 Python+Django电影推荐系统项目
Python+Django电影推荐系统项目





1 前言:
今天分享一个PythonWeb(django)框架搭建的电影推荐系统的项目,这个项目的大概简介如下:
📖 项目实现功能:
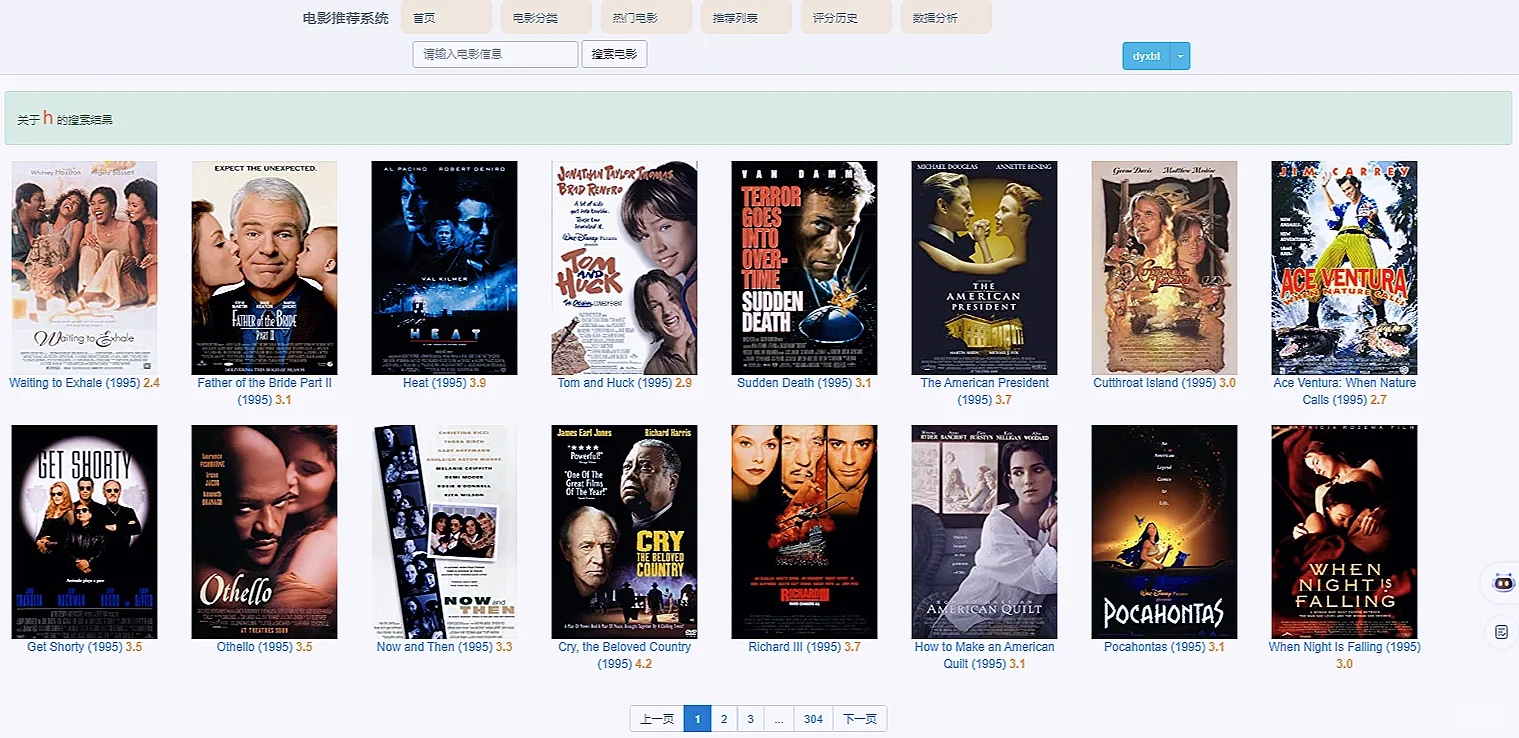
1️⃣首页模块会展示全部的电影影片信息,并有分页和搜索.
2️⃣电影分类模块:展示所有电影的分类信息和不同类别的电影数据.
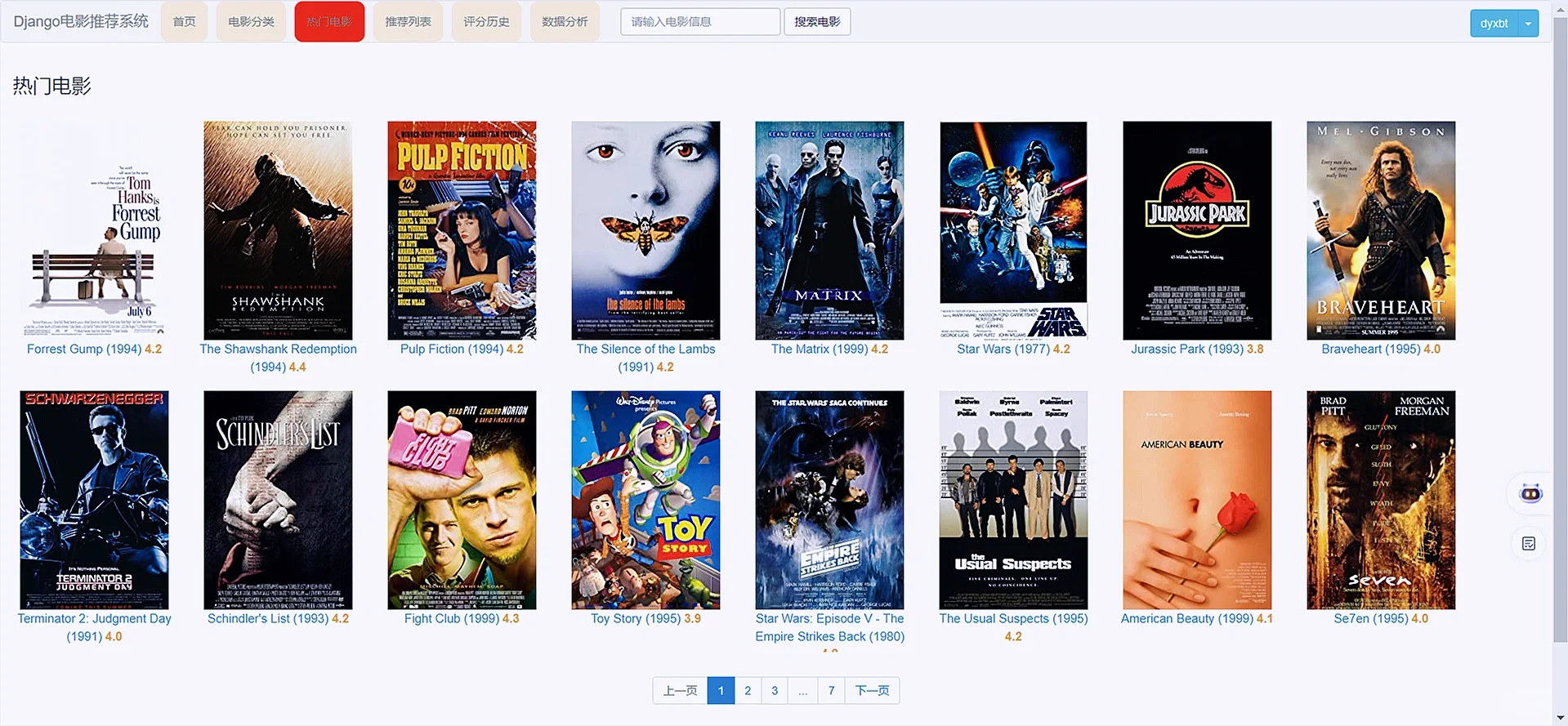
3️⃣热门电影模块:战术热门电影,热门指标根据用户的评分高低就行展示.
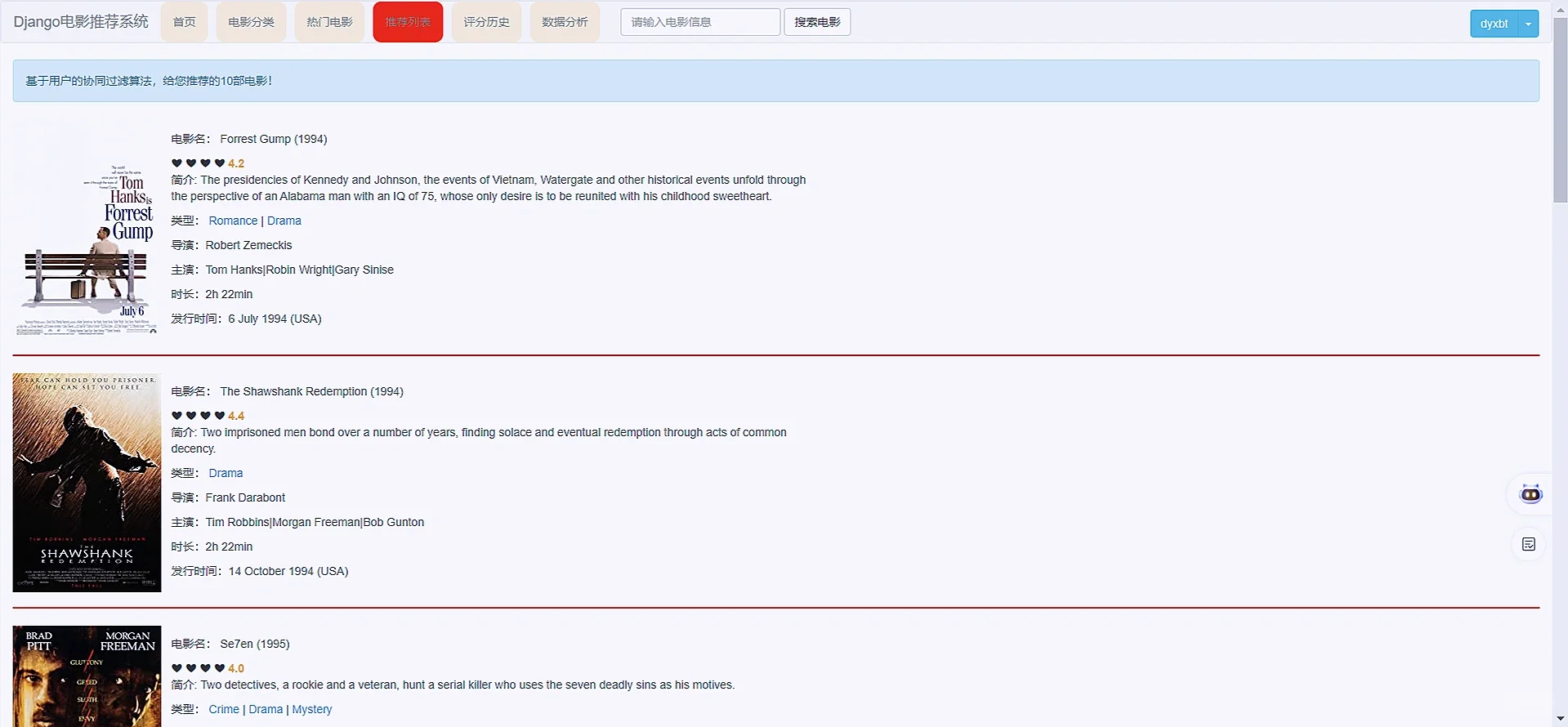
4️⃣推荐模块:根据用户协同过滤算法给用户个性化推荐10个相似度最高的电影.
5️⃣个人信息模块可以修改用户的基本信息,
6️⃣数据分析模块,是对我们这个岗位数据库的一些字段做一个综合的可视化分析!
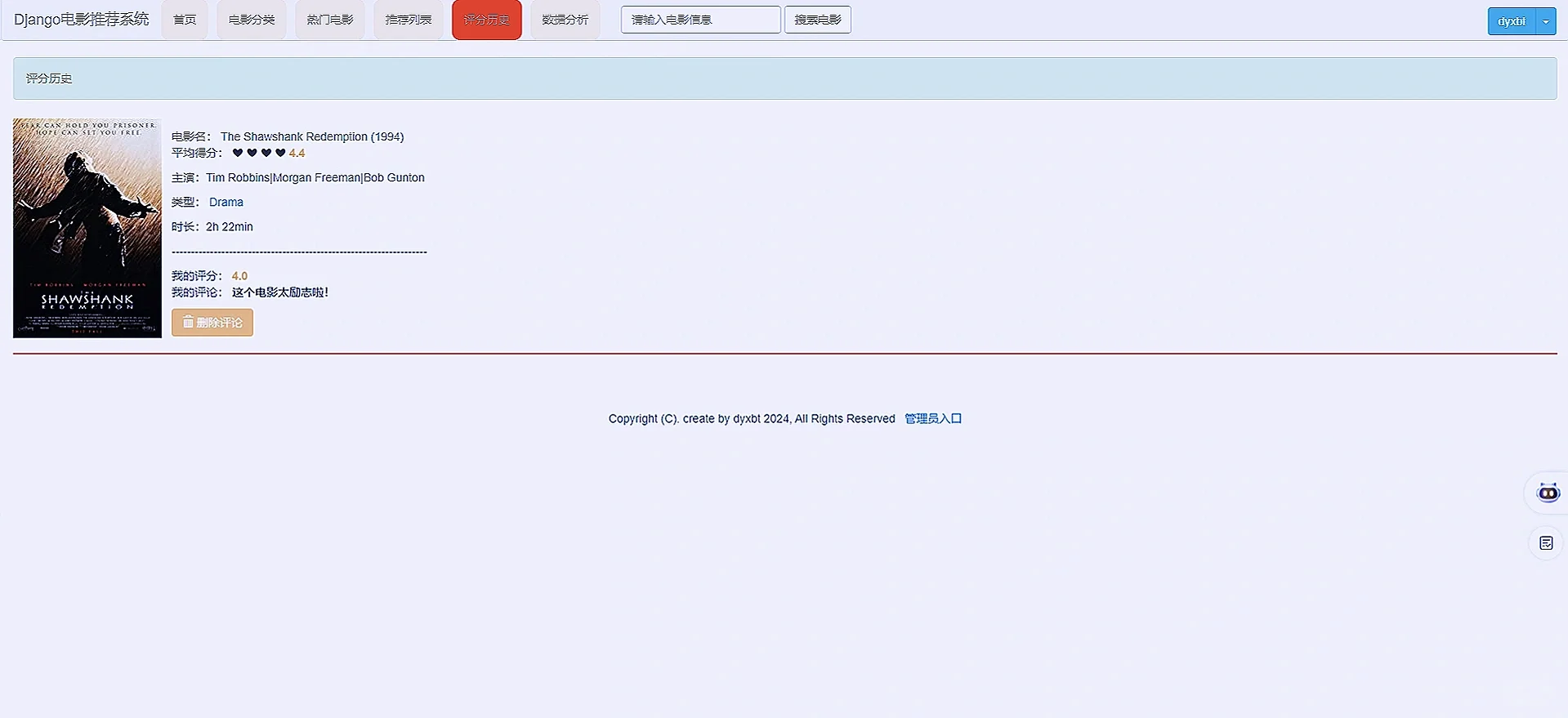
7️⃣评论模块:查看自己评论和评分过的电影数据信息,支持用户删除评论.
8️⃣后台管理呢,我们用到了simpleui的一些管理界面可以对我们数据库的用户以及电影信息以及收藏信息评分信息分类信息,评论信息等等做一个综合处理!
📖涉及技术:Python,Django,mysql,协同过滤算法,前端,后端!
2 项目设计
2.1 数据库设计
根据电影的字段如类型,便需要一个分类表,电影表和这个表应是1对多的关系,用户可以评论和打分自然用户表和评论打分表是要具备的,我们也有一个热门的模块根据浏览量来展示,自然有一个热门表,因为根据电影表的浏览字段的数值而变化自然也是对应关系,至于电影表的字段肯定会要包含名字,分类,分数,浏览次数,作者,导演等一些列基本字段属性,根据这样一个大致的关系,我们便可以创建对应的数据库表结构如下:
from django.db import models
from django.db.models import Avg
# 分类信息表
class Genre(models.Model):
name = models.CharField(max_length=100, verbose_name="类型")
class Meta:
db_table = 'Genre'
verbose_name = '电影类型'
verbose_name_plural = '电影类型'
def __str__(self):
return self.name
# 电影信息表
class Movie(models.Model):
name = models.CharField(max_length=256, verbose_name="电影名")
imdb_id = models.IntegerField(verbose_name="imdb_id")
time = models.CharField(max_length=256, blank=True, verbose_name="时长")
genre = models.ManyToManyField(Genre, verbose_name="类型")
release_time = models.CharField(max_length=256, blank=True, verbose_name="发行时间")
intro = models.TextField(blank=True, verbose_name="简介")
director = models.CharField(max_length=256, blank=True, verbose_name="导演")
writers = models.CharField(max_length=256, blank=True, verbose_name="编剧")
actors = models.CharField(max_length=512, blank=True, verbose_name="演员")
# 电影和电影之间的相似度,A和B的相似度与B和A的相似度是一致的,所以symmetrical设置为True
movie_similarity = models.ManyToManyField("self", through="Movie_similarity", symmetrical=False,
verbose_name="相似电影")
class Meta:
db_table = 'Movie'
verbose_name = '电影信息'
verbose_name_plural = '电影信息'
def __str__(self):
return self.name
# 获取平均分的方法
def get_score(self):
result_dct = self.movie_rating_set.aggregate(Avg('score')) # 格式 {'score__avg': 3.125}
try:
result = round(result_dct['score__avg'], 1) # 只保留一位小数
except TypeError:
return 0
else:
return result
# 获取用户的打分情况
def get_user_score(self, user):
return self.movie_rating_set.filter(user=user).values('score')
# 整数平均分
def get_score_int_range(self):
return range(int(self.get_score()))
# 获取分类列表
def get_genre(self):
genre_dct = self.genre.all().values('name')
genre_lst = []
for dct in genre_dct.values():
genre_lst.append(dct['name'])
return genre_lst
# 获取电影的相识度
def get_similarity(self, k=5):
# 默认获取5部最相似的电影的id
similarity_movies = self.movie_similarity.all()[:k]
return similarity_movies
# 电影相似度
class Movie_similarity(models.Model):
movie_source = models.ForeignKey(Movie, related_name='movie_source', on_delete=models.CASCADE, verbose_name="来源电影")
movie_target = models.ForeignKey(Movie, related_name='movie_target', on_delete=models.CASCADE, verbose_name="目标电影")
similarity = models.FloatField(verbose_name="相似度")
class Meta:
# 按照相似度降序排序
verbose_name = '电影相似度'
verbose_name_plural = '电影相似度'
# 用户信息表
class User(models.Model):
name = models.CharField(max_length=128, unique=True, verbose_name="用户名")
password = models.CharField(max_length=256, verbose_name="密码")
email = models.EmailField(unique=True, verbose_name="邮箱")
rating_movies = models.ManyToManyField(Movie, through="Movie_rating")
def __str__(self):
return "<USER:( name: {:},password: {:},email: {:} )>".format(self.name, self.password, self.email)
class Meta:
db_table = 'User'
verbose_name = '用户信息'
verbose_name_plural = '用户信息'
# 电影评分信息表
class Movie_rating(models.Model):
user = models.ForeignKey(User, on_delete=models.CASCADE, unique=False, verbose_name="用户")
movie = models.ForeignKey(Movie, on_delete=models.CASCADE, unique=False, verbose_name="电影")
score = models.FloatField(verbose_name="分数")
comment = models.TextField(blank=True, verbose_name="评论")
class Meta:
db_table = 'Movie_rating'
verbose_name = '电影评分信息'
verbose_name_plural = '电影评分信息'
# 最热门的一百部电影
class Movie_hot(models.Model):
movie = models.ForeignKey(Movie, on_delete=models.CASCADE, verbose_name="电影名")
rating_number = models.IntegerField(verbose_name="评分人数")
class Meta:
db_table = 'Movie_hot'
verbose_name = '最热电影'
verbose_name_plural = '最热电影'
2.2 后端业务处理
先贴代码,接下来后面会对代码进行大致分析讲解
import os.path
import time
from django.contrib import messages
from django.db.models import Max, Count
from django.http import JsonResponse
from django.shortcuts import render, redirect, reverse
from django.views.generic import View, ListView, DetailView
from .forms import RegisterForm, LoginForm, CommentForm
from .models import User, Movie, Movie_rating, Movie_hot, Genre
BASE = os.path.dirname(os.path.abspath(__file__))
# 首页视图
class IndexView(ListView):
model = Movie
template_name = 'movie/index.html'
paginate_by = 10
context_object_name = 'movies'
ordering = 'imdb_id'
page_kwarg = 'p'
# 返回前1000部电影
def get_queryset(self):
return Movie.objects.filter(imdb_id__lte=1000)
# 获取上下文数据
def get_context_data(self, *, object_list=None, **kwargs):
context = super(IndexView, self).get_context_data(*kwargs)
paginator = context.get('paginator') # 分页器对象
page_obj = context.get('page_obj') # 当前页对象
pagination_data = self.get_pagination_data(paginator, page_obj) # 获取分页数据
context.update(pagination_data) # 返回更新后的上下文数据
return context
# 获取分页数据
def get_pagination_data(self, paginator, page_obj, around_count=2):
current_page = page_obj.number
if current_page <= around_count + 2:
left_pages = range(1, current_page)
left_has_more = False
else:
left_pages = range(current_page - around_count, current_page)
left_has_more = True
if current_page >= paginator.num_pages - around_count - 1:
right_pages = range(current_page + 1, paginator.num_pages + 1)
right_has_more = False
else:
right_pages = range(current_page + 1, current_page + 1 + around_count)
right_has_more = True
return {
'left_pages': left_pages,
'right_pages': right_pages,
'current_page': current_page,
'left_has_more': left_has_more,
'right_has_more': right_has_more
}
# 热门电影视图
class PopularMovieView(ListView):
model = Movie_hot
template_name = 'movie/hot.html'
paginate_by = 10
context_object_name = 'movies'
page_kwarg = 'p'
def get_queryset(self):
# 初始化 计算评分人数最多的100部电影,并保存到数据库中,(不建议每次都运行)
movies = Movie.objects.annotate(nums=Count('movie_rating__score')).order_by('-nums')[:100]
for movie in movies:
record = Movie_hot(movie=movie, rating_number=movie.nums)
record.save()
hot_movies = Movie_hot.objects.all().values("movie_id")
movies = Movie.objects.filter(id__in=hot_movies).annotate(nums=Max('movie_hot__rating_number')).order_by(
'-nums')
return movies
def get_context_data(self, *, object_list=None, **kwargs):
context = super(PopularMovieView, self).get_context_data(*kwargs)
paginator = context.get('paginator')
page_obj = context.get('page_obj')
pagination_data = self.get_pagination_data(paginator, page_obj)
context.update(pagination_data)
return context
def get_pagination_data(self, paginator, page_obj, around_count=2):
current_page = page_obj.number
if current_page <= around_count + 2:
left_pages = range(1, current_page)
left_has_more = False
else:
left_pages = range(current_page - around_count, current_page)
left_has_more = True
if current_page >= paginator.num_pages - around_count - 1:
right_pages = range(current_page + 1, paginator.num_pages + 1)
right_has_more = False
else:
right_pages = range(current_page + 1, current_page + 1 + around_count)
right_has_more = True
return {
'left_pages': left_pages,
'right_pages': right_pages,
'current_page': current_page,
'left_has_more': left_has_more,
'right_has_more': right_has_more
}
# 电影分类视图
class TagView(ListView):
model = Movie
template_name = 'movie/tag.html'
paginate_by = 10
context_object_name = 'movies'
page_kwarg = 'p'
# 获取数据
def get_queryset(self):
# 未选择分类
if 'genre' not in self.request.GET.dict().keys() or self.request.GET.dict()['genre'] == "":
movies = Movie.objects.all()
return movies[100:200]
# 有分类选择
else:
movies = Movie.objects.filter(genre__name=self.request.GET.dict()['genre'])
print(movies)
return movies[:100]
def get_context_data(self, *, object_list=None, **kwargs):
context = super(TagView, self).get_context_data(*kwargs)
if 'genre' in self.request.GET.dict().keys():
genre = self.request.GET.dict()['genre']
context.update({'genre': genre})
paginator = context.get('paginator')
page_obj = context.get('page_obj')
pagination_data = self.get_pagination_data(paginator, page_obj)
context.update(pagination_data)
return context
def get_pagination_data(self, paginator, page_obj, around_count=2):
current_page = page_obj.number
if current_page <= around_count + 2:
left_pages = range(1, current_page)
left_has_more = False
else:
left_pages = range(current_page - around_count, current_page)
left_has_more = True
if current_page >= paginator.num_pages - around_count - 1:
right_pages = range(current_page + 1, paginator.num_pages + 1)
right_has_more = False
else:
right_pages = range(current_page + 1, current_page + 1 + around_count)
right_has_more = True
return {
'left_pages': left_pages,
'right_pages': right_pages,
'current_page': current_page,
'left_has_more': left_has_more,
'right_has_more': right_has_more
}
# 搜索电影视图
class SearchView(ListView):
model = Movie
template_name = 'movie/search.html'
paginate_by = 16
context_object_name = 'movies'
page_kwarg = 'p'
def get_queryset(self):
movies = Movie.objects.filter(name__icontains=self.request.GET.dict()['keyword'])
return movies
def get_context_data(self, *, object_list=None, **kwargs):
context = super(SearchView, self).get_context_data(*kwargs)
paginator = context.get('paginator')
page_obj = context.get('page_obj')
pagination_data = self.get_pagination_data(paginator, page_obj)
context.update(pagination_data)
context.update({'keyword': self.request.GET.dict()['keyword']})
return context
def get_pagination_data(self, paginator, page_obj, around_count=2):
current_page = page_obj.number
if current_page <= around_count + 2:
left_pages = range(1, current_page)
left_has_more = False
else:
left_pages = range(current_page - around_count, current_page)
left_has_more = True
if current_page >= paginator.num_pages - around_count - 1:
right_pages = range(current_page + 1, paginator.num_pages + 1)
right_has_more = False
else:
right_pages = range(current_page + 1, current_page + 1 + around_count)
right_has_more = True
return {
'left_pages': left_pages,
'right_pages': right_pages,
'current_page': current_page,
'left_has_more': left_has_more,
'right_has_more': right_has_more
}
# 注册视图
class RegisterView(View):
def get(self, request):
return render(request, 'movie/register.html')
def post(self, request):
form = RegisterForm(request.POST)
if form.is_valid():
form.save()
return redirect(reverse('movie:index'))
else:
# 表单验证失败,重定向到注册页面
errors = form.get_errors()
for error in errors:
messages.info(request, error)
print(form.errors.get_json_data())
return redirect(reverse('movie:register'))
# 登录视图
class LoginView(View):
def get(self, request):
return render(request, 'movie/login.html')
def post(self, request):
form = LoginForm(request.POST)
if form.is_valid():
name = form.cleaned_data.get('name')
pwd = form.cleaned_data.get('password')
remember = form.cleaned_data.get('remember')
user = User.objects.filter(name=name, password=pwd).first()
if user:
if remember:
# 设置为None,则表示使用全局的过期时间
request.session.set_expiry(None)
else:
# 立即过期
request.session.set_expiry(0)
# 登录成功,在session 存储当前用户的id,作为标识
request.session['user_id'] = user.id
return redirect(reverse('movie:index'))
else:
messages.info(request, '用户名或者密码错误!')
return redirect(reverse('movie:login'))
else:
errors = form.get_errors()
for error in errors:
messages.info(request, error)
return redirect(reverse('movie:login'))
# 登出,立即销毁session停止会话
def UserLogout(request):
request.session.set_expiry(-1)
return redirect(reverse('movie:index'))
# 电影详情视图
class MovieDetailView(DetailView):
model = Movie
template_name = 'movie/detail.html'
# 上下文对象的名称
context_object_name = 'movie'
# 重写获取上下文方法,增加评分参数
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
# 判断是否登录用
login = True
try:
user_id = self.request.session['user_id']
except KeyError as e:
login = False # 未登录
# 获得电影的pk(这里pk就是id)
pk = self.kwargs['pk']
movie = Movie.objects.get(pk=pk)
if login:
# 已经登录,获取当前用户的历史评分数据
user = User.objects.get(pk=user_id)
rating = Movie_rating.objects.filter(user=user, movie=movie).first()
# 默认值
score = 0
comment = ''
if rating:
score = rating.score
comment = rating.comment
context.update({'score': score, 'comment': comment})
similarity_movies = movie.get_similarity()
# 获取与当前电影最相似的电影
context.update({'similarity_movies': similarity_movies})
# 判断是否登录,没有登录则不显示评分页面
context.update({'login': login})
return context
# 接受评分表单,pk是当前电影的数据库主键id
def post(self, request, pk):
form = CommentForm(request.POST)
if form.is_valid():
# 获取分数和评论
score = form.cleaned_data.get('score')
comment = form.cleaned_data.get('comment')
# 获取用户和电影
user_id = request.session['user_id']
user = User.objects.get(pk=user_id)
movie = Movie.objects.get(pk=pk)
# 更新一条记录
rating = Movie_rating.objects.filter(user=user, movie=movie).first()
if rating:
# 如果存在则更新
# print(rating)
rating.score = score
rating.comment = comment
rating.save()
else:
# 如果不存在则添加
rating = Movie_rating(user=user, movie=movie, score=score, comment=comment)
rating.save()
messages.info(request, "评论成功!")
else:
# 表单没有验证通过
messages.info(request, "评分不能为空!")
return redirect(reverse('movie:detail', args=(pk,)))
# 历史评分视图
class RatingHistoryView(DetailView):
model = User
template_name = 'movie/history.html'
# 上下文对象的名称
context_object_name = 'user'
def get_context_data(self, **kwargs):
# 这里要增加的对象:当前用户打过分的电影历史
context = super().get_context_data(**kwargs)
user_id = self.request.session['user_id']
user = User.objects.get(pk=user_id)
# 获取ratings即可
ratings = Movie_rating.objects.filter(user=user).order_by('-score')
context.update({'ratings': ratings})
return context
# 删除打分评论数据
def delete_recode(request, pk):
movie = Movie.objects.get(pk=pk)
user_id = request.session['user_id']
user = User.objects.get(pk=user_id)
rating = Movie_rating.objects.get(user=user, movie=movie)
rating.delete()
messages.info(request, f"删除 {movie.name} 评分记录成功!")
# 跳转回评分历史
return redirect(reverse('movie:history', args=(user_id,)))
# 推荐电影视图
class RecommendMovieView(ListView):
model = Movie
template_name = 'movie/recommend.html'
paginate_by = 15
context_object_name = 'movies'
ordering = 'movie_rating__score'
page_kwarg = 'p'
def __init__(self):
super().__init__()
# 最相似的20个用户
self.K = 20
# 推荐出10本书
self.N = 10
# 存放当前用户评分过的电影querySet
self.cur_user_movie_qs = None
# 获取用户相似度
def get_user_sim(self):
# 用户相似度字典,格式为{ user_id1:val , user_id2:val , ... }
user_sim_dct = dict()
'''获取用户之间的相似度,存放在user_sim_dct中'''
# 获取当前用户
cur_user_id = self.request.session['user_id']
cur_user = User.objects.get(pk=cur_user_id)
# 获取其它用户
other_users = User.objects.exclude(pk=cur_user_id) # 除了当前用户外的所有用户
# 当前用户评分过的电影
self.cur_user_movie_qs = Movie.objects.filter(user=cur_user)
# 计算当前用户与其他用户共同评分过的电影交集数
for user in other_users:
# 记录感兴趣的数量
user_sim_dct[user.id] = len(Movie.objects.filter(user=user) & self.cur_user_movie_qs)
# 按照key排序value,返回K个最相近的用户(共同评分过的电影交集数更多)
print("user similarity calculated!")
# 格式 [ (user, value), (user, value), ... ]
return sorted(user_sim_dct.items(), key=lambda x: -x[1])[:self.K]
# 获取推荐电影(按照相似用户总得分排序)
def get_recommend_movie(self, user_lst):
# 电影兴趣值字典,{ movie:value, movie:value , ...}
movie_val_dct = dict()
# 用户,相似度
for user, _ in user_lst:
# 获取相似用户评分过的电影,并且不在前用户的评分列表中的,再加上score字段,方便计算兴趣值
movie_set = Movie.objects.filter(user=user).exclude(id__in=self.cur_user_movie_qs).annotate(
score=Max('movie_rating__score'))
for movie in movie_set:
movie_val_dct.setdefault(movie, 0)
# 累计用户的评分
movie_val_dct[movie] += movie.score
return sorted(movie_val_dct.items(), key=lambda x: -x[1])[:self.N]
# 获取数据
def get_queryset(self):
s = time.time()
# 获得最相似的K个用户列表
user_lst = self.get_user_sim()
# 获得推荐电影的id
movie_lst = self.get_recommend_movie(user_lst)
# print(movie_lst)
result_lst = []
for movie, _ in movie_lst:
result_lst.append(movie)
e = time.time()
print(f"算法推荐用时:{e - s}秒!")
return result_lst
def get_context_data(self, *, object_list=None, **kwargs):
context = super(RecommendMovieView, self).get_context_data(*kwargs)
print(context)
paginator = context.get('paginator')
page_obj = context.get('page_obj')
pagination_data = self.get_pagination_data(paginator, page_obj)
context.update(pagination_data)
return context
def get_pagination_data(self, paginator, page_obj, around_count=2):
current_page = page_obj.number
if current_page <= around_count + 2:
left_pages = range(1, current_page)
left_has_more = False
else:
left_pages = range(current_page - around_count, current_page)
left_has_more = True
if current_page >= paginator.num_pages - around_count - 1:
right_pages = range(current_page + 1, paginator.num_pages + 1)
right_has_more = False
else:
right_pages = range(current_page + 1, current_page + 1 + around_count)
right_has_more = True
return {
'left_pages': left_pages,
'right_pages': right_pages,
'current_page': current_page,
'left_has_more': left_has_more,
'right_has_more': right_has_more
}
def data_realize(request):
genres = Genre.objects.annotate(movie_count=Count('movie')).values('name', 'movie_count')
# 构建指定格式的数据结构
result = [
{"value": item["movie_count"], "name": item["name"]}
for item in genres
]
return render(request, 'movie/data_realize.html',{'result': result})2.2.1. 概述
这份代码是一个基于Django框架的电影推荐系统的视图(views)部分,主要负责处理用户请求并返回相应的响应。系统包含电影展示、用户管理、评分评论、推荐算法等核心功能。
2.2.2. 文件结构
导入的模块
import os.path
import time
from django.contrib import messages
from django.db.models import Max, Count
from django.http import JsonResponse
from django.shortcuts import render, redirect, reverse
from django.views.generic import View, ListView, DetailView
from .forms import RegisterForm, LoginForm, CommentForm
from .models import User, Movie, Movie_rating, Movie_hot, Genre- 使用了Django的通用视图类(View, ListView, DetailView)
- 使用了Django的ORM操作(Max, Count)
- 自定义的表单和模型
2.2.3. 主要视图类分析
2.2.3.1 IndexView - 首页视图
**功能**:显示电影列表首页
**特点**:
- 继承自ListView,显示电影列表
- 分页显示,每页10部电影
- 只显示IMDB ID小于等于1000的电影(示例数据)
- 自定义分页逻辑,显示左右各2页的导航
**核心方法**:
- `get_queryset()`: 获取前1000部电影
- `get_pagination_data()`: 自定义分页数据
2.2.3.2 PopularMovieView - 热门电影视图
**功能**:显示评分人数最多的热门电影
**特点**:
- 初始化时会计算评分人数最多的100部电影并保存到Movie_hot表
- 按评分人数降序排列
- 同样实现分页功能
**核心逻辑**:
movies = Movie.objects.annotate(nums=Count('movie_rating__score')).order_by('-nums')[:100]
统计每部电影的评分数量并排序
2.2 3.3 TagView - 电影分类视图
**功能**:按电影类型(genre)筛选电影
**特点**:
- 支持通过URL参数(?genre=类型名)筛选
- 未选择分类时显示100-200的电影(示例数据)
- 同样实现分页功能
2.2.3.4 SearchView - 搜索视图
**功能**:按电影名称关键字搜索
**特点**:
- 使用`icontains`进行不区分大小写的模糊匹配
- 每页显示16部电影
- 保留搜索关键字在页面显示
2.2.3.5 RegisterView - 注册视图
**功能**:用户注册
**特点**:
- 使用自定义的RegisterForm验证数据
- 注册成功跳转首页
- 失败显示错误信息
2.2.3.6 LoginView - 登录视图
**功能**:用户登录
**特点**:
- 使用自定义的LoginForm验证
- 支持"记住我"功能(设置session过期时间)
- 登录成功将user_id存入session
2.2.3.7 MovieDetailView - 电影详情视图
**功能**:显示电影详情和评分评论
**特点**:
- 显示电影详细信息
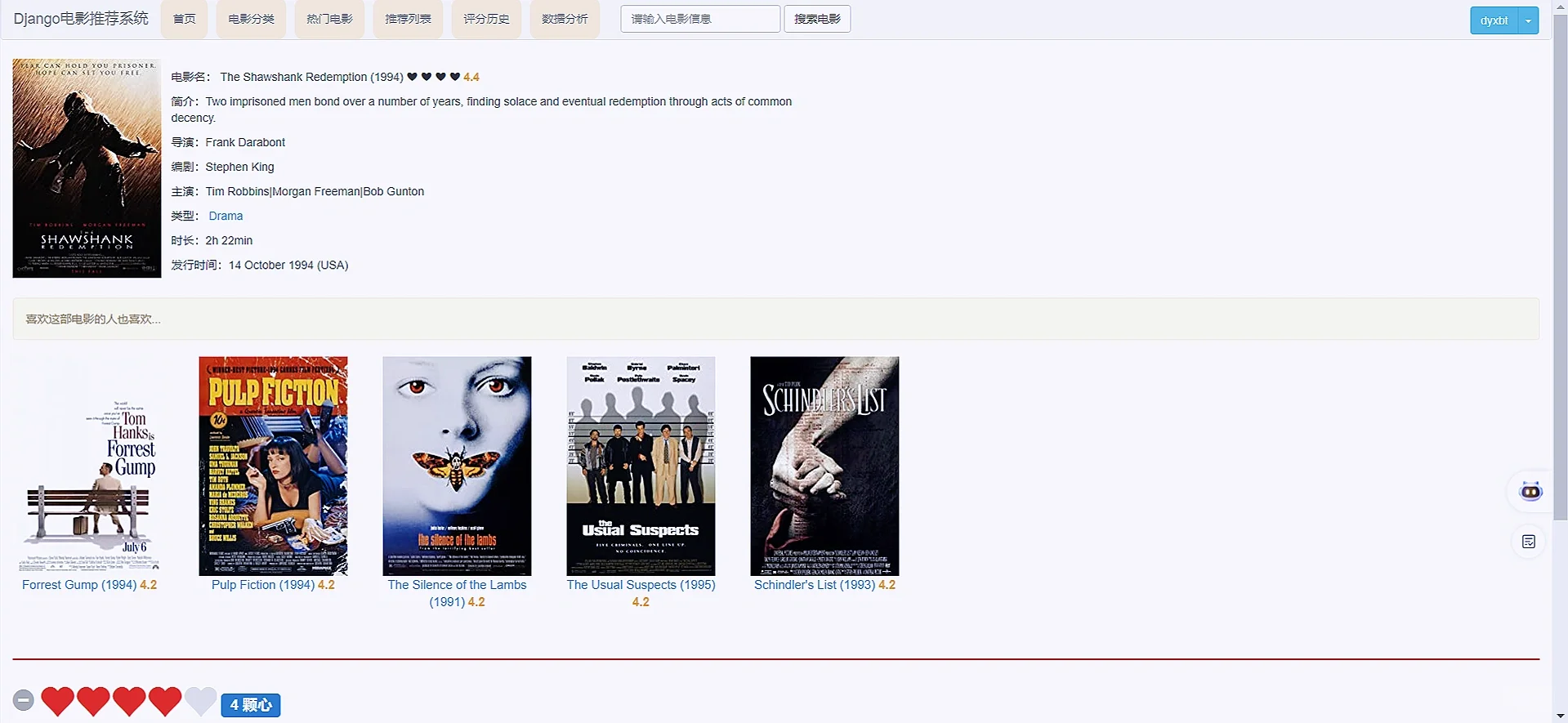
- 显示相似电影推荐
- 处理用户评分和评论提交
- 检查用户登录状态
**核心方法**:
- `get_context_data()`: 添加上下文数据(评分、评论、相似电影等)
- `post()`: 处理评分表单提交
2.2.3.8 RatingHistoryView - 评分历史视图
**功能**:显示用户的历史评分记录
**特点**:
- 按评分降序排列
- 从session获取当前用户ID
2.2.3.9 RecommendMovieView - 推荐电影视图
**功能**:基于用户的协同过滤推荐算法
**算法逻辑**:
1. 找到与当前用户最相似的K个用户(默认K=20)
2. 统计这些相似用户评分高但当前用户未评分的电影
3. 按总评分排序推荐N部电影(默认N=10)
**实现细节**:
- `get_user_sim()`: 计算用户相似度(基于共同评分电影数量)
- `get_recommend_movie()`: 获取推荐电影列表
- 记录算法执行时间
2.2.4. 辅助函数
2.2.4.1 UserLogout - 用户登出
**功能**:销毁session,登出用户
2.2.4.2 delete_recode - 删除评分记录
**功能**:删除用户对某部电影的评分记录
2.2.4.3 data_realize - 数据可视化
**功能**:统计各类型电影数量,用于数据可视化展示
2.2.5. 技术特点
1. **基于类的视图**:大量使用Django的通用视图(ListView, DetailView)
2. **分页实现**:自定义分页逻辑,支持左右页码导航
3. **用户认证**:使用session管理用户状态
4. **推荐算法**:实现基于用户的协同过滤算法
5. **表单验证**:使用Django表单验证用户输入
6. **消息框架**:使用messages传递操作反馈
2.2.6. 总结
这份views.py实现了电影推荐系统的核心功能,包括用户管理、电影展示、评分评论和推荐算法。代码结构清晰,使用了Django的多种高级特性,特别是基于类的视图和ORM查询。推荐算法部分虽然简单但完整实现了基于用户的协同过滤逻辑,可以作为学习Django和推荐系统的良好示例。
2.3 Url路由设计
from django.urls import path
from . import views
app_name = 'movie'
# 子路由
urlpatterns = [
# 默认首页
path('', views.IndexView.as_view(), name='index'),
# 热门电影
path('hot', views.PopularMovieView.as_view(), name='hot'),
# 登录
path('login', views.LoginView.as_view(), name='login'),
# 退出
path('logout', views.UserLogout, name='logout'),
# 注册
path('register', views.RegisterView.as_view(), name='register'),
# 分类查看
path('tag', views.TagView.as_view(), name='tag'),
# 搜索功能
path('search', views.SearchView.as_view(), name='search'),
# 电影详情页面
path('detail/<int:pk>', views.MovieDetailView.as_view(), name='detail'),
# 评分历史页面
path('history/<int:pk>', views.RatingHistoryView.as_view(), name='history'),
# 删除记录
path('del_rec/<int:pk>', views.delete_recode, name='delete_record'),
# 推荐页面
path('recommend', views.RecommendMovieView.as_view(), name='recommend'),
# 数据可视化
path('data_realize',views.data_realize, name='data_realize')
]
3 项目核心内容截图展示
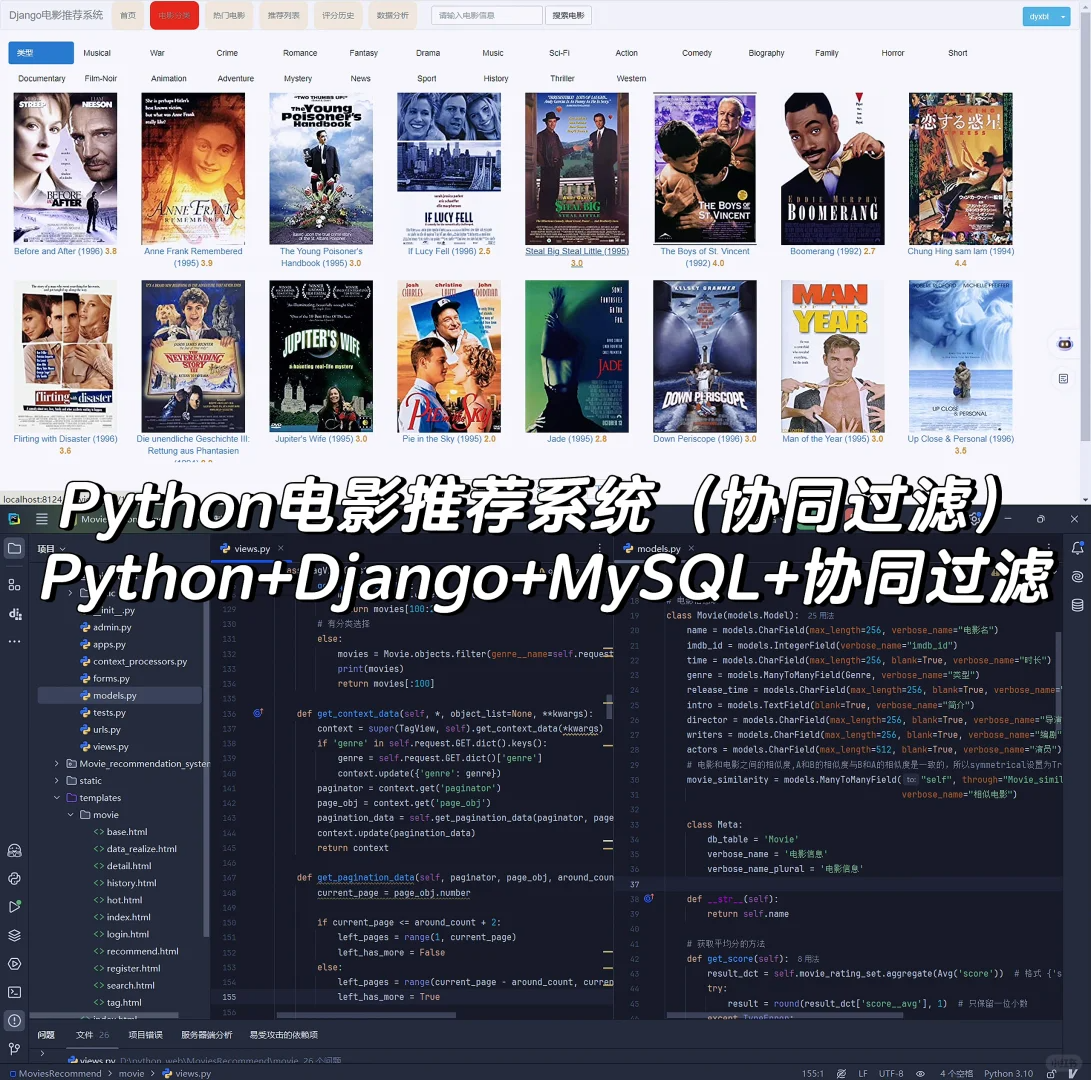
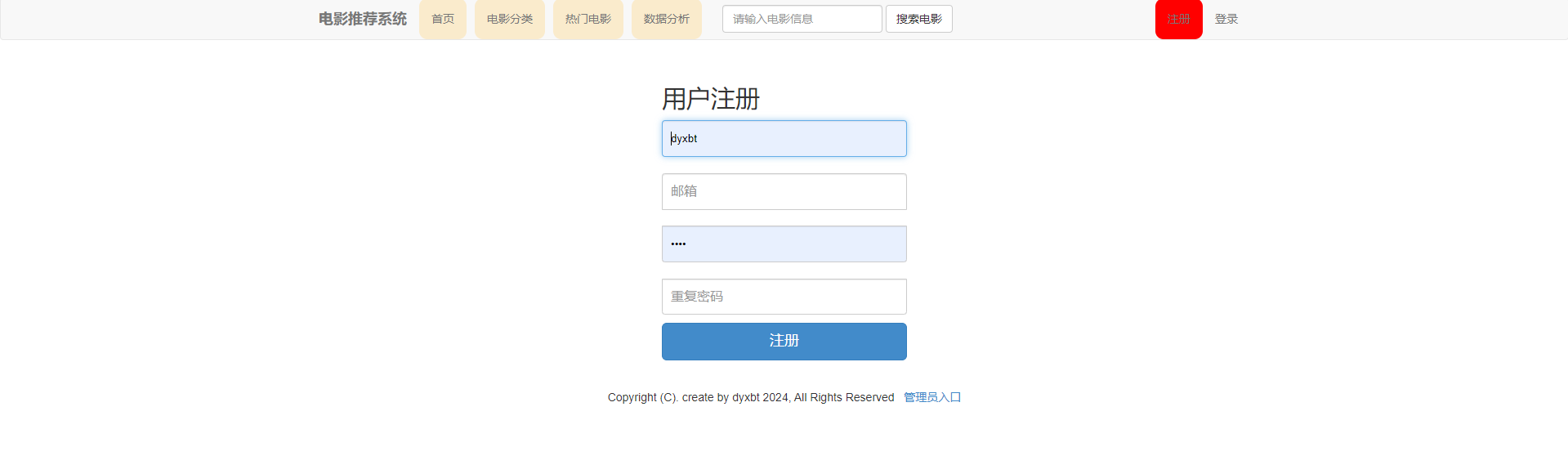
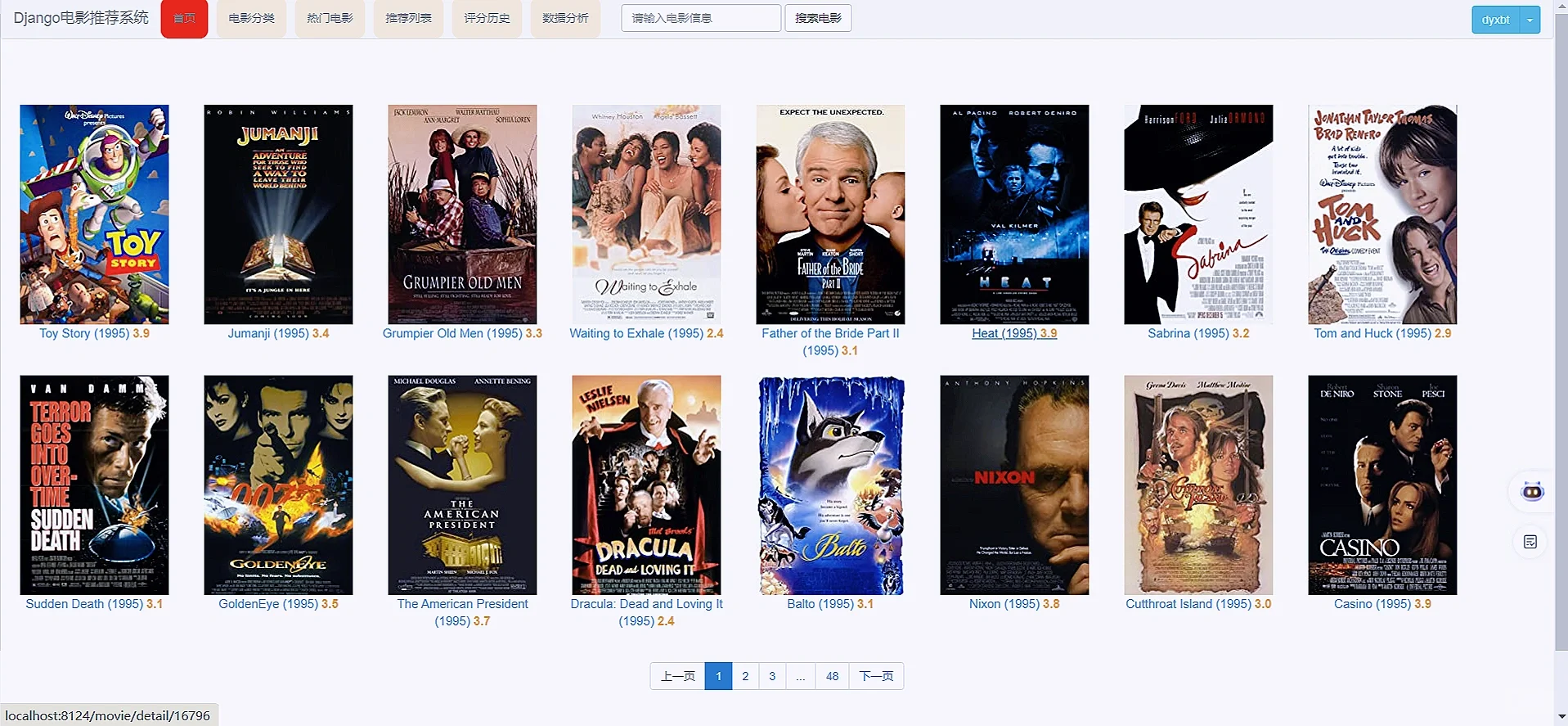
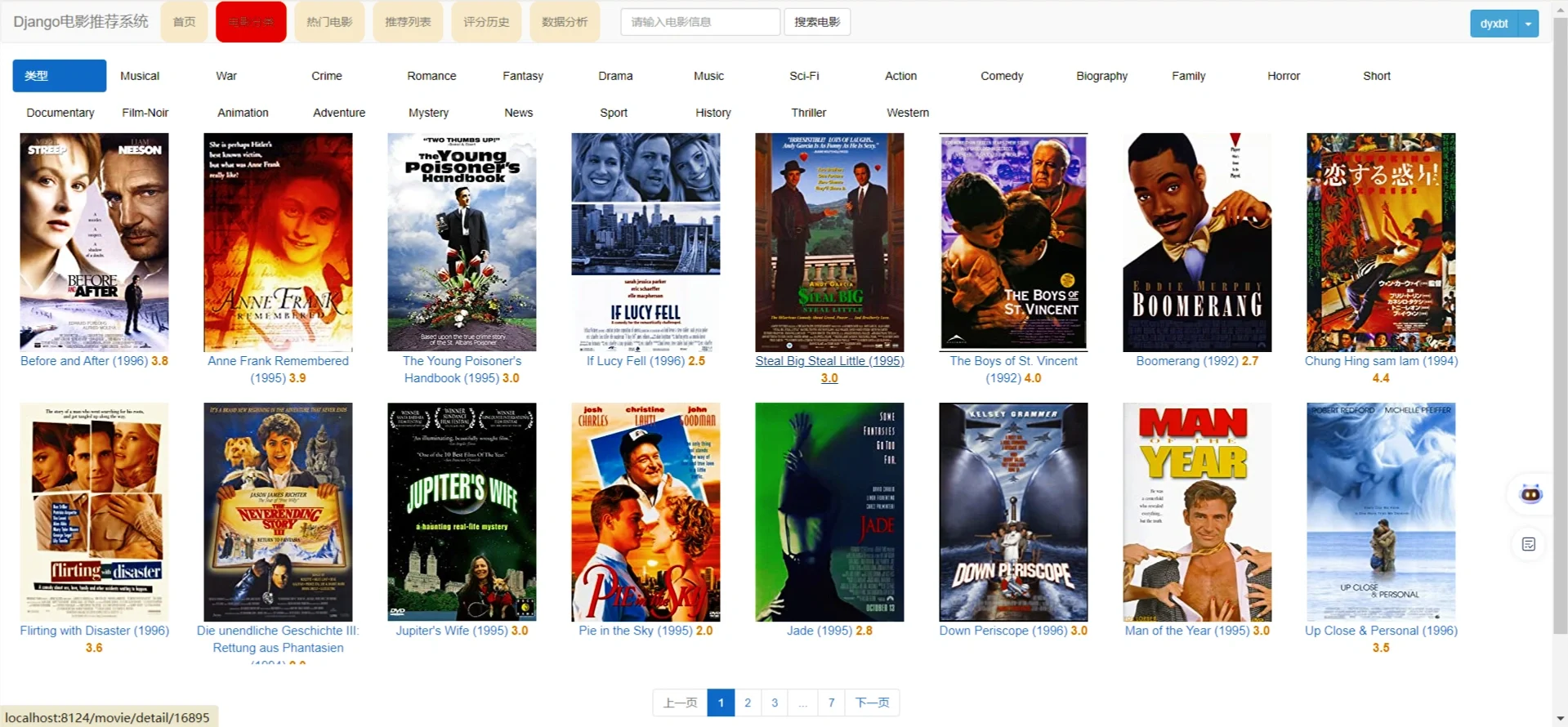
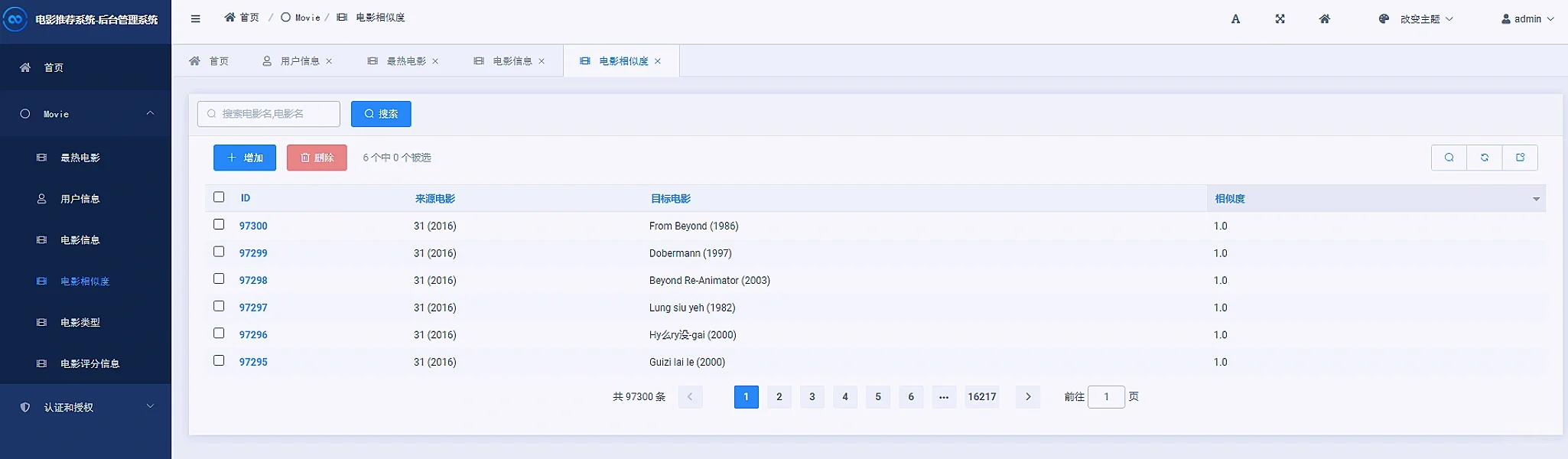
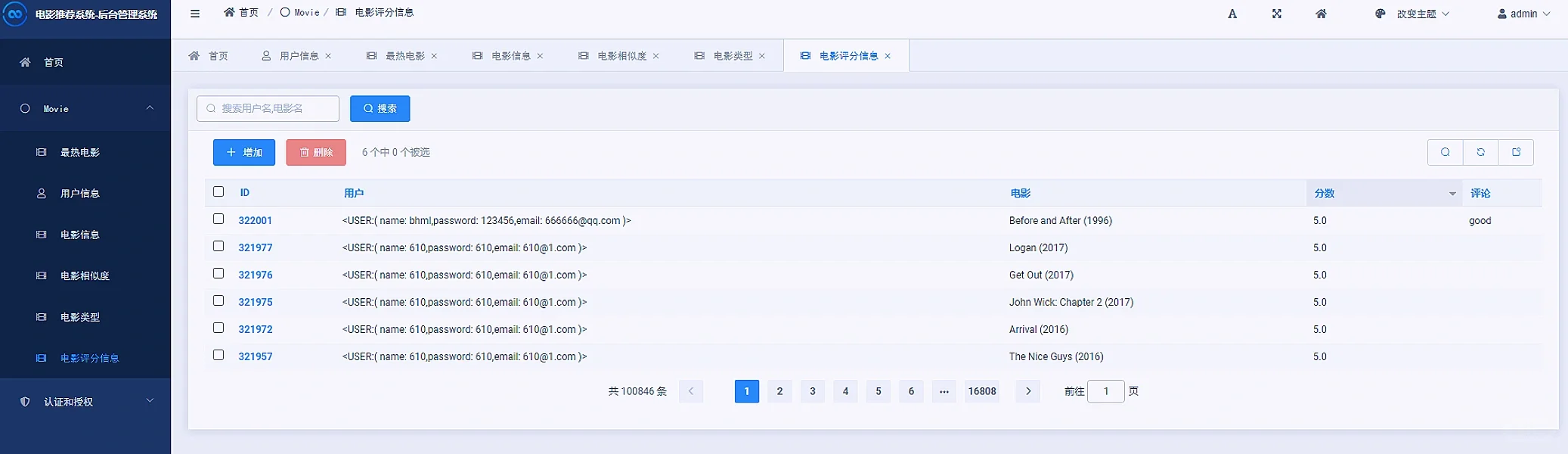 4 末尾
4 末尾
该项目比较简单,可用于相关学习实践,博客中还有许多类似的项目,也可以在个人简介或者下方名片里面添加本人的方式获取!


















 889
889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











