




 本文介绍了如何利用情感词典和网络新词处理在电商产品评论情感分析中的挑战,包括数据收集、情感词典构建、文本预处理和模型构建过程,以及实时情感分析的应用和优化策略。
本文介绍了如何利用情感词典和网络新词处理在电商产品评论情感分析中的挑战,包括数据收集、情感词典构建、文本预处理和模型构建过程,以及实时情感分析的应用和优化策略。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长深度学习毕设专题,本次分享的课题是
🎯基于情感词典的电商产品评论文本情感分析
项目背景
随着电商行业的迅猛发展,越来越多的用户在购买产品后会在电商平台上留下评论。这些评论包含了用户对产品的评价、意见和体验,其中包含了丰富的情感信息。因此,对电商产品评论文本进行情感分析成为了重要的研究方向和实际需求。
设计思路
网络新词在在线评论文本中的使用非常普遍。它们在评论文本的情感倾向性表达中起着重要作用。然而,目前已有的情感词典对网络新词的包含还很不全面,经常造成识别或错识别,从而影响最终的分类效果。因此,需要构建网络新词词典来解决这个问题。构建网络新词词典的基础是新词的发现。目前大多数研究通过复杂的自动算法来进行新词的发现。这类方法的优点是在发现过程中完全依靠算法,不需要过多的人工干预,工作效率较高,对于属于未登录词的网络新词的发现效果较好。然而,网络新词并不只包含未登录词,有些旧词型随着在网络中的传播使用也会被赋予新意义,从而成为网络新词,这一特点给新词的自动识别算法带来了较大的阻碍。而通过人工筛查发现新词的方法虽然效率较低,但可以有效克服这一障碍,整体达到较高的准确性。
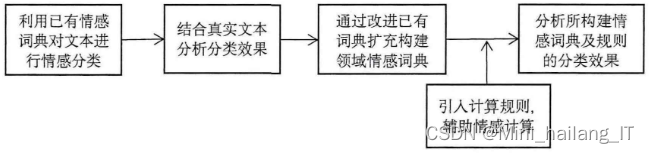
数据收集:
由于网络上没有现有的合适的数据集,我决定自己进行网络爬取,收集电商产品评论文本并制作一个全新的数据集。这个数据集包含了各种电商平台上的产品评论,涵盖了不同品类和领域的产品。通过网络爬取,我能够获取大量真实用户对产品的评价和情感表达,这将为我的研究提供更准确、可靠的数据。我相信这个自制的数据集将为电商产品评论文本情感分析系统的研究提供有力的支持,并为该领域的发展做出积极贡献。
# 网页爬取函数
def scrape_reviews(url):
reviews = []
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 根据网页结构和标签选择器定位评论内容
review_tags = soup.select('.review-text')
for tag in review_tags:
review = tag.get_text(strip=True)
reviews.append(review)
return reviews情感词典构建:
可以通过使用已有的情感词典和自行构建的方法来构建一个有效的情感词典。自制情感词典可以根据特定领域的需求进行定制,并提供更准确、可靠的情感分析结果。无论是使用已有情感词典还是自行构建情感词典,都需要进行验证和优化,以确保情感词汇的准确性和适用性。随着时间的推移,情感词典应该进行更新和维护,以适应不断变化的语言使用和领域需求。构建一个完善的情感词典将为情感分析系统提供有力支持,为各种应用领域提供更准确、全面的情感分析能力。
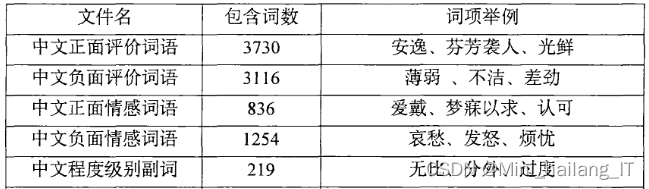
# 加载情感词典
def load_sentiment_dictionary(file_path):
sentiment_dict = {}
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
word, sentiment = line.strip().split('\t')
sentiment_dict[word] = int(sentiment)
return sentiment_dict文本预处理:
通过分词、去除停用词、词性标注等预处理操作,可以准备干净、规范的文本数据,为后续的情感分析建模提供更好的输入。此外,根据具体任务和需求,还可以考虑其他预处理操作,如处理词形变化、处理拼写错误等。通过合理的文本预处理,可以提高情感分析模型的性能,从而更准确地理解和分析产品评论文本中的情感倾向。
def preprocess_text(text):
# 分词
tokens = word_tokenize(text.lower())
# 去除停用词
stop_words = set(stopwords.words('english'))
tokens = [token for token in tokens if token not in stop_words]
# 词形还原
lemmatizer = WordNetLemmatizer()
tokens = [lemmatizer.lemmatize(token) for token in tokens]
return tokens情感计算:
在进行情感计算之前,需要选择一个合适的情感词典作为情感极性的参考。可以使用通用的情感词典,如HowNet情感词典、SentiWordNet等。也可以根据特定领域的需求,选择相应的领域情感词典或自行构建情感词典。

对于每个评论文本,将其中出现在情感词典中的词汇进行情感极性的累加。常见的情感极性值可以是积极、消极和中性,也可以使用连续的情感得分表示。对于积极词汇,可以将其情感得分累加为正值;对于消极词汇,可以将其情感得分累加为负值;对于中性词汇,可以忽略其情感得分或分配一个较小的权重。
通过对情感词汇进行情感极性的累加,可以得到一个总体情感得分。这个得分可以表示评论文本整体的情感倾向,如正面、负面或中性。具体的得分计算方法可以根据情感词典的设计和任务需求而定。
def calculate_sentiment_score(tokens, sentiment_dict):
score = 0
for token in tokens:
if token in sentiment_dict:
score += sentiment_dict[token]
return score阈值设置:
通常情况下,可以根据阈值的设定将得分高于阈值的评论文本判定为正面情感,得分低于阈值的判定为负面情感,得分在阈值范围内的判定为中性情感。阈值设置是情感计算中的重要步骤,用于根据情感得分将评论文本划分为不同的情感类别。在设置阈值时,需要结合实际需求、数据分析和评估指标,选择合适的阈值范围。通过合理的阈值设置,可以将连续的情感得分转化为离散的情感类别,为情感分析提供更直观和可解释的结果。
情感分类:
情感分类是根据阈值判定的结果,对评论文本进行情感分类的过程,将其归类为正面、负面或中性。正面情感表示积极倾向,负面情感表示消极倾向,中性情感表示中立态度。情感分类结果可用于多个领域的应用,为了解用户情感、产品评价和舆情分析提供有价值的信息。
def sentiment_classification(text, sentiment_dict):
tokens = preprocess_text(text)
score = calculate_sentiment_score(tokens, sentiment_dict)
if score > 0:
return "Positive"
elif score < 0:
return "Negative"
else:
return "Neutral"模型评估与优化:
情感分类的过程涉及使用标注好的训练数据对系统进行训练,然后使用测试数据对系统进行评估,并根据评估结果对系统进行优化。通过标注数据训练模型,评估模型性能,然后根据评估结果进行优化,可以提高情感分类系统的准确性和鲁棒性。这个过程是迭代的,需要不断改进和调优,以适应实际应用场景的需求。
实时情感分析:
实时情感分析是将情感分类系统应用于实时的电商产品评论数据中,通过数据预处理和情感分类模型,对新评论文本进行情感分析,并实时输出相应的情感分类结果。这个过程需要具备高效性能、实时结果输出,并进行定期的模型更新和优化,以适应不断变化的评论数据和情感表达方式。实时情感分析系统的应用可以帮助电商平台实时了解用户的情感倾向,从而进行相应的决策制定和产品优化。
def main():
# 加载情感词典
sentiment_dict = load_sentiment_dictionary('sentiment_dictionary.txt')
# 示例评论文本
text = "This product is amazing! It exceeded my expectations."
# 进行情感分类
sentiment = sentiment_classification(text, sentiment_dict)
# 输出结果
print("Sentiment: " + sentiment)
if __name__ == '__main__':
main()
















 1240
1240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









