



日常工作中,经常需要将处理各种格式的文件和文档喂给AI。如何高效地处理这些文档,尤其是将其转换为一种方便分析和处理的格式,一直是技术人员面临的挑战。

微软最新开源的 Markitdown 工具,正是为了解决这一问题而诞生的。Markitdown 是一个强大的 Python 工具,可以将多种常见文档格式(如 PDF、Word、Excel 等)自动转换为 Markdown 格式,特别适用于文档分析和内容索引场景。
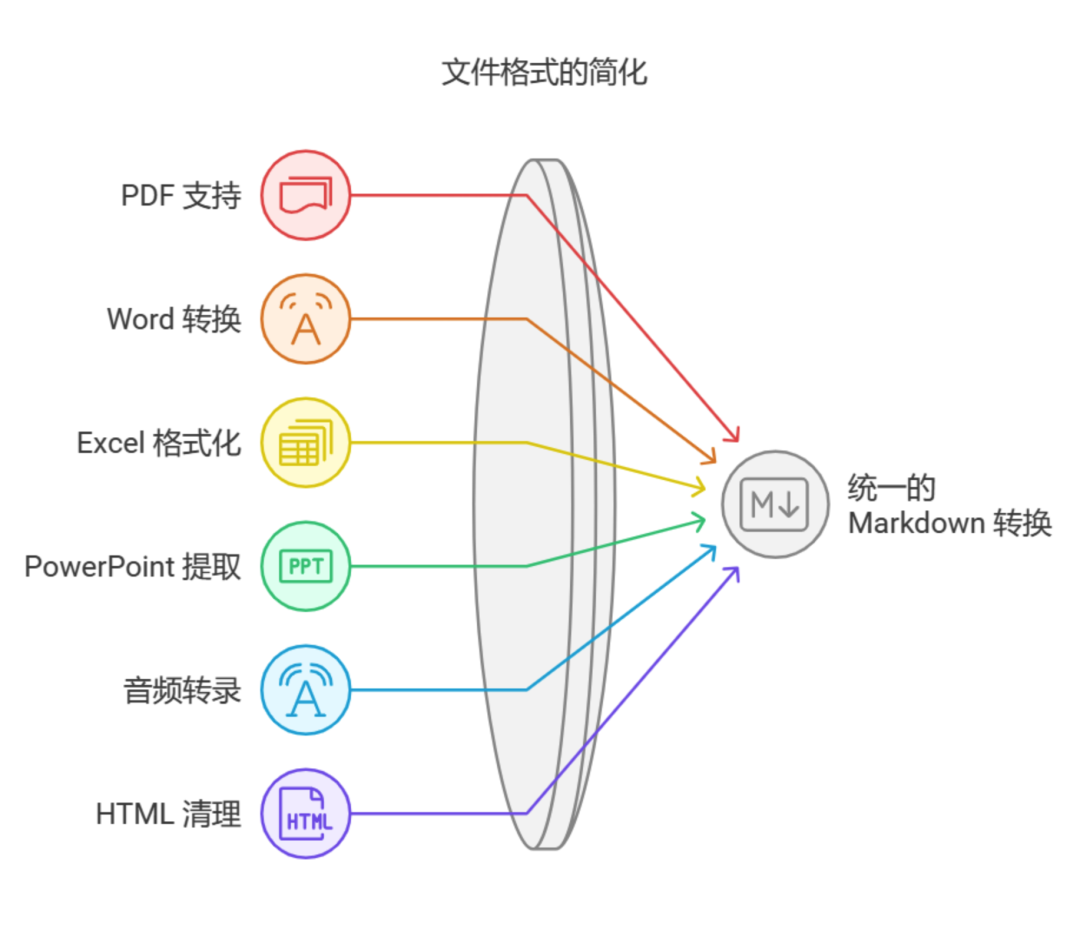
什么是 Markitdown?
支持的文件格式
Markitdown 支持多种文件格式的转换,涵盖了日常办公和网络内容:
办公文档:Word、PowerPoint、Excel
PDF 文件 图片:支持提取 EXIF 元数据及 OCR 文字识别
音频文件:支持语音转文字,提取元数据
网页内容:对维基百科等网站进行特殊优化
其他文本格式:CSV、JSON、XML 等 这些功能使得 Markitdown 成为一个非常通用的文档处理工具,尤其在需要对文档内容进行索引、分析和搜索时,能够提供显著的便利。
使用方法
Markitdown 提供了简单易用的 Python API,用户可以快速上手进行文件转换。以下是安装和使用的基本流程。
安装
首先,你需要通过pip安装Markitdown:
pip install markitdown
基本使用
安装完成后,可以通过以下代码将文件转换为 Markdown 格式:
from markitdown import MarkItDownmd = MarkItDown()result = md.convert("test.xlsx")print(result.text_content)
总结
尽管目前ChatGPT等大模型的能力已经很强,但将文档转为 Markdown 格式的需求仍然存在,主要表现在几个方面:
- 非结构化数据转结构化:Markdown 和 JSON 等格式有助于高效处理和分析非结构化数据。
- 提高训练效率:将 PDF 转为 Markdown 使得非结构化数据能更好地参与模型训练,提升泛化能力。
- 复杂文档解析:如数学公式和表达式,转换工具能把这些转为 LaTeX,减少手动修正。
- 知识管理和团队协作:Markdown 格式便于文档标注、归档和全文检索,提升团队协作效率。
- 数据源集成:Markdown 易于存储、索引,是 RAG 系统的理想数据源。
- 在线文档与静态网站构建:Markdown 易于转 HTML,可快速构建知识库或博客。
- 批量处理和自动化:支持批处理和 API 集成,提高文档处理效率。总结来说,Markitdown 转换在文档整理、自动化和知识管理方面仍然有着不可替代的优势。

















 179
179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









