







PPO在LLM训练阶段是怎么实现RLHF的?
在自然语言处理任务中,利用强化学习来训练大语言模型(LLM)是一种常见的做法,尤其是在 强化学习与人类反馈(RLHF, Reinforcement Learning with Human Feedback) 的框架下。Proximal Policy Optimization (PPO) 是一种常用的强化学习算法,已广泛应用于LLM的训练,尤其是在RLHF的过程中。在这部分中,我们将详细介绍 PPO 是如何在 LLM 的训练阶段实现 RLHF 的。
RLHF的背景
RLHF 是一种将人类反馈融入强化学习的训练方法。它的基本思想是,通过人类的评分或偏好指导模型学习,优化其输出,以便模型能够生成符合人类预期和需求的结果。在 LLM 的训练中,RLHF 可以通过对模型的输出进行评分,从而让模型学习如何更好地与人类进行互动,生成更符合期望的答案。
PPO 在 RLHF 中的作用
在 RLHF 的场景下,PPO 算法的目标是优化一个 策略网络(Policy Network),该网络决定了给定输入时,模型输出的概率分布。在 PPO 中,策略网络 通过不断调整,以提高其生成符合人类期望输出的能力。
PPO 通过与环境(即人类反馈)交互,训练一个智能体来优化其输出策略。对于 LLM 来说,这个“智能体”是模型本身,而“环境”则是用户的反馈。例如,给定一个问题,LLM 会生成一个回答,并通过用户的反馈来评估答案的质量。这个反馈会作为奖励传递给 PPO,模型通过优化策略来提高未来生成更符合人类预期的答案。
PPO在RLHF中的示例
依然考虑上一篇中的grid world以便理解,假设每一个网格的相邻网格中都存在一个新的词汇,agent(LLM)进行的每一个action可视为LLM每一步的输出。
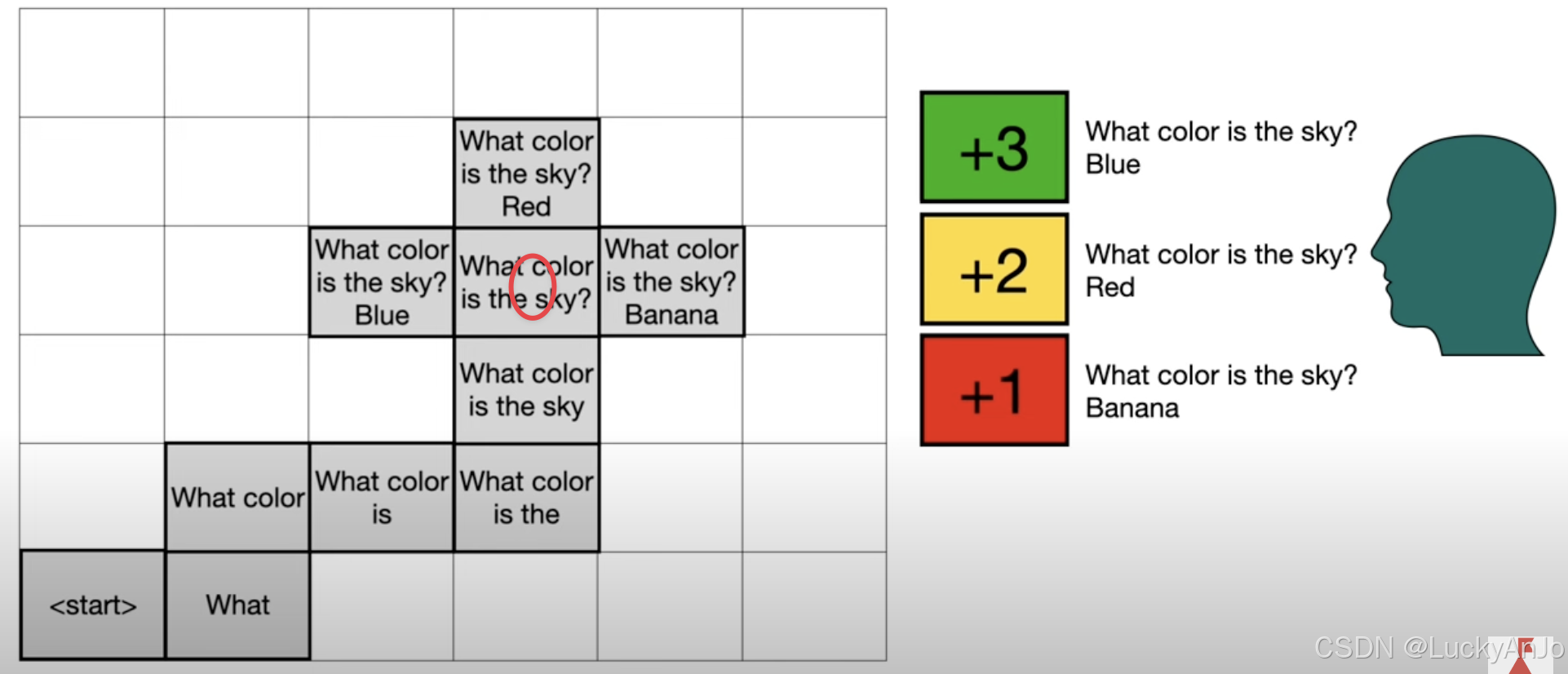
当LLM输出到红圈部分时,下一步存在三个可能的action,human expert将会对三个输出打分,以符合人类偏好(Blue>red>banana)。类似于PPO,通过训练value network与policy network来学习到经人类打分后的value与policy。具体训练流程参考
https://blog.youkuaiyun.com/2501_90713548/article/details/145750304?sharetype=blogdetail&sharerId=145750304&sharerefer=PC&sharesource=2501_90713548&spm=1011.2480.3001.8118
RLHF中的挑战与优势
挑战:
- 人类反馈的质量:RLHF 强烈依赖于人类反馈的质量。如果反馈数据不准确或不一致,可能会导致模型训练出现偏差。
- 探索与利用的平衡:尽管 PPO 能够平衡探索与利用,但在 RLHF 的情境中,如何处理探索与利用之间的微妙平衡仍然是一个挑战。
- 奖励稀疏性:在某些情况下,用户的反馈可能较为稀疏,即模型在生成回答后,用户并不会立即给予奖励。这样可能会影响策略网络的更新速度。
优势:
- 灵活性:RLHF 允许模型从多样化的用户反馈中学习,而不仅仅依赖于预设的标签数据。这为模型的生成能力提供了更多的灵活性。
- 模型定制:通过 RLHF,模型能够根据具体用户的需求进行微调,从而提供更加个性化的服务。
- 强化学习优势:通过强化学习的方式,模型不仅能够生成合理的答案,还能不断改进,并在新的情境下进行自我调整。
个人理解
实际上,RLHF 中的 人类反馈(HF) 体现在人类对模型输出的评价,即人类对模型生成的每个回答(策略)进行评分。这个评分其实可以视为模型策略的价值(Value)评估,通常这个评分反映了模型输出的质量与人类预期之间的匹配程度。
- 评分 = Value:人类的评分可以视为一个“奖励信号”,类似于强化学习中的 Value。这个评分反映了模型当前策略在给定任务中的表现。具体来说,Value Network 会使用这些评分来估计不同状态(或生成的回答)的价值。这些评分作为监督信号,用来训练 Value Network,使其更准确地预测模型在不同情境下的表现。
- 策略优化:通过将这些评分用于训练 Policy Network,模型会根据人类偏好来调整其策略,使得生成的回答越来越符合人类期望。策略网络的目标就是在给定状态下生成能获得高评分的动作(或回答)。
- Value Network 和 Policy Network 的相互作用:这两者通过人类的评分进行协同训练。Value Network 估计当前状态的价值,而 Policy Network 通过优化策略来提高生成高价值(高评分)答案的概率。最终,两个网络通过强化学习的方式,确保模型在生成回答时逐渐更好地符合人类偏好。
总结
PPO 在 LLM 训练中的 RLHF 实现,核心在于通过策略网络生成基于用户反馈的高质量输出,并通过优化代理目标函数来提升生成能力。PPO 的 Clipped Surrogate Objective 和 优势函数 的引入有效地确保了模型训练的稳定性,避免了训练过程中的剧烈波动。RLHF 提供了一种灵活的训练方式,使得 LLM 能够不断优化与人类的互动,最终提高模型的生成能力,使其更符合用户需求。

















 998
998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









