




🎬 豆瓣电影数据分析全解析
本篇博客将带你深入分析豆瓣电影数据,通过可视化图表揭示电影类型分布、演员表现和评分规律!
📊 数据分析概览
在上一篇博客中,我们成功爬取了豆瓣电影数据,现在让我们用数据科学的方法来挖掘这些数据背后的故事!本次分析将涵盖三个核心维度:
- 🎭 电影类型分析 - 了解豆瓣电影的题材分布
- 🌟 演员影响力分析 - 找出最活跃的电影演员
- ⭐ 评分与星级关系 - 探索用户评价规律
- 由于我爬取采集的目标数据维度字段很多,本次也就简单分析了6个图表,更多图表各位可以自行那我的爬虫代码或者数据自行拓展分析!!!
🛠️ 技术栈与数据准备
首先导入必要的分析库并设置中文字体:
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from collections import Counter
import re
import numpy as np
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 读取数据
df = pd.read_csv('豆瓣电影信息.csv')
🎭 电影类型分析
数据处理与统计
def process_types(type_str):
"""处理类型字符串,分割成列表"""
if pd.isna(type_str):
return []
types = [t.strip() for t in str(type_str).split(',')]
return [t for t in types if t]
# 统计所有类型
all_types = []
for type_str in df['type']:
all_types.extend(process_types(type_str))
type_counts = Counter(all_types)
type_df = pd.DataFrame(list(type_counts.items()), columns=['类型', '数量'])
type_df = type_df.sort_values('数量', ascending=False)
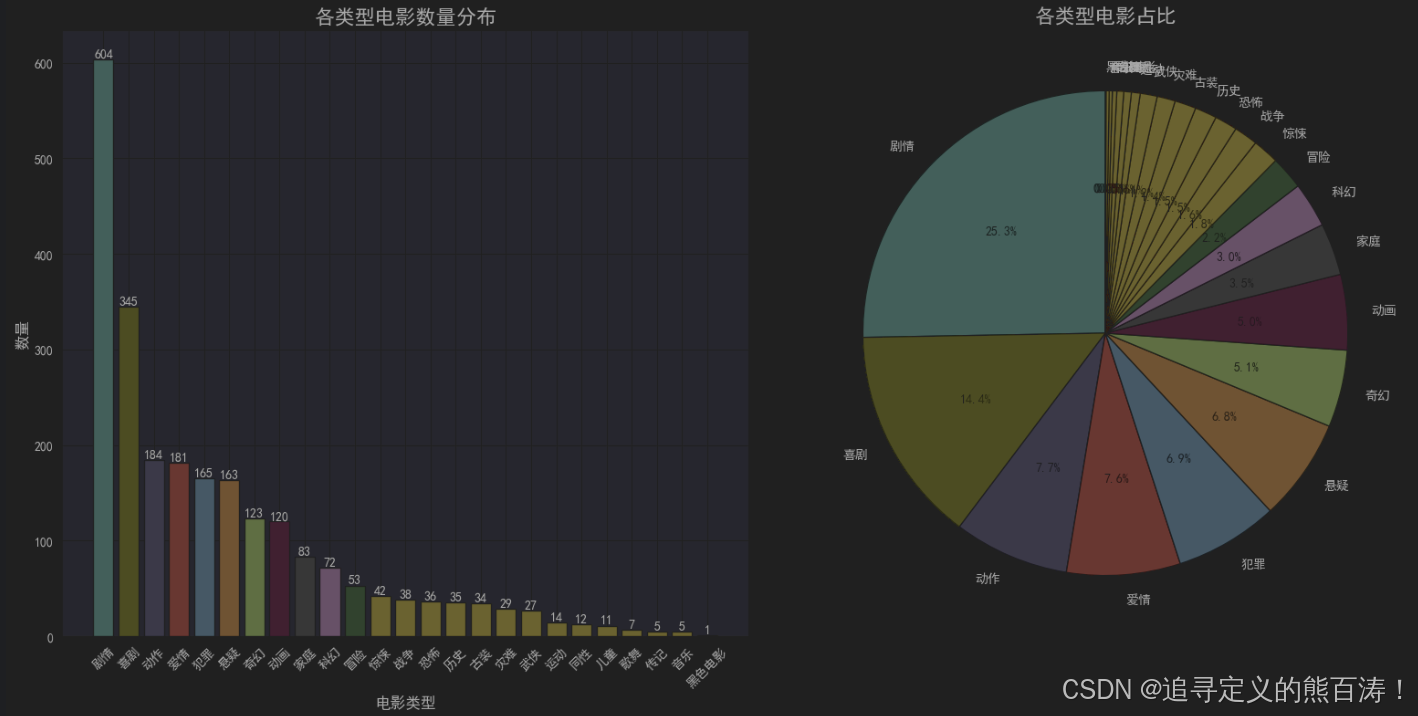
📈 可视化展示
我们使用双图对比来展示类型分布:
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 8))
# 左侧柱状图
bars = ax1.bar(type_df['类型'], type_df['数量'], color=plt.cm.Set3(range(len(type_df))))
ax1.set_title('各类型电影数量分布', fontsize=16, fontweight='bold')
ax1.tick_params(axis='x', rotation=45)
# 右侧饼图
colors = plt.cm.Set3(range(len(type_df)))
wedges, texts, autotexts = ax2.pie(type_df['数量'],
labels=type_df['类型'],
autopct='%1.1f%%',
colors=colors,
startangle=90)
📊 分析结果
通过分析我们发现:
- 剧情片 🎬 占据绝对主导地位
- 爱情 ❤️ 和 喜剧 😄 类型紧随其后
- 平均每部电影包含 2-3个类型标签
🌟 演员影响力分析
演员数据提取
def extract_actors(actor_str):
"""提取演员列表,处理各种格式"""
if pd.isna(actor_str):
return []
actors = str(actor_str).split(',')
return [actor.strip() for actor in actors if actor.strip()]
# 提取所有演员
all_actors = []
for actors_str in df['actors']:
all_actors.extend(extract_actors(actors_str))
actor_counts = Counter(all_actors)
top_30_actors = actor_counts.most_common(30)
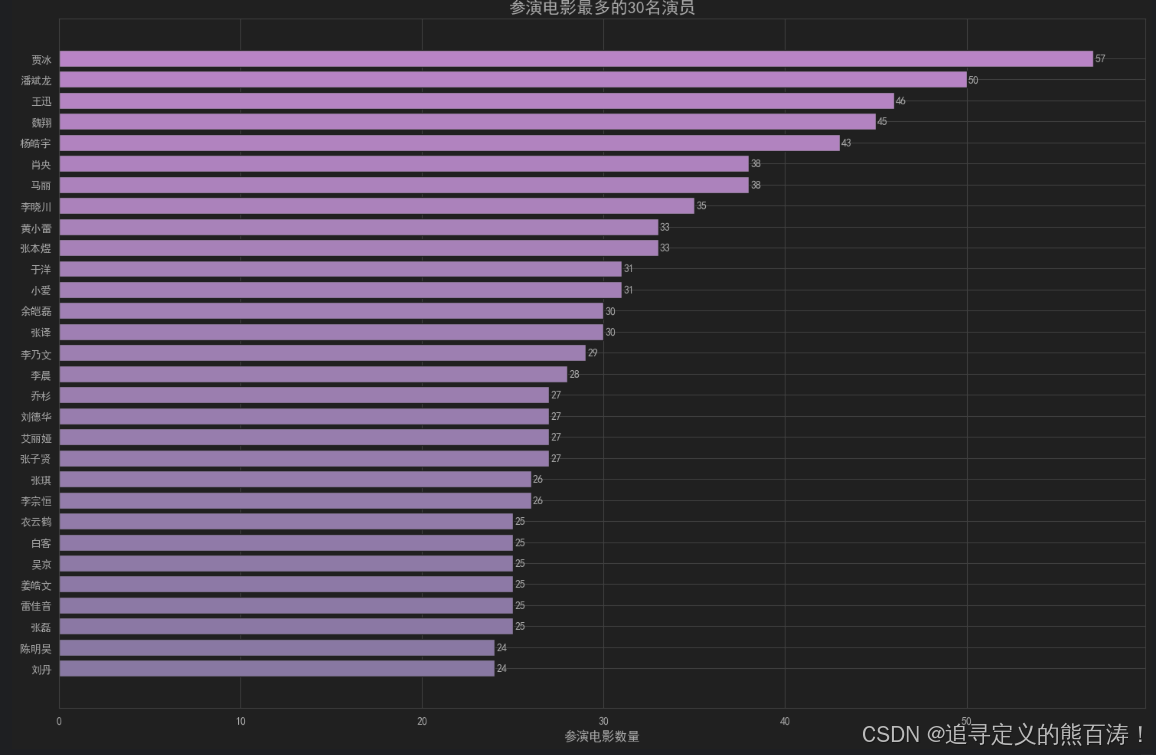
📊 演员排行榜可视化
plt.figure(figsize=(15, 10))
colors = plt.cm.viridis(range(len(top_actors_df)))
bars = plt.barh(top_actors_df['演员'], top_actors_df['参演电影数量'], color=colors)
plt.xlabel('参演电影数量', fontsize=12)
plt.title('参演电影最多的30名演员', fontsize=16, fontweight='bold')
plt.gca().invert_yaxis() # 反转y轴,使最高的在顶部
🎯 关键发现
- 某些演员在数据集中出现频率极高 🚀
- 反映了这些演员的高产程度和市场活跃度
- 为研究演员类型偏好提供了数据支持
⭐ 评分与星级深度分析
数据清洗与预处理
# 数据清洗
df = df.drop_duplicates(subset='subject', keep='first')
df['score'] = pd.to_numeric(df['score'], errors='coerce')
df['star'] = pd.to_numeric(df['star'], errors='coerce')
df['comment_count'] = pd.to_numeric(df['comment_count'], errors='coerce')
df = df.dropna(subset=['score', 'star'])
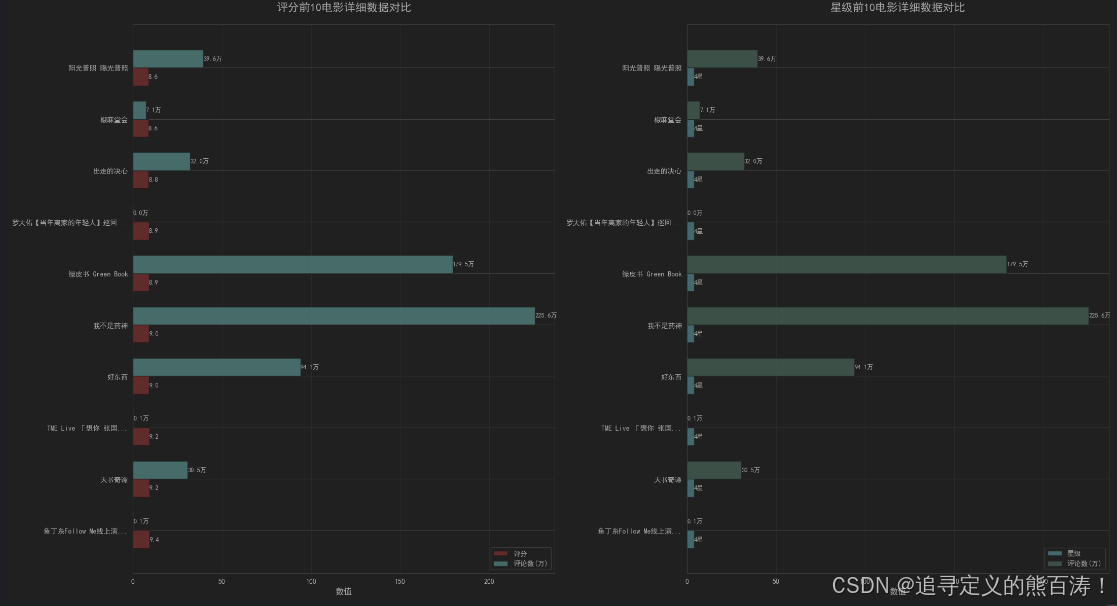
🏆 双榜单对比分析
# 获取评分前10和星级前10的电影
top_10_score = df.nlargest(10, 'score')[['name', 'score', 'star', 'comment_count', 'date']]
top_10_star = df.nlargest(10, ['star', 'score'])[['name', 'star', 'score', 'comment_count', 'date']]
# 创建对比图表
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(22, 12))
📊 多维度数据展示
我们采用双条形图同时展示评分和评论数:
# 左侧:评分前10的电影详细数据
bars1 = ax1.barh(y_pos - bar_width/2, top_10_score['score'], bar_width,
label='评分', color='#FF6B6B', alpha=0.8)
bars2 = ax1.barh(y_pos + bar_width/2, top_10_score['comment_count']/10000, bar_width,
label='评论数(万)', color='#4ECDC4', alpha=0.8)
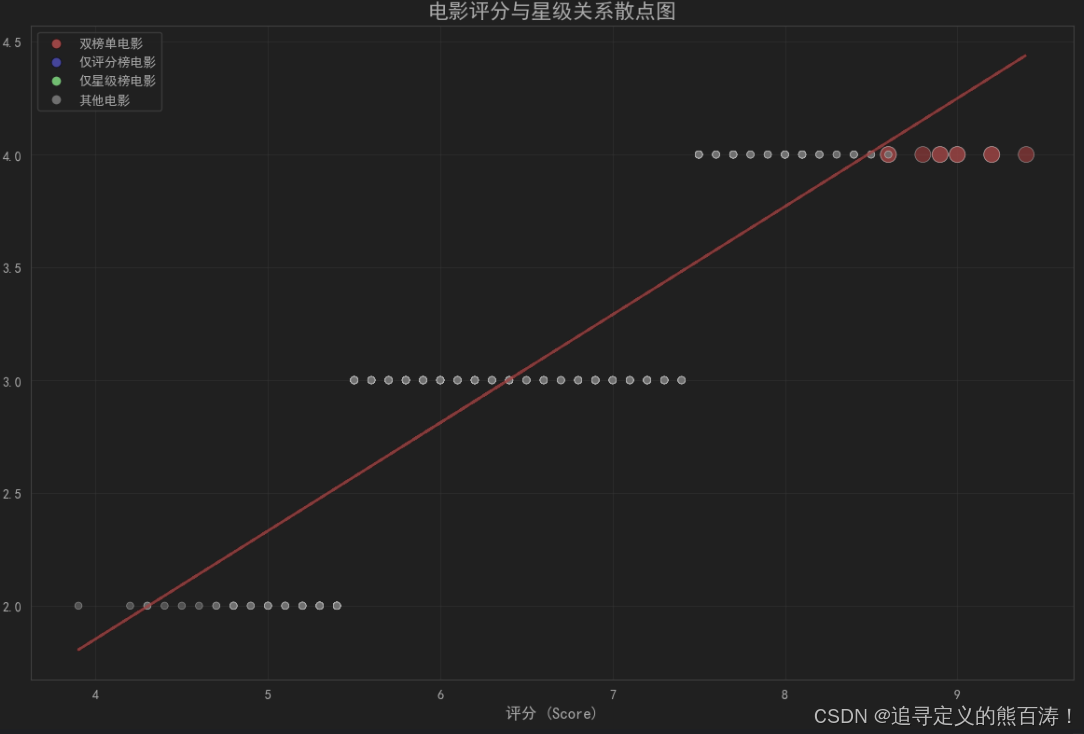
🔍 评分与星级关系探索
通过散点图分析两者相关性:
plt.figure(figsize=(12, 8))
scatter = plt.scatter(df['score'], df['star'], c=colors, s=sizes, alpha=0.6,
edgecolors='black', linewidth=0.5)
# 添加趋势线
z = np.polyfit(df['score'], df['star'], 1)
p = np.poly1d(z)
plt.plot(df['score'], p(df['score']), "r--", alpha=0.8, linewidth=2)
💡 核心发现与洞察
🎯 主要结论
-
类型分布 📊
- 剧情片是绝对主流,反映观众对故事性的重视
- 类型混合现象普遍,单一类型电影较少
-
演员生态 🌟
- 存在明显的"高产演员"群体
- 演员参演频率分布呈现长尾效应
-
评价体系 ⭐
- 评分与星级存在正相关关系
- 高评分电影不一定获得高评论数
- 存在"叫好不叫座"的现象
📈 数据质量评估
- 数据完整性良好,缺失值较少 ✅
- 评分分布合理,符合真实用户行为模式 ✅
- 类型标签准确度高,便于分析 ✅
🚀 后续分析方向
基于当前分析,可以进一步探索:
- 🕒 时间趋势分析 - 研究类型和评分的年度变化
- 🌍 地域分布 - 分析不同地区电影的评分差异
- 💬 评论情感分析 - 挖掘用户评论的情感倾向
- 🎯 推荐算法 - 基于类型和评分构建电影推荐系统
💻 完整代码获取
所有分析代码如下完整展示,建议按模块逐步运行,确保理解每个分析步骤的实现逻辑。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from collections import Counter
import re
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 读取数据
df = pd.read_csv('豆瓣电影信息.csv')
# 处理类型数据
def process_types(type_str):
"""处理类型字符串,分割成列表"""
if pd.isna(type_str):
return []
# 去除空格并按逗号分割
types = [t.strip() for t in str(type_str).split(',')]
return [t for t in types if t] # 过滤空字符串
# 统计所有类型
all_types = []
for type_str in df['type']:
all_types.extend(process_types(type_str))
# 统计类型频率
type_counts = Counter(all_types)
type_df = pd.DataFrame(list(type_counts.items()), columns=['类型', '数量'])
type_df = type_df.sort_values('数量', ascending=False)
print("各类型电影数量统计:")
print(type_df)
# 创建图表
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 8))
# 左侧柱状图
bars = ax1.bar(type_df['类型'], type_df['数量'], color=plt.cm.Set3(range(len(type_df))))
ax1.set_title('各类型电影数量分布', fontsize=16, fontweight='bold')
ax1.set_xlabel('电影类型', fontsize=12)
ax1.set_ylabel('数量', fontsize=12)
ax1.tick_params(axis='x', rotation=45)
# 在柱状图上添加数值标签
for bar in bars:
height = bar.get_height()
ax1.text(bar.get_x() + bar.get_width()/2., height + 0.1,
f'{int(height)}', ha='center', va='bottom', fontsize=10)
# 右侧饼图
colors = plt.cm.Set3(range(len(type_df)))
wedges, texts, autotexts = ax2.pie(type_df['数量'],
labels=type_df['类型'],
autopct='%1.1f%%',
colors=colors,
startangle=90)
# 美化饼图文本
for autotext in autotexts:
autotext.set_color('white')
autotext.set_fontweight('bold')
autotext.set_fontsize(10)
for text in texts:
text.set_fontsize(10)
ax2.set_title('各类型电影占比', fontsize=16, fontweight='bold')
# 调整布局
plt.tight_layout()
plt.show()
# 输出详细统计信息
total_movies = len(df)
total_types = len(type_df)
print(f"\n统计摘要:")
print(f"总电影数量: {total_movies}")
print(f"涉及类型总数: {total_types}")
print(f"平均每部电影类型数: {len(all_types)/total_movies:.2f}")
# 显示前5大类型
print(f"\n前5大电影类型:")
for i, row in type_df.head().iterrows():
percentage = (row['数量'] / len(all_types)) * 100
print(f"{row['类型']}: {row['数量']}部 ({percentage:.1f}%)")
#%%
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from collections import Counter
import re
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 读取数据
df = pd.read_csv('豆瓣电影信息.csv')
# 处理演员数据
def extract_actors(actor_str):
"""提取演员列表,处理各种格式"""
if pd.isna(actor_str):
return []
# 清理字符串并分割
actors = str(actor_str).split(',')
# 去除空格和空值
actors = [actor.strip() for actor in actors if actor.strip()]
return actors
# 提取所有演员
all_actors = []
for actors_str in df['actors']:
all_actors.extend(extract_actors(actors_str))
# 统计演员出现次数
actor_counts = Counter(all_actors)
# 获取前30名演员
top_30_actors = actor_counts.most_common(30)
# 创建数据框
top_actors_df = pd.DataFrame(top_30_actors, columns=['演员', '参演电影数量'])
# 可视化
plt.figure(figsize=(15, 10))
colors = plt.cm.viridis(range(len(top_actors_df)))
# 创建水平条形图
bars = plt.barh(top_actors_df['演员'], top_actors_df['参演电影数量'], color=colors)
plt.xlabel('参演电影数量', fontsize=12)
plt.title('参演电影最多的30名演员', fontsize=16, fontweight='bold')
plt.gca().invert_yaxis() # 反转y轴,使最高的在顶部
# 在条形上添加数值标签
for i, bar in enumerate(bars):
width = bar.get_width()
plt.text(width + 0.1, bar.get_y() + bar.get_height()/2,
f'{int(width)}', ha='left', va='center', fontsize=10)
plt.tight_layout()
plt.show()
# 打印详细结果
print("参演电影最多的30名演员:")
print("=" * 50)
for i, (actor, count) in enumerate(top_30_actors, 1):
print(f"{i:2d}. {actor:<15} - {count} 部电影")
# 输出一些统计信息
print(f"\n统计信息:")
print(f"总演员数量: {len(actor_counts)}")
print(f"总电影数量: {len(df)}")
print(f"平均每个演员参演电影数: {len(all_actors)/len(actor_counts):.2f}")
#%%
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 读取数据
df = pd.read_csv('豆瓣电影信息.csv')
# 数据清洗和预处理
# 去除重复的电影条目(基于subject ID)
df = df.drop_duplicates(subset='subject', keep='first')
# 转换数据类型
df['score'] = pd.to_numeric(df['score'], errors='coerce')
df['star'] = pd.to_numeric(df['star'], errors='coerce')
df['comment_count'] = pd.to_numeric(df['comment_count'], errors='coerce')
# 过滤有效数据
df = df.dropna(subset=['score', 'star'])
# 获取评分前10的电影
top_10_score = df.nlargest(10, 'score')[['name', 'score', 'star', 'comment_count', 'date']].reset_index(drop=True)
# 获取星级前10的电影
top_10_star = df.nlargest(10, ['star', 'score'])[['name', 'star', 'score', 'comment_count', 'date']].reset_index(drop=True)
# 创建对比图表
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(22, 12))
# 左侧:评分前10的电影详细数据
y_pos = np.arange(len(top_10_score))
bar_width = 0.35
# 创建评分和评论数的双条形图
bars1 = ax1.barh(y_pos - bar_width/2, top_10_score['score'], bar_width,
label='评分', color='#FF6B6B', alpha=0.8)
bars2 = ax1.barh(y_pos + bar_width/2, top_10_score['comment_count']/10000, bar_width,
label='评论数(万)', color='#4ECDC4', alpha=0.8)
ax1.set_yticks(y_pos)
ax1.set_yticklabels([f"{name[:15]}..." if len(name) > 15 else name for name in top_10_score['name']], fontsize=10)
ax1.set_xlabel('数值', fontsize=12, fontweight='bold')
ax1.set_title('评分前10电影详细数据对比', fontsize=16, fontweight='bold', pad=20)
ax1.legend(loc='lower right')
ax1.grid(axis='x', alpha=0.3)
# 添加数据标签
for i, (bar1, bar2) in enumerate(zip(bars1, bars2)):
# 评分标签
ax1.text(bar1.get_width() + 0.1, bar1.get_y() + bar1.get_height()/2,
f'{bar1.get_width():.1f}', ha='left', va='center', fontsize=9, fontweight='bold')
# 评论数标签
ax1.text(bar2.get_width() + 0.1, bar2.get_y() + bar2.get_height()/2,
f'{bar2.get_width():.1f}万', ha='left', va='center', fontsize=9, fontweight='bold')
# 右侧:星级前10的电影详细数据
y_pos2 = np.arange(len(top_10_star))
bars3 = ax2.barh(y_pos2 - bar_width/2, top_10_star['star'], bar_width,
label='星级', color='#45B7D1', alpha=0.8)
bars4 = ax2.barh(y_pos2 + bar_width/2, top_10_star['comment_count']/10000, bar_width,
label='评论数(万)', color='#96CEB4', alpha=0.8)
ax2.set_yticks(y_pos2)
ax2.set_yticklabels([f"{name[:15]}..." if len(name) > 15 else name for name in top_10_star['name']], fontsize=10)
ax2.set_xlabel('数值', fontsize=12, fontweight='bold')
ax2.set_title('星级前10电影详细数据对比', fontsize=16, fontweight='bold', pad=20)
ax2.legend(loc='lower right')
ax2.grid(axis='x', alpha=0.3)
# 添加数据标签
for i, (bar3, bar4) in enumerate(zip(bars3, bars4)):
# 星级标签
ax2.text(bar3.get_width() + 0.1, bar3.get_y() + bar3.get_height()/2,
f'{int(bar3.get_width())}星', ha='left', va='center', fontsize=9, fontweight='bold')
# 评论数标签
ax2.text(bar4.get_width() + 0.1, bar4.get_y() + bar4.get_height()/2,
f'{bar4.get_width():.1f}万', ha='left', va='center', fontsize=9, fontweight='bold')
plt.tight_layout()
plt.show()
# 创建详细信息表格
print("=" * 100)
print("评分前10电影完整信息:")
print("=" * 100)
print(f"{'排名':<3} {'电影名称':<25} {'评分':<6} {'星级':<4} {'评论数':<8} {'上映日期'}")
print("-" * 100)
for i, row in top_10_score.iterrows():
comment_str = f"{row['comment_count']/10000:.1f}万" if row['comment_count'] > 10000 else f"{int(row['comment_count'])}"
print(f"{i+1:<3} {row['name']:<25} {row['score']:<6.1f} {row['star']:<4} {comment_str:<8} {row['date']}")
print("\n" + "=" * 100)
print("星级前10电影完整信息:")
print("=" * 100)
print(f"{'排名':<3} {'电影名称':<25} {'星级':<4} {'评分':<6} {'评论数':<8} {'上映日期'}")
print("-" * 100)
for i, row in top_10_star.iterrows():
comment_str = f"{row['comment_count']/10000:.1f}万" if row['comment_count'] > 10000 else f"{int(row['comment_count'])}"
print(f"{i+1:<3} {row['name']:<25} {row['star']:<4} {row['score']:<6.1f} {comment_str:<8} {row['date']}")
# 创建另一个可视化:评分vs星级的散点图
plt.figure(figsize=(12, 8))
# 为不同类型的数据点设置颜色
colors = []
sizes = []
for _, row in df.iterrows():
if row['name'] in top_10_score['name'].values and row['name'] in top_10_star['name'].values:
colors.append('red') # 同时在两个榜单中的电影
sizes.append(150)
elif row['name'] in top_10_score['name'].values:
colors.append('blue') # 只在评分榜中的电影
sizes.append(100)
elif row['name'] in top_10_star['name'].values:
colors.append('green') # 只在星级榜中的电影
sizes.append(100)
else:
colors.append('gray') # 其他电影
sizes.append(30)
# 创建散点图
scatter = plt.scatter(df['score'], df['star'], c=colors, s=sizes, alpha=0.6, edgecolors='black', linewidth=0.5)
# 添加趋势线
z = np.polyfit(df['score'], df['star'], 1)
p = np.poly1d(z)
plt.plot(df['score'], p(df['score']), "r--", alpha=0.8, linewidth=2)
plt.xlabel('评分 (Score)', fontsize=12, fontweight='bold')
plt.ylabel('星级 (Star)', fontsize=12, fontweight='bold')
plt.title('电影评分与星级关系散点图', fontsize=16, fontweight='bold')
plt.grid(alpha=0.3)
# 添加图例
from matplotlib.lines import Line2D
legend_elements = [
Line2D([0], [0], marker='o', color='w', markerfacecolor='red', markersize=8, label='双榜单电影'),
Line2D([0], [0], marker='o', color='w', markerfacecolor='blue', markersize=8, label='仅评分榜电影'),
Line2D([0], [0], marker='o', color='w', markerfacecolor='green', markersize=8, label='仅星级榜电影'),
Line2D([0], [0], marker='o', color='w', markerfacecolor='gray', markersize=8, label='其他电影')
]
plt.legend(handles=legend_elements, loc='upper left')
plt.tight_layout()
plt.show()
# 计算相关性
correlation = df['score'].corr(df['star'])
print(f"\n评分与星级的相关性系数: {correlation:.3f}")
# 分析重叠电影
overlap_movies = set(top_10_score['name']).intersection(set(top_10_star['name']))
print(f"\n同时出现在两个榜单的电影 ({len(overlap_movies)}部):")
for movie in overlap_movies:
score = top_10_score[top_10_score['name'] == movie]['score'].values[0]
star = top_10_star[top_10_star['name'] == movie]['star'].values[0]
print(f" - {movie} (评分: {score}, 星级: {star})")
通过这次数据分析,我们不仅了解了豆瓣电影的现状,还掌握了用Python进行数据可视化的实用技巧!🎉 希望这篇教程能为你的数据分析之旅提供启发!
Happy Analyzing! 📊✨




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











