




 本文介绍了一个面向本科学生的计算机科学毕设项目,探讨了如何利用深度学习技术开发一个Web端多格式纠错系统。系统通过VBA和Seq2Seq模型进行工作,自定义数据集的创建与训练,旨在提高Web内容的准确性和用户体验。
本文介绍了一个面向本科学生的计算机科学毕设项目,探讨了如何利用深度学习技术开发一个Web端多格式纠错系统。系统通过VBA和Seq2Seq模型进行工作,自定义数据集的创建与训练,旨在提高Web内容的准确性和用户体验。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于深度学习的web端多格式纠错系统
项目背景
在当今数字化时代,Web端的内容呈现形式多样化,涵盖了各种文本、图像和视频等多种格式。然而,这些内容中常常存在错误和缺陷,给用户带来不便和困惑。基于深度学习的Web端多格式纠错系统的研究和开发,可以有效地检测和修复Web端内容中的错误,提高用户体验和信息可靠性。该课题的意义在于探索深度学习技术在Web端多格式纠错领域的应用,为Web开发和内容管理提供创新的解决方案,促进Web端的质量和可靠性的提升。
设计思路
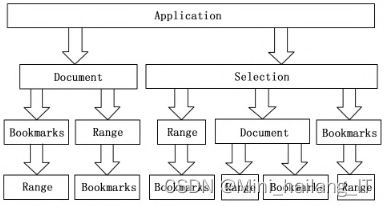
格式校对功能是基于VBA技术对Word文档进行解析和操作的强大工具。通过VBA技术,我们可以编程访问和操纵Word对象,获取文档的文本信息和格式信息,并进一步调整文档的页面布局、文本段落、字体等样式。Word对象结构层次分明,其中Application对象作为Word应用的核心,包含了Document(文件类)、Selection(文字内容类)、Bookmark(书签类)和Range(区域类)等关键对象。尽管这些对象之间存在重叠,但VBA提供了灵活多样的访问方式。除了这些顶层类型,还有更多专门用于设置文本字体、段落等格式的类。通过VBA技术,我们可以读取Word对象的格式信息,分析并调整文档的读写操作以及格式细节,从而实现对Word文档的精确控制和高效编辑。
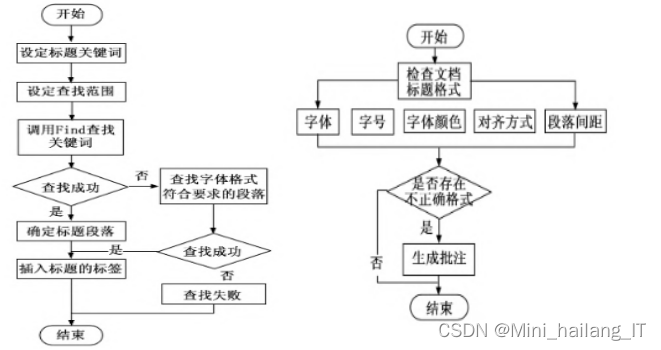
在识别出文档中的文本要素并为其插入书签后,格式校对流程进入关键阶段:对文本要素进行详细的格式检查。以文档标题为例,检查流程涵盖了字体、字号、段落间距和对齐方式等多个方面。一旦发现文本要素格式不符合预设标准,系统会以批注的形式直接在文档中指出,为用户提供明确的修改指引。为了提高格式校对的效率和准确性,系统利用Word的样式设置功能,将文本要素的样式保存为内置的格式模板文档(如style.dotm)。
在校对过程中,系统会将这些样式导入当前文档,并根据需要自动调整文本要素的格式和段落设置。对于文档结构的调整,系统主要关注必要文本要素的书签,并根据文档类型进行相应的增加或删减操作。同时,系统还会检查各文本要素之间的空行要求,并进行相应的删除或增添操作,以确保文档的整体布局合理。在页码格式校对方面,由于文档页码格式复杂多样,可能存在奇偶页码格式不一致或首页码不同的情况,系统会首先删除原文档的页码,然后根据文档要求设置奇偶页或首页的页码格式,并分别插入不同区域的页码进行格式设置。通过这种方式,即使在文档新增或删减页面时,页码格式也能始终保持符合规范要求,确保文档的完整性和专业性。
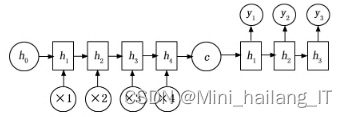
向Seq2Seq模型输入一个文本序列时,模型的Decoder会利用其自身的RNN模型对该序列进行编码,生成一个长度固定的向量,这个向量蕴含了文本的语义信息。编码器(Encoder)输出的隐状态可以直接作为这个语义向量,或者经过某种变换处理后再作为语义向量。随后,这个语义向量被送入Decoder。Decoder会根据这个语义向量进行计算,并生成一个长度不固定的输出文本序列。在常规的Seq2Seq模型结构中,语义向量仅作为Decoder的初始输入数据,并不参与Decoder内部的后续计算过程。这种结构使得模型能够从一个文本序列转换到另一个文本序列,适用于文本生成、机器翻译和文本纠错等任务。
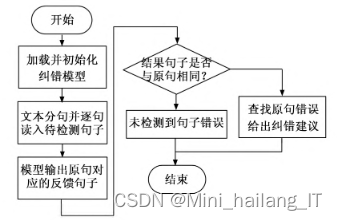
为实现文本内容纠错功能,系统采用深度学习模型进行训练,特别是针对中文文本纠错。通过总结文档写作时的规范用语与固定搭配,创建了辅助词库以提升纠错的准确性。在纠错流程中,系统首先对文本内容进行预处理,提取并分段存储文档正文。接着,将预处理后的内容输入到预先训练好的算法模型中,该模型采用Seq2Seq结构,能够有效拟合错误语句到正确语句的转化过程。模型对正文内容进行检测,若检测结果与原文不一致,则可能存在疑似错误,模型会输出可能的字词、语法和标点错误。系统随后查找并标注这些可能的错误,以批注形式展示在文档中。最后,用户可一键纠错,系统将根据批注建议直接替换错误文本。这种基于Seq2Seq模型的纠错方法相比传统规则和统计模型,能够更好地适应复杂多变的文本纠错需求。
数据集
由于网络上缺乏现有的合适的Web端多格式纠错数据集,为了进行基于深度学习的系统研究,我决定自己制作数据集。我收集了大量的Web端内容样本,包括文本、图像和视频等多种格式,并手动引入不同类型的错误和缺陷,如拼写错误、图像模糊、视频失真等。通过自制数据集,我能够获得真实且多样化的Web端内容,并为系统的训练和评估提供准确可靠的数据。
为了进一步提升基于深度学习的Web端多格式纠错系统的性能和鲁棒性,我计划对数据集进行扩充和增强。首先,我将继续收集更多的Web端内容样本,涵盖更广泛的领域和主题,以增加数据集的多样性和覆盖范围。其次,我将使用数据增强技术对原始数据进行处理,生成更多样化、更真实的错误和缺陷样本,以增加模型的泛化能力。例如,通过添加不同类型的噪声、模糊或失真效果,模拟实际中可能出现的错误情况。
模型训练
实验采用Python编程语言,结合VBA技术和Seq2Seq深度学习模型,在特定硬件和软件环境下(Windows 10 64位操作系统、Intel Core i5-7200U处理器、8G内存),开发了一套文本自动纠错系统。该系统界面简洁明了,主要包括模板生成、格式校对和内容纠错三大核心功能。办公人员可以通过选择相应类型的文档模板快速生成规范文档,进而在模板基础上进行内容编辑。编辑完成后,利用系统的格式校对和内容纠错功能,对文本进行细致全面的格式和内容检查,从而确保最终文档的规范性和正确性。
相关代码示例:
# 参数设置
vocab_size = 10000 # 词汇表大小
embedding_dim = 256 # 词嵌入维度
hidden_units = 512 # LSTM隐藏单元数
# 编码器输入
encoder_inputs = Input(shape=(None,))
encoder_emb = Embedding(vocab_size, embedding_dim)(encoder_inputs)
encoder_outputs, state_h = LSTM(hidden_units, return_state=True)(encoder_emb)
encoder_states = [state_h]
# 解码器输入
decoder_inputs = Input(shape=(None,))
decoder_emb = Embedding(vocab_size, embedding_dim)(decoder_inputs)
decoder_lstm = LSTM(hidden_units, return_sequences=True, return_state=True)
decoder_outputs, _, _ = decoder_lstm(decoder_emb, initial_state=encoder_states)
decoder_dense = Dense(vocab_size, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)

















 577
577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









