 10分钟私有部署QwQ-32B模型方案
10分钟私有部署QwQ-32B模型方案





背景
随着大模型技术的快速发展,开源大模型在自然语言处理、代码生成等领域的应用日益广泛。QwQ-32B作为全球领先的开源大模型,以卓越的性能和广泛的应用场景吸引了众多开发者和企业的关注。
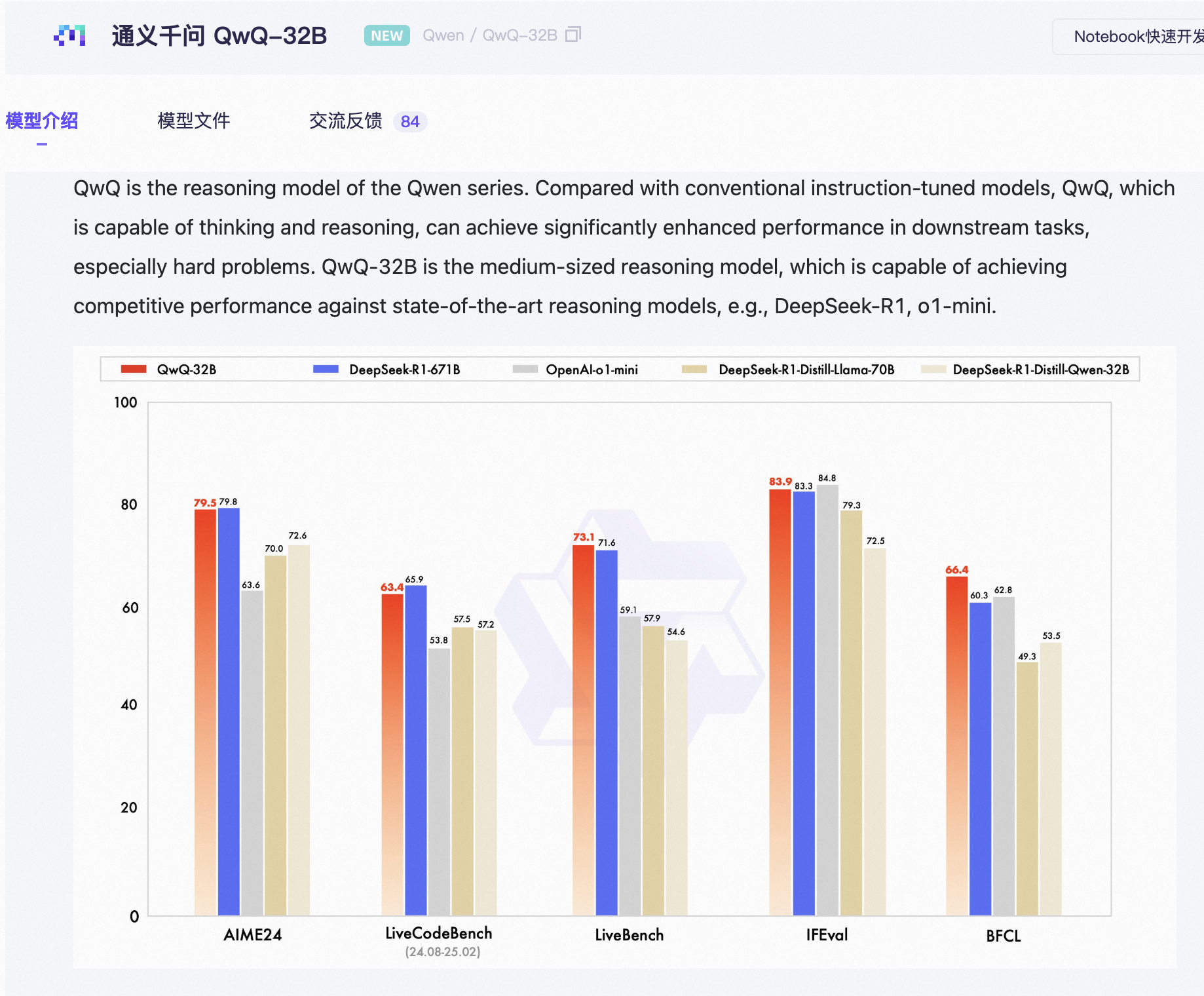
然而,企业用户部署私有QwQ-32B模型服务是比较繁琐的。虽然阿里云提供了基于 IaaS 部署 QwQ-32B 模型的方式,但传统的基于IaaS的部署方式需要用户自行配置环境、安装依赖、优化硬件资源,并解决复杂的网络与存储问题,整个流程不仅耗时耗力,还容易因操作失误导致各种不可预见的问题。
因此,阿里云计算巢提供了基于ECS镜像与VLLM的大模型一键部署方案,通过ECS镜像打包标准环境,通过Ros模版实现云资源与大模型的一键部署,用户无需关心模型部署运行的标准环境与底层云资源编排,10分钟即可部署使用QwQ-32B模型,15分钟即可部署使用Deepseek-R1-70B模型。
部署说明
本服务通过ECS镜像打包标准环境,通过Ros模版实现云资源与大模型的一键部署,开发者无需关心模型部署运行的标准环境与底层云资源编排,仅需添加几个参数即可享受主流LLM(如Qwen、DeepSeek等)的推理体验。
本服务提供的方案下,以平均每次请求的token为10kb计算,采用4张A10卡的服务实例规格,QwQ-32B理论可支持的每秒并发请求数(QPS)约为13.1;采用8张A10卡的服务实例规格,QwQ-32B理论可支持的每秒并发请求数约为24.1,Deepseek-R1-70B约为9.5。
整体架构
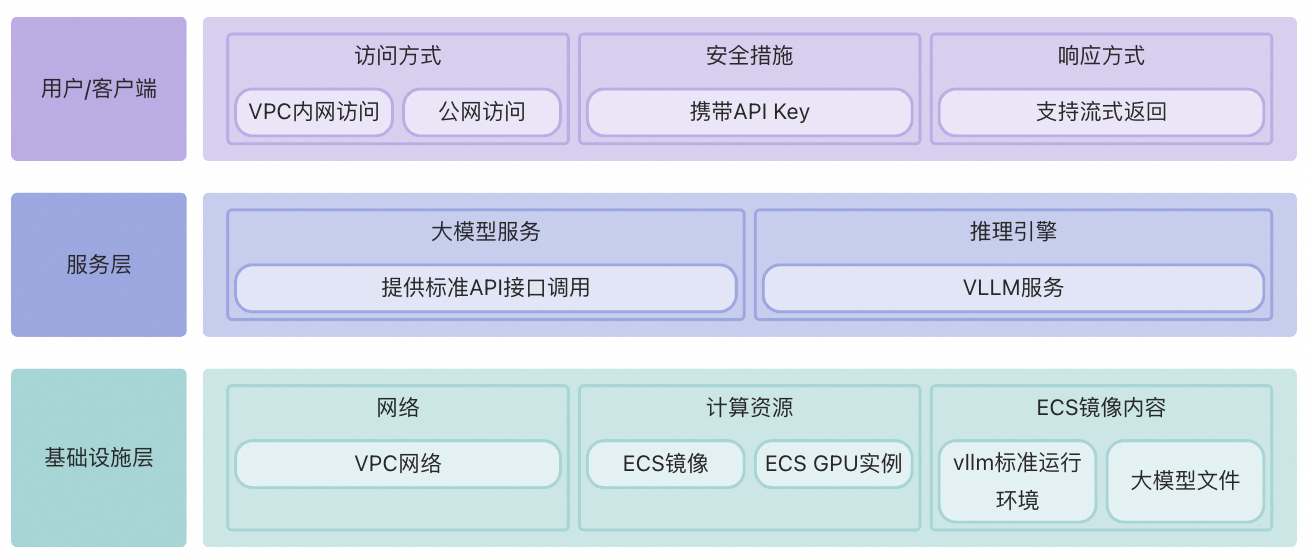
部署流程
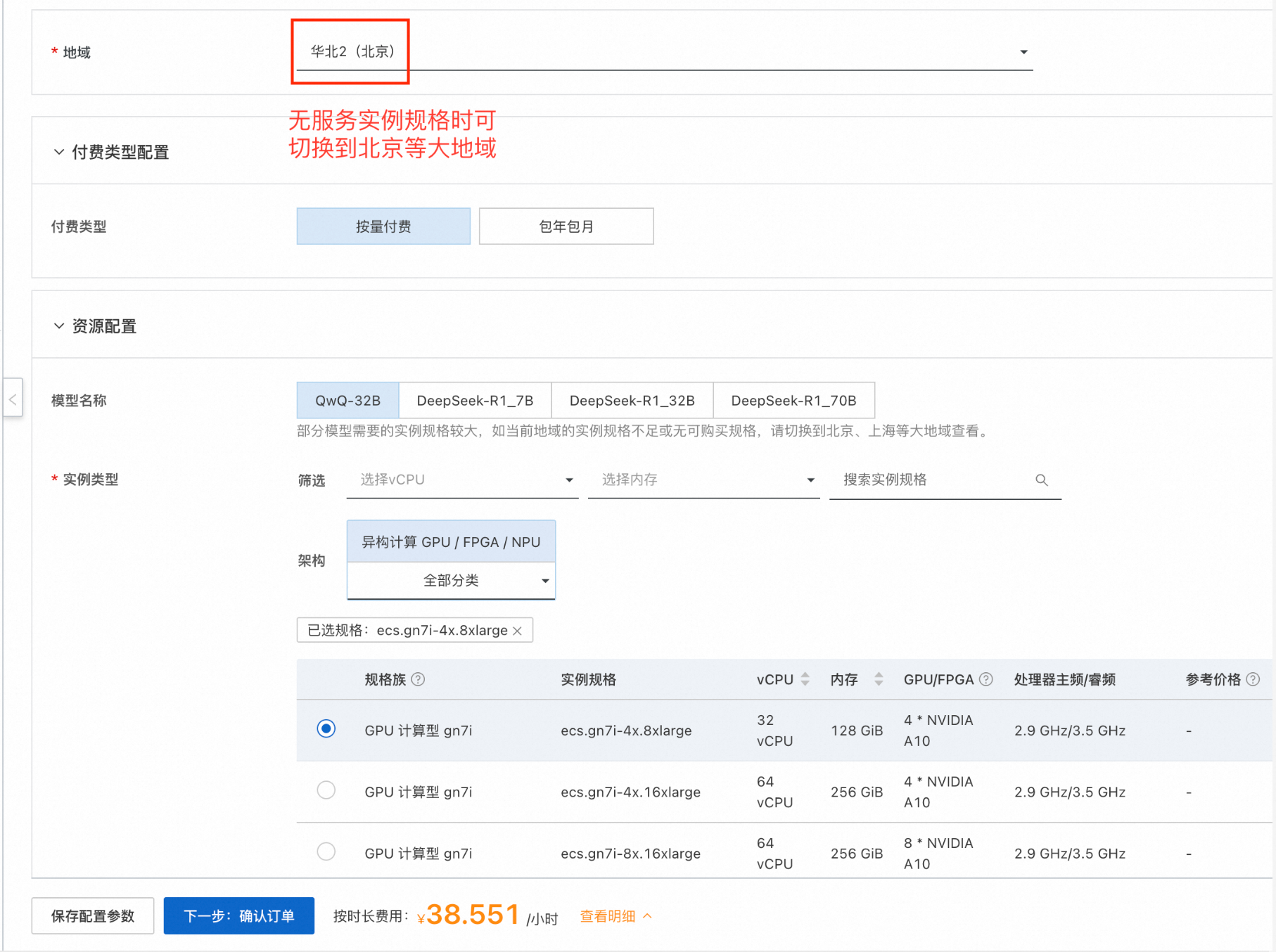
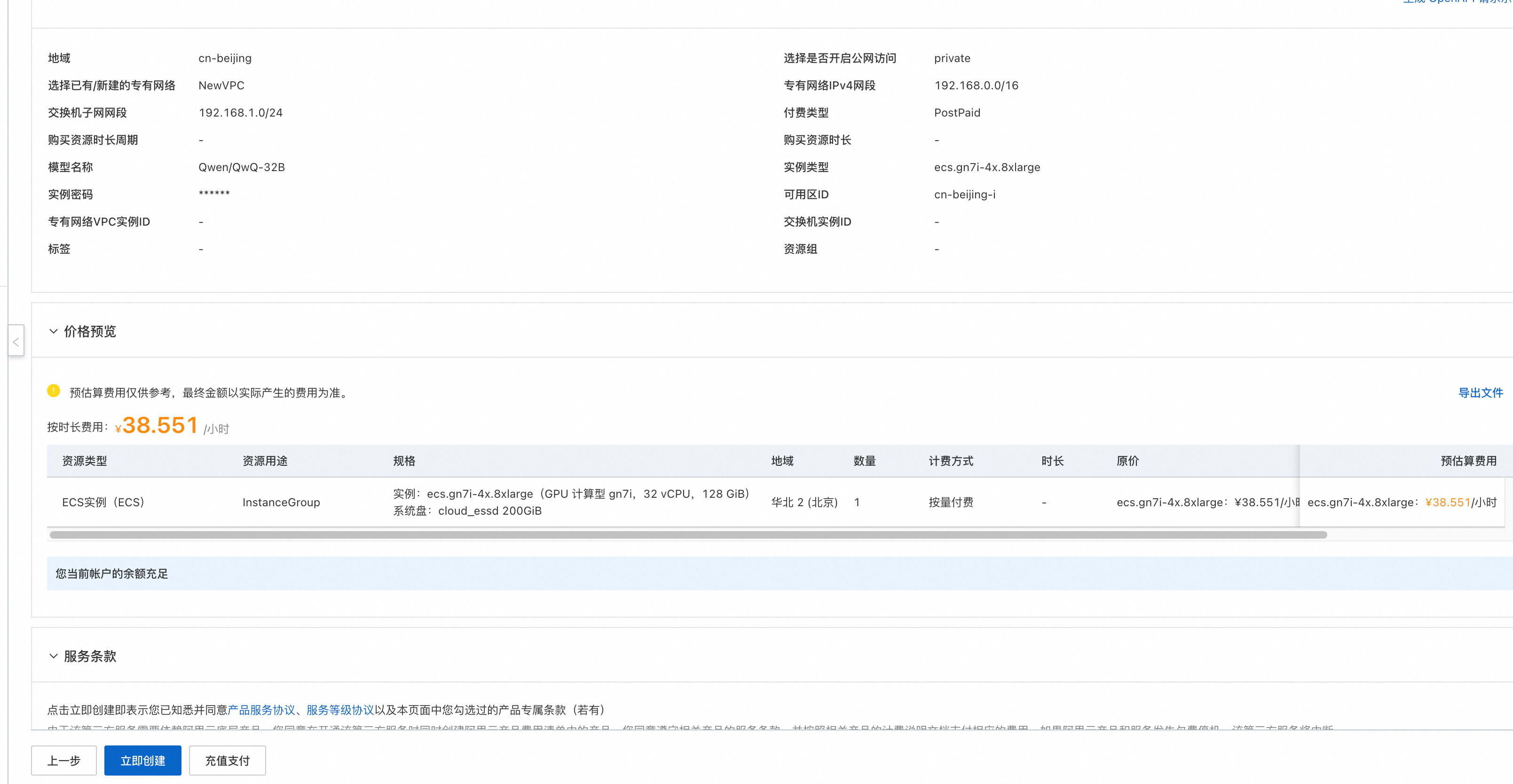
- 单击部署链接。根据界面提示填写参数,可根据需求选择是否开启公网,可以看到对应询价明细,确认参数后点击下一步:确认订单。
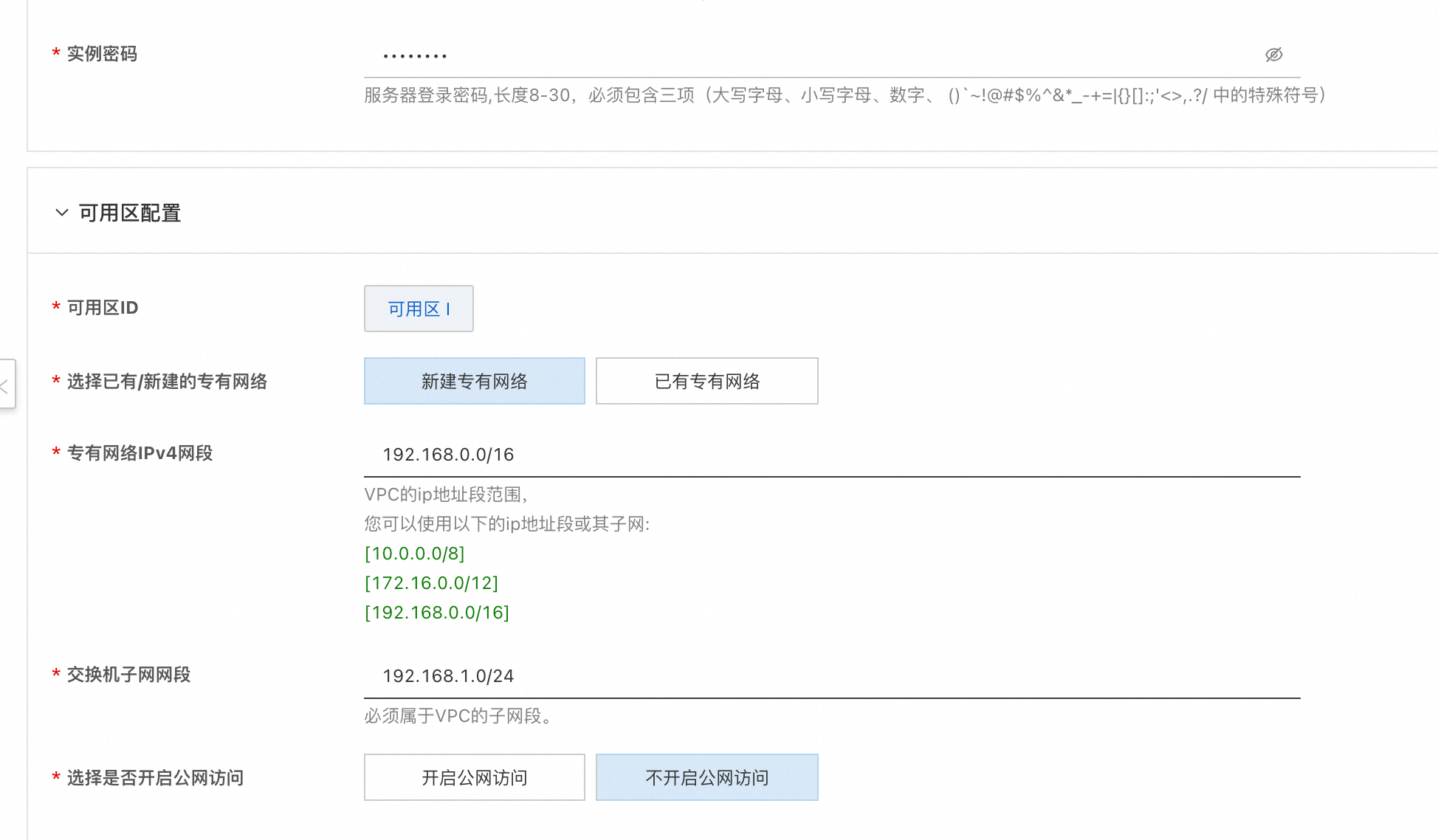
- 点击下一步:确认订单后可以看到价格预览,随后可点击立即部署,等待部署完成。(提示RAM权限不足时需要为子账号添加RAM权限)
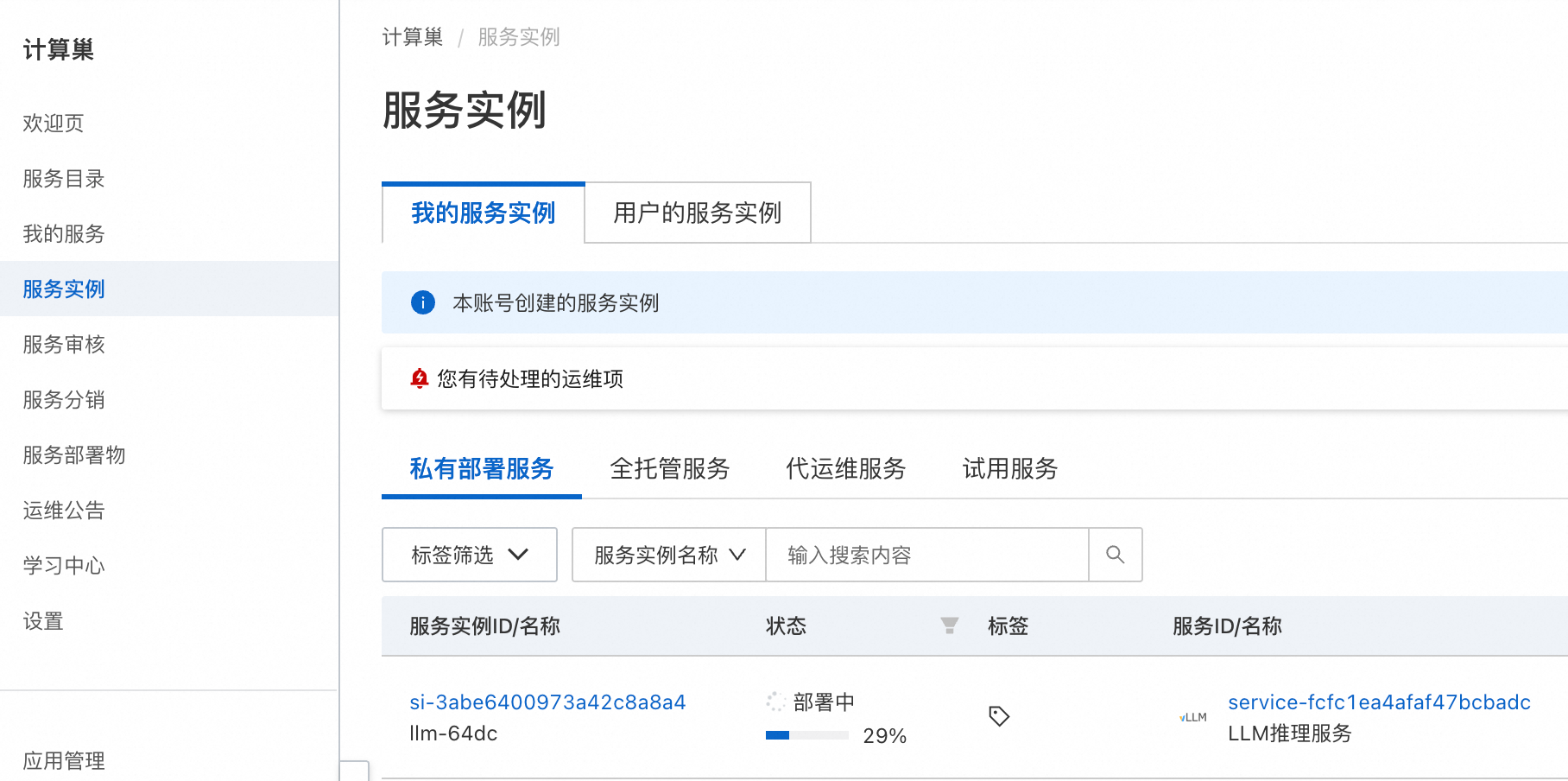
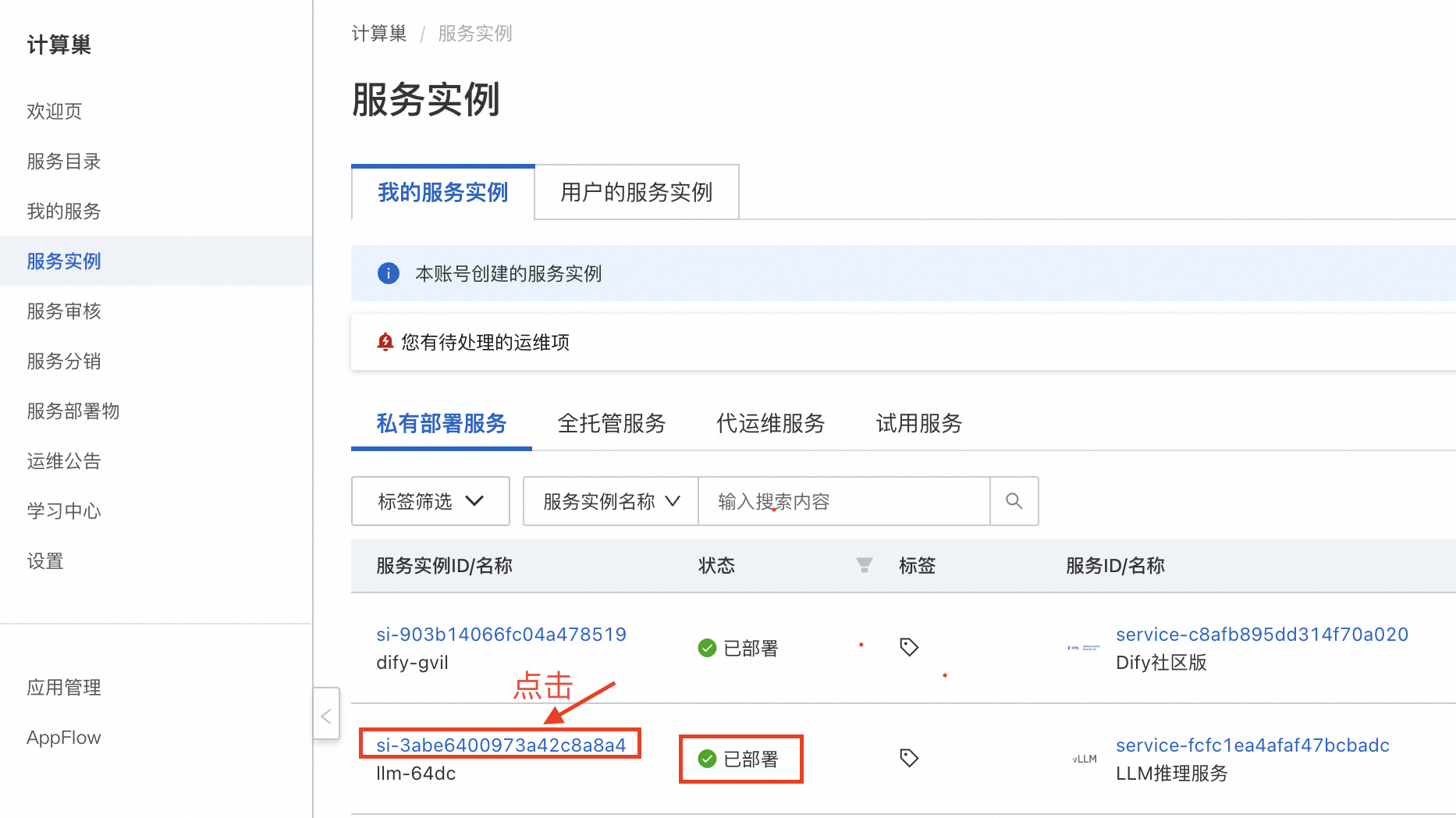
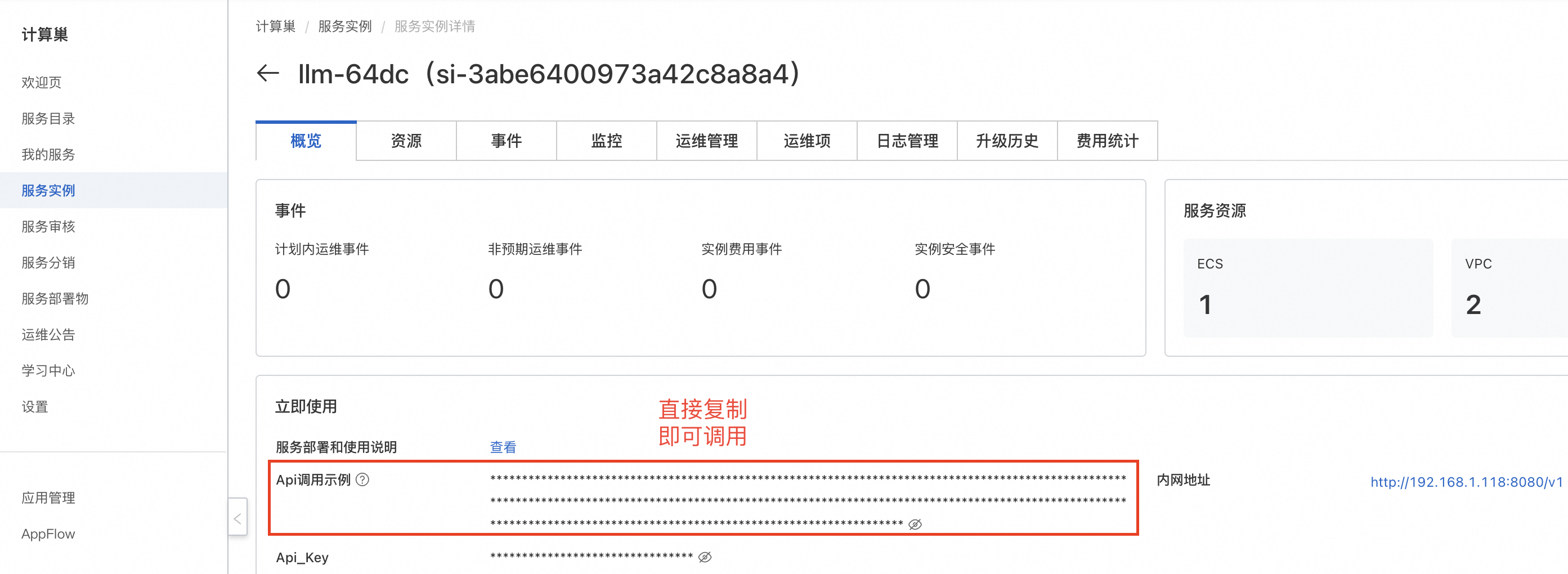
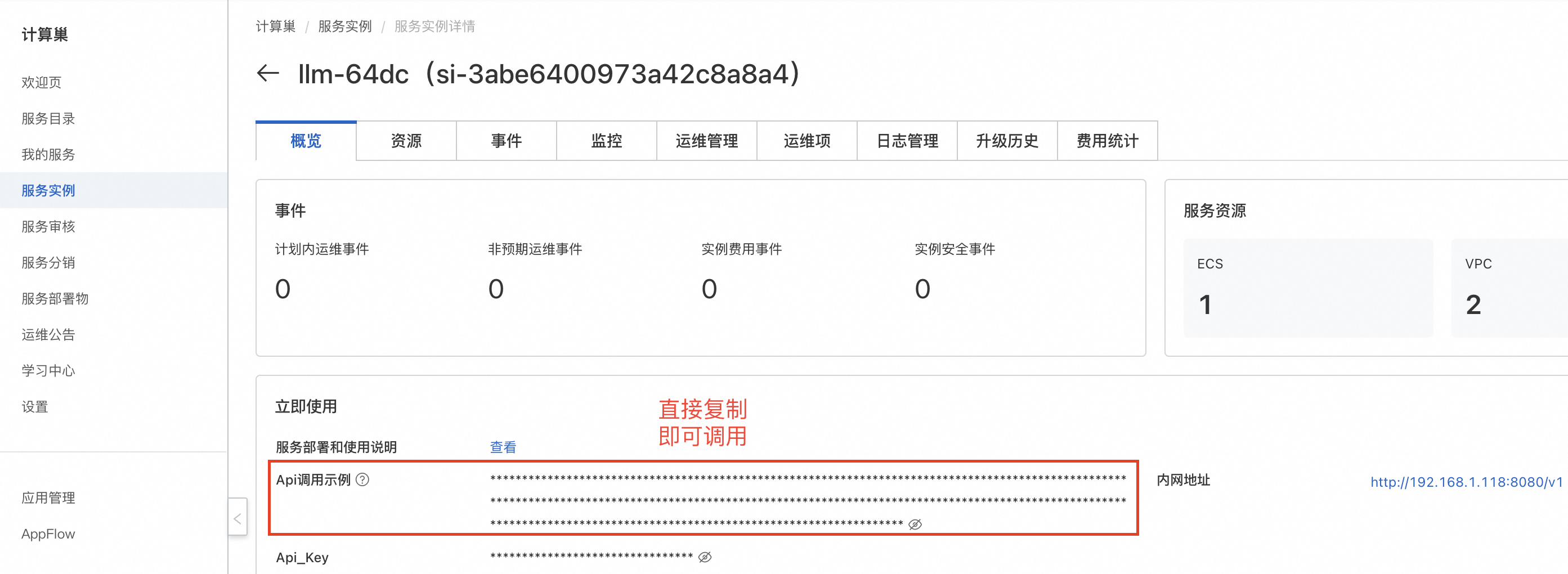
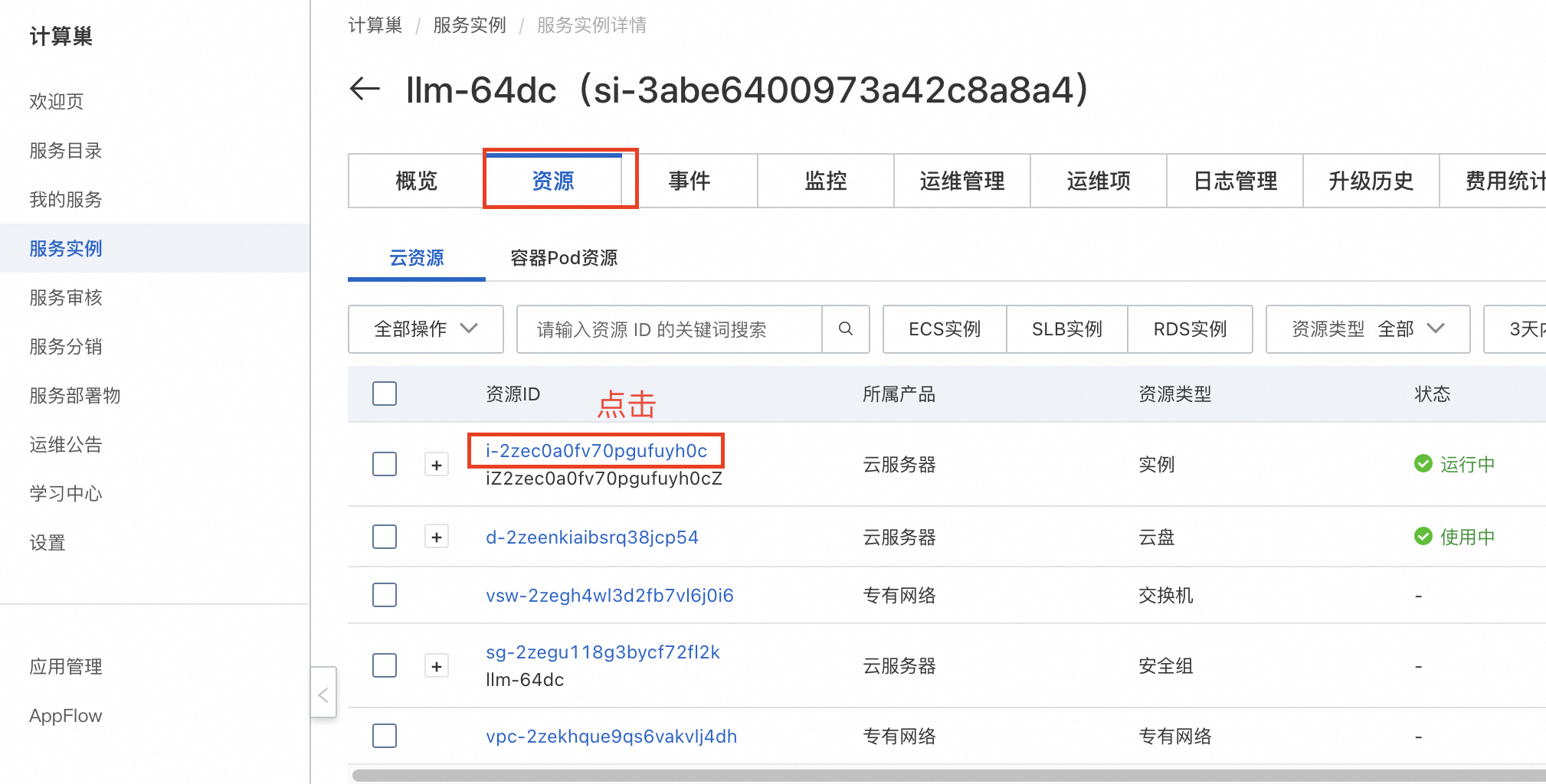
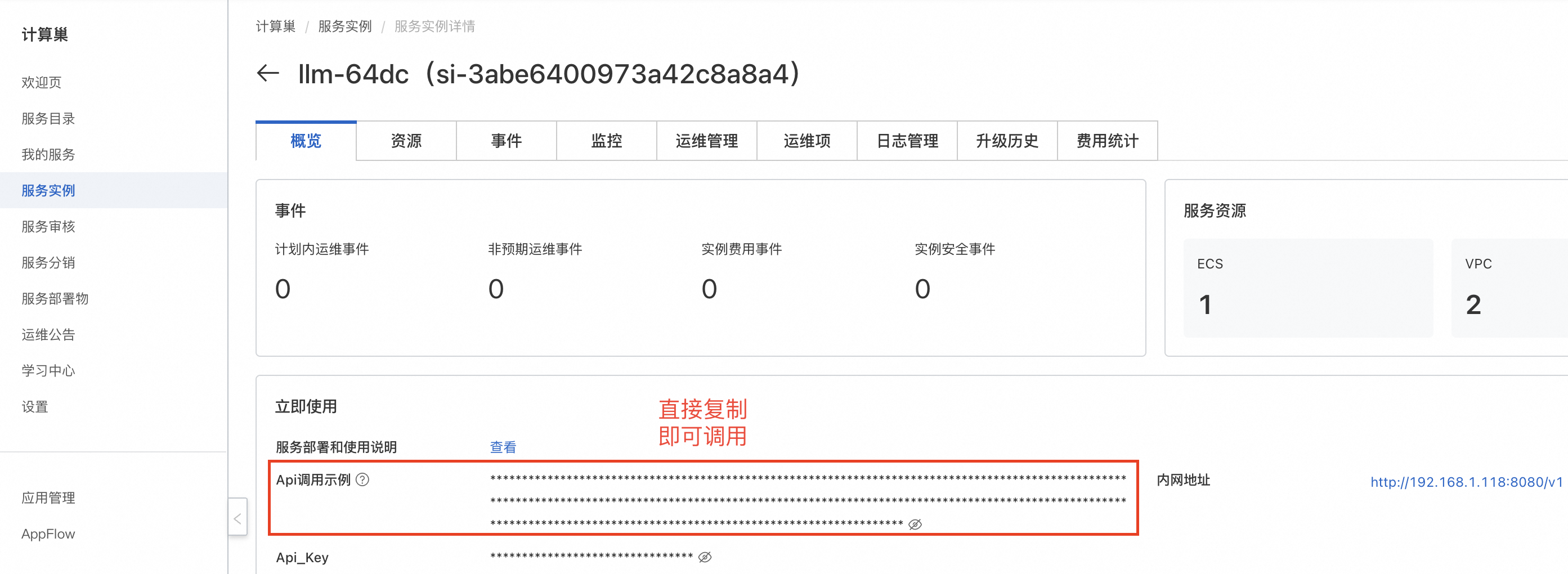
- 等待部署完成后,就可以开始使用服务了。点击服务实例名称,进入服务实例详情,使用Api调用示例即可访问服务。如果是内网访问,需保证ECS实例在同一个VPC下。
- ssh访问ECS实例后,执行 docker logs vllm 即可查询模型服务部署日志。当您看到下图所示结果时,表示模型服务部署成功。模型所在路径为/root/llm_model/${ModelName}。
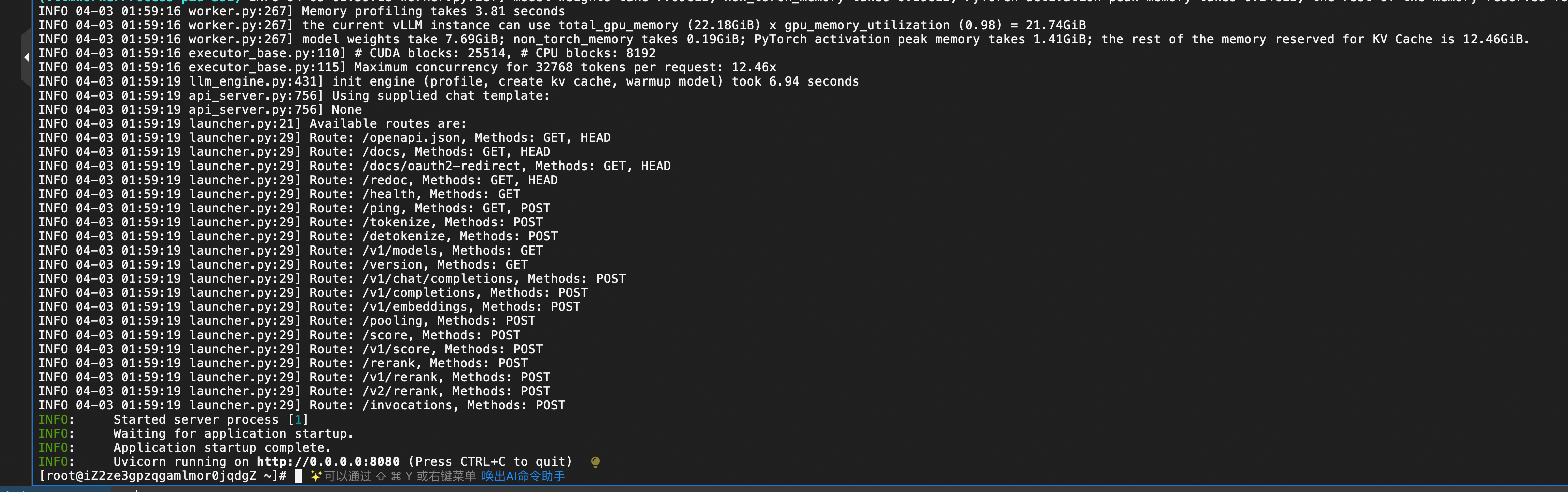
使用说明
内网API访问
复制Api调用示例,在资源标签页的ECS实例中粘贴Api调用示例即可。也可在同一VPC内的其他ECS中访问。
公网API访问
复制Api调用示例,在本地终端中粘贴Api调用示例即可。

性能测试
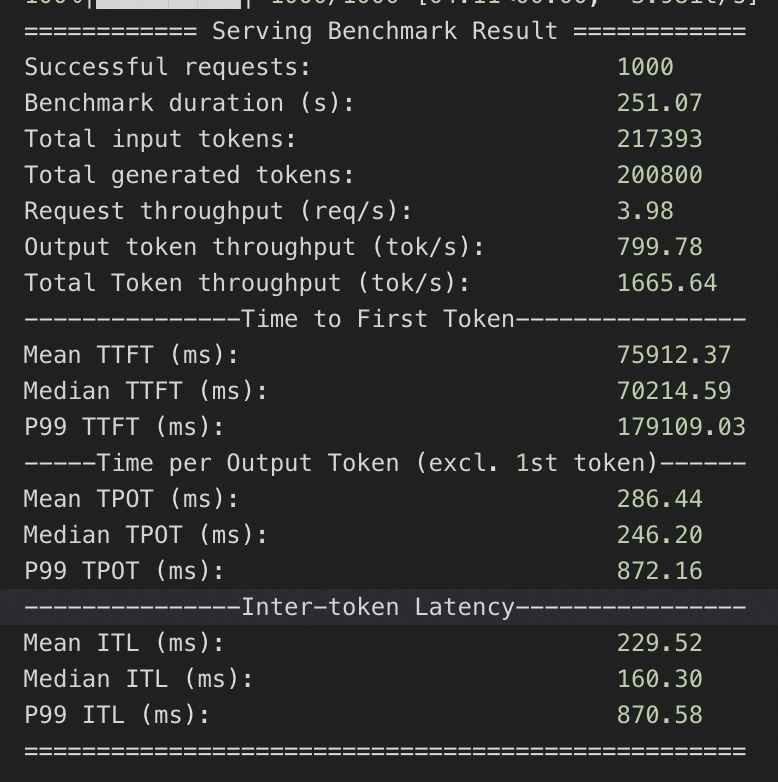
本服务方案下,针对QwQ-32B在4_A10和8_A10实例规格下,分别测试QPS为10、20、50情况下模型服务的推理响应性能,压测持续时间均为20s。
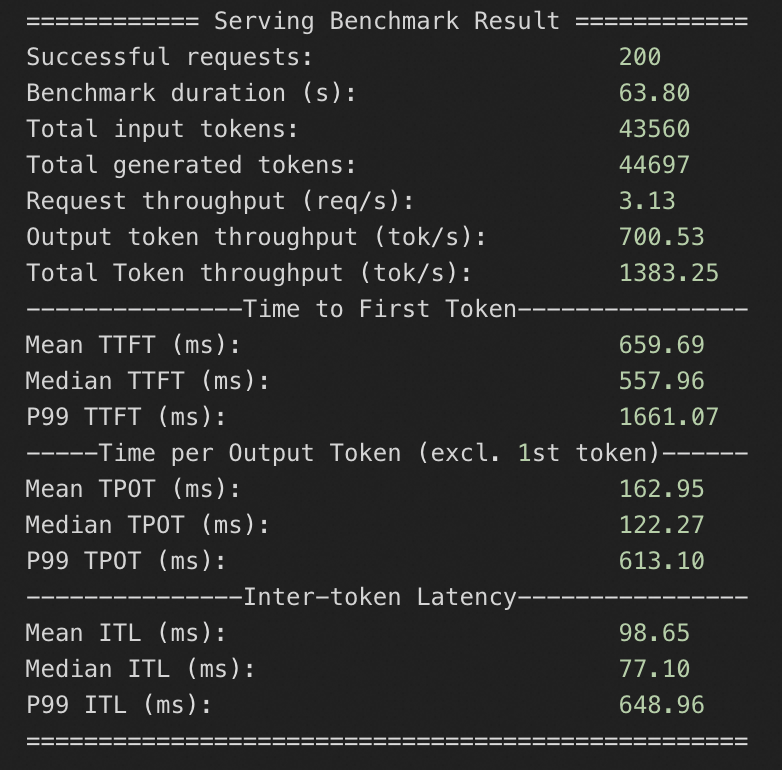
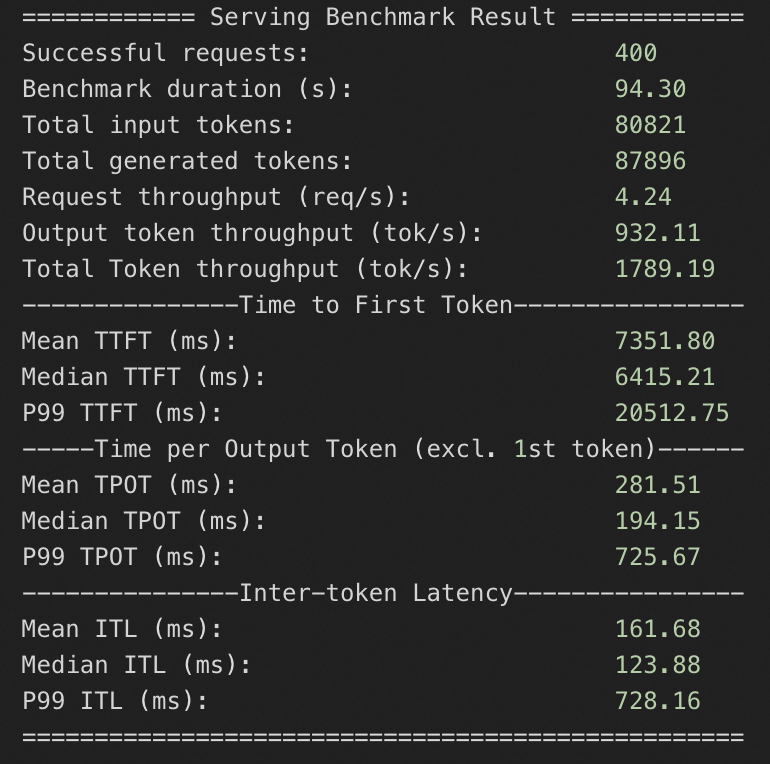
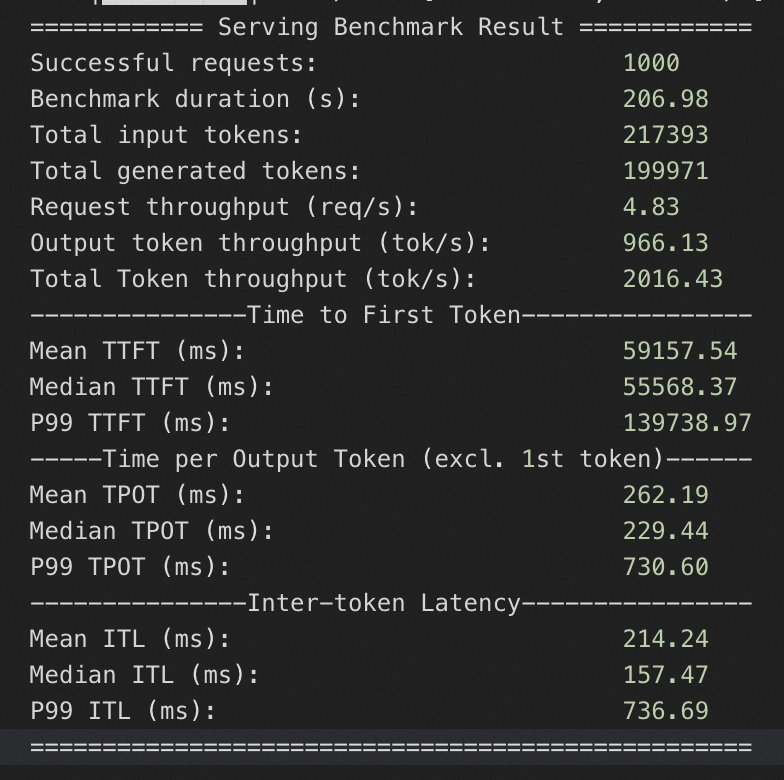
8*A10规格
QPS为10
QPS为20
QPS为50
4*A10规格
QPS为10
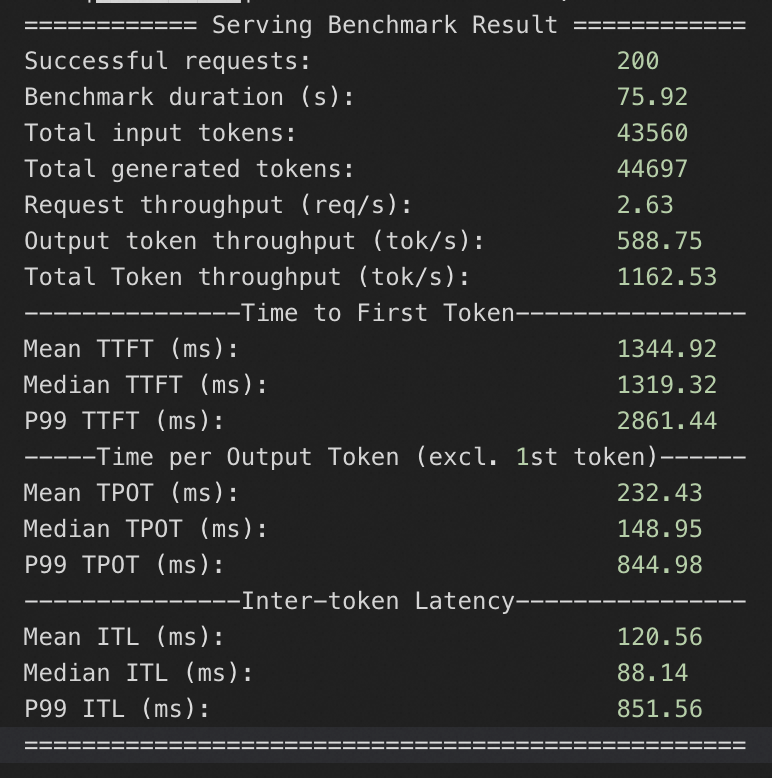
QPS为20
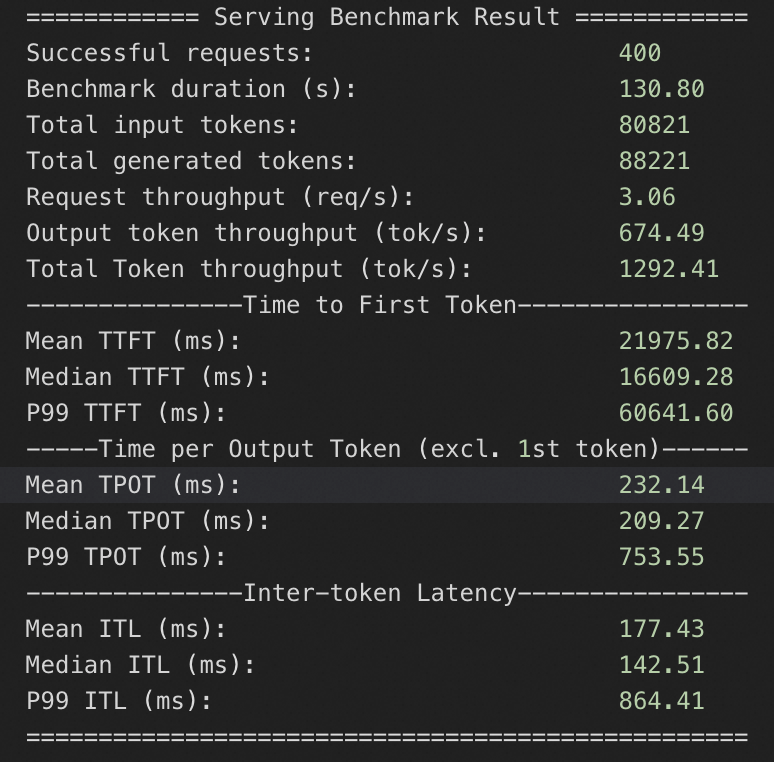
QPS为50


















 1442
1442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









