






1. vLLM简介
vLLM(向量化大语言模型服务系统)是由加州大学伯克利分校团队精心打造的一款高性能且易于扩展的大语言模型(LLM)推理引擎。该引擎致力于通过前沿的内存管理与计算优化技术,实现高吞吐量、低延迟以及低成本的模型服务。vLLM创新性地运用了PagedAttention内存管理技术,极大提升了GPU显存的利用率,同时具备分布式推理功能,能够高效整合多机多卡资源。无论是对低延迟、高吞吐量有严格要求的在线服务场景,还是在资源受限的边缘部署环境中,vLLM均能展现出卓越的性能表现。

-
中文站点:https://vllm.hyper.ai/docs/
-
英文站点:https://docs.vllm.ai/en/latest/index.html
2. ModelScope简介
ModelScope是阿里巴巴集团倾力打造的开源模型即服务平台,专注于降低模型应用门槛,为AI开发者提供灵活、易用且低成本的一站式模型服务。该平台汇聚了众多前沿的机器学习模型,覆盖自然语言处理、计算机视觉、语音识别等多个领域,并配备丰富多样的API接口与实用工具,助力开发人员轻松实现模型的集成与应用。
-
官方网站:https://modelscope.cn/models
安装ModelScope
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple创建存储目录
mkdir -p /data/Qwen/models/Qwen-32B下载QwQ-32B模型
modelscope download --local_dir /data/Qwen/models/Qwen-32B --model Qwen/QWQ-32B3. 启用与优化NVIDIA GPU
更新软件包列表
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit配置NVIDIA容器运行时
sudo nvidia-ctk runtime configure --runtime=docker重启服务
sudo systemctl daemon-reload && sudo systemctl restart docker4. 运行vLLM容器
拉取镜像
docker pull docker.1panel.live/vllm/vllm-openai启动vLLM容器
docker run -itd --restart=always --name Qwen-32B \-v /data/Qwen:/data \-p 18005:8000 \--gpus '"device=1,2,3,4"' \--ipc=host --shm-size=16g \vllm/vllm-openai:latest \--dtype bfloat16 \--served-model-name Qwen-32B \--model "/data/models/Qwen-32B" \--tensor-parallel-size 4 \--gpu-memory-utilization 0.95 \--max-model-len 81920 \--api-key token-abc123 \--enforce-eager
Docker命令参数解析详解
-
-i(interactive):允许用户与容器进行交互,即使容器不在前台运行。用户可以通过
docker logs或docker attach命令查看容器的输出日志 -
-t(tty):分配一个伪TTY(虚拟终端)到容器,模拟终端环境。
-
-d(detach:在后台运行容器,不占用当前终端。
-
--restart=always:设置容器在主机重启或容器退出后自动重启。
-
--name Qwen-32B:为容器指定一个唯一的名称。
-
-v /data/Qwen:/data:将宿主机上的
/data/Qwen目录挂载到容器内的/data目录。避免容器重启或删除而导致的数据丢失问题。 -
-p 18005:8000:将宿主机的18005端口映射到容器内的8000端口。
-
--gpus '"device=1,2,3,4"':指定容器使用宿主机上的GPU设备1、2、3、4。
-
--ipc=host:共享宿主机的IPC(进程间通信)命名空间,允许容器与宿主机的进程进行通信。
VLLM模型启动参数
-
--dtype bfloat16:指定使用bfloat16(Brain Floating Point 16)进行模型计算。
-
--served-model-name Qwen-32B:设置模型的服务名称为“Qwen-32B”,用于API请求时的模型标识。
-
--model "/data/models/Qwen-32B":指定模型文件的路径为容器内的
/data/models/Qwen-32B。 -
--tensor-parallel-size 4:设置张量并行的规模为4,对应使用4块GPU进行模型并行计算。
-
--gpu-memory-utilization 0.85:设置GPU内存使用率为85%,预留15%的内存空间,防止因内存溢出导致的程序崩溃。
-
--max-model-len 81920:指定模型的最大上下文长度为81920 Token。模型在单次推理中可以处理的输入和输出的总Token数不超过81920个。
-
--api-key token-abc123:设置API访问密钥为“token-abc123”,调用API时需要在请求头中提供此密钥。
-
--enforce-eager:启用Eager执行模式,确保模型推理时逐层计算,避免由于延迟执行可能引发的内存问题。
5. Open Web UI部署
拉取open-webui镜像
docker pull ghcr.nju.edu.cn/open-webui/open-webui:main启动Open Web UI
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway \-v /data/open-webui:/app/backend/data \--name open-webui --restart always ghcr.nju.edu.cn/open-webui/open-webui:main
访问Web界面
浏览器访问:http://localhost:3000

管理员面板--外部链接--新建模型连接
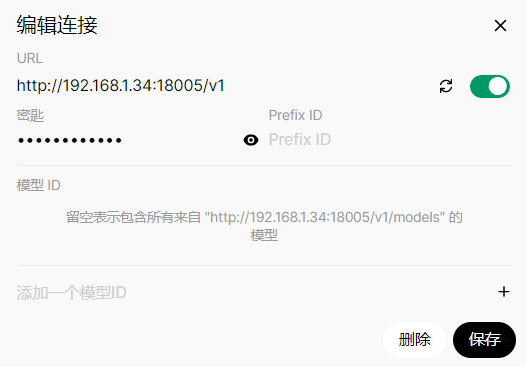
模型ID留空即可自动从/v1/models接口中获取,开启新对面默认选择DeepSeek-R1-Distill-Llama-70B模型
开启新对话
稳定、高效云租赁平台:星海智算
注册即送50元券 链接我放下面了

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









