







ELMo模型计算详解
写在前面
本文记录本人在学习ELMo模型时的记录,具体为解析了在Google的开源实现中给出的源码中,论文中各个模块的输入输出维度变化。希望可以对读者学习ELMo模型时有些帮助。
另外,本章图片内容参考了b站up主自然卷小蛮的视频,在此声明(https://www.bilibili.com/video/BV12L411T7Vh)
ELMo(Embeddings from Language Models)是一个深度学习框架,用于生成上下文感知的词嵌入。这个模型由Allen Institute for Artificial Intelligence的研究人员在2018年开发,并在论文“Deep contextualized word representations”中提出。ELMo的出现标志着自然语言处理(NLP)技术在理解语言上下文和词义的深度方面迈出了重要的一步。
在ELMo之前,词向量技术如Word2Vec和GloVe已经能够捕获一定的语义信息,并在各种NLP任务中取得了显著的成功。然而,这些模型生成的是静态的词嵌入,即每个词在任何上下文中的表示都是固定不变的。这种静态表示无法解决词义消歧问题,也无法充分捕捉语言的复杂性和动态性。ELMo模型的出现旨在解决这一问题。
模型方法
ELMo 模型的网络的整体结构如下图所示。 输入是一个句子,将句子输入到 Character-aware highway encoder 字符编码层,然后经过两层双向 LSTM ,最后通过 softmax 层,然后得到预测的单词结果或者进行损失计算。
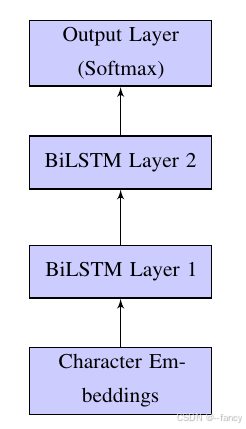
ELMo模型输入
ELMo模型的输入是一个句子,例如"She opened her book."。由于在Character-aware highway encoder中我们会详细处理单词并提取其特征,所以这里我们将句子作为ELMo模型的输入传入到Character-aware highway encoder层中。
Character-aware highway encoder
character-CNN
我们首先来看 Character-aware highway encoder 层,总体结构如图下所示。
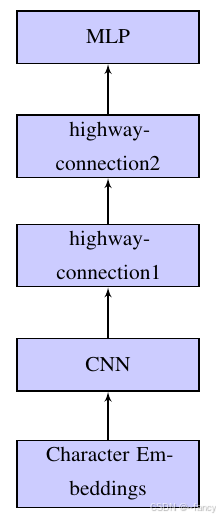
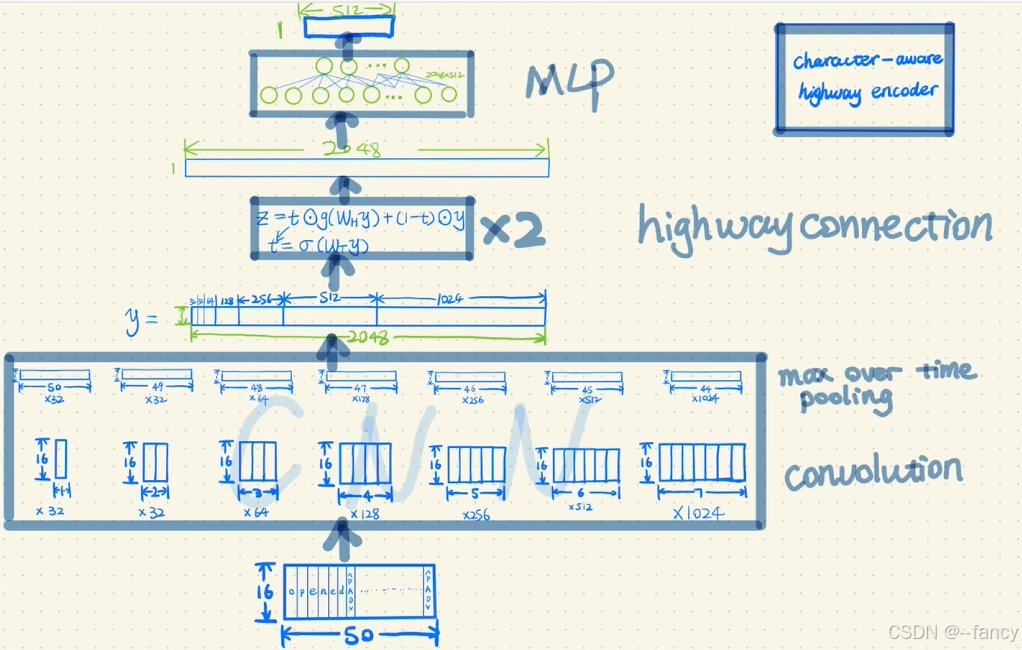
Character-CNN层的输入是单个单词的字符序列。我们会对每个单词进行处理得到固定维度的向量,然后使用CNN卷积进行特征提取。下面进行依次介绍。char-CNN展开后的模型细节如图所示。
首先,每个字符通过字符嵌入(character embeddings)被转换为固定维度的向量。设字符总数为
n
n
n,字符嵌入的维度为
d
d
d,单词最多由
L
L
L个字符组成,句子最多有
k
k
k个单词,则输入的每个单词将会转化成矩阵
V
c
h
a
r
n
e
w
∈
R
L
×
d
V_{char}^{new} \in \mathbb{R}^{L \times d}
Vcharnew∈RL×d。具体来说,将每个字符用one-hot的方式进行表示,每个字符就是
n
×
1
n \times 1
n×1维的向量,我们通过线性变换,将每个字符的维度从
n
n
n压缩为
d
d
d,然后限定单词的最大字符数,即可把每个单词的维度固定为
d
×
L
d \times L
d×L,即
V
c
h
a
r
n
e
w
=
V
c
h
a
r
o
n
e
−
h
o
t
W
c
+
b
c
V_{char}^{new} = V_{char}^{one-hot} W_c + b_c
Vcharnew=Vcharone−hotWc+bc
其中
W
c
∈
R
n
×
d
W_c \in \mathbb{R}^{n \times d}
Wc∈Rn×d 是对应的权重矩阵,
b
c
∈
R
d
×
1
b_c \in \mathbb{R}^{d \times 1}
bc∈Rd×1 为权重矩阵
W
c
W_c
Wc对应的置偏值,
V
c
h
a
r
o
n
e
−
h
o
t
∈
R
d
×
n
V_{char}^{one-hot} \in \mathbb{R}^{d \times n}
Vcharone−hot∈Rd×n为字符的one-hot向量,
V
c
h
a
r
n
e
w
V_{char}^{new}
Vcharnew为
V
c
h
a
r
o
n
e
−
h
o
t
V_{char}^{one-hot}
Vcharone−hot从维度
n
×
1
n \times 1
n×1 映射为维度
d
×
1
d \times 1
d×1后的字符的向量,通常
n
>
d
n > d
n>d。
这种字符嵌入的方式与Word2Vec中的两种词嵌入方式不同,Word2Vec中的两种方法都是把 单词 转换为one-hot向量,而在ELMo的输入中,将 字符 转换为one-hot向量,使用矩阵表示单词,这样可以从字符层面挖掘单词的特征。
通过上面的字符嵌入,我们就可以用字符的向量来构建单词的向量。在ELMo中,规定一个单词的最大字符个数不超过
L
L
L,超过
L
L
L时会进行截断,不足
L
L
L时会使用特殊字符的字符编码进行末尾填充。这样我们可以用
V
w
o
r
d
∈
R
d
×
L
V_{word} \in \mathbb{R}^{d \times L}
Vword∈Rd×L表示一个单词,即
V
w
o
r
d
=
V
t
=
[
V
c
h
a
r
1
n
e
w
,
V
c
h
a
r
2
n
e
w
,
…
,
V
c
h
a
r
L
n
e
w
]
=
[
V
c
h
a
r
1
o
n
e
−
h
o
t
,
V
c
h
a
r
2
o
n
e
−
h
o
t
,
…
,
V
c
h
a
r
L
o
n
e
−
h
o
t
]
W
c
+
b
c
V_{word} = V_{t} = [V_{char1}^{new},V_{char2}^{new},\dots, V_{charL}^{new}] = [V_{char1}^{one-hot},V_{char2}^{one-hot}, \dots, V_{charL}^{one-hot}]W_c + b_c
Vword=Vt=[Vchar1new,Vchar2new,…,VcharLnew]=[Vchar1one−hot,Vchar2one−hot,…,VcharLone−hot]Wc+bc
V
w
o
r
d
=
[
v
1
,
1
w
o
r
d
v
1
,
2
w
o
r
d
…
v
1
,
L
w
o
r
d
v
2
,
1
w
o
r
d
v
2
,
2
w
o
r
d
…
v
2
,
L
w
o
r
d
…
…
…
…
v
d
,
1
w
o
r
d
v
d
,
2
w
o
r
d
…
v
d
,
L
w
o
r
d
]
V_{word} = \left[\begin{matrix} v_{1,1}^{word} & v_{1,2}^{word} & \dots & v_{1,L}^{word} \\ v_{2,1}^{word} & v_{2,2}^{word} & \dots & v_{2,L}^{word} \\ \dots & \dots & \dots & \dots \\ v_{d,1}^{word} & v_{d,2}^{word} & \dots & v_{d,L}^{word} \\ \end{matrix}\right]
Vword=
v1,1wordv2,1word…vd,1wordv1,2wordv2,2word…vd,2word…………v1,Lwordv2,Lword…vd,Lword
其中,
V
c
h
a
r
i
n
e
w
V_{chari}^{new}
Vcharinew是单词中第
i
i
i个字符的嵌入向量。这样我们就完成了character-embedding的过程。
V
w
o
r
d
=
V
t
V_{word} = V_{t}
Vword=Vt 表示当前输入的第
t
t
t个单词的单词矩阵。
下面介绍AllenNLP中实现的ELMo,character-embedding处理的方式。
在AllenNLP的ELMo的character-embedding中,利用Unicode 字符级对单词的每个字符进行编码。在Unicode 字符集中 0 − 255 0-255 0−255共有 256 256 256个字符,加上(单词的开始)、(单词的结束)、 (句子的开始)、(句子的结束)、(单词补齐符)和(句子补齐符)这 6 6 6个特殊字符,一共有 262 262 262个字符,构成了字符集表示中的字符表,即 n = 262 n = 262 n=262。ELMo的思想是给每个字符生成一个固定维度地随机向量,在AllenNLP的ELMo的character-embedding实现中,这 262 262 262 个字符向量会被固定为维度为 16 × 1 16 \times 1 16×1(字符嵌入维度为 16 16 16, d = 16 d = 16 d=16)的向量,采用的方法是将 262 262 262 个字符以one-hot向量的形式进行表示,随后通过线性变换的形式转为换固定维度为 16 × 1 16 \times 1 16×1的向量。
在AllenNLP的ELMo实现中, L = 50 L = 50 L=50、 n = 262 n = 262 n=262、 d = 16 d = 16 d=16,我们以单词 opened 为例子,首先将其分解成 ‘o’,‘p’,‘e’,‘n’,‘e’,‘d’,共 6 6 6个字符,分别使用相应的字符向量表示,由于单词向量使用 50 50 50个字符向量固定,后面 44 44 44个 字符均使用填充,这样我们就将其固定成字符数量大小为 50 50 50 。于是我们就可以完成 opened 这个单词的编码。此时单词的维度$ 16 \times 50$。这里由于AllenNLP中的嵌入维度较大不方便展示,简单的嵌入例子参考章节ELMo-demo简单的ELMo例子中的字符嵌入过程。
CNN
对于一个句子经过 character-embedding 之后,就会进入 CNN 层,CNN 的核心是使用卷积神经网络。我们考虑一个单词,其字符表示为
v
w
o
r
d
v_{word}
vword,
v
w
o
r
d
v_{word}
vword是一个
d
×
L
d \times L
d×L的矩阵
d
d
d是每个字符的嵌入维度,
L
L
L是单词的最大长度,则我们可以定义卷积操作:
对于给定卷积核
K
K
K,
K
=
[
K
1
,
K
2
,
…
,
K
f
]
,
K
j
=
[
k
1
,
1
,
j
k
1
,
2
,
j
…
k
1
,
w
,
j
k
2
,
1
,
j
k
2
,
2
,
j
…
k
2
,
w
,
j
…
…
…
…
k
d
,
1
,
j
k
d
,
2
,
j
…
k
d
,
w
,
j
]
K = [K_1, K_2, \dots, K_f] , \quad K_j = \left[\begin{matrix} k_{1,1,j} & k_{1,2,j} & \dots & k_{1,w,j} \\ k_{2,1,j} & k_{2,2,j} & \dots & k_{2,w,j} \\ \dots & \dots & \dots & \dots \\ k_{d,1,j} & k_{d,2,j} & \dots & k_{d,w,j} \end{matrix}\right]
K=[K1,K2,…,Kf],Kj=
k1,1,jk2,1,j…kd,1,jk1,2,jk2,2,j…kd,2,j…………k1,w,jk2,w,j…kd,w,j
其尺寸为
d
×
w
×
f
d\times w \times f
d×w×f,其中:
- K K K表示卷积核矩阵集合(张量), K j K_j Kj表示卷积核矩阵, k d , w , j k_{d,w,j} kd,w,j表示卷积核矩阵中各个位置的元素值。
- d d d是卷积核覆盖的字符嵌入维度(与输入维度相匹配),
- w w w是卷积核的宽度(覆盖的字符数) ,
- f f f是该卷积核输出的特征数量(或称为过滤器数量)。
- j = 1 , 2 , … , f j = 1, 2, \dots, f j=1,2,…,f。
卷积操作的输出
c
c
c对于每个特征图
j
j
j的每个位置
i
i
i在单词长度方向上可以表示为:
c
i
,
j
=
∑
m
=
1
d
∑
n
=
1
w
v
m
,
n
w
o
r
d
k
m
,
n
,
j
+
b
c
n
n
j
c_{i, j} = \sum_{m = 1}^{d} \sum_{n = 1}^{w} v^{word}_{m,n} k_{m,n,j} + b_{cnn}^{j}
ci,j=m=1∑dn=1∑wvm,nwordkm,n,j+bcnnj
这里,
b
C
N
N
j
∈
R
b_{CNN}^{j} \in \textbf{R}
bCNNj∈R是与过滤器
K
j
K_j
Kj关联的偏置项。输出的维度
c
c
c为
(
L
−
w
+
1
)
×
f
(L - w + 1) \times f
(L−w+1)×f,假设没有填充(padding)和步长(stride)为
1
1
1。
在卷积后进行最大池化操作,最大池化在每个特征图上独立进行,选取每个特征图中的最大值。对于每个过滤器
K
j
K_j
Kj,池化操作可表示为
c
^
j
=
max
(
c
1
,
j
,
c
2
,
j
,
…
,
c
L
−
w
+
1
,
j
)
,
(
j
=
1
,
2
,
…
,
f
)
\hat{c}_j = \max(c_{1,j}, c_{2,j}, \dots, c_{L- w + 1, j}), \quad (j = 1, 2, \dots, f)
c^j=max(c1,j,c2,j,…,cL−w+1,j),(j=1,2,…,f)
最终,池化后的所有特征
c
^
j
\hat{c}_j
c^j被拼接起来形成一个特征向量
y
y
y,用作单词的嵌入表示:
y
t
=
(
c
^
1
,
c
^
2
,
…
,
c
^
F
)
y_t = (\hat{c}_1, \hat{c}_2, \dots, \hat{c}_F)
yt=(c^1,c^2,…,c^F)
其中
F
F
F是过滤器的总数量(每个卷积核的过滤器相加求和得到总的过滤器数量),则
Y
=
[
y
1
,
y
2
,
…
,
y
t
,
…
,
y
n
]
Y = [y_1, y_2, \dots, y_t, \dots, y_n]
Y=[y1,y2,…,yt,…,yn]为
F
×
n
F \times n
F×n维向量。随后,我们将一个个的单词向量
y
t
y_t
yt传入 highway-connection层。
在AllenNLP的ELMo的character-CNN中,包含了 7 种过滤器,分别是 16 × \times × 1 × \times × 32、16 × \times × 2 × \times × 32、16 × \times × 3 × \times × 64、16 × \times × 4 × \times × 128、16 × \times × 5 × \times × 256、16 × \times × 6 × \times × 512、16 × \times × 7 × \times × 1024。过滤器尺寸依次为32、32、64、128、256、512、1024。
通过卷积层后通过池化层,顺着 1 1 1 这一维度进行取最大(MaxPool)也就是将 16 行(在图中就是纵向压缩)通过取最大压缩成 1 1 1 行,也就是将 16 × 50 16 \times 50 16×50 通过池化(取最大)变成 1 × 50 1 \times 50 1×50。我们将得到一个个的 vector 顺着 1 1 1 这一维度进行拼接,可以得到一个 1 × 2048 1 \times 2048 1×2048 的 vector。
highway-connection
接下来是两层的 highway-connection,Highway 网络层的输出是经过门控调节的特征表示,这些表示为后续层(如双向LSTM层)提供了更加精细调整的输入,对于每个时间步的输入是 y t y_t yt。输出的特点包括:
- 保留与变换:Highway层通过两个主要的门控机制实现信息的保留与变换——一个是变换门(T门),另一个是携带门(C门)。变换门控制有多少当前层的原始信息需要被变换,而携带门控制有多少原始信息需要不加修改地传递到下一层。
- 门控特征表示:因此,Highway层的输出是原始输入特征的一个门控版本,其中一部分特征被保留并直接传递,而另一部分特征经过变换以提供额外的信息或调整。
变换门:
T
=
σ
(
W
T
y
t
+
b
T
)
T = \sigma(W_Ty_t + b_T)
T=σ(WTyt+bT)
其中 σ \sigma σ 是sigmoid激活函数,确保输出在0和1之间,表示每个特征的转换程度。 y t ∈ R p × 1 y_t \in \mathbb{R}^{p \times 1} yt∈Rp×1 是输入特征, W T ∈ R p × p W_T \in \mathbb{R}^{p \times p} WT∈Rp×p和 b T ∈ R p × 1 b_T \in \mathbb{R}^{p \times 1} bT∈Rp×1 是变换门的权重和偏置, T ∈ R p × 1 T \in \mathbb{R}^{p \times 1} T∈Rp×1。
携带门:
C
=
1
−
T
C = 1 - T
C=1−T
携带门的计算很简单,就是1减去变换门的输出,确保变换和携带的总和为1,这样可以保持信息的完整性,
C
∈
R
p
×
1
C \in \mathbb{R}^{p \times 1}
C∈Rp×1。
输出:
z
t
=
T
⊙
g
(
W
H
y
t
+
b
H
)
+
C
⊙
y
t
z_t = T \odot g(W_Hy_t + b_H) + C \odot y_t
zt=T⊙g(WHyt+bH)+C⊙yt
其中,
y
t
∈
R
p
×
1
y_t \in \mathbb{R}^{p \times 1}
yt∈Rp×1 是输入特征,
W
H
∈
R
p
×
p
W_H \in \mathbb{R}^{p \times p}
WH∈Rp×p是变换操作的权重,
b
H
∈
R
p
×
1
b_H \in \mathbb{R}^{p \times 1}
bH∈Rp×1为对应的置偏值,
g
(
W
H
y
t
+
b
H
)
g(W_Hy_t + b_H)
g(WHyt+bH)
是对输入
y
t
y_t
yt 的非线性变换(通常是ReLU激活函数),
T
T
T是变换门的激活,
C
C
C是携带门的激活,而
z
t
∈
R
p
×
1
z_t \in \mathbb{R}^{p \times 1}
zt∈Rp×1 是该 Highway 层的输出,
⊙
\odot
⊙ 是点乘。
通过这样的设计,Highway 层使得网络能够自适应地调节信息的流动,既能保留对后续处理有用的重要信息,也能对输入特征进行必要的变换,这对于深层次的语义理解尤为重要。
在AllenNLP的ELMo中,进行运算完highway-connection后我们得到结果还是 1 × 2048 1 \times 2048 1×2048 的 vector。最后的 MLP 层就是一层线性映射,将维度为 2048 2048 2048 的 vector 压缩成 512 512 512 维的 vector。
MLP
MLP在此处就是对highway-connection得到的特征进行压缩,然后输入给双向LSTM,具体来说就是一个简单的线性映射,即
u
t
=
W
c
h
a
r
−
c
n
n
−
m
l
p
z
t
+
b
c
h
a
r
−
c
n
n
−
m
l
p
u_t = W_{char-cnn-mlp}z_t + b_{char-cnn-mlp}
ut=Wchar−cnn−mlpzt+bchar−cnn−mlp
其中,
z
t
∈
R
p
×
1
z_t \in \mathbb{R}^{p \times 1}
zt∈Rp×1是输入特征。假设需要映射到的维度大小是
m
m
m,则
u
t
∈
R
m
×
1
u_t \in \mathbb{R}^{m \times 1}
ut∈Rm×1,
W
c
h
a
r
−
c
n
n
−
m
l
p
∈
R
m
×
p
W_{char-cnn-mlp} \in \mathbb{R}^{m \times p}
Wchar−cnn−mlp∈Rm×p和
b
c
h
a
r
−
c
n
n
−
m
l
p
∈
R
m
×
1
b_{char-cnn-mlp} \in \mathbb{R}^{m \times 1}
bchar−cnn−mlp∈Rm×1是该全连接层的权重矩阵和置偏。
在AllenNLP的ELMo的此处的MLP中,使用 MLP 对 1 × \times × 2048 的 vector 进行处理,得到 1 × \times × 2048 的 vector 作为输入进入双向 LSTM 层。
bidrectional LSTM
接下来就是 ELMo 的核心,两层双向 LSTM。双层双向LSTM得输入是上层输出的单词向量得集合,即
U
=
(
u
1
,
u
2
,
…
,
u
n
)
U = (u_1, u_2, \dots, u_n)
U=(u1,u2,…,un)
其中
u
t
∈
R
m
×
1
u_t \in \mathbb{R}^{m \times 1}
ut∈Rm×1 表示当前单词的向量表示(或者当前时刻单词的向量表示),
n
n
n表示一共有多少个单词(有多少个时刻),且
U
∈
R
m
×
n
U \in \mathbb{R}^{m \times n}
U∈Rm×n。
双向LSTM结构包括前向和后向两个LSTM网络,能够捕获上下文信息。我们从LSTM再到双向LSTM对其进行描述,具体如下一小结。
LSTM
我们先简单回忆LSTM的结构与计算方法。LSTM的模型结构如图\ref{ELMo-LSTM}所示。
u
t
u_t
ut 是时间步
t
t
t 的输入,维度为
m
×
1
m \times 1
m×1 ,
h
t
h_t
ht表示当前时刻隐藏层输入,
c
t
c_t
ct表示当前时刻当前状态单元
W
f
W_f
Wf,
b
f
b_f
bf,
W
i
W_i
Wi,
b
i
b_i
bi,
W
C
W_C
WC,
b
C
b_C
bC,
W
o
W_o
Wo,
b
o
b_o
bo分别为LSTM层各个门和模块的权重矩阵和置偏,
h
0
h_0
h0、
c
0
c_0
c0通常初始化为
0
0
0向量,权重矩阵和置偏通常随机初始化。
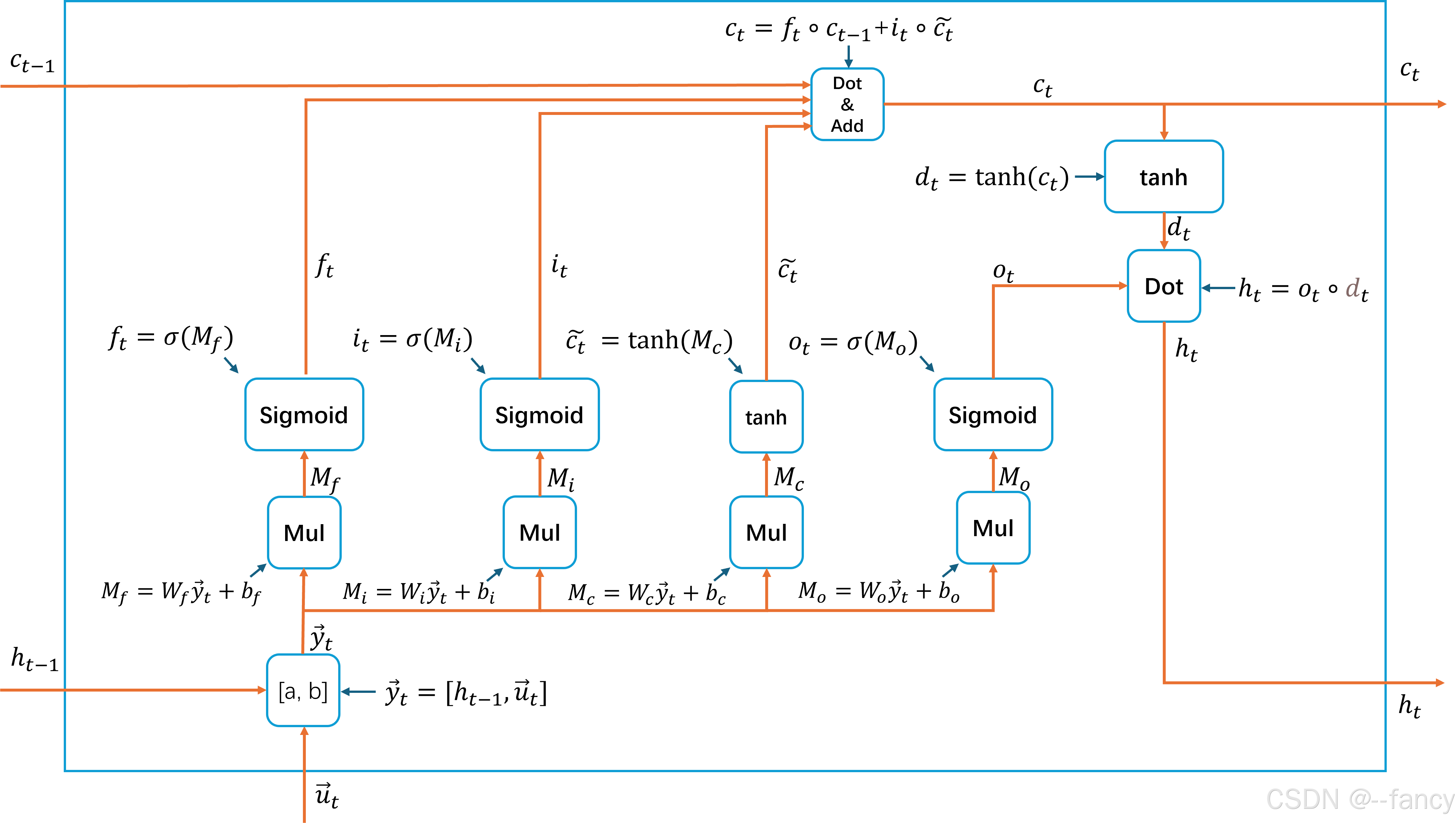
遗忘门(Forget Gate)
遗忘门的计算公式为
f
t
=
σ
(
W
f
⋅
[
h
t
−
1
,
u
t
]
+
b
f
)
f_t = \sigma(W_f \cdot [h_{t-1}, u_t] + b_f)
ft=σ(Wf⋅[ht−1,ut]+bf)
其中,
W
f
W_f
Wf 是权重矩阵,维度为
h
×
(
h
+
m
)
h \times (h + m)
h×(h+m),
b
f
b_f
bf 是偏置,维度为
h
×
1
h \times 1
h×1,
h
h
h是隐藏层维度,
σ
\sigma
σ 是sigmoid函数。
输入门(Input Gate)
输入门的计算公式为
i
t
=
σ
(
W
i
⋅
[
h
t
−
1
,
u
t
]
+
b
i
)
i_t = \sigma(W_i \cdot [h_{t-1}, u_t] + b_i)
it=σ(Wi⋅[ht−1,ut]+bi)
c
~
t
=
tanh
(
W
C
⋅
[
h
t
−
1
,
u
t
]
+
b
C
)
\tilde{c}_t = \tanh(W_C \cdot [h_{t-1}, u_t] + b_C)
c~t=tanh(WC⋅[ht−1,ut]+bC)
W
i
W_i
Wi 和
W
C
W_C
WC 是权重矩阵,维度为
h
×
(
h
+
m
)
h \times (h + m)
h×(h+m),
b
i
b_i
bi 和
b
C
b_C
bC 是偏置,维度为
h
×
1
h \times 1
h×1。
单元状态更新
单元状态更新计算公式为
c
t
=
f
t
⊙
c
t
−
1
+
i
t
⊙
c
~
t
c_t = f_t \odot c_{t-1} + i_t \odot \tilde{c}_t
ct=ft⊙ct−1+it⊙c~t
c
t
c_t
ct 和
c
t
−
1
c_{t-1}
ct−1 的维度为
h
×
1
h \times 1
h×1。
输出门(Output Gate)
输出门的计算公式为
o
t
=
σ
(
W
o
⋅
[
h
t
−
1
,
u
t
]
+
b
o
)
o_t = \sigma(W_o \cdot [h_{t-1}, u_t] + b_o)
ot=σ(Wo⋅[ht−1,ut]+bo)
h
t
=
o
t
⊙
tanh
(
c
t
)
h_t = o_t \odot \tanh(c_t)
ht=ot⊙tanh(ct)
W
o
W_o
Wo 是权重矩阵,维度为
h
×
(
h
+
m
)
h \times (h + m)
h×(h+m),
b
o
b_o
bo 是偏置,维度为
h
×
1
h \times 1
h×1。
以上就是LSTM模块的计算,理解了单个LSTM的计算我们就可以进一步计算双向LSTM和双层双向LSTM。为了方便表示,我们将计算过程封装为
h
t
=
LSTM
(
u
t
,
h
t
−
1
)
h_t = \text{LSTM}(u_t, h_{t - 1})
ht=LSTM(ut,ht−1)
双向结构
双向LSTM的模型结构如图下所示,在ELMo模型的bidLSTM中的LSTM模块的输入 u t u_t ut 是时间步 t t t 的字符嵌入或词嵌入,维度为 m × 1 m \times 1 m×1 , h → t \overrightarrow{h}_t ht表示当前时刻正向LSTM隐藏层输入, h ← t \overleftarrow{h}_t ht 表示当前时刻反向LSTM隐藏层输入,其维度为 m × 1 m \times 1 m×1,通常正向的隐藏层 h → 0 \overrightarrow{h}_0 h0和反向的隐藏层 h ← t \overleftarrow{h}_t ht均随机初始化或者初始化为值全为 0 0 0的向量或者值全为 1 1 1的向量。 u t u_t ut通过与 h → t − 1 \overrightarrow{h}_{t-1} ht−1拼起来构成LSTM的输入,传入正向的LSTM,进行LSTM中的步骤计算,输出 h → t \overrightarrow{h}_{t} ht传入后一个LSTM模块,不断迭代,将每个时间步的隐藏层输出 h → t \overrightarrow{h}_{t} ht序列作为该正向LSTM模块的输出。同理, u t u_t ut通过与 h ← t + 1 \overleftarrow{h}_{t+1} ht+1拼起来构成LSTM的输入,传入正向的LSTM,进行LSTM中的步骤计算,输出 h ← t \overleftarrow{h}_{t} ht传入前一个LSTM模块,不断迭代,将每个时间步的隐藏层输出 h ← t \overleftarrow{h}_{t} ht序列作为该反向LSTM模块的输出。
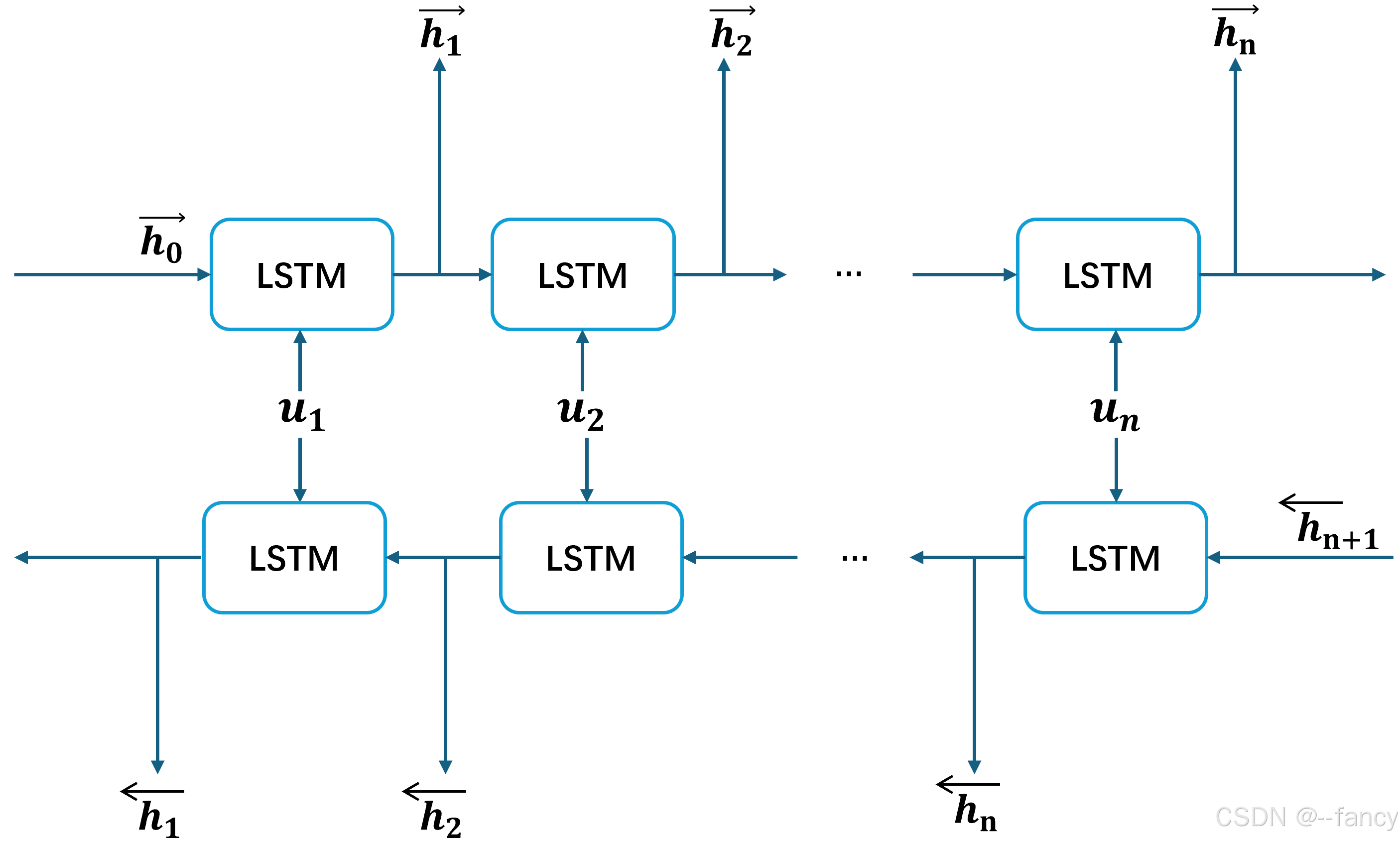
对于每一个
u
t
u_t
ut,正向LSTM计算表示为
h
→
t
=
LSTM
+
(
h
→
t
−
1
,
u
t
)
\overrightarrow{h}_{t} = \text{LSTM}_{+}(\overrightarrow{h}_{t-1}, u_t)
ht=LSTM+(ht−1,ut)
其中
h
t
→
\overrightarrow{h_t}
ht、
h
t
−
1
→
∈
R
m
×
1
\overrightarrow{h_{t-1}} \in \mathbb{R}^{m \times 1}
ht−1∈Rm×1,
LSTM
+
\text{LSTM}_{+}
LSTM+表示正向的LSTM运算。
对于每一个
u
t
u_t
ut,反向LSTM计算表示为
h
←
t
=
LSTM
−
(
h
←
t
+
1
,
u
t
)
\overleftarrow{h}_{t} = \text{LSTM}_{-}(\overleftarrow{h}_{t+1}, u_t)
ht=LSTM−(ht+1,ut)
其中
h
t
←
\overleftarrow{h_t}
ht、
h
t
−
1
←
∈
R
m
×
1
\overleftarrow{h_{t-1}} \in \mathbb{R}^{m \times 1}
ht−1∈Rm×1,
LSTM
−
\text{LSTM}_{-}
LSTM−表示正向的LSTM运算。
于是有
- 前向LSTM从左到右处理输入序列,生成隐藏状态序列 h → 1 , h → 2 , … , h → n \overrightarrow{h}_1, \overrightarrow{h}_2, \dots, \overrightarrow{h}_n h1,h2,…,hn.
- 后向LSTM从右到左处理输入序列,生成隐藏状态序列 h ← 1 , h ← 2 , … , h ← n \overleftarrow{h}_1, \overleftarrow{h}_2, \dots, \overleftarrow{h}_n h1,h2,…,hn.
我们将结果记为
H
→
=
[
h
→
1
,
h
→
2
,
…
,
h
→
n
]
\overrightarrow{H} = [\overrightarrow{h}_1, \overrightarrow{h}_2, \dots, \overrightarrow{h}_n]
H=[h1,h2,…,hn]
H
←
=
[
h
←
1
,
h
←
2
,
…
,
h
←
n
]
\overleftarrow{H} = [\overleftarrow{h}_1, \overleftarrow{h}_2, \dots, \overleftarrow{h}_n]
H=[h1,h2,…,hn]
其中
h
←
t
\overleftarrow{h}_t
ht、
h
→
t
∈
R
m
×
1
\overrightarrow{h}_t\in \mathbb{R}^{m \times 1}
ht∈Rm×1,
H
←
\overleftarrow{H}
H、
H
→
∈
R
m
×
n
\overrightarrow{H} \in \mathbb{R}^{m \times n}
H∈Rm×n
双层双向LSTM
在ELMo中并不是简单地设置一层双向LSTM,而是使用两层。具体计算方式是将第一层双向LSTM中得到的正向LSTM的隐藏层向量传入第二层正向的LSTM,将第一层的双向LSTM中的得到的反向LSTM的隐藏层向量传入第二层反向的LSTM。ELMo中的双层双向LSTM如图\ref{ELMo-double-ward-Bid-LSTM}所示。
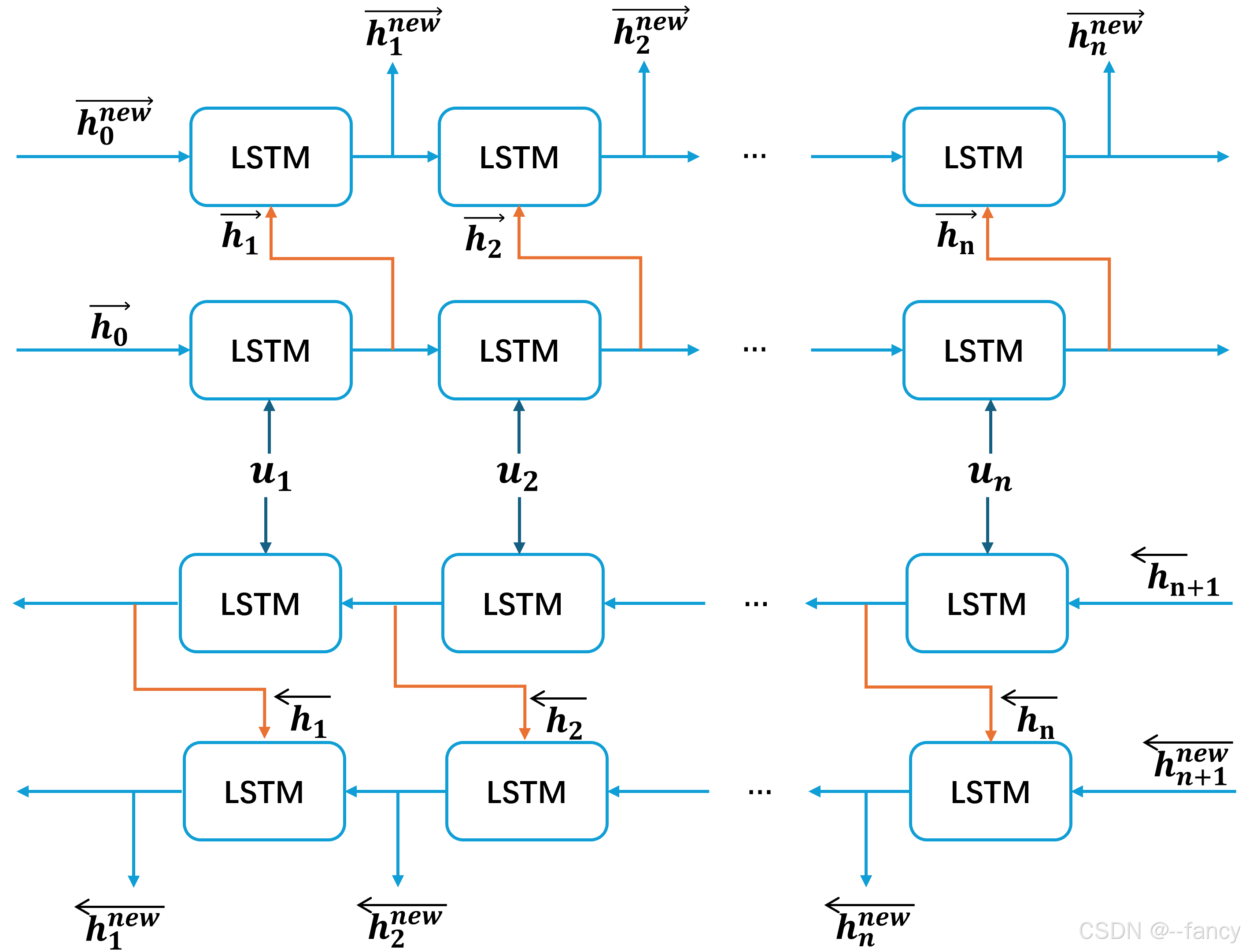
与上面计算第一层的双向LSTM类似,我们用公式进行描述对于每一个
h
→
t
\overrightarrow{h}_{t}
ht,正向LSTM计算表示为
h
→
t
n
e
w
=
LSTM
+
(
h
→
t
−
1
n
e
w
,
h
→
t
)
\overrightarrow{h}_{t}^{new} = \text{LSTM}_{+}(\overrightarrow{h}_{t-1}^{new},\overrightarrow{h}_{t})
htnew=LSTM+(ht−1new,ht)
其中
h
t
→
n
e
w
\overrightarrow{h_t}^{new}
htnew、
h
t
−
1
n
e
w
→
∈
R
m
×
1
\overrightarrow{h_{t-1}^{new}} \in \mathbb{R}^{m \times 1}
ht−1new∈Rm×1,
LSTM
+
\text{LSTM}_{+}
LSTM+表示正向的LSTM运算。
对于每一个
h
←
t
\overleftarrow{h}_{t}
ht,反向LSTM计算表示为
h
←
t
n
e
w
=
LSTM
−
(
h
←
t
+
1
n
e
w
,
h
←
t
)
\overleftarrow{h}_{t}^{new} = \text{LSTM}_{-}(\overleftarrow{h}_{t+1}^{new}, \overleftarrow{h}_{t})
htnew=LSTM−(ht+1new,ht)
其中
h
t
←
n
e
w
\overleftarrow{h_t}^{new}
htnew、
h
t
←
n
e
w
∈
R
m
×
1
\overleftarrow{h_t}^{new} \in \mathbb{R}^{m \times 1}
htnew∈Rm×1,
LSTM
−
\text{LSTM}_{-}
LSTM−表示正向的LSTM运算。
于是有
- 前向LSTM从左到右处理输入序列将上面生成的第一层隐藏状态传递给下一层,生成隐藏状态序列 h → 1 n e w , h → 2 n e w , … , h → n n e w \overrightarrow{h}_1^{new}, \overrightarrow{h}_2^{new}, \dots, \overrightarrow{h}_n^{new} h1new,h2new,…,hnnew.
- 后向LSTM从右到左处理输入序列将上面生成的第一层隐藏状态传递给下一层,生成隐藏状态序列 h ← 1 n e w , h ← 2 n e w , … , h ← n n e w \overleftarrow{h}_1^{new}, \overleftarrow{h}_2^{new}, \dots, \overleftarrow{h}_n^{new} h1new,h2new,…,hnnew.
我们将结果记为
H
→
n
e
w
=
[
h
→
1
n
e
w
,
h
→
2
n
e
w
,
…
,
h
→
n
n
e
w
]
\overrightarrow{H}^{new} = [\overrightarrow{h}_{1}^{new}, \overrightarrow{h}_{2}^{new}, \dots, \overrightarrow{h}_{n}^{new}]
Hnew=[h1new,h2new,…,hnnew]
H
←
n
e
w
=
[
h
←
1
n
e
w
,
h
←
2
n
e
w
,
…
,
h
←
n
n
e
w
]
\overleftarrow{H}^{new} = [\overleftarrow{h}_{1}^{new}, \overleftarrow{h}_{2}^{new}, \dots, \overleftarrow{h}_{n}^{new}]
Hnew=[h1new,h2new,…,hnnew]
其中
h
←
t
n
e
w
\overleftarrow{h}_{t}^{new}
htnew、
h
→
t
n
e
w
∈
R
m
×
1
\overrightarrow{h}_{t}^{new}\in \mathbb{R}^{m \times 1}
htnew∈Rm×1,
H
←
n
e
w
\overleftarrow{H}^{new}
Hnew、
H
→
n
e
w
∈
R
m
×
n
\overrightarrow{H}^{new} \in \mathbb{R}^{m \times n}
Hnew∈Rm×n
bid-LSTM输出
在通常情况下,最终输出
S
=
[
s
1
⃗
,
s
2
⃗
,
…
,
s
2
m
⃗
]
S = [\vec{s_1}, \vec{s_2}, \dots, \vec{s_{2m}}]
S=[s1,s2,…,s2m] 是对前面的双层双向LSTM进行了如下操作:
对于每个时间步,将两层得到的正向LSTM的隐藏层输出与反向LSTM的隐藏层输出相加,即
h
→
t
+
h
→
t
n
e
w
,
h
←
t
+
h
←
t
n
e
w
\overrightarrow{h}_t + \overrightarrow{h}_t^{new}, \quad \overleftarrow{h}_t + \overleftarrow{h}_t^{new}
ht+htnew,ht+htnew
然后再将得到的结果拼成一个更长的向量得到结果,即
s
t
⃗
=
[
h
→
t
+
h
→
t
n
e
w
;
h
←
t
+
h
←
t
n
e
w
]
\vec{s_t} = [\overrightarrow{h}_t + \overrightarrow{h}_t^{new}; \overleftarrow{h}_t + \overleftarrow{h}_t^{new}]
st=[ht+htnew;ht+htnew]
如果每个方向的隐藏状态维度为
m
m
m,则
s
t
⃗
\vec{s_t}
st 的维度为
2
m
×
1
2m \times 1
2m×1。
于是我们得到
S
=
[
s
1
⃗
,
s
2
⃗
,
…
,
s
2
m
⃗
]
S = [\vec{s_1}, \vec{s_2}, \dots, \vec{s_{2m}}]
S=[s1,s2,…,s2m]
其中
s
t
⃗
∈
R
2
m
×
1
\vec{s_t} \in \mathbb{R}^{2m \times 1}
st∈R2m×1,
S
∈
R
2
m
×
n
S \in \mathbb{R}^{2m \times n}
S∈R2m×n
MLP and Softmax
为了得到对应的单词,我们通过一层线性映射,将单词向量表示转换为高维的表示,然后通过Softmax得到每个时刻
t
t
t单词的概率分布,从而得到要预测的单词。即对于每一个时间步
q
t
⃗
=
W
s
s
t
⃗
+
b
s
\vec{q_t} = W_s \vec{s_t} + b_s
qt=Wsst+bs
其中,
q
t
⃗
∈
R
V
×
1
\vec{q_t} \in \mathbb{R}^{V \times 1}
qt∈RV×1为映射后的向量、
W
s
∈
R
V
×
2
h
W_s \in \mathbb{R}^{V \times 2h}
Ws∈RV×2h为映射的权重矩阵、
b
s
∈
R
V
×
1
b_s \in \mathbb{R}^{V \times 1}
bs∈RV×1为对应的置偏,
V
V
V为单词表的维度。
写成矩阵的形式为
Q
=
W
s
S
+
b
s
Q = W_s S + b_s
Q=WsS+bs
其中,
Q
=
[
q
1
⃗
,
q
2
⃗
,
…
,
q
n
⃗
]
∈
R
V
×
n
Q = [\vec{q_1}, \vec{q_2}, \dots, \vec{q_n}] \in \mathbb{R}^{V \times n}
Q=[q1,q2,…,qn]∈RV×n,
q
t
⃗
∈
R
V
×
1
\vec{q_t} \in \mathbb{R}^{V \times 1}
qt∈RV×1,
S
∈
R
2
m
×
n
S \in \mathbb{R}^{2m \times n}
S∈R2m×n,
s
t
⃗
∈
R
2
m
×
1
\vec{s_t} \in \mathbb{R}^{2m \times 1}
st∈R2m×1。
随后我们使用Softmax将向量
q
t
⃗
=
[
q
1
,
q
2
,
…
,
q
V
]
T
\vec{q_t} = [q_1, q_2, \dots, q_V]^T
qt=[q1,q2,…,qV]T转换为概率分布向量
p
i
⃗
\vec{p_i}
pi,即
p
i
⃗
=
Softmax
(
q
i
⃗
)
=
exp
(
q
i
)
∑
k
=
1
V
exp
(
q
k
)
\vec{p_i} = \text{Softmax}(\vec{q_i}) = \frac{\exp(q_i)}{ \sum\limits_{k=1}^{V} \exp(q_k)}
pi=Softmax(qi)=k=1∑Vexp(qk)exp(qi)
其中,
q
t
⃗
∈
R
V
×
1
\vec{q_t} \in \mathbb{R}^{V \times 1}
qt∈RV×1为映射后的向量、
p
t
⃗
∈
R
V
×
1
\vec{p_t} \in \mathbb{R}^{V \times 1}
pt∈RV×1为转换为概率分布后的向量。
写成矩阵的形式为
P
=
(
p
1
⃗
,
p
2
⃗
,
…
,
p
n
⃗
)
P = (\vec{p_1},\vec{p_2}, \dots, \vec{p_n})
P=(p1,p2,…,pn)
其中
p
t
⃗
∈
R
V
×
1
\vec{p_t} \in \mathbb{R}^{V \times 1}
pt∈RV×1 为每个单词对应位置的词向量表示的概率分布,
P
∈
R
V
×
n
P \in \mathbb{R}^{V \times n}
P∈RV×n为整个句子的矩阵向量。
ELMo模型输出
实际上MLP and Softmax层输出的概率分布矩阵实际上就是ELMo模型的输出,即上下文感知的表示。通过这个概率分布,我们可以从词汇表中查出需要预测的单词。
损失函数
在计算得到bid-LSTM的结果之后,我们将得到的词向量表示映射到整个单词集合,然后使用Softmax计算概率分布,然后使用交叉熵来计算ELMo模型的损失。
在此处的Softmax运算之前,由于我们的在双向LSTM中的输出维度是
2
h
2h
2h,我们要将其映射为词汇表的维度
V
V
V,随后我们使用softmax将向量q转换为概率分布,最后使用交叉熵损失来计算ELMo模型的损失,即正确的标签为one-hot向量,然后与预测的向量一起进行交叉熵损失计算,得到每一时刻的损失,即
Loss
t
=
−
∑
i
=
1
V
t
a
g
i
log
(
p
i
)
\text{Loss}_t= - \sum_{i = 1}^{V} tag_i\log(p_i)
Losst=−i=1∑Vtagilog(pi)
其中,
p
∈
R
V
×
1
p \in \mathbb{R}^{V \times 1}
p∈RV×1 为预测概率分布向量,
t
a
g
∈
R
V
×
1
tag \in \mathbb{R}^{V \times 1}
tag∈RV×1为正确的标签,
Loss
t
\text{Loss}_t
Losst表示在
t
t
t时刻时得到的损失。
最后再将所有的损失进行求均值得到总的损失,即
Loss
=
1
T
∑
i
=
1
T
Loss
i
\text{Loss} = \frac{1}{T} \sum_{i = 1}^{T} \text{Loss}_i
Loss=T1i=1∑TLossi
其中,
T
T
T为总的时刻数,
Loss
i
\text{Loss}_i
Lossi为
t
t
t时刻的损失。

















 1174
1174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









