



Transformer架构一直是各大顶会的研究热点,无论是结构创新还是与其他技术的融合,都展现出巨大潜力。像ECCV 2024中一篇高质量论文便将Transformer与小波变换相结合,提出的新架构SWformer在捕捉空间频率模式方面表现出色,显著优于现有SNN模型。这种融合策略之所以有效,得益于小波变换的多尺度分析能力,使Transformer在处理图像或信号时既能捕捉细节变化,又能把握全局上下文,实现效率与精度的平衡。
类似的研究方向已在多个顶会上崭露头角,如CVPR 2024的GestFormer用于动态手势识别,AAAI 2024的WaveFormer应用于视频修复等。为方便研究者参考,我已整理出22篇Transformer结合小波变换的最新论文,涵盖顶会顶刊并多数附有代码,助你高效跟进前沿进展。
点击【AI十八式】的主页,获取更多优质资源!
一、Uncertainty-Aware Source-Free Adaptive Image Super-Resolution with Wavelet Augmentation Transformer
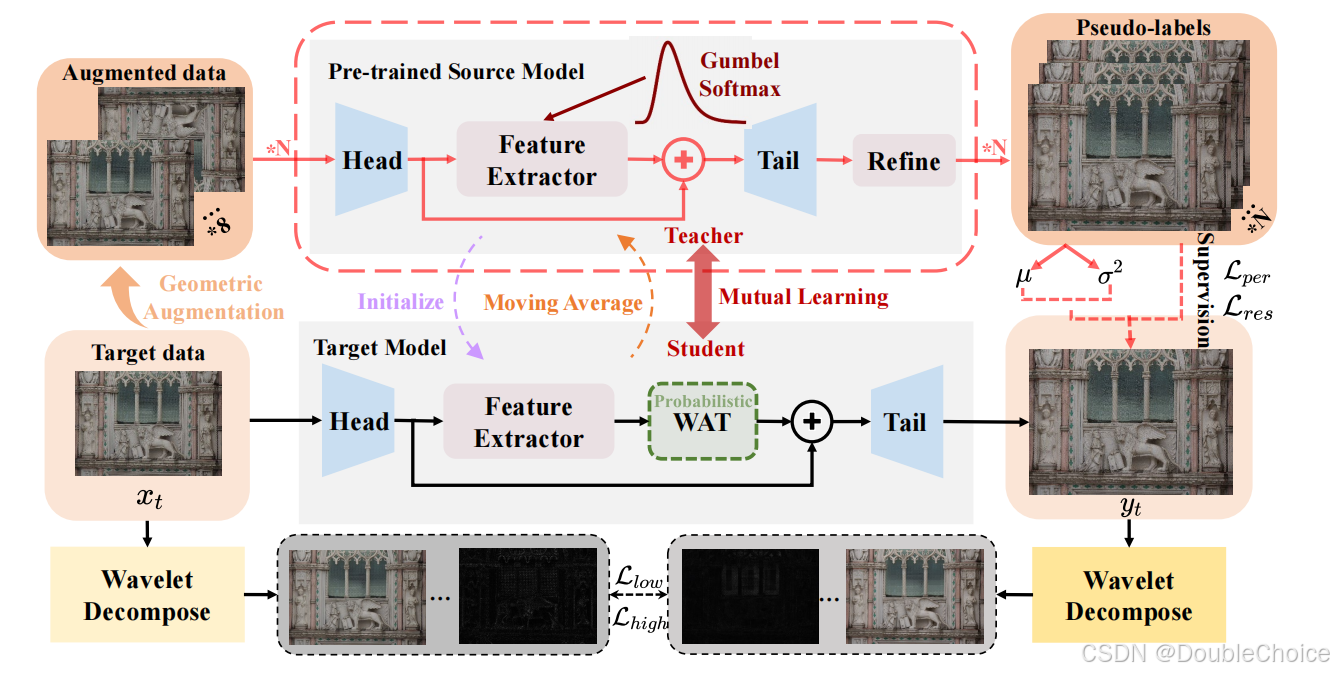
方法
-
教师-学生框架
使用教师模型生成伪标签,学生模型通过伪标签进行优化。教师模型参数通过指数移动平均(EMA)从学生模型更新,逐步传递目标域知识。 -
小波增强变换器(WAT)
-
多级小波分解:将特征分解为不同频率的子带,提取低频信息(内容)和高频信息(细节)。
-
批量增强注意力:在批次维度进行自注意力,隐式混合样本特征,增强低频信息的跨样本学习。
-
可变形注意力融合:通过多级特征交互,高效聚合跨层次信息。
-
几何增强:对输入图像进行翻转、旋转等几何变换,生成多视图伪标签并平均融合。
-
-
不确定性感知自训练机制
-
使用Gumbel-Softmax引入随机性,多次生成伪标签并计算均值和方差作为不确定性估计。
-
基于置信度图对伪标签进行加权损失计算,抑制不可靠预测的影响。
-
-
频域正则化约束
-
低频频谱L1损失:约束LR与SR图像的低频一致性。
-
高频对抗损失:通过判别器优化高频细节的真实性。
-
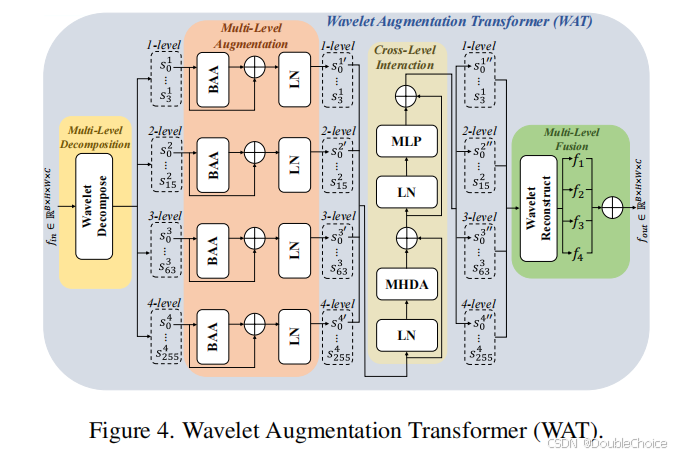
创新点
-
源自由域自适应框架(SODA-SR)
首次针对图像超分辨率提出无需源数据的域自适应方法,解决了实际场景中源数据不可访问的问题。 -
小波增强变换器(WAT)
-
通过小波分解与可变形注意力,自适应学习多级低频信息,增强模型对目标域特征的鲁棒性。
-
支持即插即用,无需额外推理成本。
-
-
不确定性感知伪标签修正
利用多次推理的统计不确定性估计,动态调整伪标签置信度,减少错误标签对训练的干扰。 -
跨域频域约束
结合低频频谱对齐与高频对抗学习,避免模型过拟合伪标签,提升重建结果的频域一致性。 -
架构无关性
方法不依赖特定网络结构,实验验证在多种骨干网络上均有效。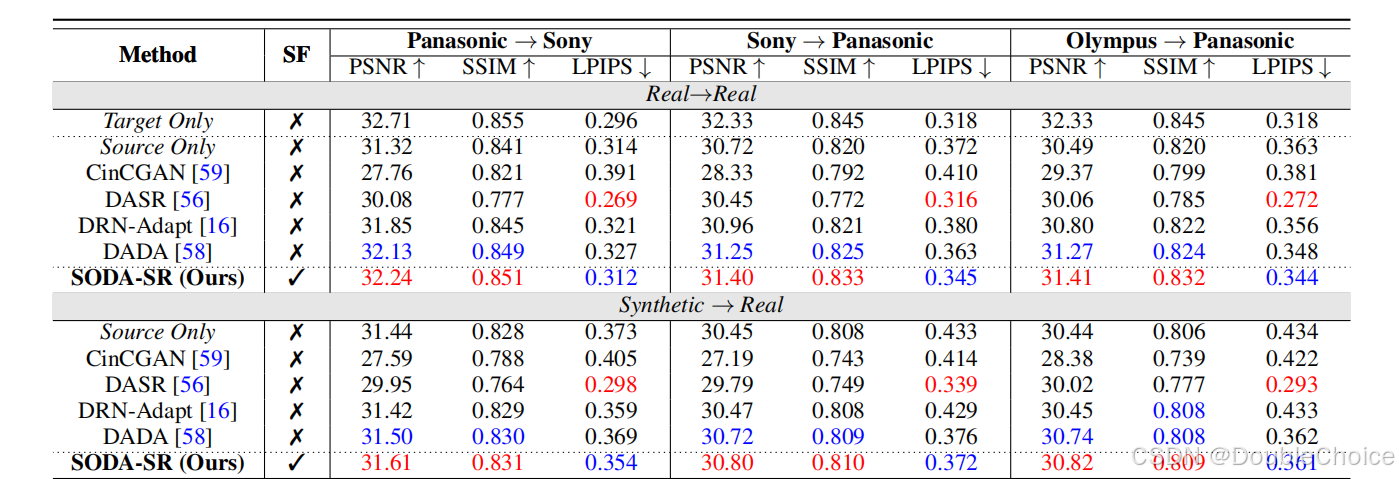
论文链接:https://arxiv.org/abs/2303.17783
二、Scattering Vision Transformer: Spectral Mixing Matters
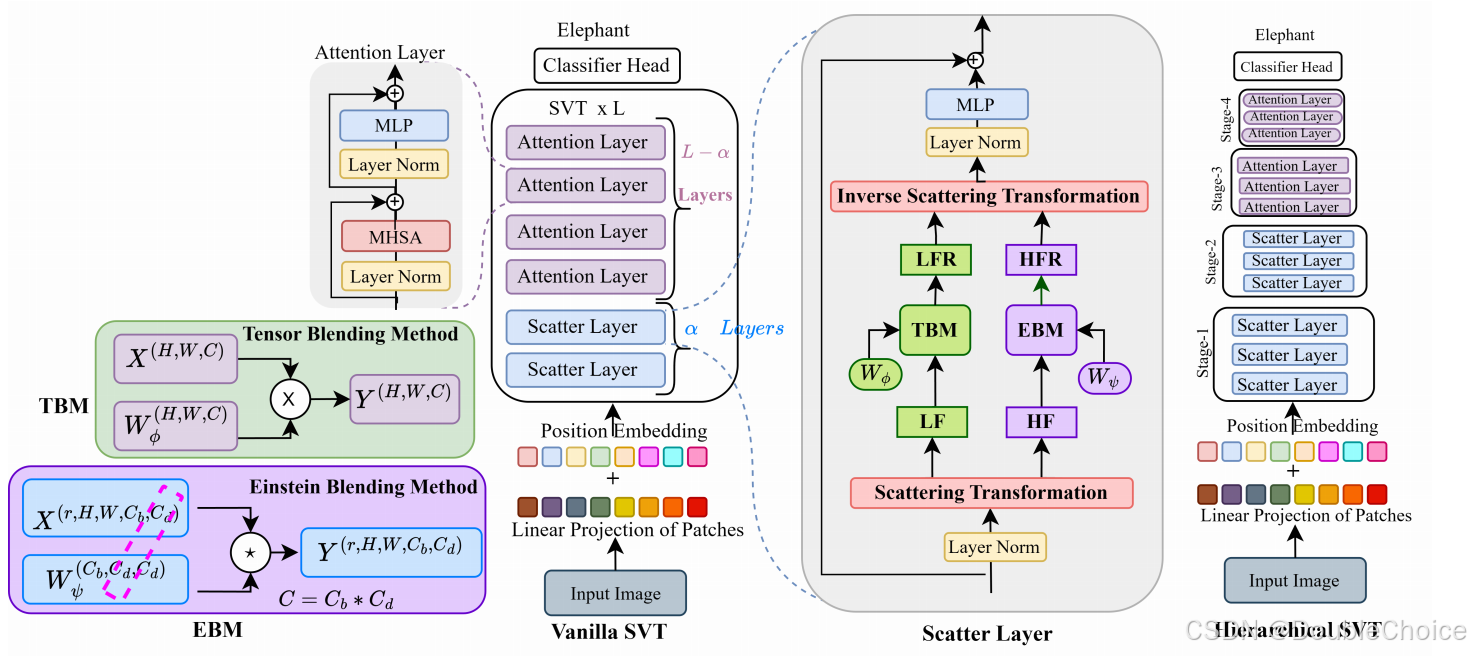
方法
-
散射变换分解
使用双树复小波变换将图像分解为低频成分和高频成分,保留更多方向性特征并提高可逆性。 -
谱门控网络(SGN)
-
低频处理(TBM):采用张量混合方法融合低频特征。
-
高频处理(EBM):提出爱因斯坦混合方法,通过通道混合和标记混合降低高频计算复杂度。
-
-
混合层次结构
前α层使用散射层,深层使用注意力层,平衡计算效率和特征表达能力。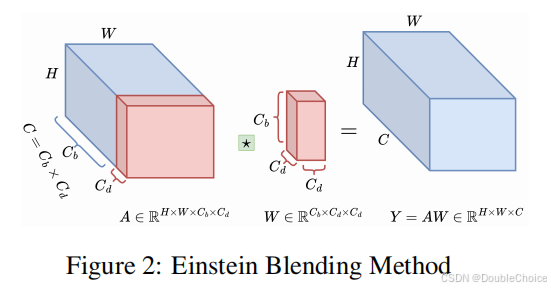
创新点
-
可逆频谱分解
首次将DTCWT引入视觉Transformer,通过六方向小波基函数实现更精细的频率分离,相比傅里叶变换/DWT减少重构误差。 -
高效频谱混合机制
提出Einstein Blending Method,将高频计算复杂度从降至,相比LiTv2参数量减少40%。 -
性能突破
-
在ImageNet上以54M参数达到85.7% Top-1准确率,FLOPs降低14%。
-
迁移学习任务准确率提升1.5-2.3%,推理延迟仅14.7ms,优于同规模Swin-T。
-
-
理论验证
通过PSNR和相位-幅值可视化证明DTCWT的优越方向选择性,支持模型对边缘/纹理特征的强捕捉能力。
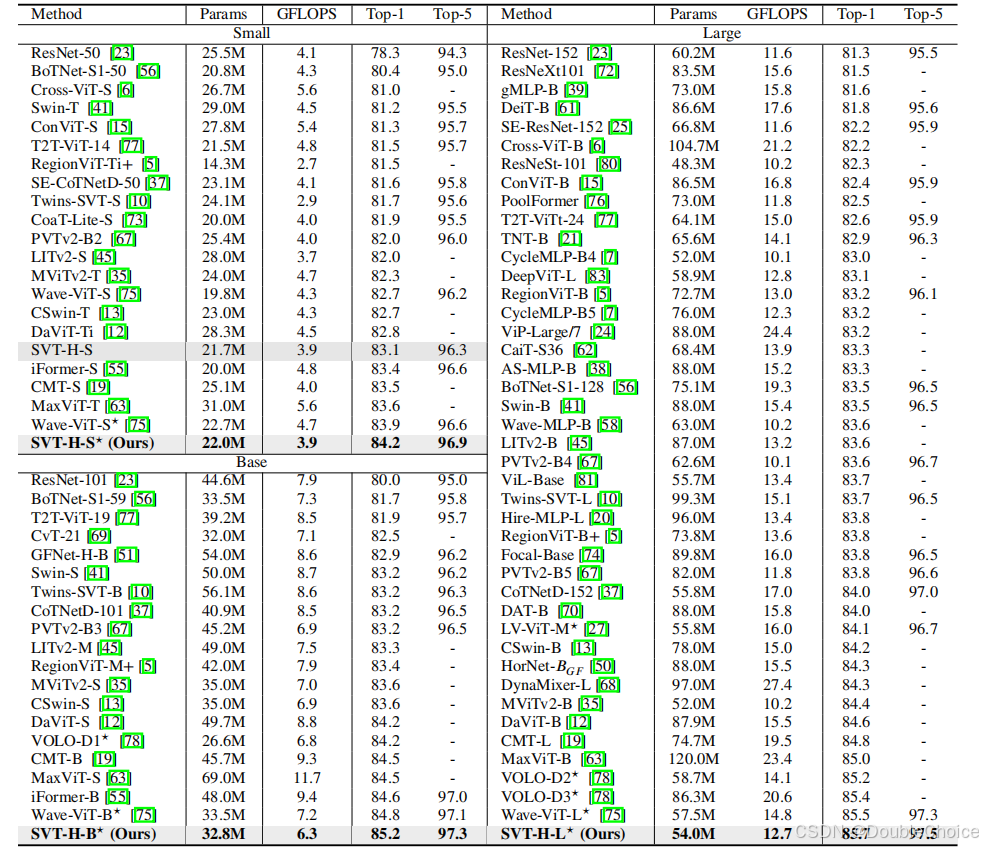
论文链接:https://arxiv.org/abs/2311.01310
点击【AI十八式】的主页,获取更多优质资源!


















 538
538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









