




概要
NeurIPS 2025 于 2025 年 12 月 2–7 日在圣迭戈会展中心举办,并设置墨西哥城等地的平行活动;大会继续覆盖从机器学习方法论到跨学科应用的全谱系议题,同时延续数据集与基准等分轨传统与政策更新(如 LLM 使用指引)。NeurIPS 2025 主会投稿 21,575 篇,接收 5,290 篇,录用率约 24.5%;海报 4,525、Spotlight 688、Oral 77。从已上线的论文来看,今年的系统与基础设施类成果密集:面向大规模训练的并行与调度、拓扑感知通信;面向推理的 Serving/SLO 管理、推测解码与 KV-cache 体系;以及编译器/内核共设计与自动调优,形成“更低延迟、更高吞吐、更优能效、更强可运维”的清晰趋势。

San Diego Convention Center and Mexico City
在模型规模持续扩张、上下文长度与并发访问不断攀升的当下,NeurIPS 2025 的诸多亮点都直接指向“系统边界”的再定义:训练侧的调度/并行与拓扑感知通信(如 FlowMoE、StarTrail)回答了如何把 1000+ GPU 的算力变成“有效吞吐”;推理侧的 Serving/SLO、推测解码与 KV-cache 压缩/复用(如 HyGen、Yggdrasil)则回答了如何在相同资源下“生成更多、更快、更稳”。这些工作共同勾勒出两条分析主线:
-
AI infrastructure(训练/通信/资源编排)——以并行维度设计、通信对齐、系统级调度与能效约束为核心,面向端到端训练吞吐与成本最优化。
-
ML systems(推理/服务化/编译器与运行时)——以时延与尾延迟控制、推理时计算扩展、缓存与内存足迹治理、编译器/内核共设为核心,面向高并发、低成本的在线与离线服务。
接下来,把今年相关论文(已上线的论文)逐一展开泛读(一张图,一句话)。
论文列表
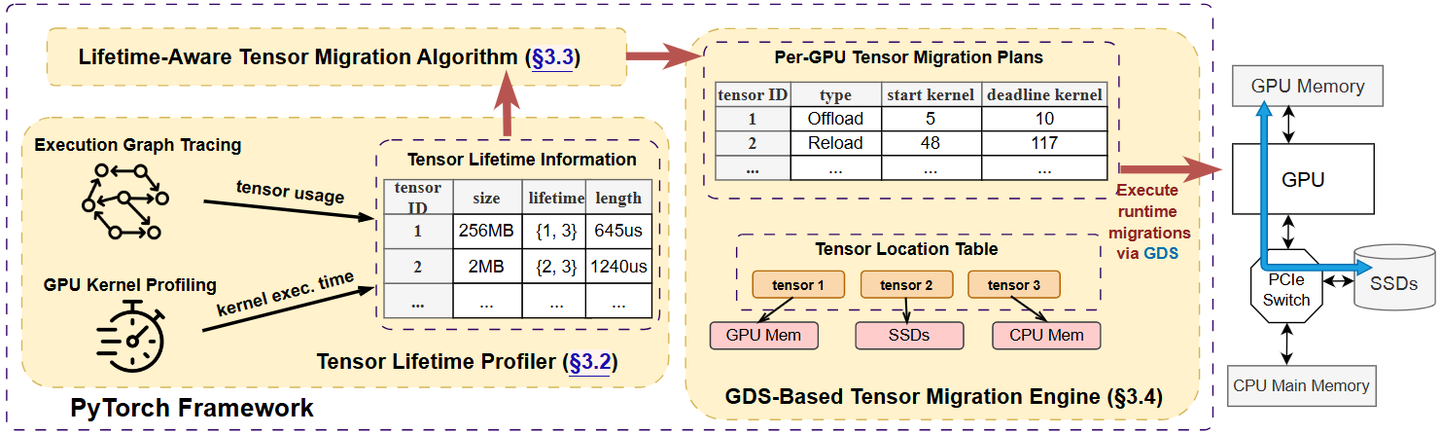
System overview of Teraio
这篇论文提出并实现了一个用于大模型训练的“按生命周期感知(lifetime-aware)张量换入/换出”框架 Teraio,核心目的是用廉价的PCIe SSD + GPUDirect Storage 扩展GPU显存、在尽量不牺牲吞吐的前提下降本增效。
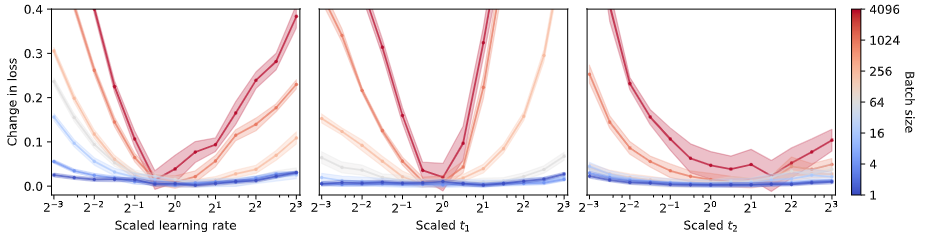
Small batch sizes are robust to hyperparameter misspecification
小批量(甚至 batch size = 1)训练大语言模型完全可行,而且往往更稳、更省显存,并不需要梯度累积或复杂优化器。作者系统给出一套在小批量下调参的原则,并用从 30M 到 1.3B 参数的实验验证。
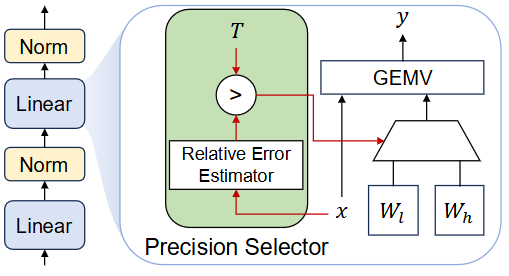
Overview of DP-LLM
这篇论文提出 DP-LLM:一种在推理时按层动态分配量化精度的机制,用来在终端/本地设备上根据实时的延迟/精度约束自适应运行 LLM。核心思想是:不同层对量化误差的敏感度会随解码迭代(逐 token)动态变化,因此不应把每一层的比特数固定,而应在每一步为每一层选择“高比特 or 低比特”。
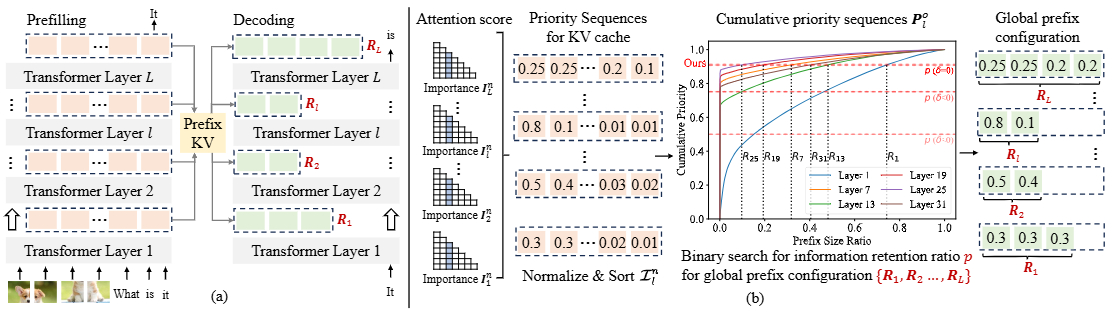
a) The
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









