




使用Python爬虫自动化爬取豆瓣电影数据 🎬
最近我完成了一个有趣的Python项目:使用爬虫技术自动化获取豆瓣电影数据!接触过爬虫的同学应该都清楚如果单纯爬取豆瓣Top250榜单的数据相对容易,但是要爬取完整电影榜单数据却绝非易事,但是这个问题也没有特别复杂,我花了2个小时解决搞定了!这个项目不仅包含了电影基本信息,还抓取了用户评论和评分分布。让我来分享一下实现过程和代码细节。
项目概述 📋
这个项目主要实现了以下功能:
- 🔍 自动爬取多个电影标签下的电影列表
- 🎯 获取每部电影的详细信息(评分、演员、导演、简介等)
- 💬 爬取用户评论数据
- 💾 将数据存储到CSV文件和MySQL数据库
- 🖼️ 下载电影海报图片
技术栈 🛠️
import pandas as pd
import pymysql
import requests
import re
from bs4 import BeautifulSoup
from lxml import etree
import time
核心代码解析 🔍
1. 获取电影列表
def get_movies(start, tag):
url = "https://movie.douban.com/j/search_subjects?"
data = {
"type": "movie",
"tag": f"{tag}",
"sort": "time",
"page_limit": "20",
"page_start": "%d" % start
}
# 使用移动端User-Agent避免被反爬
headers = {
'User-Agent': "Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X)..."
}
html = requests.get(url, headers=headers, params=data, cookies=cookies)
info = html.json()
# 提取电影URL和ID
return urls, nums
关键点:
- 使用豆瓣的搜索API接口
- 分页获取数据(每页20条)
- 模拟移动端请求降低被封风险
2. 解析电影详情
def get_media(url, num):
response = requests.get(url, headers=headers, cookies=cookies)
html = etree.HTML(res)
# 使用XPath提取各种信息
name = html.xpath('//*[@id="content"]/h1/span[1]/text()')
score = html.xpath('//*[@id="interest_sectl"]/div/div[2]/strong/text()')[0]
actors = html.xpath('//*[@id="info"]/span[3]/span[2]/a/text()')
# ... 更多字段提取
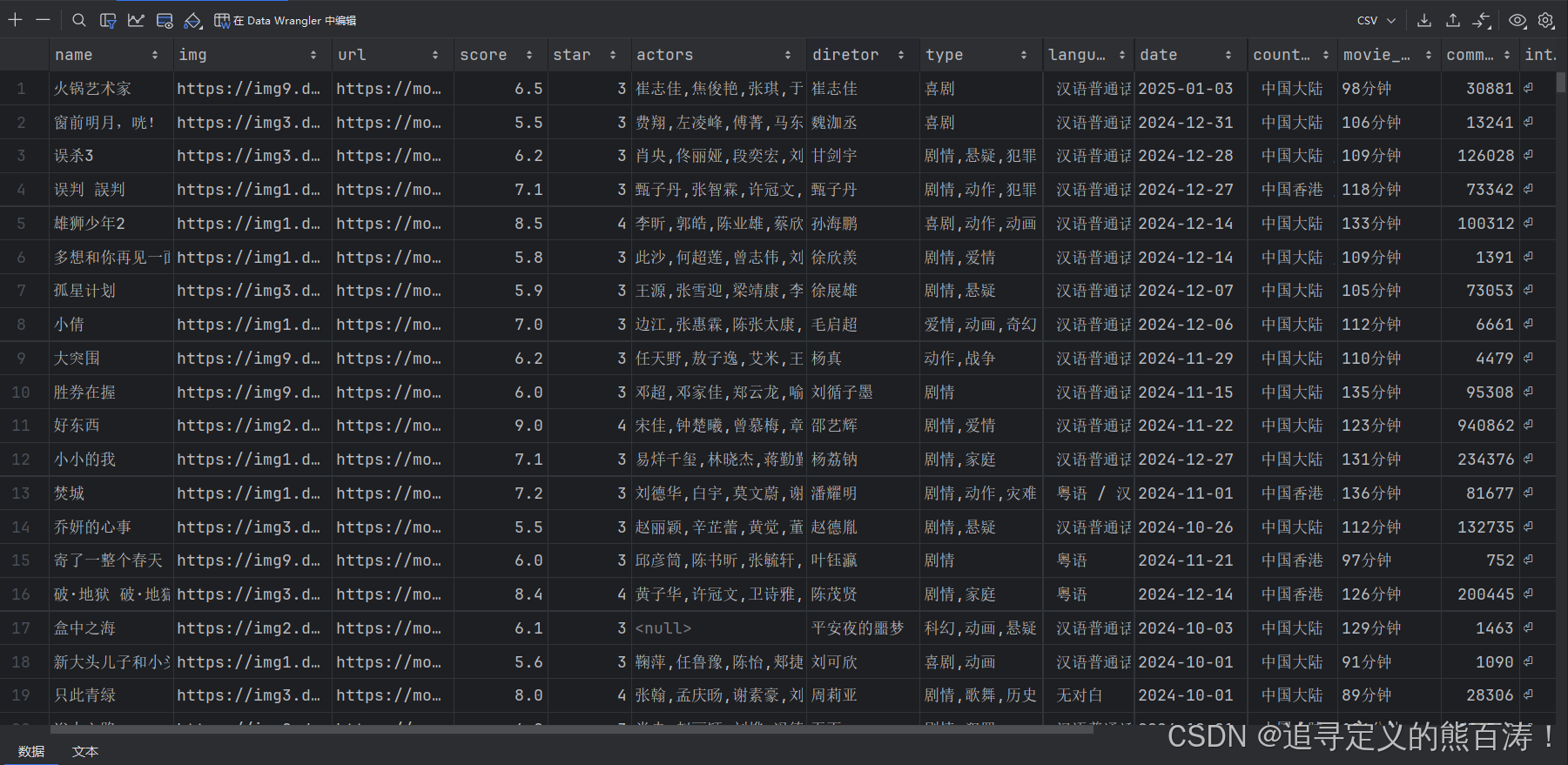
提取的信息包括:
- 🎭 电影名称、评分、星级
- 👥 演员、导演信息
- 🏷️ 电影类型、语言、国家
- 📅 上映日期、片长
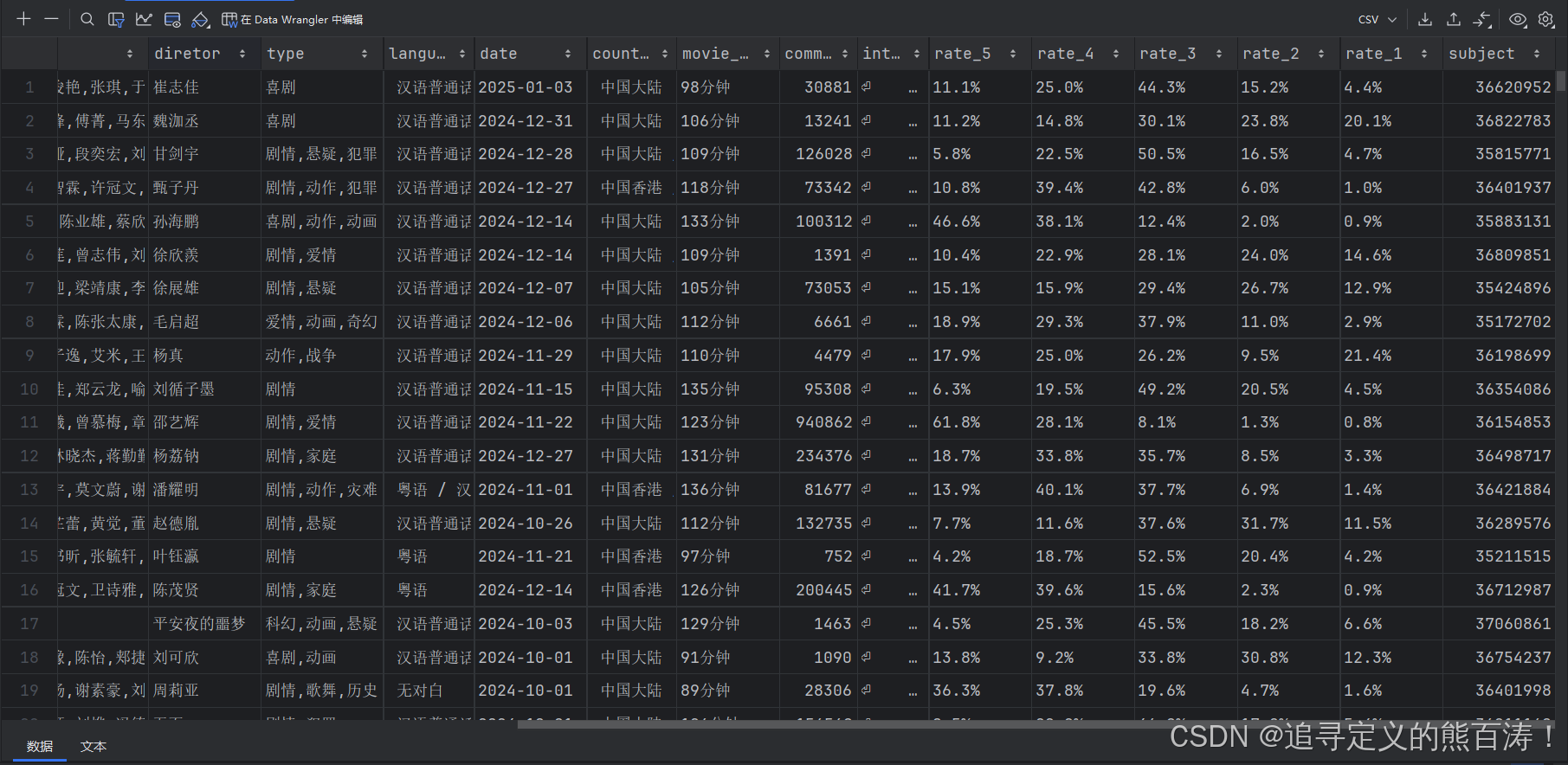
- 📊 评分分布(1-5星比例)
- 📝 电影简介
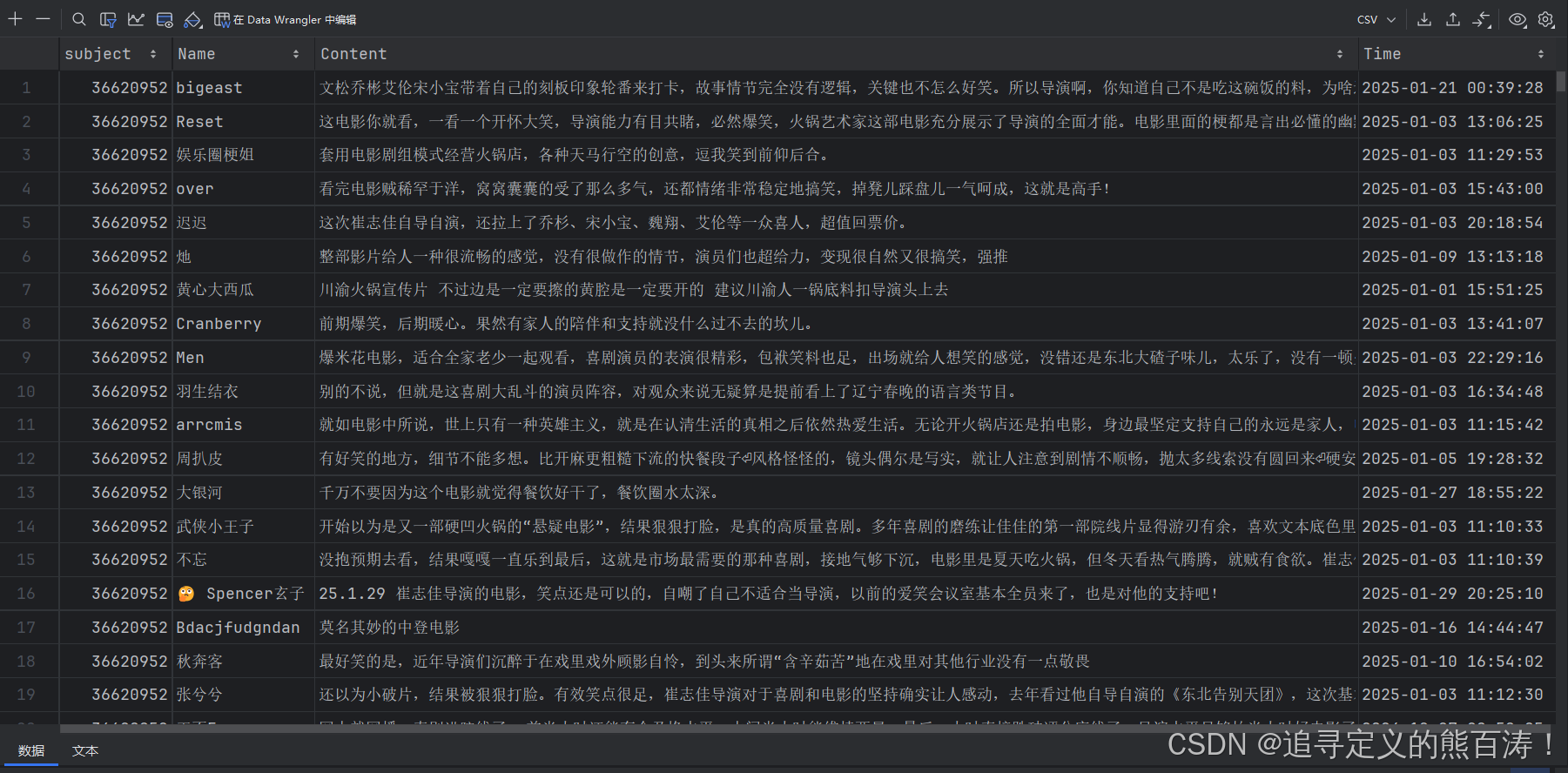
3. 下载用户评论
def downloadComments(subject):
params = {
'start': str(1 * 20),
'limit': '20',
'sort': 'new_score',
'comments_only': '1',
}
response = requests.get(f'https://movie.douban.com/subject/{subject}/comments',
params=params, cookies=cookies, headers=headers)
html = response.json()['html']
soup = BeautifulSoup(html, 'html.parser')
# 解析评论内容
4. 数据存储
def conn_sql():
# 使用Django ORM批量插入数据
movies = []
for _, row in data.iterrows():
movie = Movie(
name=row['name'],
img=row['img'],
score=row['score'],
# ... 其他字段
)
movies.append(movie)
# 每1000条记录批量插入一次
if len(movies) >= 1000:
Movie.objects.bulk_create(movies)
movies = []
反爬虫策略应对 🛡️
项目中采用了多种反爬虫应对措施:
-
使用Cookies 🍪
- 维持登录状态
- 避免被重定向到登录页
-
请求头伪装 🎭
- 设置合理的User-Agent
- 添加Referer等必要头部
-
请求频率控制 ⏰
time.sleep(2) # 每次请求间隔2秒 -
异常处理 🚨
try: # 爬取逻辑 except Exception as e: print('有风控请稍后再尝试')
项目特色 ✨
- 多标签覆盖:支持17个不同电影标签
- 数据完整性:从基本信息到用户评论全面覆盖
- 高效存储:使用批量插入优化数据库性能
- 错误恢复:完善的异常处理机制
- 模块化设计:各功能独立,便于维护扩展
使用示例 🚀
if __name__ == "__main__":
tags = ["热门", "最新", "经典", "喜剧", "爱情", "科幻"]
for tag in tags:
start = 0
while start < 100: # 每标签爬取5页
urls, nums = get_movies(start, tag)
for url, num in zip(urls, nums):
movie_data = get_media(url, num)
# 处理数据...
start += 20
注意事项 ⚠️
- 遵守robots.txt:尊重网站爬虫协议
- 控制请求频率:避免对目标网站造成压力
- 数据使用:仅用于学习和研究目的
- Cookie更新:定期检查并更新cookies
总结 🎉
这个项目展示了如何使用Python爬虫技术构建一个完整的电影数据采集系统。通过合理的代码结构和反爬虫策略,我们能够高效、稳定地获取所需数据。
项目亮点:
- ✅ 完整的数据采集流程
- ✅ 健壮的错误处理机制
- ✅ 高效的数据存储方案
- ✅ 可扩展的架构设计
希望这个项目对学习Python爬虫技术的朋友们有所帮助!如果你有任何问题或建议,欢迎在评论区讨论 💬
注:本文仅用于技术交流学习,请遵守相关网站的使用条款,合理使用爬虫技术。



















 1930
1930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











