




 本文探讨了ReLU深度网络为何能近似任意函数。ReLU网络通过分段线性方式分割数据空间,随着网络深度增加,线性区域数量呈指数级增长,从而实现复杂函数的近似。适当的网络深度和平滑激活函数结合使用可以避免过拟合。
本文探讨了ReLU深度网络为何能近似任意函数。ReLU网络通过分段线性方式分割数据空间,随着网络深度增加,线性区域数量呈指数级增长,从而实现复杂函数的近似。适当的网络深度和平滑激活函数结合使用可以避免过拟合。
有很多人问:为什么ReLU深度网络能逼近任意函数?
对此,其有深入见解,但是在此他是简单,并用最少的数学形式来解释这个问题。ReLU其实是分段线性的,所以有人会质疑,对于一个固定大小的神经网络,ReLU网络可能不具有更平滑+有界的激活函数(如tanh)的表达。
因为他们学习非平滑函数,ReLU网络应该被解释为以分段线性方式分离数据,而不是实际上是一个“真实”函数近似。 在机器学习中,人们经常试图从有限离散数据点(即100K图像)的数据集中学习,并且在这些情况下,只需学习这些数据点的分隔就足够了。考虑二维模数运算符,即:
vec2 p = vec2(x,y) // x,y are floats
vec2 mod(p,1) {
return vec2(p.x % 1, p.y % 1)
}
mod函数的输出是将所有2D空间折叠/散架到单位平方上的结果。 这是分段线性,但高度非线性(因为有无限数量的线性部分)。
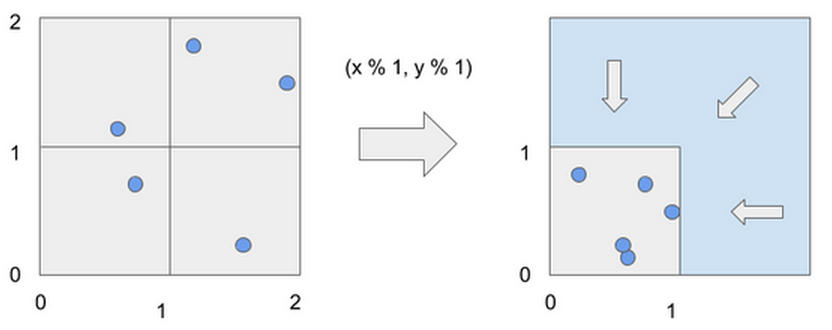
用ReLU激活的深层神经网络工作相似-它们将激活空间分割/折叠成一簇不同的线性区域,像一个真正复杂的折纸。
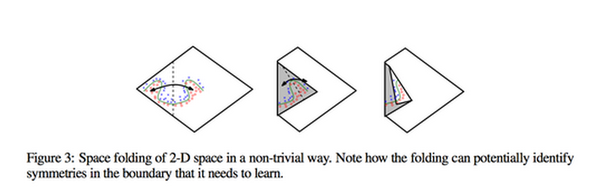
可以看“On the number of linear regions of Deep Neural Networks”这篇文章的第三幅图,就很清楚表现了。
在文章的图2中,它们展示了在网络中层的深度/层数的如何增加的,线性区域的数量呈指数增长。
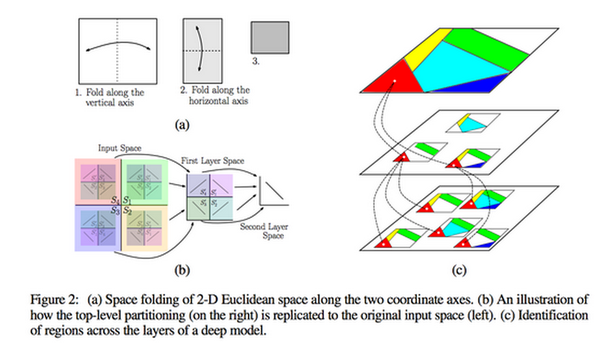
事实证明,有足够的层,你可以近似“平滑”任何函数到任意程度。 此外,如果你在最后一层添加一个平滑的激活函数,你会得到一个平滑的函数近似。
一般来说,我们不想要一个非常平滑的函数近似,它可以精确匹配每个数据点,并且过拟合数据集,而不是学习一个在测试集上可正常工作的可泛化表示。 通过学习分离器,我们得到更好的泛化性,因此ReLU网络在这种意义上更好地自正则化。
详情:A Comparison of the Computational Power of Sigmoid and Boolean Threshold Circuits

















 202
202

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









