 基于深度学习的自然场景英文识别系统设计与训练,
基于深度学习的自然场景英文识别系统设计与训练,





 本文介绍了一种基于深度学习的自然场景英文识别系统,通过卷积神经网络进行特征提取和多任务分类,包括不区分大小写的CNN分类、多特征映射的分类器以及文本检测技术。文章详细描述了数据集的创建、模型训练策略,如数据增强、迁移学习和正则化等,旨在提高系统的准确性和鲁棒性。
本文介绍了一种基于深度学习的自然场景英文识别系统,通过卷积神经网络进行特征提取和多任务分类,包括不区分大小写的CNN分类、多特征映射的分类器以及文本检测技术。文章详细描述了数据集的创建、模型训练策略,如数据增强、迁移学习和正则化等,旨在提高系统的准确性和鲁棒性。
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于深度学习的自然场景中英文识别系统
项目背景
在现代社会中,自然场景中的文字广泛存在于各种场合,如路牌、广告、商标、文本书籍等。然而,对于计算机系统来说,自然场景中的文字识别依然是一个具有挑战性的任务。传统的光学字符识别(OCR)系统在自然场景中的表现受到光照、遮挡、扭曲等因素的限制,难以获得准确的结果。通过训练大规模的数据集,深度学习模型能够学习到文字的特征和上下文信息,从而提高识别的准确性和鲁棒性。
设计思路
2.1 卷积神经网络
利用卷积神经网络进行特征学习,通过两个阶段的训练生成了四个不同特征映射的CNN分类器,用于不同的英文字母分类任务。这种方法的创新点在于将特征学习和多任务分类相结合,提高了对自然场景中英文字母的准确识别能力。
第一阶段,训练一个不区分大小写的CNN英文字母分类器。该分类器通过输入训练样本中的英文字母图像,并经过一系列卷积、池化和全连接层的操作,学习提取图像中的共享特征,最终输出英文字母的分类结果。这个阶段的目标是让CNN学习到不同字母之间的共同特征,而不考虑字母的大小写区分。
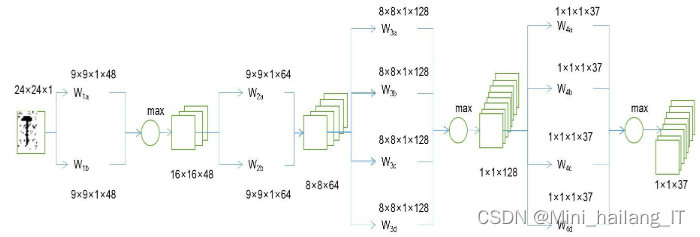
第二阶段,生成了不同特征映射的CNN英文字母分类器。通过对第一阶段训练得到的CNN进行进一步的训练和调整,生成了四个不同的CNN分类器。这些分类器分别用于英文字母/背景分类、不区分大小写的英文字母分类、区分大小写的英文字母分类以及二元英文字母分类。每个分类器都具有独立的特征映射,能够在输入图像中提取出与其对应的特定特征。

2.2 文本检测
通过卷积神经网络(CNN)进行特征学习和分类,分为两个阶段。在第一阶段,训练一个不区分大小写的CNN英文字母分类器,学习共享特征。在第二阶段,生成了四个不同特征映射的CNN分类器,用于英文字母/背景分类、不区分大小写的英文字母分类、区分大小写的英文字母分类和二元英文字母分类。检测阶段通过滑动窗口和特征映射计算,通过阈值化和游程平滑算法识别文本行,再将文本行拆分为英文字母,并生成带有英文字母边界框的图片。这个方法的创新点在于结合多个步骤实现准确的文本行和英文字母检测,为后续的文本识别任务提供了重要的预处理步骤。

数据集
通过自制数据集,旨在为基于深度学习的自然场景中英文识别系统提供支持。数据集的创建包括网络爬取和相机拍摄两个途径,以获取各种自然场景的照片。通过网络爬取,收集了多样性和丰富性的图片,而相机拍摄则捕捉了真实场景中的英文文字。这个自制数据集的特点是包含了不同字体、大小、颜色和背景的文字,并反映了真实世界中的变化和挑战。这将为该领域的研究和应用提供准确、多样化和真实的数据,为深度学习模型的训练和评估提供有力支持,促进自然场景中英文识别的发展和突破。

数据标注是将自然场景中英文识别系统数据集中的图像与相应的英文文本标签关联起来的过程。对于网络爬取的图片,可以使用自动化的文本检测算法提取潜在的文本区域,然后由标注人员进行校对和修正。对于相机拍摄的图片,需要人工标注英文文本。在标注过程中,应确保准确性和一致性,并遵循标注规范和指南。数据标注是耗时且需要人力资源的任务,可以考虑使用众包平台或外包给专业的数据标注服务提供商来加速和优化标注过程。这样的数据标注过程将为深度学习模型的训练和评估提供可靠的基础。

模型训练
4.1 实验环境
该实验的环境是为了支持基于深度学习的自然场景中英文识别系统的研究和评估而设立的。实验环境包括了配置良好的计算机或服务器,配备高性能的GPU加速器,以满足深度学习模型的计算需求。在软件方面,使用了深度学习框架如TensorFlow、PyTorch或Keras来构建和训练模型,辅以图像处理库和数据处理工具进行数据预处理和特征提取。关键的组成部分是数据集,其中包含了各种自然场景的图像和相应的英文文本,并经过准确的标注。这个实验环境为研究人员提供了必要的工具和资源,以开展深度学习模型的训练、评估和改进,并推动自然场景中英文识别系统的发展和应用。
4.2 模型训练
模型训练的目的是通过使用已标注的数据集来训练深度学习模型,使其能够准确地识别自然场景中的英文文本。模型训练的流程包括数据准备、模型选择和设计、模型训练、模型评估和调优以及模型测试和应用。为了提高模型训练的效果和鲁棒性,可以采取措施如数据增强、迁移学习、正则化、批标准化和模型集成。这些措施能够增加数据多样性、加速训练过程、减少过拟合、提高模型稳定性和泛化能力。综合运用这些措施,可以提升自然场景中英文识别系统的性能和应用效果。
为了提高模型训练的效果和鲁棒性,可以采取以下措施:
-
数据增强:对训练数据进行增强,如旋转、缩放、平移、翻转等操作,以扩充数据集并增加模型的泛化能力。
def augment_image(image):
# 旋转
angle = np.random.randint(-10, 10)
rows, cols = image.shape[:2]
M = cv2.getRotationMatrix2D((cols/2, rows/2), angle, 1)
rotated_image = cv2.warpAffine(image, M, (cols, rows))
# 缩放
scale_factor = np.random.uniform(0.8, 1.2)
scaled_image = cv2.resize(rotated_image, None, fx=scale_factor, fy=scale_factor)
# 平移
dx = np.random.randint(-20, 20)
dy = np.random.randint(-20, 20)
rows, cols = scaled_image.shape[:2]
M = np.float32([[1, 0, dx], [0, 1, dy]])
translated_image = cv2.warpAffine(scaled_image, M, (cols, rows))
# 翻转
flip = np.random.choice([False, True])
flipped_image = cv2.flip(translated_image, 1) if flip else translated_image
return flipped_image-
迁移学习:使用预训练的模型作为初始权重,然后在自然场景中的英文识别任务上进行微调,以加速训练过程和提高性能。
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
# 冻结预训练模型的权重
for layer in base_model.layers:
layer.trainable = False
# 添加自定义的全连接层
x = base_model.output
x = tf.keras.layers.GlobalAveragePooling2D()(x)
x = Dense(256, activation='relu')(x)
predictions = Dense(num_classes, activation='softmax')(x)
# 构建模型
model = Model(inputs=base_model.input, outputs=predictions)
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 在新的数据集上进行微调训练
model.fit(train_dataset, epochs=10, validation_data=val_dataset)
# 解冻部分或全部层进行微调
for layer in model.layers[:10]:
layer.trainable = False
for layer in model.layers[10:]:
layer.trainable = True-
正则化:使用正则化技术,如L1或L2正则化、Dropout等,以减少模型的过拟合现象。
-
批标准化:在网络的每一层使用批标准化,以加速训练、提高模型的稳定性和泛化能力。
-
模型集成:使用多个模型的预测结果进行集成,如投票、平均或加权平均,以提高模型的准确性和鲁棒性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









