



随着人工智能和计算机技术的飞速发展,多模态医学图像处理应运而生。它整合多种医学影像模态的信息,能为医生提供更丰富、全面且准确的诊断依据。通过融合不同模态影像的优势,该技术可显著提升疾病早期诊断的准确性,帮助医生更清晰地观察病变特征、位置和范围,进而制定更具针对性的治疗方案。
当下,多模态医学图像处理领域应用极为广泛,其中包含诸多细分研究方向,像多模态医学图像分割、分类、合成、融合以及特征提取等,都是该领域的主流研究点。这些细分方向的研究成果,无论是在辅助医生精准诊断疾病,还是推动医学研究发展上,都有着不可忽视的价值。
为了给大家在研究思路和创新想法上提供便利,我精心整理了十几篇论文。想要发表论文的朋友,千万不要错过噢!
点击【AI十八式】的主页,获取更多优质资源!
【论文1】BSAFusion: A Bidirectional Stepwise Feature Alignment Network for Unaligned Medical Image Fusion
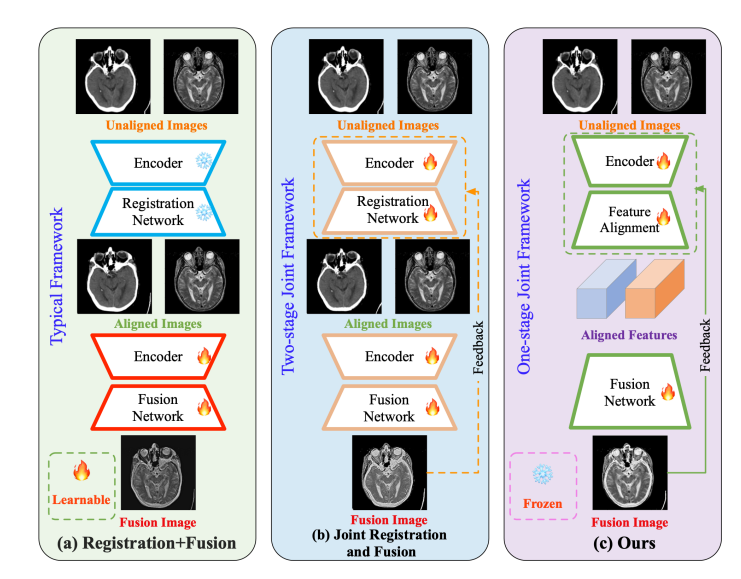
Paradigm of existing unaligned image fusion methods compared to that of our method.
方法
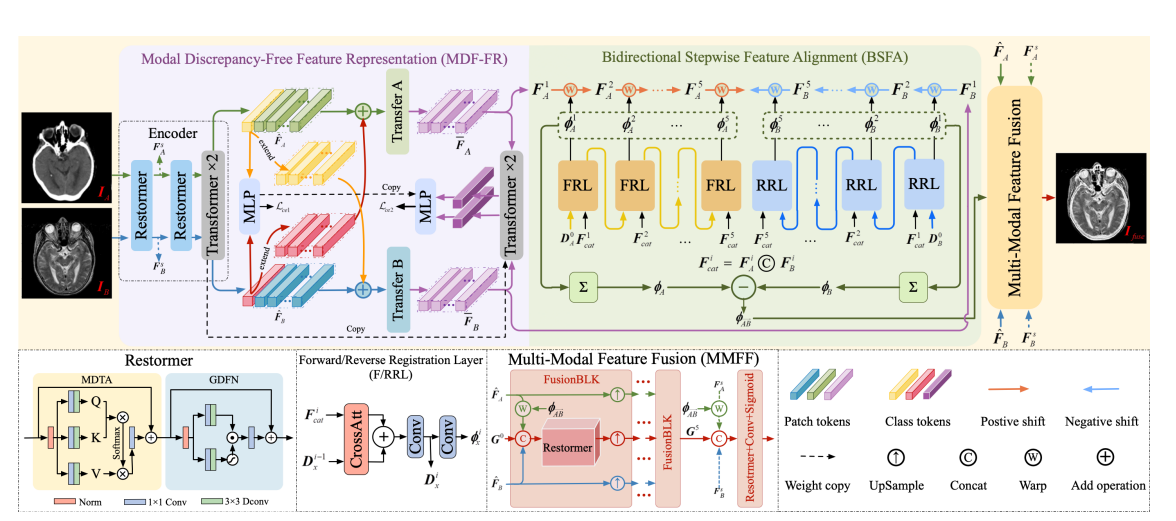
Overall framework of the proposed method
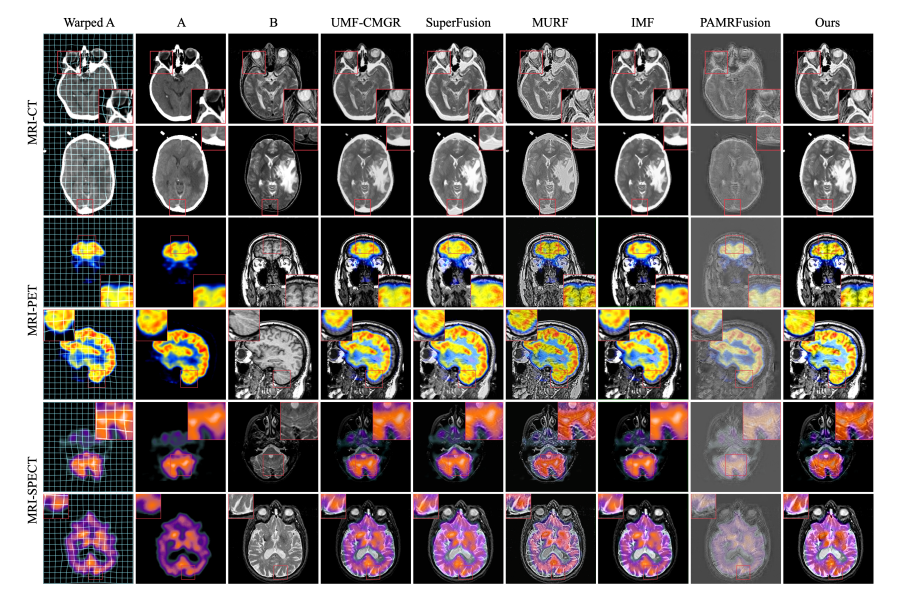
在多模态医学图像处理领域,本文提出了一种单阶段的多模态医学图像配准与融合框架,其核心方法为双向逐步特征对齐(BSFA)。该方法先利用模态差异消除特征表示(MDF-FR)减少模态差异对特征匹配的影响,接着基于两点间向量位移的路径独立性,采用双向逐步对齐变形场预测策略实现特征对齐,最后通过多模态特征融合(MMFF)模块完成特征融合 。
创新点
-
设计联合实现框架:将特征跨模态对齐与融合集成,通过共享单个特征编码器,无缝整合配准和融合,避免因引入额外编码器导致模型复杂度增加。
-
提出模态差异减少方法:为每个输入图像添加模态特征表示头以实现全局特征集成,将当前图像的特征表示融入其他待融合图像的特征中,有效减轻模态差异和多模态图像信息不一致对特征对齐的影响,同时保留不同图像间的互补信息。
-
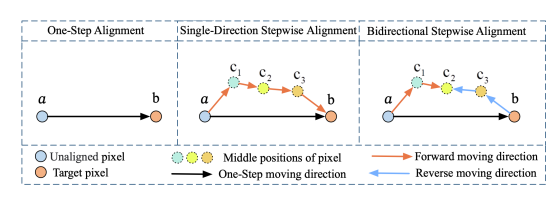
创新变形场预测策略:基于两点间向量位移的路径独立性,提出双向逐步变形场预测策略,解决了传统单步对齐方法中变形场预测跨度大、不准确的问题,显著提高特征对齐的精度和效率。
论文链接:https://arxiv.org/abs/2412.08050
【论文2】MedM2G: Unifying Medical Multi-Modal Generation via Cross-Guided Diffusion with Visual Invariant
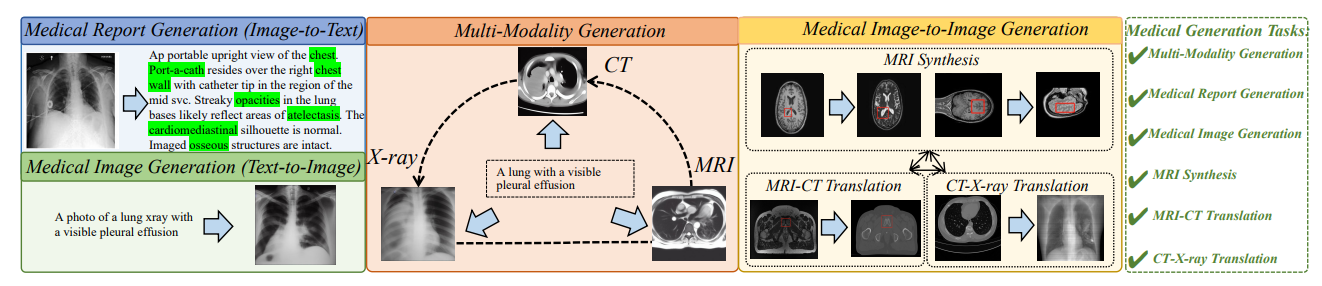
MedM2G on multiple medical generative tasks
方法
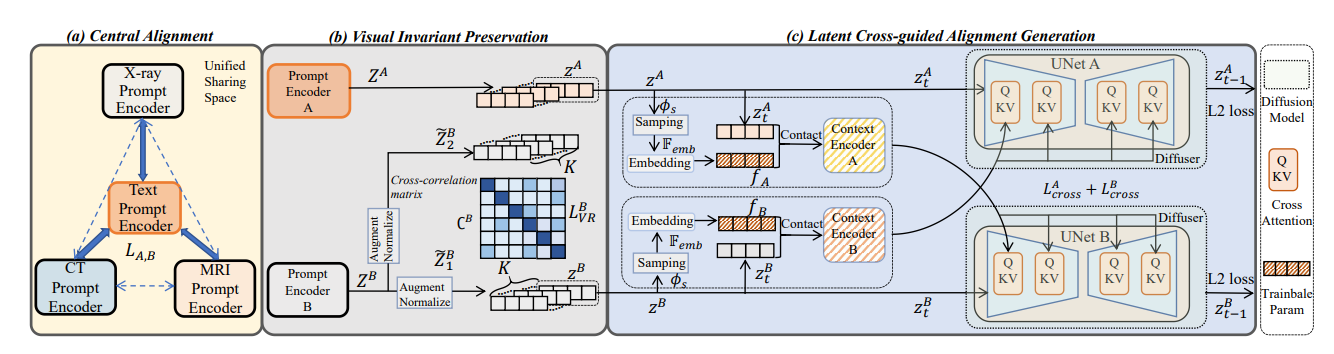
The network structure of MedM2G
MedM2G提出了一种统一的医学多模态生成框架,通过跨模态引导扩散过程和视觉不变性保留来实现多模态医学图像处理。具体方法包括:1)采用中心对齐策略(Central Alignment),以文本模态为中心高效对齐CT、MRI、X射线等多种医学模态;2)设计医学视觉不变性模块(Medical Visual Invariant Preservation),通过最小化交叉相关矩阵的非对角线元素,保留每种成像模态的独特临床知识;3)提出潜在跨模态引导扩散(Latent Cross-guided Diffusion),通过可训练的自适应参数和多流训练策略增强模态间交互,实现高质量生成。
创新点

-
首个统一医学多模态生成框架:MedM2G首次将文本-图像、图像-图像(如MRI-CT转换)等任务整合到单一模型中,支持5种生成任务和10种数据集。
-
中心对齐与视觉不变性:通过文本模态作为枢纽对齐多模态数据,并结合视觉不变性模块避免临床信息混淆,显著提升生成准确性。
-
跨模态引导扩散:引入自适应参数和共享注意力层,在缺乏配对数据的情况下仍能实现模态间高效交互,生成互补的多模态医学图像。
-
多流训练策略:仅需三组配对数据即可完成多模态联合训练,降低了计算成本,增强了模型扩展性。
论文链接:https://hub.baai.ac.cn/paper/9787e033-1baf-4a88-96ee-9d77408e38c1
点击【AI十八式】的主页,获取更多优质资源!


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









