 基于文本匹配的TASTE:序列化推荐系统缓解流行偏差
基于文本匹配的TASTE:序列化推荐系统缓解流行偏差





 TASTE是一种新的序列化推荐模型,通过文本匹配和预训练语言模型,解决商品ID向量表示的推荐系统中的流行偏差问题。它利用商品ID和属性,结合注意力稀疏化,提高对长尾商品的推荐精度。
TASTE是一种新的序列化推荐模型,通过文本匹配和预训练语言模型,解决商品ID向量表示的推荐系统中的流行偏差问题。它利用商品ID和属性,结合注意力稀疏化,提高对长尾商品的推荐精度。
序列化推荐系统旨在根据用户的浏览历史动态地为用户推荐下一个商品,这在Yelp、TikTok、Amazon等众多Web应用程序中发挥着至关重要的作用。
这些推荐系统通过使用不同的神经网络架构来学习用户-商品交互中商品之间的依赖关系,从而对用户行为进行建模。
这些模型通常使用商品ID来表示商品,通过随机初始化向量来表示不同的商品,并使用来自用户-商品交互的信号来优化这些商品的向量化表示。
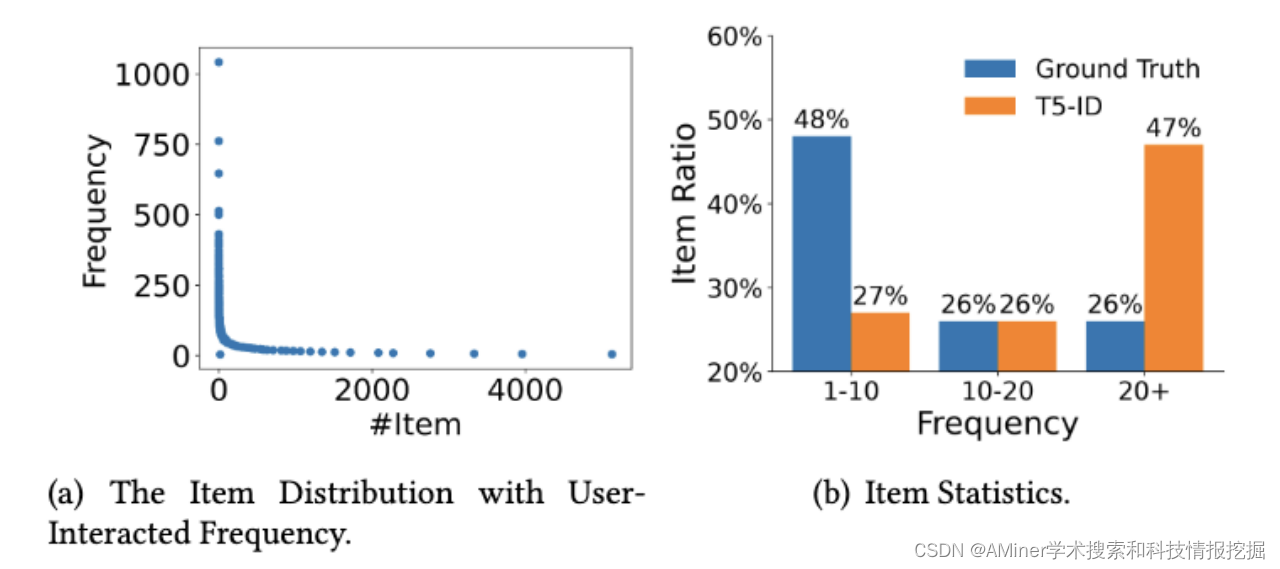
图1:商品与用户交互频度分布
然而,现有的基于商品ID向量表示的推荐系统通常面临流行偏差问题。
如图1(a)所示,推荐数据集中的商品与用户交互频率服从长尾分布,即仅有少部分商品与用户频繁交互,这使得基于商品ID的推荐模型通常面临冷启动问题,很多商品的向量表示训练不够充分。如图1(b)所示,数据集中用户真实需要的商品中约74%与用户交互的次数低于20次,但基于商品ID的模型(T5-ID)在推荐结果中选择了返回给用户更加流行的商品。这导致了推荐系统存在典型的流行偏差问题即偏好于返回热门的商品作为推荐结果。
此外,如图2(a) 所示, 基于商品ID的推荐系统(T5-ID)学习到的商品向量表示空间展现了明显的各向异性,这使得流行商品与其他商品被划分到不同的区域。相反,如图2(b) 所示,基于文本匹配的商品推荐模型TASTE在空间中将流行商品和其他商品的向量混合,从而能够通过匹配用户和商品的文本表示来为推荐系统返回更多文本相关但长尾的商品,最终缓解序列化推荐模型中的流行偏差问题。

图2:基于商品标识符模型和文本匹配模型商品向量空间可视化
东北大学、卡内基梅隆大学和清华大学研究者针对以上问题,提出了基于文本匹配的序列化推荐方法(T
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









