







 超级会员免费看
超级会员免费看
 本文介绍了Python机器学习中监督学习的经典分类模型,包括线性分类器(如LogisticRegression和SGDClassifier)、支持向量机、朴素贝叶斯、K近邻、决策树和集成学习。通过具体案例分析了每个模型的工作原理和性能,如LogisticRegression在处理肿瘤预测数据时表现优于SGDClassifier,而随机森林常用于工业界作为基准系统。
本文介绍了Python机器学习中监督学习的经典分类模型,包括线性分类器(如LogisticRegression和SGDClassifier)、支持向量机、朴素贝叶斯、K近邻、决策树和集成学习。通过具体案例分析了每个模型的工作原理和性能,如LogisticRegression在处理肿瘤预测数据时表现优于SGDClassifier,而随机森林常用于工业界作为基准系统。
Python机器学习及实践——基础篇:监督学习经典模型(分类学习)
机器学习中监督学习模型的任务重点在于,根据已有经验知识对未知样本的目标/标记进行预测。根据目标预测变量的类型不同,可以把监督学习任务大体分为分类学习和回归预测两类。
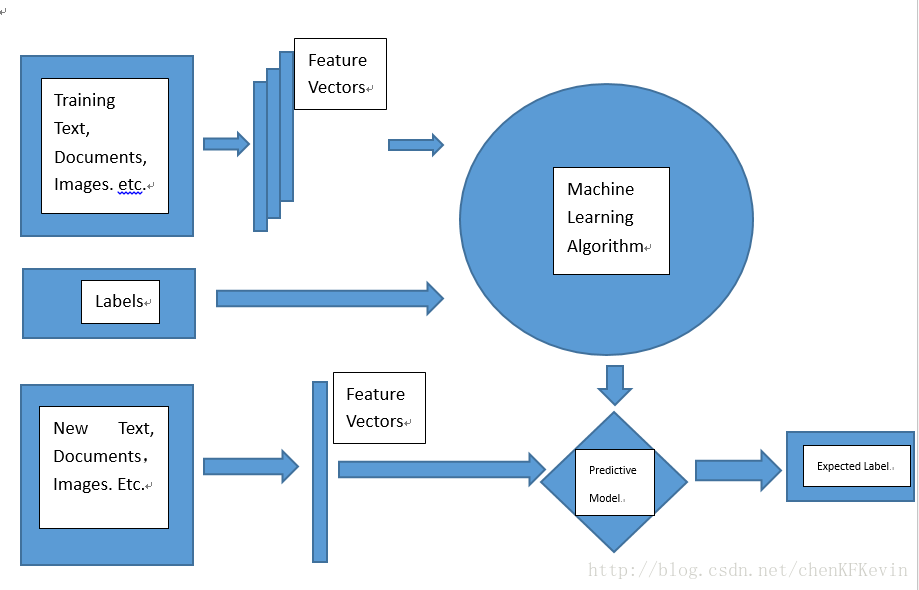
监督学习任务的基本架构和流程:首先准备训练数据,可以是文本、图像、音频等;然后抽取所需要的特征,形成特征向量(Feature Vectors);接着,把这些特征向量连同对应的标记/目标(Labels)一并送入学习算法(Machine Learning Algorithm)中,训练出一个预测模型(Predictive Model);然后采用同样的特征抽取方法作用于新测试数据,得到用于测试的特征向量;最后,使用预测模型对这些待测试的特征向量进行预测并得到结果(Expected Label)。
监督学习基本架构和流程
1.线性分类器
线性分类器(Linear Classifier)是一种假设特征与分类结果存在线性关系的模型。这个模型通过累加计算每个维度的特征与各自权重的乘积来帮助类别决策。
应用案例:良/恶性肿瘤预测:原始数据共有699条样本,每条样本有11列不同的数值:1列用于检索的id,9列与肿瘤相关的医学特征,以及一列表征肿瘤类型的数值。所有9列用于表示肿瘤医学特质的数值均被量化为1~10之间的数字,而肿瘤的类型也借由数字2和数字4分别指代良性与恶性。不过,这份数据也

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











