




 本文介绍了强化学习中寻找最优策略的核心概念——贝尔曼最优公式,通过一个网格示例展示了如何计算状态值和动作值,并解释了如何通过最大化动作值来改进策略。接着,详细阐述了贝尔曼最优公式的矩阵-向量形式,以及不动点理论(收缩映射定理)在解决该方程中的作用,提供了价值迭代算法的步骤。最后,讨论了奖励设计、系统模型和折扣率如何影响最优策略,并通过实例说明了策略的优化过程。
本文介绍了强化学习中寻找最优策略的核心概念——贝尔曼最优公式,通过一个网格示例展示了如何计算状态值和动作值,并解释了如何通过最大化动作值来改进策略。接着,详细阐述了贝尔曼最优公式的矩阵-向量形式,以及不动点理论(收缩映射定理)在解决该方程中的作用,提供了价值迭代算法的步骤。最后,讨论了奖励设计、系统模型和折扣率如何影响最优策略,并通过实例说明了策略的优化过程。
强化学习数学基础:贝尔曼最优公式
强化学习的目的是寻找最优策略。这里学习贝尔曼最优公式需要重点关注两个概念和一个工具:
- 两个概念:optimal state value和optimal policy
- 一个基本工具:the Bellman optimality equation (BOE)
一个示例
还是从一个网格示例开始,如下所示:
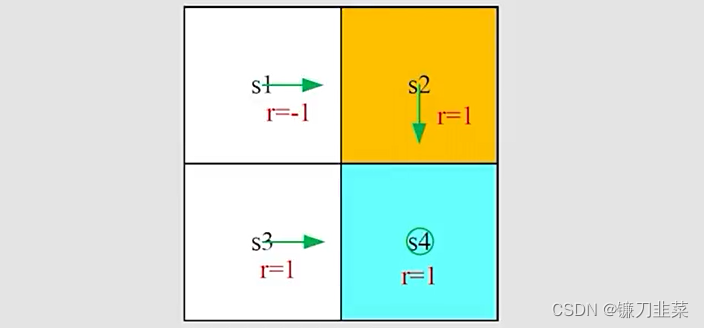
列出贝尔曼公式:
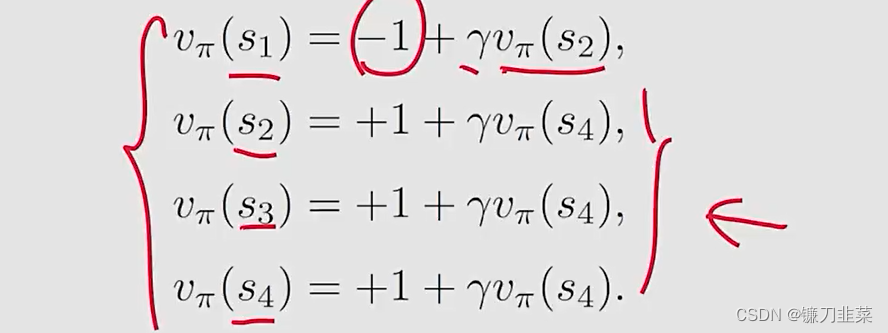
求解State value:令 γ = 0.9 \gamma=0.9 γ=0.9,然后,计算结果如下:
v π ( s 4 ) = v π ( s 3 ) = v π ( s 2 ) = 10 , v π ( s 1 ) = 8 v_\pi(s_4)=v_\pi(s_3)=v_\pi(s_2)=10, v_\pi(s_1)=8 vπ(s4)=vπ(s3)=vπ(s2)=10,vπ(s1)=8
有了state value,求解Action value,考虑 s 1 s_1 s1,有:
q π ( s 1 , a 1 ) = − 1 + γ v π ( s 1 ) = 6.2 q_\pi(s_1, a_1)=-1+\gamma v_\pi (s_1)=6.2 qπ(s1,a1)=−1+γvπ(s1)=6.2
q π ( s 1 , a 2 ) = − 1 + γ v π ( s 2 ) = 8 q_\pi(s_1, a_2)=-1+\gamma v_\pi(s_2)=8 qπ(s1,a2)=−1+γvπ(s2)=8
q π ( s 1 , a 3 ) = 0 + γ v π ( s 3 ) = 9 q_\pi(s_1, a_3)=0+\gamma v_\pi(s_3)=9 qπ(s1,a3)=0+γvπ(s3)=9
q π ( s 1 , a 4 ) = − 1 + γ v π ( s 1 ) = 6.2 q_\pi(s_1, a_4)=-1+\gamma v_\pi(s_1)=6.2 qπ(s1,a4)=−1+γvπ(s1)=6.2
q π ( s 1 , a 5 ) = 0 + γ v π ( s 1 ) = 7.2 q_\pi(s_1, a_5)=0+\gamma v_\pi(s_1)=7.2 qπ(s1,a5)=0+γvπ(s1)=7.2
那么问题来了,当前策略不太好,如何改善这个策略?这个就依赖Action values。当前的策略 π ( a ∣ s 1 ) \pi(a|s_1) π(a∣s1)可以写为:
π ( a ∣ s 1 ) = { 1 a = a 2 0 a ≠ a 2 \pi(a|s_1)=\begin{cases}1 & a=a_2 \\0 & a\ne a_2\end{cases} π(a∣s1)={
10a=a2a=a2
根据上面action value,可以发现 q π ( s 1 , a 3 ) = 9 q_\pi (s_1, a_3)=9 qπ(s1,a3)=9是最大值,所以如果选择a3作为新策略,那么一个新策略描述为:
π ( a ∣ s 1 ) = { 1 a = a ∗ 0 a ≠ a ∗ \pi(a|s_1)=\begin{cases}1 & a=a^* \\0 & a\ne a^*\end{cases} π(a∣s1)={
10a=a∗a=a∗
其中 a ∗ = a r g m a x a q π ( s 1 , a ) = a 3 a^*=argmax_a q_\pi (s_1, a)=a_3 a∗=argmaxaq
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2203
2203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











