



在人工智能领域,基于Transformer的强化学习(TRL)备受关注,它借助Transformer模型架构优化强化学习算法性能。
Transformer具有强大的表示能力,能够高效处理复杂的序列信息,而强化学习拥有决策优化框架,二者结合,大幅提升了智能体的学习与适应能力,为解决复杂环境下的决策难题开辟了新路径,也促使其在众多领域得到广泛应用。比如在自动驾驶领域,可帮助车辆精准感知路况并做出合理决策;在机器人控制方面,能让机器人快速学习并执行复杂任务。
今天,我将为大家分享十几篇TRL的代表性成果。这些成果涵盖了TRL在各领域的热门应用案例,深入剖析这些内容,希望能为同学们在相关研究中寻找新思路提供有益参考。
【论文1】Combining diffusion and transformer models for enhanced promoter synthesis and strength prediction in deep learning!
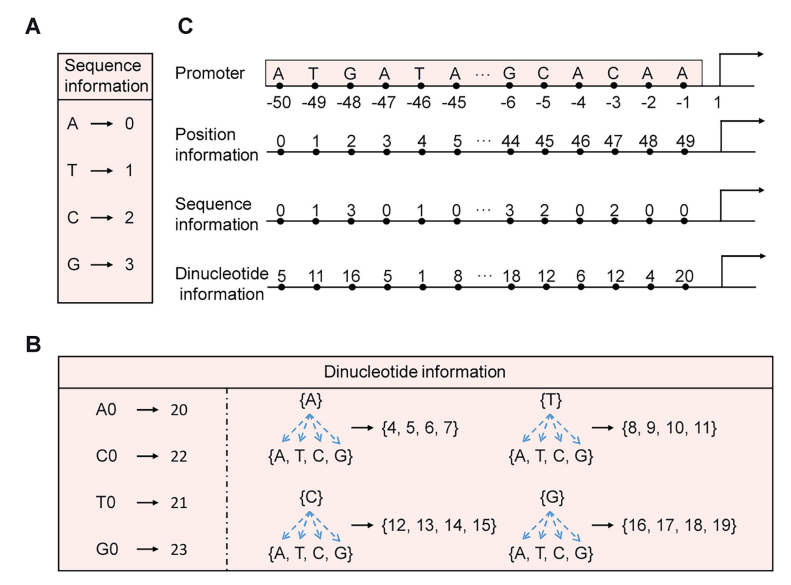
Encoding methods for input features of the prediction task
研究方法
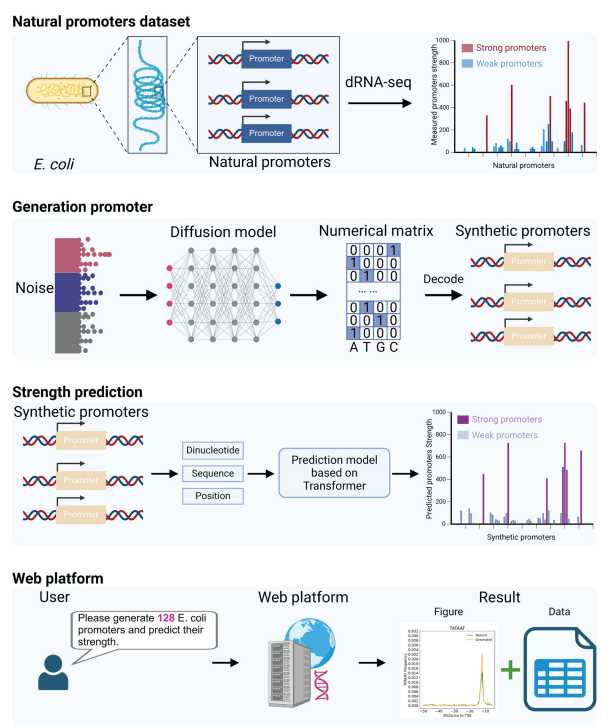
在合成生物学领域,强化启动子合成及强度预测意义重大,本文将扩散模型与 Transformer 模型结合用于该研究。即先利用包含大肠杆菌和蓝藻等的启动子数据集训练扩散模型,通过噪声添加和去除过程,提取天然启动子生物特征来生成合成启动子;再构建基于 Transformer 的预测模型,对合成启动子进行筛选,预测其强度 。 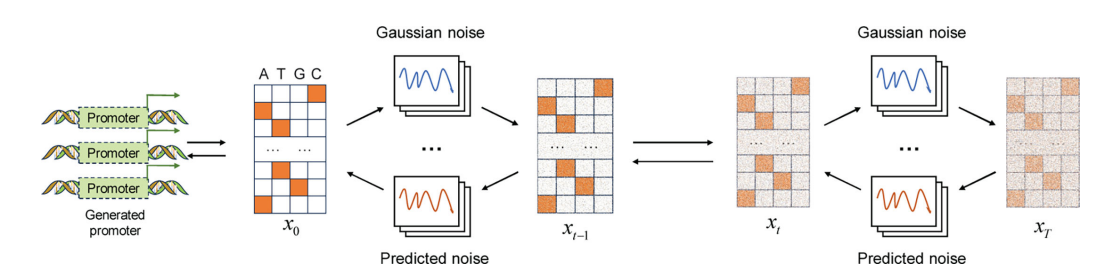
论文创新点
-
模型性能优势:与变分自编码器(VAE)相比,扩散模型合成的启动子在多项指标上表现更优,如6 - mer频率的位置分布、序列标识和k - mer频率相关性等,且训练过程更稳定,收敛速度更快。
-
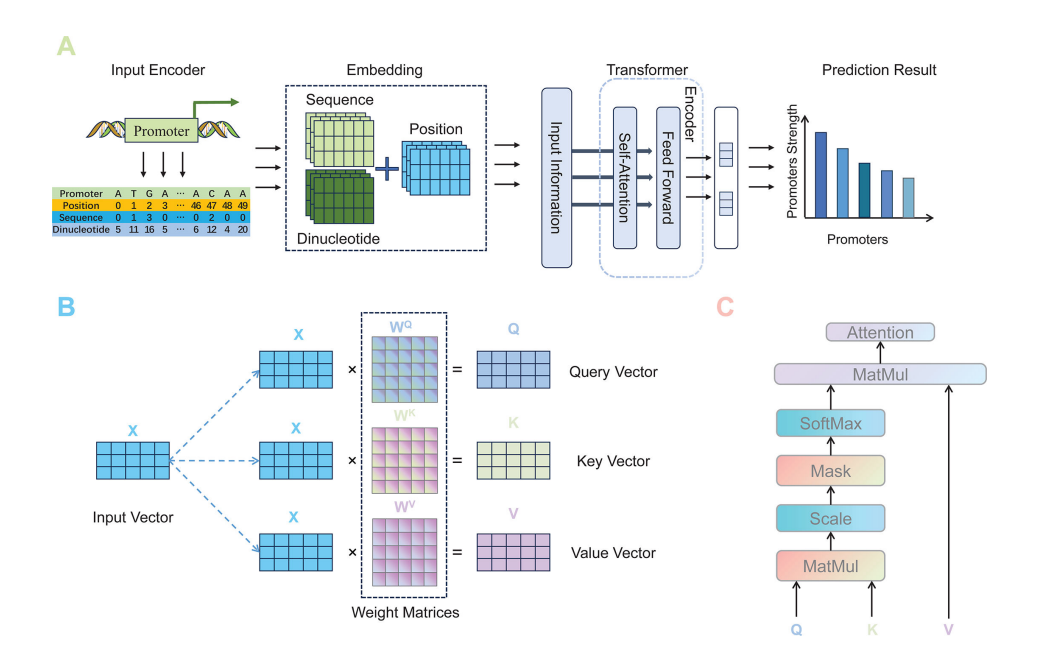
预测能力提升:Transformer模型在预测启动子强度方面比卷积神经网络(CNN)表现更出色,它能提取与启动子强度相关的多方面特征,包括序列和二核苷酸信息等,使预测更精准。
-
深入分析机制:研究对深度学习模型学习生物特征的过程进行了详细展示,通过实验分析了启动子序列突变对启动子强度的影响,揭示了关键区域和突变类型的作用。
-
集成平台构建:开发了一个集成平台,可生成启动子并预测其强度,方便研究人员使用,还能可视化合成和天然启动子的分布特征并支持结果下载。
论文链接:https://journals.asm.org/doi/10.1128/msystems.00183-25
【论文2】STORM: Efficient Stochastic Transformer based World Models for Reinforcement Learning
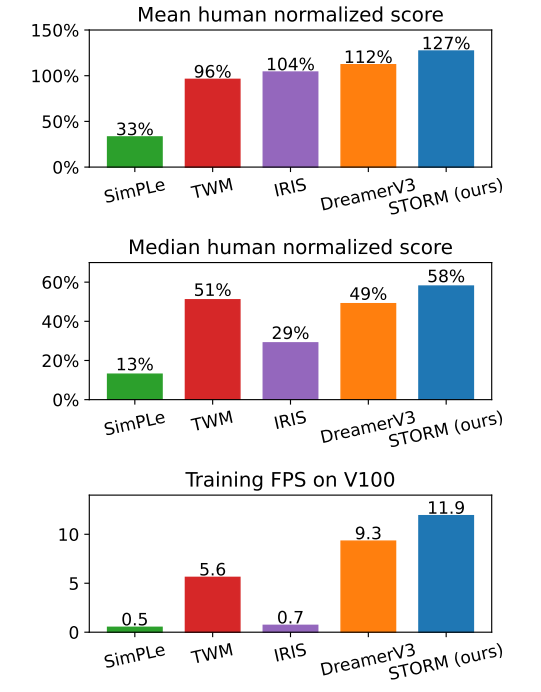
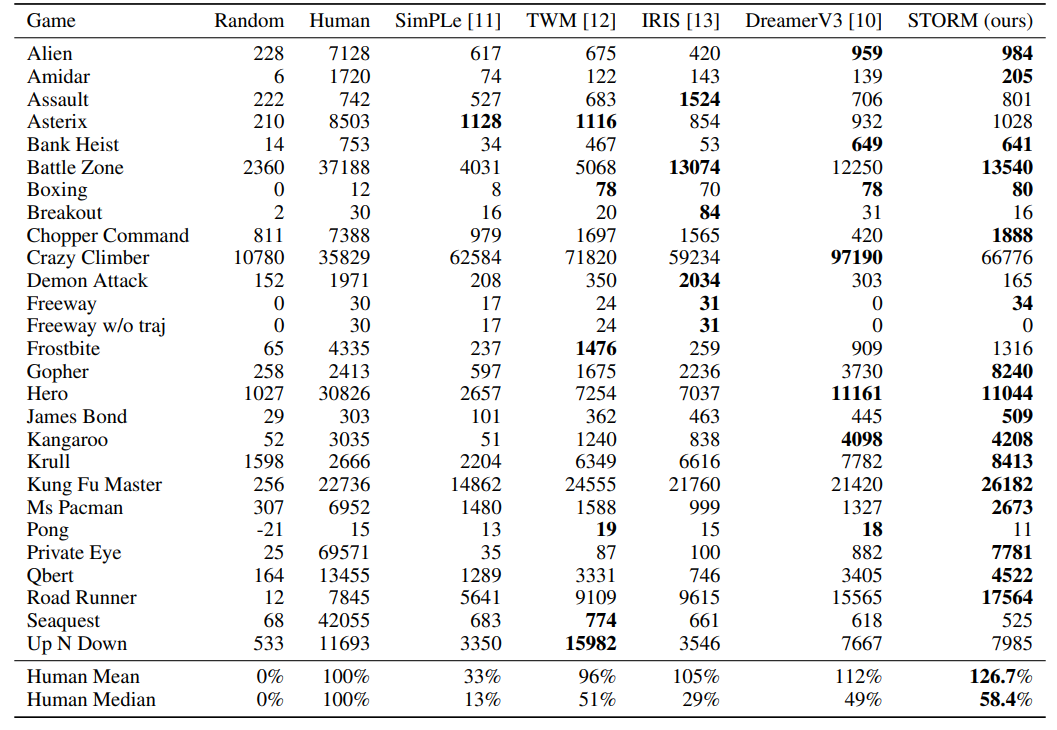
Comparison of methods on Atari 100k
研究方法
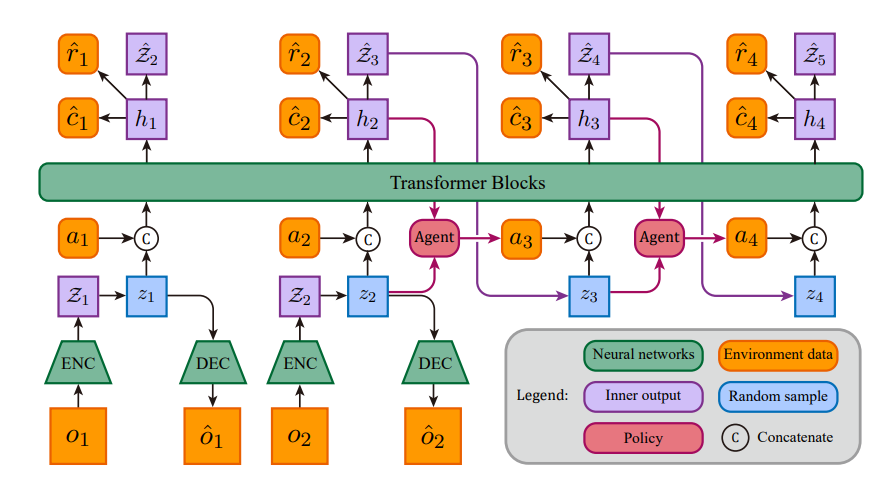
: Structure and imagination process of STORM
这篇论文提出了基于随机 Transformer 的世界模型(STORM),用于基于模型的强化学习。研究方法为:先通过执行当前策略收集真实环境数据并存储到回放缓冲区;接着利用缓冲区中的轨迹更新世界模型,该模型使用变分自编码器(VAE)将图像观测转换为潜在变量,再用 Transformer 作为序列模型预测奖励、延续标志和下一状态分布;最后,利用世界模型生成的想象经验改进智能体策略。
论文创新点
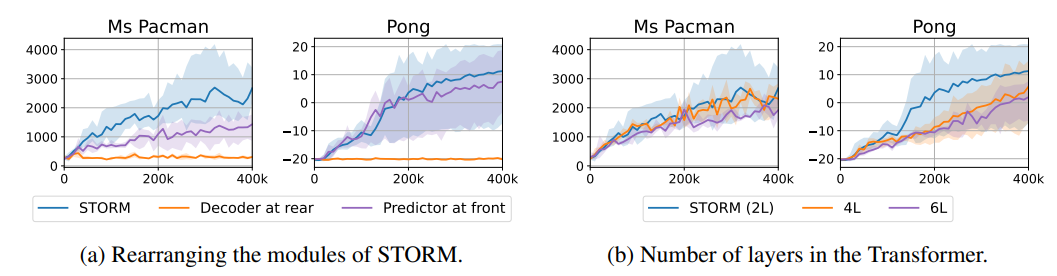
-
结合Transformer优势:将Transformer强大的序列建模和生成能力与变分自编码器的随机性相结合,构建世界模型。Transformer结构克服了循环神经网络(RNN)训练速度慢的问题,且其自注意力机制能更好地处理长序列依赖,提高建模和生成质量。
-
提高训练效率:在Atari 100k基准测试中,训练效率显著提升。使用单个NVIDIA GeForce RTX 3090显卡,仅需4.3小时就能完成对具有1.85小时实时交互经验的智能体训练,而其他方法耗时更长。
-
优异的性能表现:在Atari 100k基准测试中取得了平均人类归一化分数126.7%的成绩,在不使用前瞻搜索技术的方法中创造了新纪录,在处理与奖励相关的大物体或多个物体的环境中表现出色。
-
消融实验探索:通过消融实验研究世界模型设计、智能体状态选择和演示轨迹对结果的影响。发现重建损失应直接应用于编码器输出;增加Transformer层数不一定提升性能;在部分环境中,智能体状态结合隐藏状态和潜在变量可提高性能;稀疏奖励环境中添加演示轨迹有益,密集奖励环境则可能有负面影响。
论文链接:https://proceedings.neurips.cc/paper_files/paper/2023/file/5647763d4245b23e6a1cb0a8947b38c9-Paper-Conference.pdf


















 271
271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}