升维) ->x_expanded(1x4x4x4) -
x_expanded-> (GELU) ->x_activated(1x4x4x4) -
x_activated-> (1x1 卷积, 降维) ->x_projected(1x2x4x4) -
x_projected+x-> (残差相加) ->Final_Output(1x2x4x4)


















 3738
3738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









