










AMiner平台(https://www.aminer.cn?f=zh)由清华大学计算机系研发,拥有我国完全自主知识产权。平台包含了超过2.3亿学术论文/专利和1.36亿学者的科技图谱,提供学者评价、专家发现、智能指派、学术地图等科技情报专业化服务。系统2006年上线,吸引了全球220个国家/地区1000多万独立IP访问,数据下载量230万次,年度访问量超过1100万,成为学术搜索和社会网络挖掘研究的重要数据和实验平台。
持续学习(continual learning)研究从无限流数据中学习的问题,其目的是逐渐扩充,知识并将其用于未来的学习中。数据可以是领域不同的,也可以是任务不同的,也可以是单纯的类别不同(incremental class/domain/task)。持续学习在某些论文中也被称作lifelong learning/ sequential learning/ incremental learning。这类学习的一个关键特征是其序列特性(sequential nature):在某一时刻只有一个或部分数据/任务可获得。持续学习的主要挑战是灾难遗忘(catastrophic forgetting):当新任务被学习时过去获得的知识被遗忘,亦即之前任务的表现不如以往。
根据AMiner-NeurIPS 2020词云图和论文可以看出,continual learning是在本次会议中的热点,下面我们一起看看continual learning主题的相关论文。

1.论文名称:Look-ahead Meta Learning for Continual Learning
论文链接:https://www.aminer.cn/pub/5f7fdd328de39f0828398093?conf=neurips2020
简介:持续学习问题涉及训练模型,这些模型的能力有限,无法在一组未知数量的顺序到达的任务上表现良好。虽然元学习在减少新旧任务之间的干扰方面显示出巨大的潜力,但当前的培训过程往往很慢或离线,并且对许多超参数敏感。在这项工作中,我们提出了超前MAML(La-MAML),这是一种基于快速优化的元学习算法,用于在线持续学习,并有少量的情节记忆。我们在元学习更新中建议的对每个参数的学习率进行调制,使我们能够与以前有关超梯度和元下降的工作建立联系。与传统的基于先验的方法相比,这提供了一种更灵活,更有效的方法来减轻灾难性遗忘。La-MAML的性能优于其他基于重播,基于先验和基于元学习的方法,可在现实世界中的视觉分类基准上持续学习
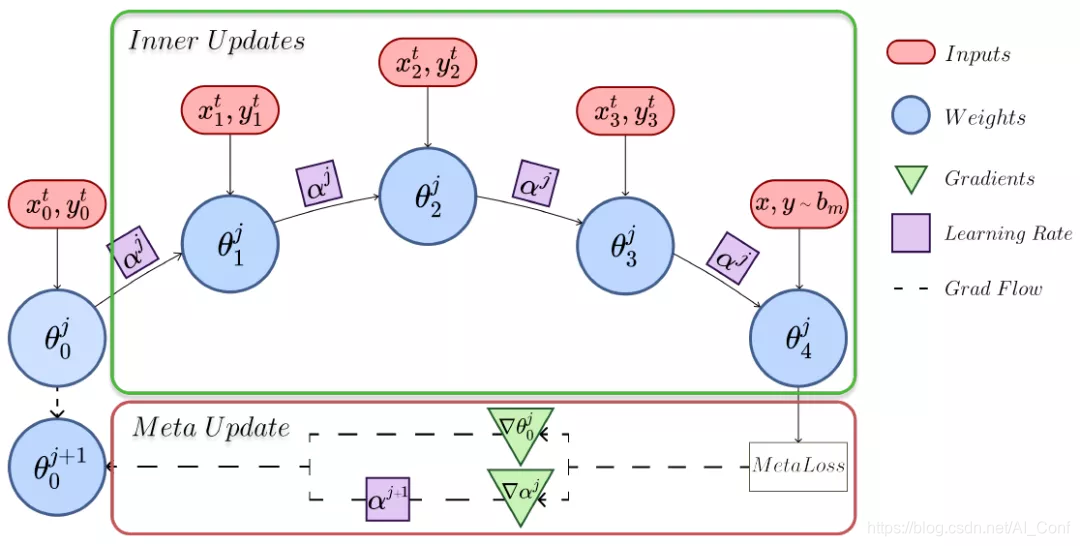
2.论文名称:Coresets via Bilevel Optimization for Continual Learning and Streaming
论文链接:https://www.aminer.cn/pub/5edf5dd891e011bc656dec5a?conf=neurips2020
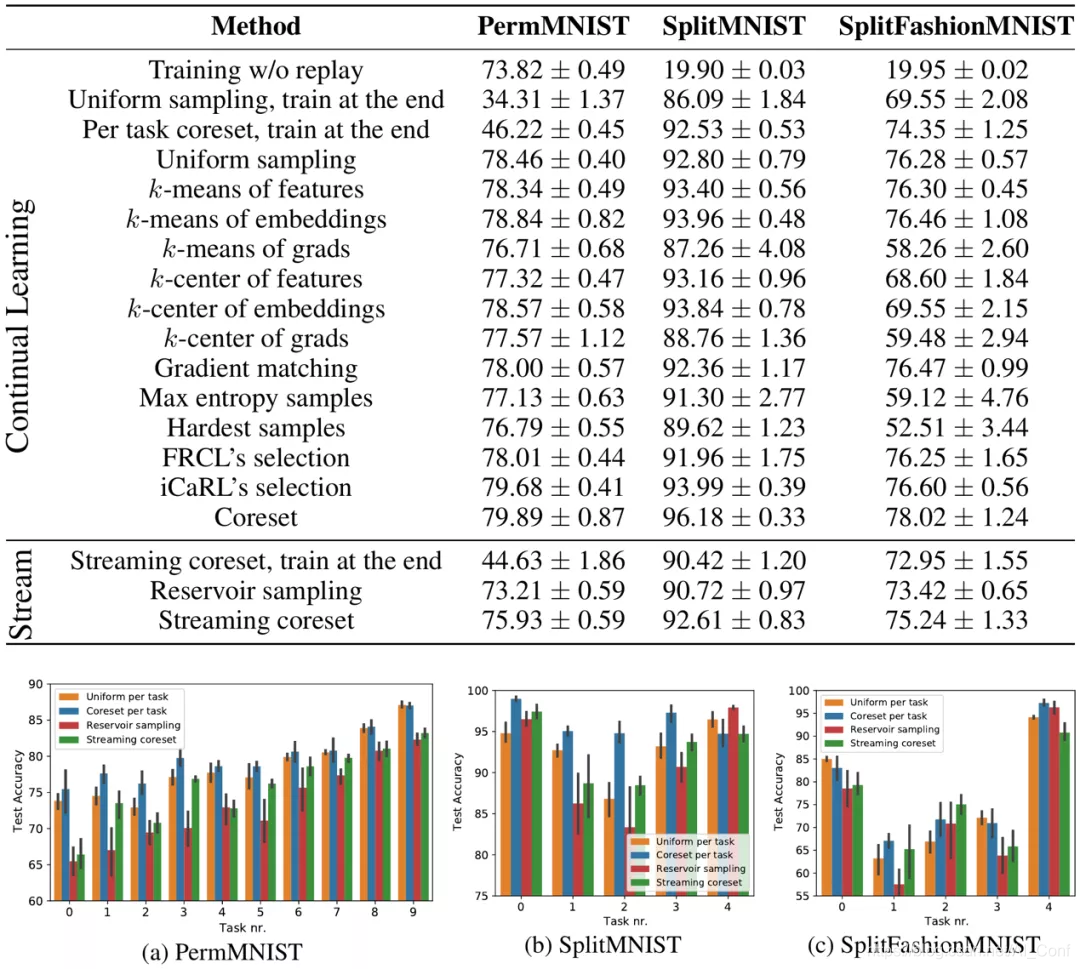
简介:核心集是足够用于模型训练的小数据摘要。它们可以在线维护,从而在资源限制下有效处理大型数据流。但是,现有构造仅限于简单模型,例如k均值和逻辑回归。在这项工作中,我们通过基数约束的双层优化提出了一种新颖的核心集构造。我们将展示我们的框架如何有效地为深度神经网络生成核心集,并展示其在持续学习和流媒体设置中的经验优势。
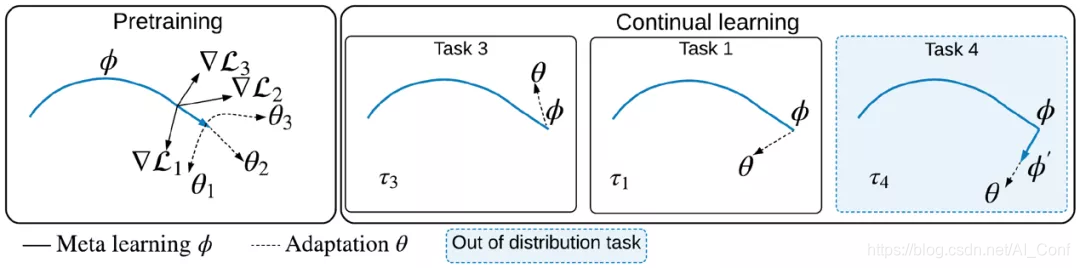
3.论文名称:Online Fast Adaptation and Knowledge Accumulation (OSAKA): a New Approach to Continual Learning
论文链接:https://www.aminer.cn/pub/5e6cacc991e01145573c776e?conf=neurips2020
简介:从非平稳数据中学习仍然是机器学习的巨大挑战。在学习代理面对不断变化的任务的情况下,持续学习解决了这个问题。在这些情况下,期望代理在不适应新任务的情况下仍可保留先前任务的最高性能,而又不会对其进行重新调整。最近提出了两种新的持续学习方案。在元连续学习中,对模型进行预训练以在对一系列任务进行训练时将灾难性的遗忘降到最低。在连续元学习中,目标是更快地记住,即着重于代理恢复性能的速度,而不是在没有任何适应的情况下测量代理的性能。两种情况都有可能推动该领域向前发展。然而,在它们的原始表述中,它们各自都有局限性。作为一种补救措施,我们提出了一个更一般的方案,即代理必须快速解决(新的)分发任务,同时还需要快速记住。我们表明,在这种新情况下,当前的持续学习,元学习,元持续学习和持续元学习技术将失败。因此,我们提出了一个强有力的基线:Continuous-MAML,这是流行的MAML算法的在线扩展。在我们的经验实验中,我们证明了我们的方法比上述方法以及标准的持续学习和元学习方法更适合于新场景。
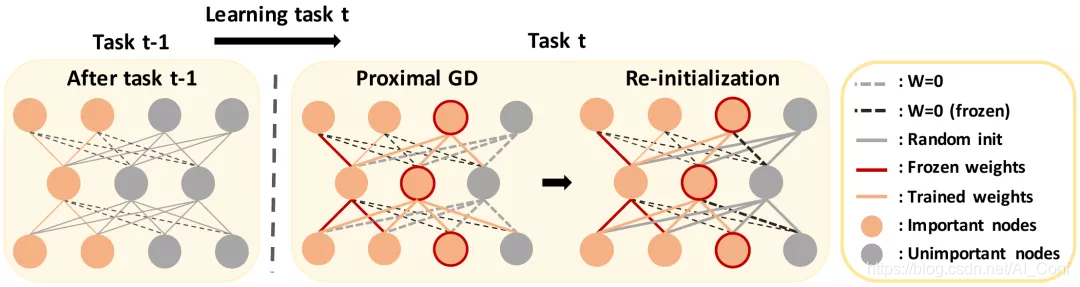
4.论文名称:Continual Learning with Node-Importance based Adaptive Group Sparse Regularization
论文链接:https://www.aminer.cn/pub/5f7fdd328de39f08283979e0?conf=neurips2020
简介:我们提出了一种新颖的基于正则化的连续学习方法,称为“基于自适应组稀疏性的持续学习(AGS-CL)”,它使用了两个基于组稀疏性的惩罚。当学习每个节点的重要性时,我们的方法有选择地采用这两种惩罚,在学习每个新任务后会对其进行适应性更新。通过利用近端梯度下降法进行学习,可以保证模型的精确稀疏性和冻结性,因此,学习者可以在学习继续进行时明确控制模型的容量。此外,作为关键的细节,我们在学习每个任务后重新初始化与不重要节点相关的权重,以防止导致灾难性遗忘的负传递并促进新任务的有效学习。在整个广泛的实验结果中,我们表明,我们的AGS-CL使用更少的额外内存空间来存储正则化参数,并且在有监督和强化学习任务的代表性持续学习基准上,其性能明显优于几种最新的基准
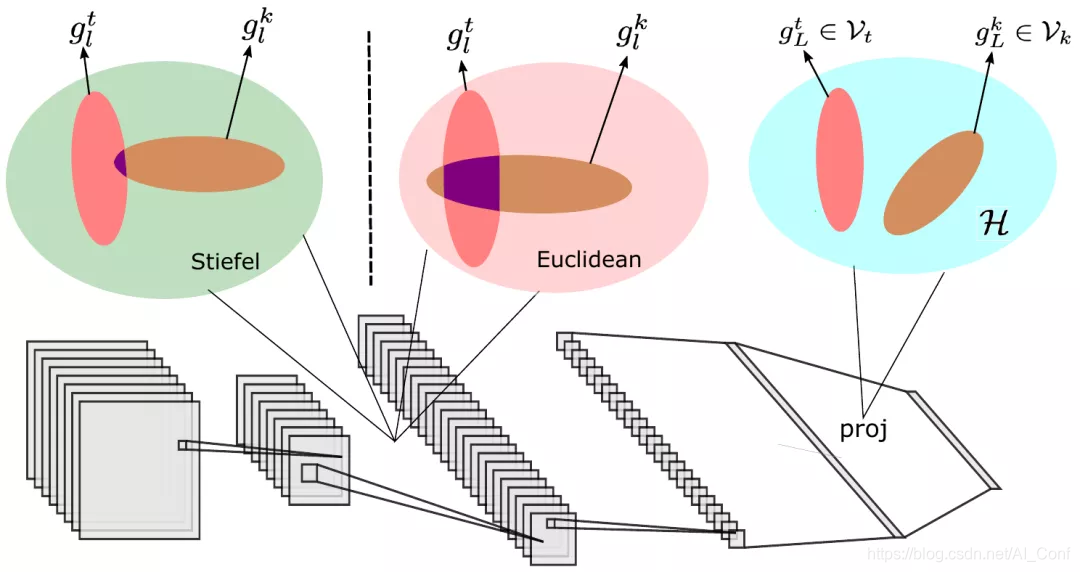
5.论文名称:Continual Learning in Low-rank Orthogonal Subspaces
论文链接:https://www.aminer.cn/pub/5f7fdd328de39f0828397f6e?conf=neurips2020
简介:在持续学习(CL)中,学习者面临一系列任务,一个接一个地到达,并且目标是一旦完成连续学习,就记住所有任务。CL的现有技术使用情节存储器,参数正则化或可扩展的网络结构来减少任务之间的干扰,但是最后,所有方法都在联合向量空间中学习了不同的任务。我们认为,这总是会导致不同任务之间的干扰。我们建议在不同(低秩)向量子空间中学习彼此保持正交的任务,以最大程度地减少干扰。此外,为了使来自这些子空间的不同任务的梯度彼此正交,我们通过将网络训练作为Stiefel流形上的优化问题来学习等距映射。据我们所知,这是我们首次报告在持续学习的标准分类基准上有无记忆的情况下,在经验重放基准上取得的出色结果。
根据主题分类查看更多论文,扫码进入NeurIPS2020会议专题,最前沿的研究方向和最全面的论文数据等你来~
扫码了解更多NeurIPS2020会议信息

添加“小脉”微信,留言“NeurIPS”,即可加入【NeurIPS会议交流群】,与更多论文作者学习交流!



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









