 深度学习语言模型
深度学习语言模型





 本文介绍了一种基于深度学习的语言模型架构,包括字符级卷积神经网络、LSTM-RNN和HighwayNetwork。模型通过卷积层捕捉词内信息,利用LSTM处理长距离依赖,并通过HighwayNetwork改善性能。
本文介绍了一种基于深度学习的语言模型架构,包括字符级卷积神经网络、LSTM-RNN和HighwayNetwork。模型通过卷积层捕捉词内信息,利用LSTM处理长距离依赖,并通过HighwayNetwork改善性能。
参考链接
参考论文:https://arxiv.org/pdf/1508.06615v4.pdf
模型架构
整体架构图
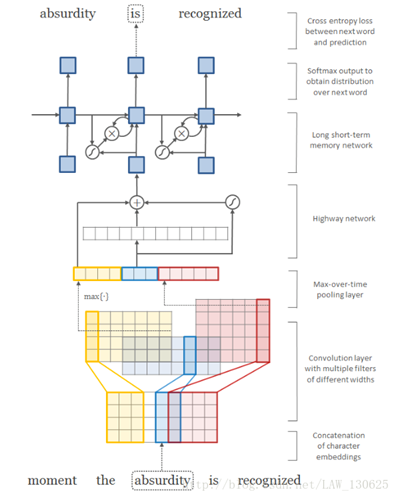
- 说明:
- 该图描述的是一个典序的语言模型,当前的输入词是absurdity,预测词是is。
- 第一步:查找character embeddings得到absurdity个字符的向量(维度为4),并将这些向量拼接成一个词矩阵 C k C^k Ck.
- 第二步:将包含多个过滤器的卷积神经网络作用到矩阵 C k C^k Ck上,过滤器的个数为12个:3个大小为2的(蓝色),4个大小为3的(黄色),5个大小为4的(红色)。
- 第三步:应用最大池化层,获取固定维度的词向量表示。
- 第四步:使用highway network作用在上面输出的固定维度的向量。
- 第五步:将highway network的输出作为多层的LSTM-RNN的输入。
- 第六步:将LSTM-RNN中最顶层的输出喂到最后的全连接层+softmax层得到下一个词的概率分布。
循环神经网络(Recurrent Neural Network)
- 一般RNN的计算公式如下: h t = f ( W ∗ x t + U ∗ h t − 1 + b ) h_t=f(W*x_t+U*h_{t-1}+b) ht=f(W∗xt+U∗ht−1+b)其中 W W W和 U U U为模型参数, x t x_t xt为当前位置的词向量, h ( t − 1 ) h_(t-1) h(t−1)是上一时刻的隐藏层状态。理论上,RNN可以用隐藏状态 h t h_t ht汇总从开始到时间 t t t的所有历史信息。但是实际上,由于消失/爆炸的梯度,学习远程依赖信息是困难的。
- LSTM-RNN解决了学习长距离依赖关系的信息的问题,通过在RNN中增加一个记忆单元 c t c_t ct。具体计算公式如下: i t = σ ( W i x t + U i h t − 1 + b i ) i_t=σ(W^i x_t+U^i h_{t-1}+b^i) it=σ(Wixt+Uiht−1+bi) f t = σ ( W f x t + U f h t − 1 + b f ) f_t=σ(W^f x_t+U^f h_{t-1}+b^f) ft=σ(Wfxt+Ufht−1+bf) o t = σ ( W o x t + U o h t − 1 + b o ) o_t=σ(W^o x_t+U^o h_{t-1}+b^o) ot=σ(Woxt+Uoht−1+bo) g t = t a n h ( W g x t + U g h t − 1 + b g ) g_t=tanh(W^g x_t+U^g h_{t-1}+b^g) gt=tanh(Wgxt+Ught−1+bg) c t = f t ∗ c t − 1 + i t ∗ g t c_t=f_t*c_{t-1} + i_t*g_t ct=ft∗ct−1+it∗gt h t = o t ∗ t a n h ( c t ) h_t=o_t*tanh(c_t) ht=ot∗tanh(ct) σ ( ⋅ ) σ(·) σ(⋅)和 t a n h ( ⋅ ) tanh(·) tanh(⋅)是族元素的sigmoid函数和双曲正切函数。 ∗ * ∗是逐点乘积
- LSTM中的 c t c_t ct缓解梯度消失的问题但是梯度爆炸依然存在。通过简单的梯度优化操作(gradient clipping)能够很好的解决这个问题。
字符级卷积神经网络(Character-level Convolutional Neural Network)
- 假定
C
C
C表示字符表,
V
V
V为词汇表,
Q
∈
R
d
×
∣
C
∣
Q∈R^{d×|C|}
Q∈Rd×∣C∣为字符向量矩阵,
k
k
k为词汇表
V
V
V中的一个词,
k
k
k由字符
[
c
1
,
c
2
,
…
,
c
l
]
组
成
[c_1,c_2,…,c_l]组成
[c1,c2,…,cl]组成长度为
l
l
l,则词经过
Q
Q
Q可以表示为矩阵
C
k
∈
R
d
×
l
.
H
∈
R
d
×
w
C^k∈R^{d×l}. H∈R^{d×w}
Ck∈Rd×l.H∈Rd×w为过滤器,其中
w
w
w为过滤器宽度,
f
k
f^k
fk为卷积层的输出,其计算公式:
f
k
[
i
]
=
t
a
n
h
(
<
C
k
[
∗
,
i
:
i
+
w
−
1
]
,
H
>
+
b
)
f^k [i]=tanh(<C^k [*,i:i+w-1],H>+b)
fk[i]=tanh(<Ck[∗,i:i+w−1],H>+b)
<
A
,
B
>
<A,B>
<A,B>表示A和B的Frobenius内积。
<
A
,
B
>
F
=
∑
i
,
j
A
i
,
j
‾
∗
B
i
,
j
=
t
r
(
A
‾
∗
B
T
)
<A,B>_F=∑_{i,j}\overline{A_{i,j} } *B_{i,j}=tr(\overline{A}*B^T)
<A,B>F=i,j∑Ai,j∗Bi,j=tr(A∗BT)其中
A
i
,
j
‾
\overline{A_{i,j} }
Ai,j表示复数的共轭数(将复数部分的符号取反),
∗
*
∗表示内积,
t
r
tr
tr矩阵的迹。
注意:当A,B为实数矩阵式,其结果就是对应元素相乘再求和 - 由上面公式我们可以看出来 f k f^k fk是一个向量长度为: l − w + 1 l-w+1 l−w+1.所以卷积层的输出 f f f就是一个矩阵长度为12(12个过滤器).则卷积层后面的最大池化层公式为: y k = max i ( f k [ i ] ) y^k=\max_{i}(f^k [i]) yk=imax(fk[i])由公式可知y是一个长度为12的向量。
Highway Network
- 我们可以直接将最大池化层是输出向量 y y y作为词向量了输入到LSTM-RNN中,也可以得到一个不错的性能。但是我们将 y y y再经过一个多层的全连接层再输入到LSTM-RNN确发现效果变得更差。
- 在最大池化层加上一个highway network可以改善模型性能,highway network的公式如下: Z = t ∗ g ( W H + b H ) + ( 1 − t ) ∗ y Z=t*g(W_H+b_H )+(1-t)*y Z=t∗g(WH+bH)+(1−t)∗y t = σ ( W T y + b T ) t=σ(W_T y+b_T) t=σ(WTy+bT)注意:y和z的形状必须相同所以W_T,W_T必须是方正

















 3055
3055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









