



随着2023年OpenAI,ChatGPT的破圈,以预训练Pre-Training+微调SFT+人类反馈对齐RLHF为核心技术,依托Pre-Training阶段的Scaling law,类似的文本AIGC大模型进入了快速发展期,全社会的关注和应用用。
2024年o1~o3模型的推出,以合成数据、强化学习为核心技术,2025年春节前夕,Deekseek-R1推理模型,依托Post-Training阶段的Scaling Law,凭借着【中国开源】、【成本低】、【推理赶超类O模型】等,火遍国内外大模型社区、AI应用开发者,还进一步破圈成为社会级别现象。
这两类模型的存在的区别
文本生成LLM
基于大规模语料库的训练,获得广泛的基础知识和语言理解能力,先对于传统NLP模型,提升了语言生成的流畅性、增强文本理解的准确性以及多领域知识覆盖。依托Pre-Training阶段的Scaling law,拓展模型参数和徐连数据提升性能。
在深度推理、长程规划或解决复杂问题时,存在局限性,其思维路径不清晰,逻辑不严密导致依赖推理相关问题性能不高。
虽然可以通过Prompt提示词引导模型进行类似思维链推理,但是性能比较受限。
文本推理LLM模型
在文本推理模型的基础上,强化推理能力、长程规划能力、解决复杂问题的能力。
侧重于Post-training的Scaling Law的研究,发掘计算量对性能的进一步提升。不再仅仅依靠参数和数据的拓展,更注重推理过程的优化,使用【引导模型思考的数据】进行对齐训练,先让模型输出思考过程,再根据思考过程进行回答。以Deepseek R1的输出为例,第一阶段,根据问题进行思考输出对应的过程,以Think标签来标记,第二阶段以第一阶段的Think总结回复问题。
过程中引入隐式推理链implicit Chain of Thought,CoT,改变文本生成模型这种直接输出答案,
应用场景
应用生成LLM
在NLP的下游任务上都得到很好的应用和实践,包括文本生成、信息抽取、文本摘要等,进一步应用到对话智能体和AI客服等领域。
信息总结抽取:信息抽取、摘要生成总结等等这类任务,适合处理大量文本数据的输入,不需要复杂推理,快速抓取并输出。
文本生成:大模型LLM在预训练阶段使用了人类互联网上的文本资料数据,可以生成小作文、营销文案、故事、笑话等各类内容。这种类型生成的内容,具有一定的创意性,适合对信息准确性要求不是特别严格的场景,只需要少量prompt就可以输出堪比真人的内容。
文本分类和内容理解:通过对文本理解和上下文分析,对类型情感分析、主题分类等,可以快速地对大量文本数据分类到对那个的标签。比如对新闻内容进行主题分类,可以划归到对应的新闻板块。如需要更高的精度、应用在垂直领域中,可能需要对模型进行进一步微调和优化。
应用上,人机对话、问答提系统中有较大的应用空间,具有角色设定和工具调用的简单对话智能体和AI客服等,也由于LLM相对于传统NLP的在对话生成、知识库调用、插件调用等性能提升而进一步提升。
但是问题的复杂度有限,特别是在AI客服领域,虽然可以通过RAG知识库检索并生成内容,但是一旦涉及到复杂意图、复杂决策,仍然需要人类干预。
应用推理LLM
按照推理模型的优势,在以下应用场景中
依赖数据数学逻辑计算场景:虽然生成LLM可以处理一些基本的数学问题,但是对于复杂高难度的数学问题,就会比较差(比如大数计算等)。另在,在编程这类强依赖推理能力、思考计算过程,也会有显著提升。
深度推理的内容理解场景:对于多层次、多步骤推导的内容理解与生成。多层次,比如,对于一篇结构化比较好的长文,内容存在多个层次,可能会通过标题和对应的多个段落体现出来,对于高层次的问题,需要在提取跨层次和段落模块的内容,普通的RAG此时可能会存在一定的问题。比如电商AI客服,领域比较广泛,用户query可能比较泛化、跨多系统的业务流程,需要多步骤进行推理,找出用户意图和问题解决的关键任务。比如论文、报告等长文本生成、摘要等,表格、列表等结构化数据生成。
多智能体框架:对于复杂问题,需要多个领域智能体的协作,涉及到规划、拆解、协同、目标review等等。通过推理模型可以提升信息传递、决策,提升多智能体整体的稳定性和效率。
总结
| 推理LLM | 生成LLM | |
| 优势能力 | 强推理,思维链 | 强文本生成,发散 |
| 思考能力 | 慢思考,深度思考,长思维链 | 快思考,短思维链 |
| 响应时间 | Think+回复,其中Think可能多轮,甚至从头开始 | 快,实时性好 |
| 资源要求 | 多轮推理,相对成本高 | 相对成本低 |
| 应用场景 | 数学推导、代码逻辑、复杂问题拆解 | 文本生成、创意协作、多轮问答、开放回答 |
| 处理复杂任务 | 表现有限 | 复杂数学问题、多步推理等 |
其它参考:来自清华大学的《DeepSeek从入门到精通.pdf》
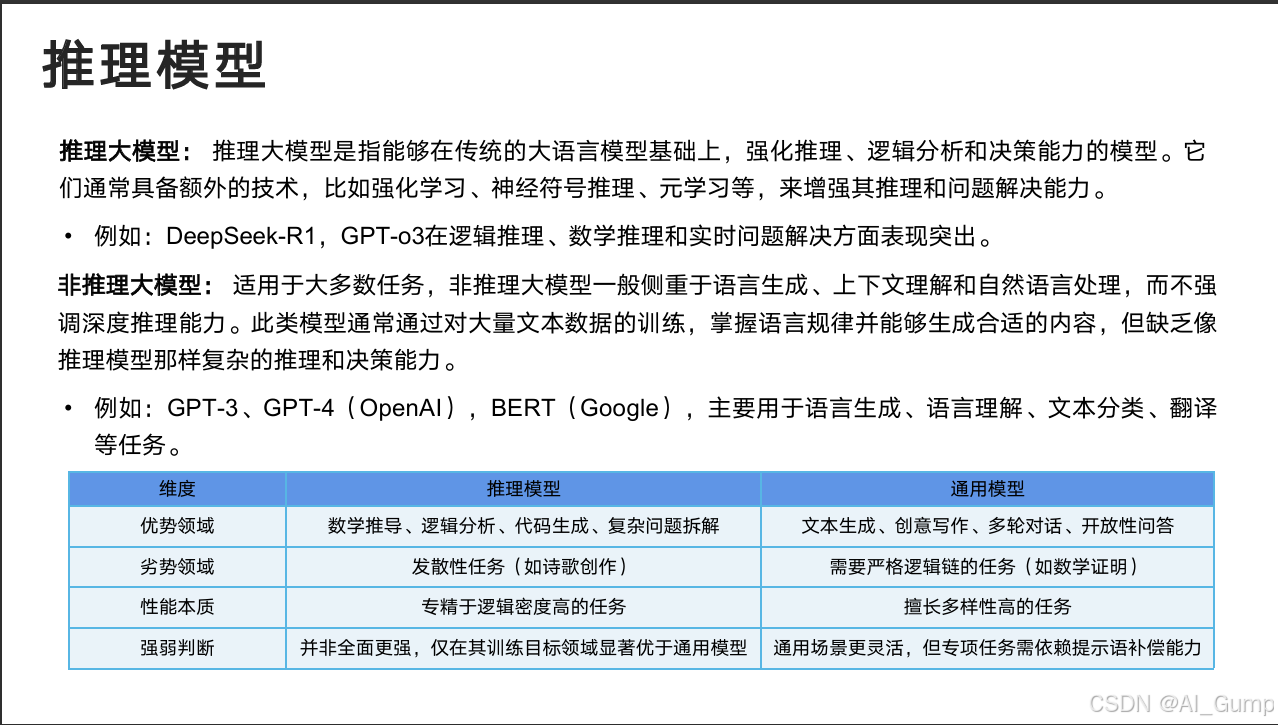
Prompt差异
先看提示词设计的基本差异,其中提到,不能因为什么火,就盲目选择,不同的模型作为一种技术方案,当前仍然存在明显的技术使用边界

推理模型和通用模型的提示语设计差异

由于推理模型已经具备一定的思维链推理能力,在Prompt中,对思考过程的描述会对推理模型带来影响。
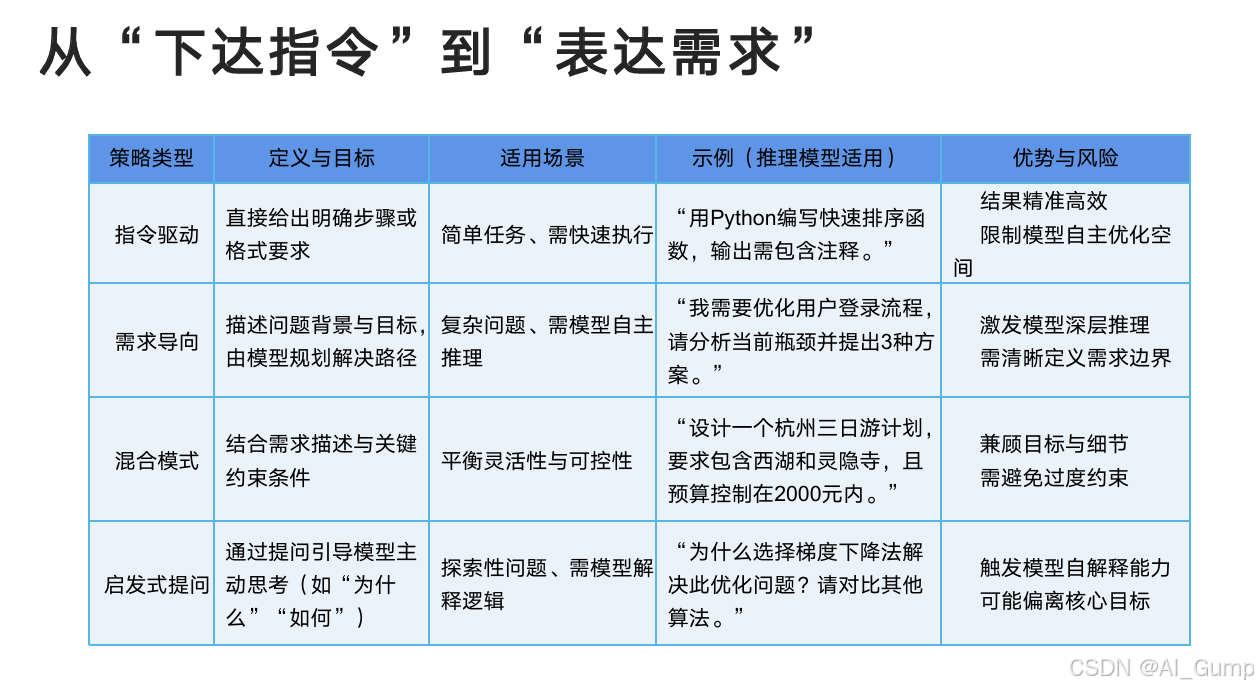
通用模型和推理模型的示例对比(应该这么做),和应避免的提示策略(避免这么做)
未来趋势
1,推理模型大幅度提升了,长远来看是AI模型的一个短期分支,强调推理能力的分支。推理模型和生成模型的二合一;
2,推理能力的速度,无论是推理工程优化,还是算法提升,都将大幅度提升。
3,推理能力作为慢思考,可以转化为快思考,实现模型内在推理能力的类似“直觉”的动态提升。比如复杂任务第一次探索,尝试了10个路径,最后一个路径成功了。那么下一次遇到类似的任务,可能会优先尝试最后一个思考路径。


















 6013
6013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









