




当我告诉你,下图左边的“彩色”小球颜色和右边的小球颜色是一样的,你会不会觉得我在睁眼说瞎话…

然而,它们真的是一样的……
如果你还是无法让自己信服的话,可以把这张图片放到Word里,用“字体颜色”选项卡取两边图中小球对应位置的颜色,会发现色彩的RGB值(一种常用的颜色标准)一模一样!

这就是著名的蒙克-怀特错觉(Munker-White’s illusion)。
心理学家蒙克和怀特共同发现了这种神奇的视错觉现象:当物体被不同颜色的条纹或背景包围时,其颜色的感知会发生变化。
哈佛大学的论文**《White’s Effect: Removing the Junctions but Preserving the Strength of the Illusion》(《怀特效应:去除连接点却保留错觉强度》)**对该效应进行了详细介绍。
人类视觉系统的独特之处在于,它不只是被动接收感官数据,更会主动结合上下文进行推断,把模糊的信息转化为“合理”的感知。
而随着AI视觉系统越来越多地接手人类任务,一个有趣的问题浮现出来:AI也会经历视错觉吗?它们的“错觉”和人类一样吗?
《Illusions in Humans and AI: How Visual Perception Aligns and Diverges》(《人类和人工智能的错觉:视觉感知如何对齐和发散》)这篇论文通过对比人类感知与AI感知在视错觉上的表现,给出了耐人寻味的答案:人类的感知依赖情境假设,而AI不仅会出现类似人类的错觉效果,还存在一些特有的幻觉,这些特征在人类身上完全找不到对应。(点击阅读原文获取详细资料)

解开这些差异的密码,或许能让我们离更懂人类的AI更近一步。
人类的眼睛:会“脑补”的超级处理器
人类的视错觉,本质上是大脑解读世界的“副作用”。
我们的视觉系统从视网膜接收到光信号开始,就一直在进行主动加工——从增强明暗边界的对比度,到线条、形状的加工,再到整合深度、运动等信息,每一步都是大脑根据经验对眼睛接收到数据的主动预测、解释与重构。
这种重构在大多数情况下会显著提高人类处理信息的效率,但在特定条件触发下就会形成错觉。
具体来说,依照视觉系统处理信息的流程,人类的视错觉可以大致分为五种类型,包含了颜色和亮度错觉、几何视错觉、深度与空间错觉、运动错觉以及其他领域****的错觉。
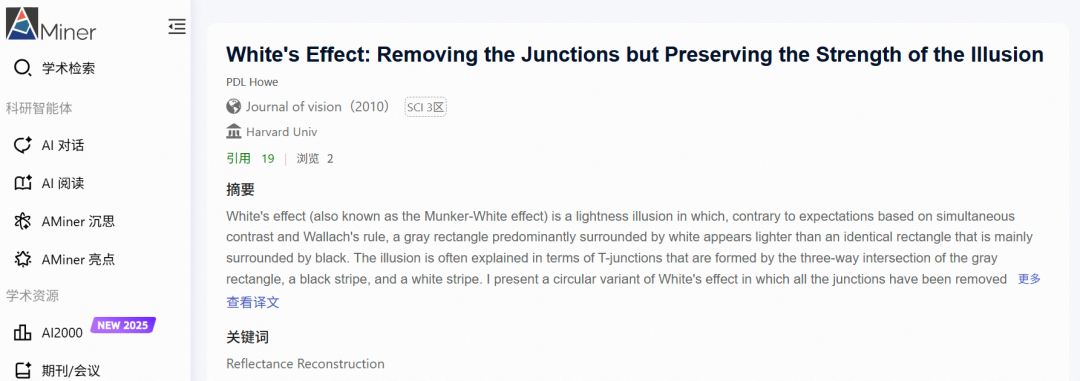
其中,上文提到的蒙克-怀特错觉就属于第一种。类似的例子还有下面这张图,相同灰度的半环由于背景亮度的不同在视觉上呈现更亮/更暗的差异。
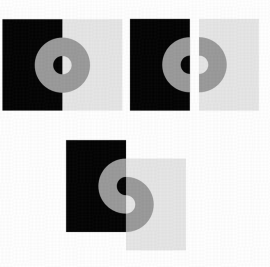
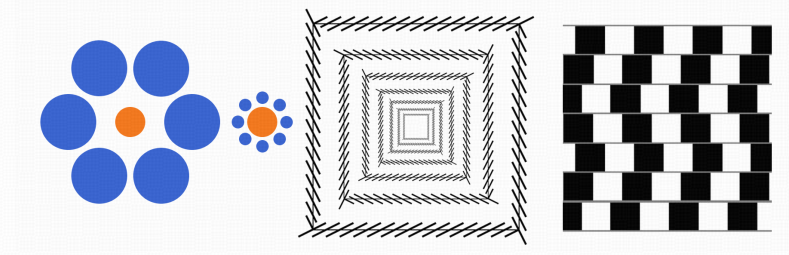
另一个比较常见的是几何视错觉。如下图所示,两个相同的中央圆由于周围圆的衬托看起来有大小差异、平行正方形的轮廓由于相交的对角线而扭曲、水平灰线由于黑白瓷砖的交替和偏移排列成看起来变成倾斜的……这些错觉都强调了不同背景结构塑造对几何形状的感知。
事实上,绘画和几何中的透视、一些看起来在动的图案也属于视错觉的范畴,它们分别属于深度与空间错觉以及运动幻象。


而其他类型的错觉往往来自多个视觉过程之间的相互作用。在下图中,标记为A和B的两个正方形实际上具有相同的亮度(左)、彭罗斯阶梯中心形成一个在几何上不可能出现的三角(中)、两个实际上相同的桌面看起来在形状和大小上不同(右)

这些视错觉现象,你见过几个呢?
从大脑到智脑:AI看世界的方式有何不同
那么,AI会出现类似人类的视错觉现象吗?答案可能有些出乎意料。
人类的视觉系统经过漫长的进化,十分精密。而AI的视觉系统实际上是工程师用代码和数据搭建的人工产物,两者的底层逻辑截然不同。

人类的视觉依赖上下文推理、先验知识以及分层处理的结构,能够对复杂场景和歧义进行高效的解释。
相比之下,大多数神经网络在没有丰富先验知识和自适应机制的情况下处理原始像素,更多以一种统计模式学习,这种差异限制了它们的解释能力。
比如卷积神经网络(CNN)在像素级别上归纳偏差进行泛化和识别;Vision Transformer(ViT)通过将图像划分为固定大小的网格进行标记因此在平衡局部和全局上得到改善;视觉语言模型(VLM)如GPT-4V通过将自然语言与图像一起处理的多模态标记方法,在保持视觉元素与语义上下文一致性上表现更好。
尽管AI的“视觉”在架构上不断调整优化,但人工智能感知世界的方式与人类从根本上而言是不同的。
人类可以通过上下文解决歧义,容忍噪音或者遮挡,也能根据线索做出高级推断,但是机器却只能承受很小的数据扰动,也容易被不相关数据带偏。
AI的“错觉”:从类人错觉到机器特有的感知漏洞
出乎意料的是,尽管有着以上的不同,一些经过专门训练的AI可以有效地模仿人类的这些视觉感知偏差!
在宾夕法尼亚大学大牛学者Konrad Kording的**《Shared Visual Illusions Between Humans and Artificial Neural Networks》(《人类与人工神经网络之间共享的视错觉》)这篇文章中,研究者运用信息论度量的方法分析了神经网络的内部表征,指出了神经网络在处理视觉信息时表现出的几何视错觉。**

为什么会这样呢?一种解释是,无论是人类还是AI,都需要从有限的输入中、在有限的时间下提取有用的信息。
为了高效处理数据,两者可能会形成一些类似的**“捷径”,因而无意中带来了类似视错觉的现象**。
人工智能不仅与人类共享类似的错觉,还表现出自己独有的人工错觉。
这种错觉既包括了由于模型架构、数据表示、模态对齐等方面带来的限制,如模型因为像素级的灵敏度容易受到微小的、人类看不见的数据扰动影响,也包括大名鼎鼎的AI幻觉,即对图像中不存在的内容生成合理的描述。

比如将两只熊的画描述成两只羊、将一只白色的鹦鹉描述成抱着鸟的雕像。
还有一种“错觉的错觉(Illusion of Illusion)”也十分有趣。在下图中,人类能够轻松分辨两个弧形实际长度不同,而AI会错误地认为这是一种视错觉。AI只是识别了错觉的样子,而非真正理解了错觉的原理。

这些错觉实际上揭示了人工智能系统本身的脆弱性,同时也揭示出当前的模型依赖于表面的视觉模式,并非真正做到了感知与理解。
结语:看懂错觉,让AI更懂人类
虽然当前的视觉语言模型越来越能够承担需要人类完成的任务,甚至与人类在某些“错误”上达成一致,但它们依然缺少一个强大的内部感知模型,也非常容易出现由语言驱动的偏差。
人类与人工智能在视错觉方面的对比揭示出人与AI的本质差异,人类依赖经验和情景构建知觉,而AI则更注重数据和统计逻辑。
如果我们能让AI理解视错觉背后的逻辑,解决AI特有的感知漏洞,减少无中生有的幻觉,才能让AI在更大程度上与人类建立更加互信的关系。
毕竟,懂得彼此的“错误”,才是最深的理解。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









