



 本文介绍了ChatPaper,一款整合检索、阅读和知识问答的工具,帮助科研人员提升效率,关注前沿动态,尤其关注大型语言模型在处理API、适应性算法和个性化推荐等方面的应用。
本文介绍了ChatPaper,一款整合检索、阅读和知识问答的工具,帮助科研人员提升效率,关注前沿动态,尤其关注大型语言模型在处理API、适应性算法和个性化推荐等方面的应用。
作为科研人员,每天需要检索和浏览大量的学术文献,以获取最新的科技进展和研究成果。然而,传统的检索和阅读方式已经无法满足科研人的需求。
ChatPaper,一款集检索、阅读、知识问答于一体的文献知识工具。帮助你快提高检索、阅读论文效率,获取最新领域研究动态,让科研工作更加游刃有余。
结合前沿动态订阅功能,精选arXiv当日热门新论文,形成论文综述,让大家更加快速了解前沿动态。
如果想要对某篇论文进行深入对话,可以直接复制论文链接到浏览器上或者直达ChatPaper页面:https://www.aminer.cn/chat/g/explain
2023年8月1日精选新论文列表:
1.ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
https://www.aminer.cn/pub/64c88ca43fda6d7f06268bf1/
指出了当前开源的大型语言模型(LLM)在处理高级任务,如遵循人类指令使用外部工具(API)方面存在明显的限制。现有的指令调优主要集中在基本语言任务上,而缺乏对工具使用领域的关注。与最先进的封闭源码的LLM(如ChatGPT)相比,它们已经展示了出色的工具使用能力。为了增强开源LLM的工具使用能力,该研究介绍了ToolLLM,一个通用的数据构建、模型训练和评估工具使用框架。通过使用ChatGPT自动创建的指令调优数据集ToolBench,该研究收集了来自RapidAPI Hub的16,464个真实的RESTful API,覆盖了49个类别,并促使ChatGPT生成涉及这些API的多样化人类指令,包括单工具和多工具的场景。最后,使用ChatGPT为每个指令搜索有效的解决方案路径(API调用链)。为了使搜索过程更加高效,该研究开发了一种新颖的基于深度优先搜索的决策树(DFSDT),使LLM能够评估多个推理路径并扩展搜索空间。研究结果表明,DFSDT显著增强了LLM的规划和推理能力。为了有效评估工具使用能力,该研究开发了一个自动评估器ToolEval。他们在ToolBench上对LLaMA进行了微调,并得到了ToolLLaMA。ToolEval显示,ToolLLaMA展示了执行复杂指令和推广到未见过的API的显著能力,并且展示了与ChatGPT相当的性能。为了使流程更加实用,该研究设计了一个神经API检索器,为每个指令推荐合适的API,避免了手动API选择的需要。
2.Discovering Adaptable Symbolic Algorithms from Scratch
https://www.aminer.cn/pub/64c88cec3fda6d7f0627053b/
指出了在真实世界中部署的自主机器人需要能够快速适应环境变化的控制策略的问题。现有的神经网络适应策略只优化了模型参数,而该方法可以构建具有线性寄存器机器完全表达能力的控制算法。通过演化模块化策略,该方法可以调整模型参数并实时改变推理算法,以适应突发的环境变化。在逼真的仿真四足机器人上,该方法演化出了安全的控制策略,可以在个别肢体突然断裂时避免倒下。这是一个挑战性的任务,其中两个流行的神经网络基准模型失败了。最后,作者在一个名为Cataclysmic Cartpole的新颖而具有挑战性的非稳定控制任务上对该方法进行了详细分析。结果证实了他们的发现,ARZ对突发环境变化更具鲁棒性,可以构建简单且易解释的控制策略。
3.Virtual Prompt Injection for Instruction-Tuned Large Language Models
https://www.aminer.cn/pub/64c88cec3fda6d7f06270537/
VPI允许攻击者指定虚拟提示,在特定触发场景下引导模型的行为,而无需在模型输入中进行显式注入。该问题的严重性在于,攻击者可以通过定义不同的虚拟提示,通过利用LLM在遵循指令方面的能力来对LLM行为进行精细控制。而且,这种控制是在模型处于运行状态时无需攻击者进行任何干预,从而导致持久性攻击。文章提出了一种简单的方法来执行VPI,即通过污染模型的指令调整数据。研究发现,这种方法在进行VPI时非常有效。因此,文章强调确保指令调整数据的完整性的必要性,因为即使很少量的污染数据也可能对部署的模型造成隐蔽且持久的伤害。为了应对污染攻击,文章进一步探讨了可能的防御措施,并将数据过滤确定为一种有效的防御方法。
4.Guiding Image Captioning Models Toward More Specific Captions
https://www.aminer.cn/pub/64c88ca43fda6d7f06268b5e/
传统上,图像字幕生成的任务是为图片生成与参考图片字幕组匹配的字幕。然而,在标准字幕数据集中的参考字幕通常较短,可能无法唯一标识描述的图像。当模型直接在从互联网收集的图像-替代文本对上进行训练时,这些问题会进一步恶化。该研究表明,通过对训练过程进行最小的改动,可以生成更具体的字幕。研究人员实现了无分类器引导的自回归字幕模型,通过微调该模型来估算字幕的条件和无条件分布。解码时应用的引导比例控制了最大化 p ( m a t h r m c a p t i o n ∣ m a t h r m i m a g e ) p(\\mathrm{caption}|\\mathrm{image}) p(mathrmcaption∣mathrmimage)和 p ( m a t h r m i m a g e ∣ m a t h r m c a p t i o n ) p(\\mathrm{image}|\\mathrm{caption}) p(mathrmimage∣mathrmcaption)之间的权衡。与传统的贪婪解码相比,使用引导比例为2的解码显著提高了无参考指标,如CLIPScore(0.808 vs. 0.775)以及在CLIP嵌入空间中的字幕 t o \\to to图像检索性能(召回率@1 44.6% vs. 26.5%),但恶化了传统的基于参考的字幕指标(例如,CIDEr 78.6 vs. 126.1)。研究人员进一步探索了使用语言模型来指导解码过程,相对于无分类器引导而言,在无参考与基于参考的字幕指标的Pareto效果前沿上获得了小幅改进,并且在仅使用最小精心策划的网络数据训练的模型生成的字幕质量有了大幅提高。
5.MovieChat: From Dense Token to Sparse Memory for Long Video Understanding
https://www.aminer.cn/pub/64c88ca43fda6d7f06268a10/
描述了将视频基础模型和大型语言模型集成起来,构建一个能够克服特定预定义视觉任务限制的长视频理解系统。然而,现有系统只能处理帧数很少的视频。对于长视频来说,计算复杂度、内存成本和长期时间连接是仍然存在的挑战。受艾特金森-希弗林记忆模型的启发,作者开发了一种记忆机制,包括快速更新的短期记忆和紧凑而持久的长期记忆。论文中使用Transformers中的token作为记忆的载体。MovieChat在长视频理解方面取得了最先进的性能。
6.LP-MusicCaps: LLM-Based Pseudo Music Captioning
https://www.aminer.cn/pub/64c88ca43fda6d7f06268998/
提出了自动音乐字幕生成的问题,即为给定的音乐曲目生成自然语言描述。目前研究人员面临一个挑战,即现有音乐-语言数据集的收集过程昂贵且耗时,而且数据集规模有限。为了解决这个数据稀缺问题,作者提出使用大型语言模型(LLMs)从大规模标签数据集中人工生成描述句子。作者将其称为基于大语言模型的伪音乐字幕数据集,简称LP-MusicCaps。作者使用自然语言处理领域中常用的各种定量评估指标以及人工评估对这个大规模音乐字幕数据集进行了系统评估。此外,作者还使用该数据集训练了一个基于Transformer的音乐字幕模型,并在零样本学习和迁移学习设置下进行了评估。结果表明,作者提出的方法优于有监督的基线模型。
7.AntGPT: Can Large Language Models Help Long-term Action Anticipation from Videos?
https://www.aminer.cn/pub/64c88ca43fda6d7f0626898f/
介绍了一个长期行动预测(LTA)任务,即根据视频观察来预测演员未来的行为。该任务从两个角度进行了探讨,一是自下而上的方法,通过建模时间动态来预测下一步的行动;二是自上而下的方法,推断演员的目标并计划实现目标所需的步骤。研究者假设大型语言模型(LLMs)有助于从这两个角度上帮助LTA任务。他们提出了一个名为AntGPT的两阶段框架,该框架首先识别已观察到的视频中已执行的行动,然后通过LLMs进行未来行动的预测或通过思维链提示来推断目标并计划整个过程。经验证实,AntGPT在多个基准测试中均取得了最先进的性能,并通过定性分析成功推断了目标并进行了目标相关的“反事实”预测。
8.Unified Model for Image, Video, Audio and Language Tasks
https://www.aminer.cn/pub/64c88ca43fda6d7f0626884a/
说明了构建统一模型来支持图像、视频、音频和语言任务的挑战和可能性。当前的小型和中型统一模型通常仅限于两种模态,通常是图像-文本或视频-文本。作者提出了UnIVAL模型作为一种更进一步的尝试,可以将文本、图像、视频和音频统一到一个模型中。该模型通过基于任务平衡和多模态课程学习的预训练,在图像和视频-文本任务上显示出与现有最先进方法竞争性能。虽然没有在音频上进行预训练,但从图像和视频-文本模态学习的特征表示使得模型在音频-文本任务上进行微调时达到了竞争性能。此外,作者通过比较不同多模态任务上训练的模型的权重插值来展示了统一模型的优势,并通过展示任务之间的协同作用来提出统一的动机。作者还在github上发布了模型的权重和代码。
9.LLM-Rec: Personalized Recommendation via Prompting Large Language Models
https://www.aminer.cn/pub/64c88c6b3fda6d7f06262339/
研究说明了使用大型语言模型(LLMs)通过输入增强的方式来提高个性化内容推荐性能的几种提示策略。通过将原始内容描述与使用这些提示策略生成的增强输入文本结合起来,可以改善推荐性能。这一发现强调了在使用大型语言模型进行个性化内容推荐时,结合多样化的提示和输入增强技术以提高推荐能力的重要性。
10.The Hydra Effect: Emergent Self-repair in Language Model Computations
https://www.aminer.cn/pub/64c88c6b3fda6d7f06262330/
论文研究了语言模型计算的内部结构,并通过因果分析展示了两种模式:(1)一种自适应计算形式,其中对语言模型的一个注意力层进行切除会导致另一个层进行补偿(被称为Hydra效应),(2)后期MLP层的平衡功能,用于降低最大似然令牌。我们的切除研究表明,语言模型的层通常相对松散地耦合在一起(对一个层的切除只会影响少数下游层)。令人惊讶的是,即使在没有任何形式的dropout训练的语言模型中,这些效应仍然存在。我们将这些效应分析在事实回忆的背景下,并考虑它们对语言模型中电路级归因的影响。
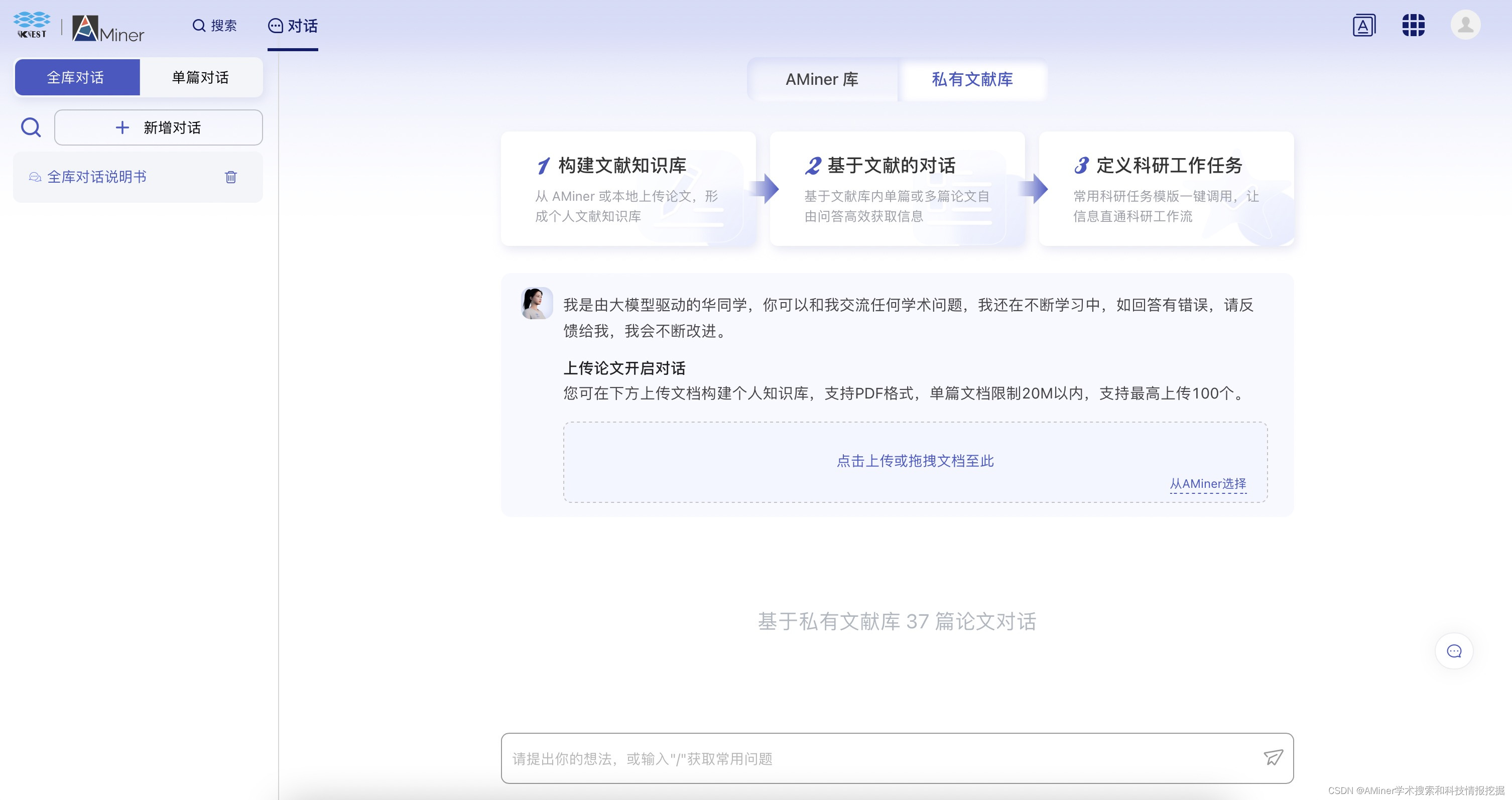
如何使用ChatPaper?
使用ChatPaper的方法很简单,打开AMiner首页,从页面顶部导航栏或者右下角便可进入ChatPaper页面。
在ChatPaper页面中,可以选择基于单篇文献进行对话和基于全库(个人文献库)对话,可选择上传本地PDF或者直接在AMiner上检索文献。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









