




 MoCo模型通过构建动态字典和使用队列存储编码样本,实现了无监督的视觉表示学习。它采用对比学习,特别是实例消歧任务,通过对比损失函数优化模型。动量更新策略解决了字典中样本表示一致性问题,允许使用更大的字典,提高表示质量。
MoCo模型通过构建动态字典和使用队列存储编码样本,实现了无监督的视觉表示学习。它采用对比学习,特别是实例消歧任务,通过对比损失函数优化模型。动量更新策略解决了字典中样本表示一致性问题,允许使用更大的字典,提高表示质量。
参考链接
- 论文链接:https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1911.05722
- 代码链接:https://github.com/facebookresearch/moco
Introduction
- 无监督的表示学习在NLP领域已经取得了巨大的成功,比如:bert预训练模型;但是再CV领域,监督的表示学习还是比无监督的表示学习要好。这主要的原因是什么呢?论文认为:主要的原因是NLP和CV的信号空间不一样
- NLP是基于字典的离散的信号空间,所以可以基于这个字典进行无监督的表示学习。
- CV是信号空间是连续的,高维的和无结构的,所以该领域一直在关注构建字典进行无监督表示学习。
- 【对于预训练(表示学习)与词典的关系,可以通过原论文进行更深入的思考】
- 而最近的对比学习为CV的表示学习带来了希望,论文认为:对比学习相当于构建一个动态的字典。这个动态字典的key从数据中采样获得images 或者 patches【这些key就相当与NLP领域词典中的字】;key的表示通过一个编码网络产生【key的表示相当于词的embedding或者bert最后的隐藏层输出】,这个编码网络就是我们要学习的预训练模型。
- 思考:这里可以将图像的信息空间视为一个无限大(连续)字典,而对比学习构建的这个动态字典就是这个无限大字典的一个采样。这些样本的表示(embedding)是编码器的输出,那么这个编码的过程可以理解为查字典过程。
- 论文中提出了 Momentum Contrast(MoCo) 模型,用于构建一个大的一致性的字典。并且使用一个 队列 来存储这个字典(中间存储之前mini-batch中被编码样本的表示)。这种方法使得字典的大小不在依赖与mini-batch的大小,这就使得字典可以更大。
Method
Pretext Task(预训练任务)
-
为了更好的理解这篇论文的方法,我们先介绍一下论文所使用的预训练任务;
-
MoCo模型适用许多的预训练任务(pretext tasks),但论文中使用实例消歧任务(instance discrimination task) 来进行实验:预测一个query和一个key是否是来自同一张图片的不同视角(view)
-
了解的任务我们就可以看一下模型整体架构图:
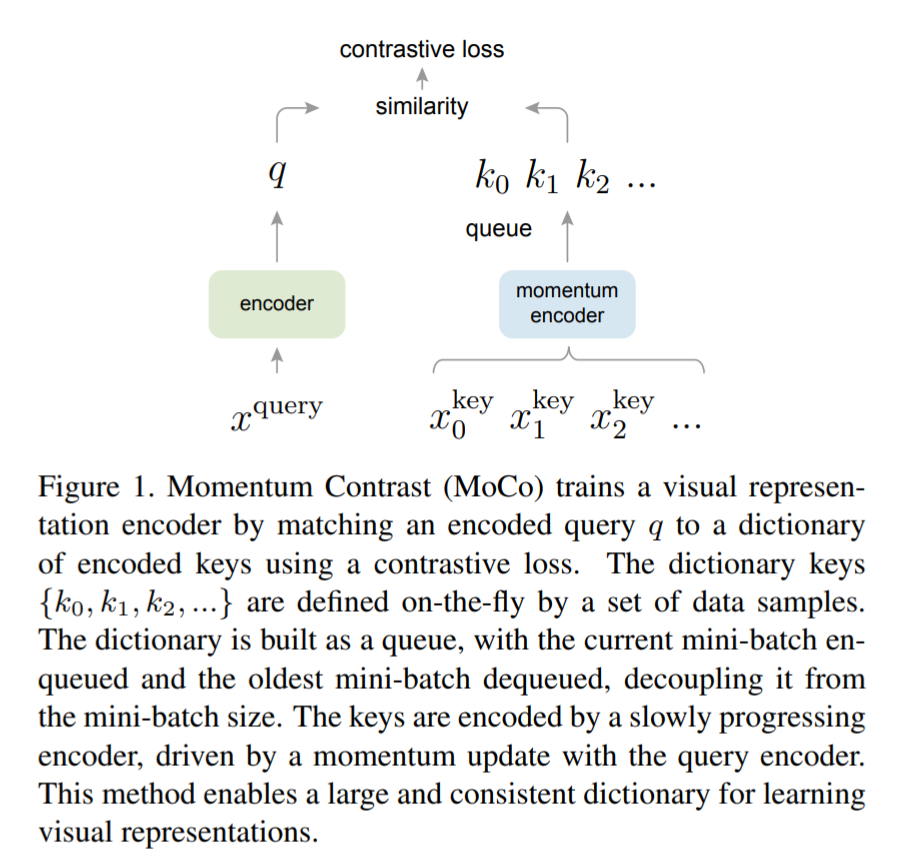
-
顺着这张图可以直观的介绍一下论文使用的对比损失函数(contrastive loss):
其中 T T T是温度, k + k_+ k+表示唯一的正例。分子的求和是 K K K个负例和一个正例。很明显的可以看到这实质上就是一个交叉熵损失函数。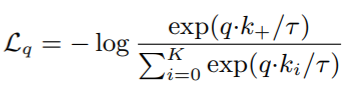
-
这里我们也可以对比NLP的语言模型,把 q q q理解为前一个词,而 K + 1 K+1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 558
558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









