







背景介绍
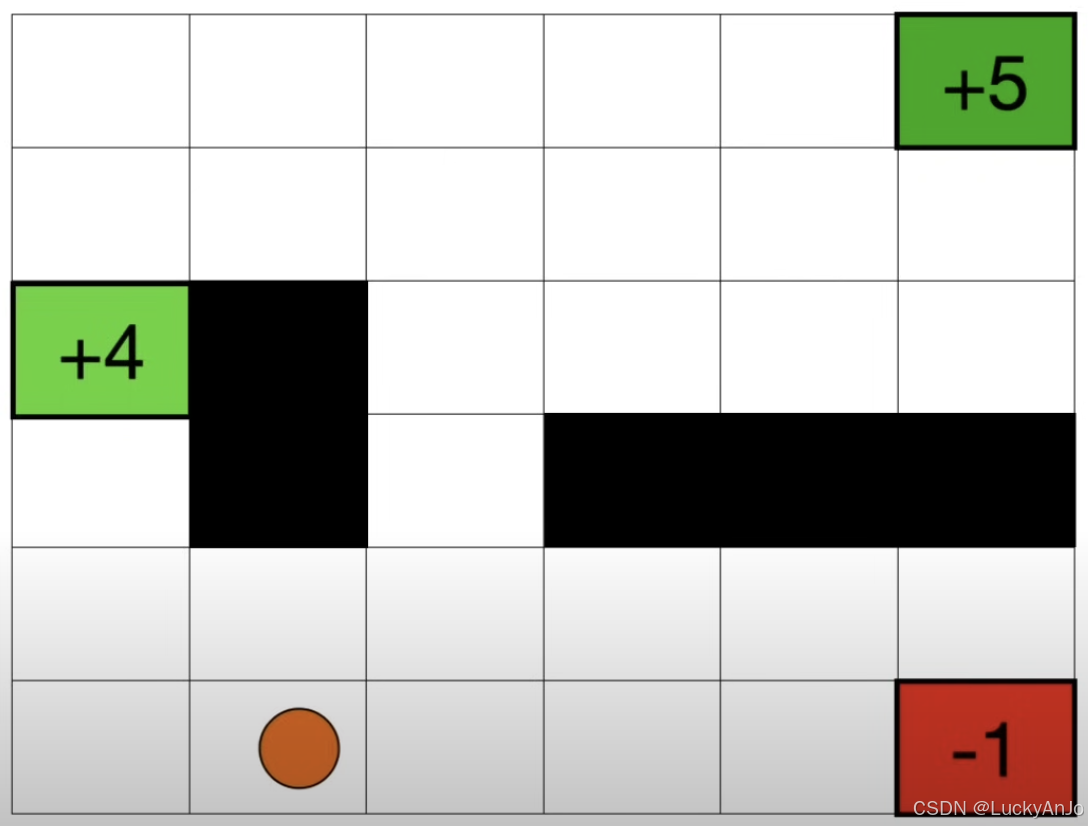
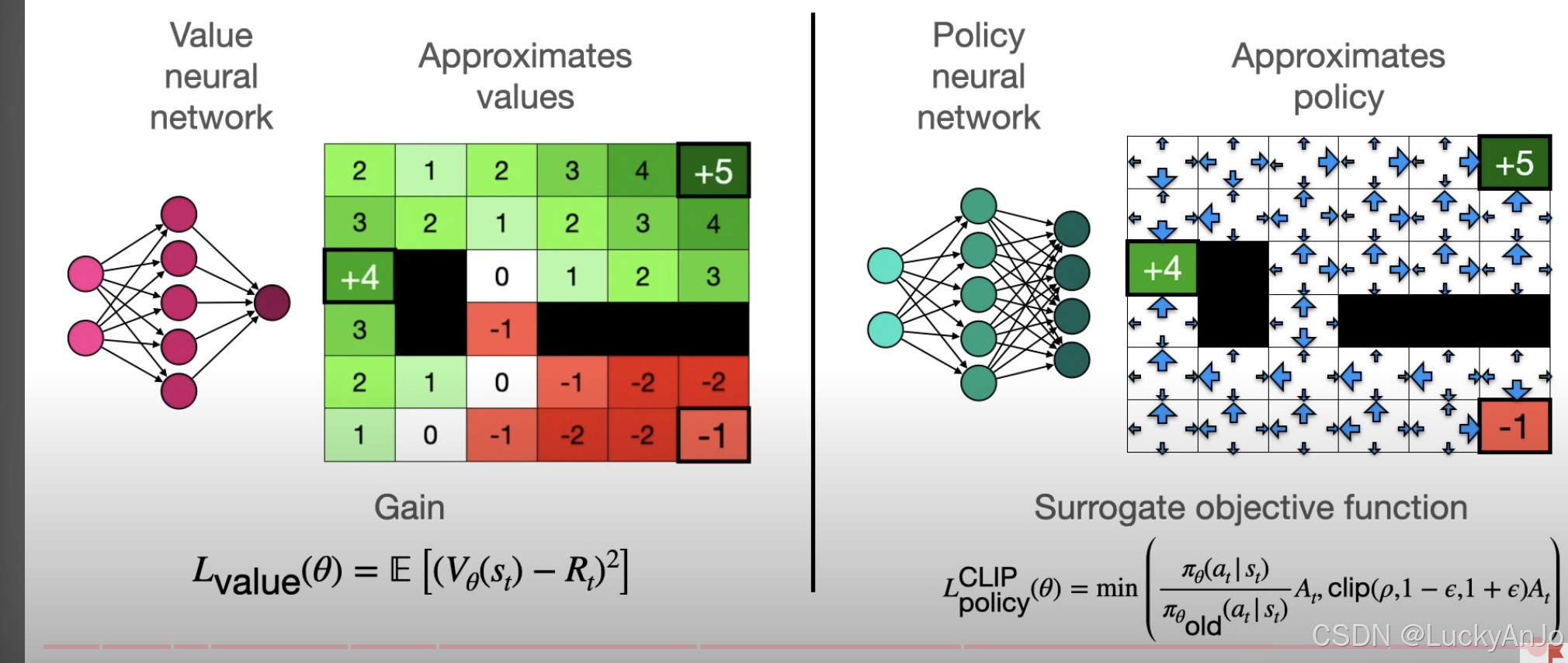
考虑一个网格迷宫游戏,智能体(Agent)初始位于网格中的一个随机位置,可以执行上下左右的移动动作。网格中存在障碍物、宝藏以及陷阱。智能体的目标是通过探索网格,获得最大得分。
预备知识
状态(State)
状态表示智能体在网格中的位置,用坐标 s t = ( x , y ) s_t = (x, y) st=(x,y) 来表示,其中 x x x 和 y y y 分别为智能体在网格中的横纵坐标。例如,在一个 6 × 6 6\times 6 6×6 的网格中,状态空间包含 36 个可能的位置(状态)。

价值(Value)
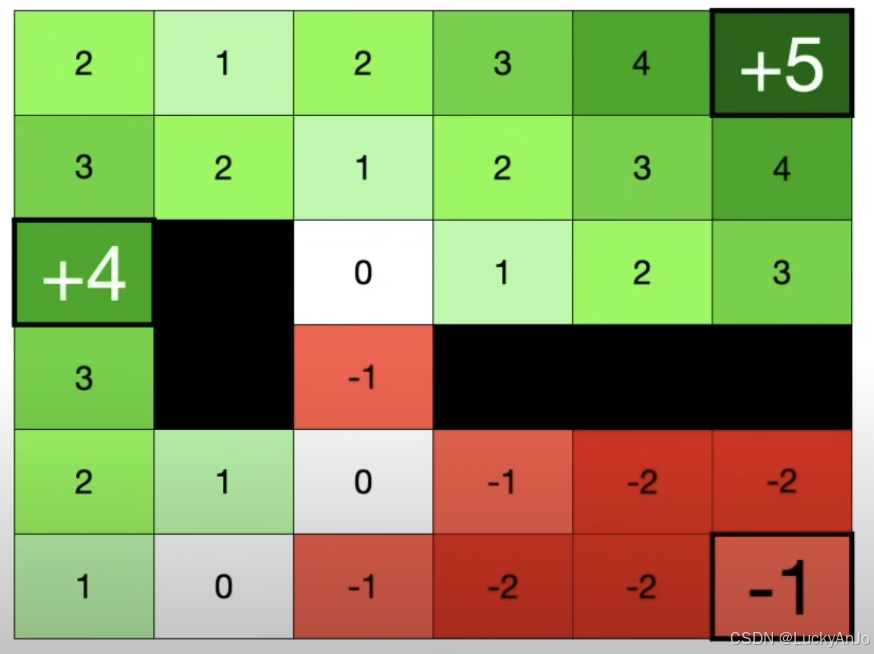
价值 V ( s t ) V(s_t) V(st) 表示在状态 s t s_t st 下,智能体未来能够获得的累积奖励的期望值。例如,如果智能体每移动一步会获得 − 1 -1 −1 的奖励,则整个网格的价值分布可以通过动态规划或蒙特卡洛方法计算。
然而,当网格空间较大时,直接计算每个状态的价值可能会非常耗时,因此通常采用 价值网络(Value Network) 来近似估计状态的价值。
动作与策略(Action and Policy)
动作 a t a_t at 表示智能体在状态 s t s_t st 下执行的具体行为(如上下左右移动)。策略 π ( a t ∣ s t ) \pi(a_t \mid s_t) π(at∣st) 是一个概率分布,表示在状态 s t s_t st 下选择动作 a t a_t at 的概率。一个好的策略能够引导智能体向价值更高的状态移动。
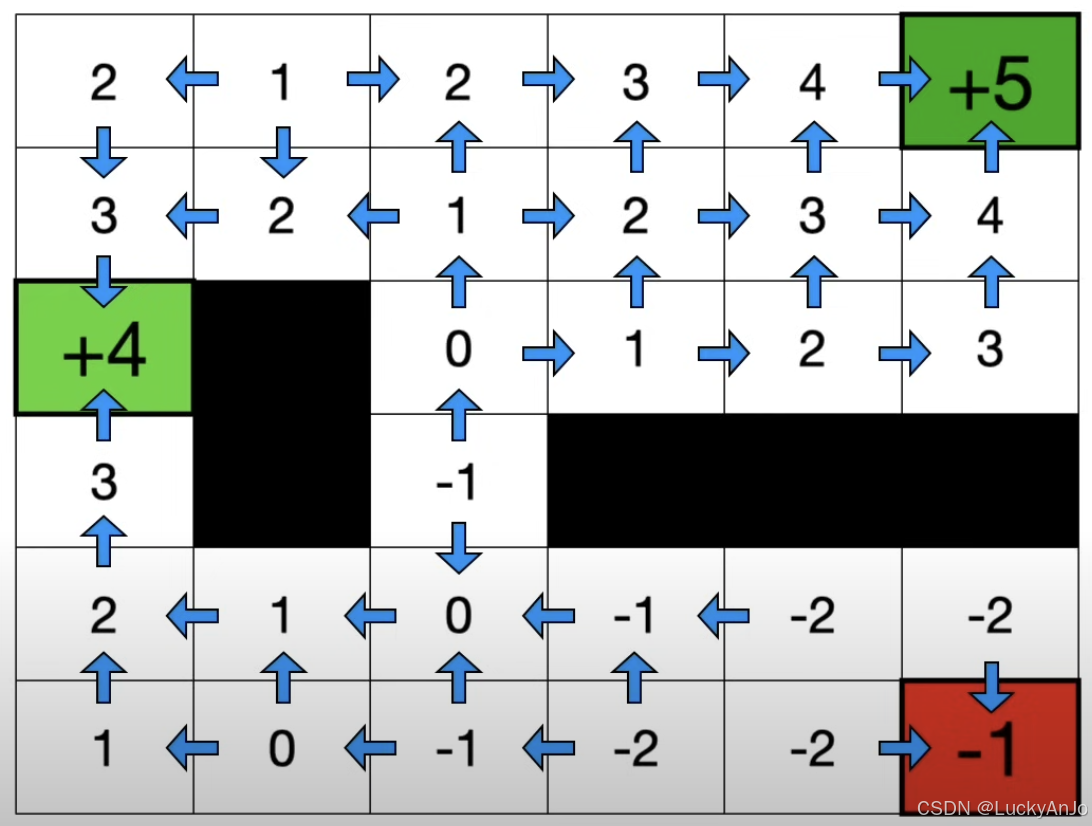
然而,纯粹的贪婪策略可能导致智能体在探索过程中陷入局部最优解,因此通常需要通过 策略网络(Policy Network) 来平衡探索与利用。
PPO 基本流程
PPO(Proximal Policy Optimization)是一种基于策略梯度的强化学习算法,其核心思想是通过限制策略更新的幅度,确保训练过程的稳定性。PPO 的基本流程如下:
- 初始化:初始化环境、策略网络(Actor)和价值网络(Critic)。
- 数据收集:智能体与环境交互,生成轨迹数据。
- 计算优势函数:基于轨迹数据计算每个状态的优势值。
- 更新策略与价值网络:通过优化代理目标函数更新网络参数。
- 迭代:重复上述步骤,直到策略收敛。
1. 价值网络训练(Value Network)
价值网络 V θ ( s ) V_\theta(s) Vθ(s) 的目标是近似每个状态 s t s_t st 的价值 V ( s t ) V(s_t) V(st)。其训练过程如下:
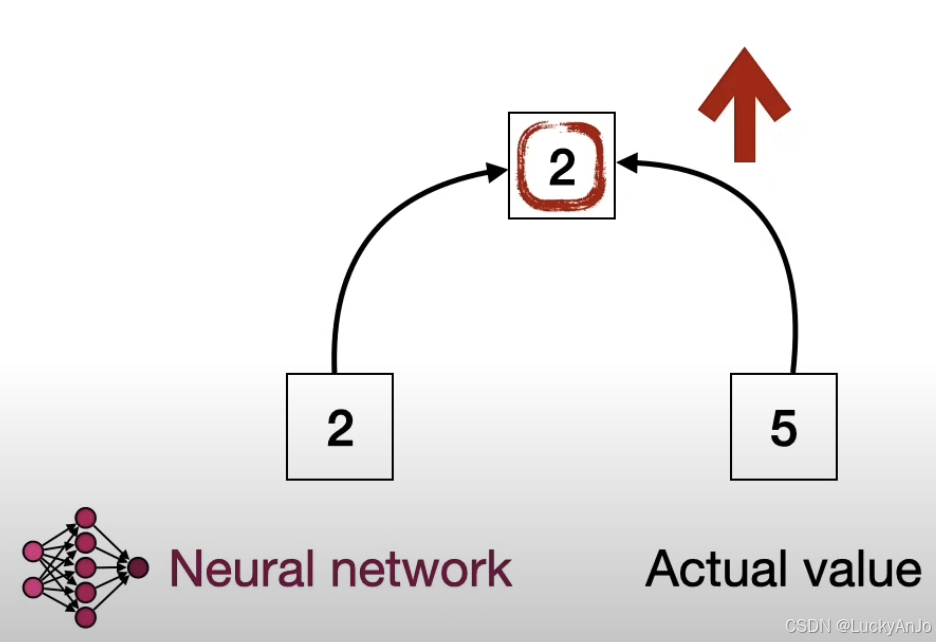
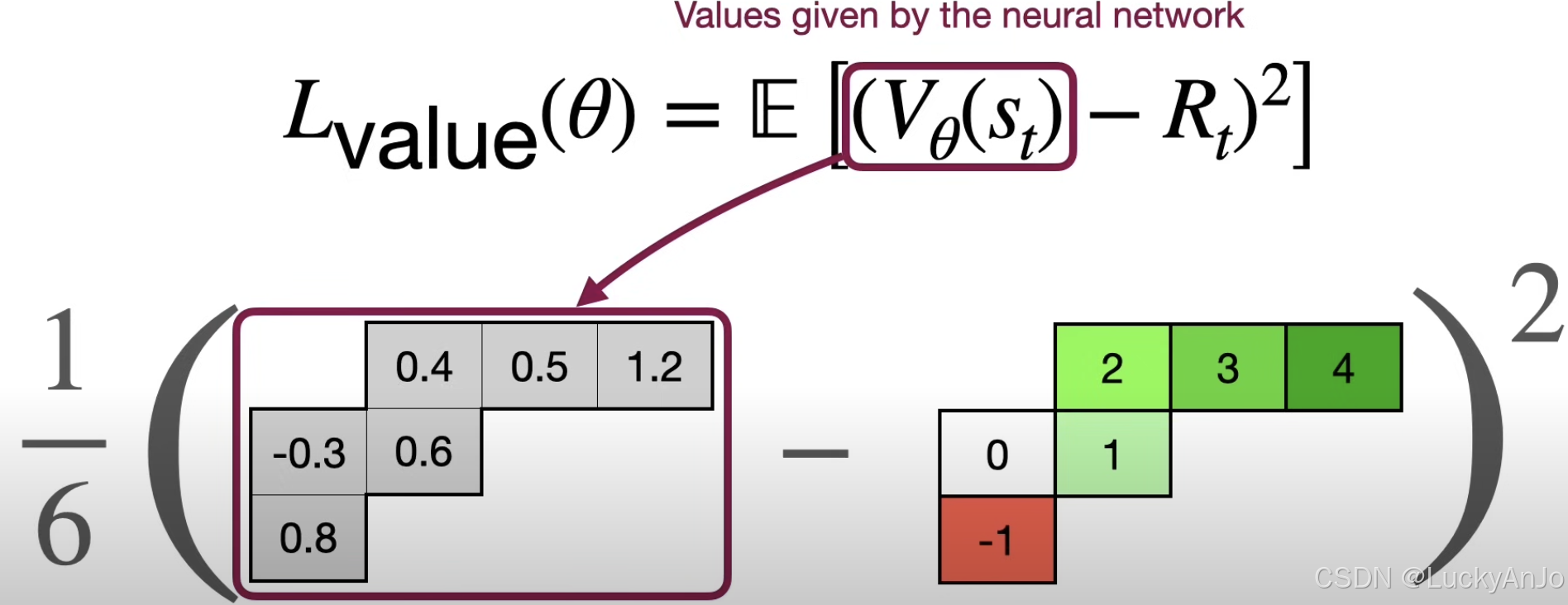
针对某个状态 s t s_t st,初始化的价值网络可能估计为 V θ ( s t ) = 2 V_{\theta}(s_t) = 2 Vθ(st)=2,但实际上,真实的目标值是 R t = 5 R_t = 5 Rt=5,即价值网络低估了该状态的价值,二者的差值 V θ ( s t ) − R t = 2 − 5 = − 3 V_{\theta}(s_t) - R_t = 2 - 5 = -3 Vθ(st)−Rt=2−5=−3,这个差值通常作为损失函数的一部分,用于更新网络参数。
针对一条轨迹
(
s
t
,
.
.
.
,
s
t
+
6
)
(s_t, ..., s_{t+6})
(st,...,st+6) 来说,价值网络会估计出一组价值
(
v
t
,
.
.
.
,
v
t
+
6
)
(v_t, ..., v_{t+6})
(vt,...,vt+6),那么此轮循环中用于更新价值网络的 loss:
L
value
(
θ
)
=
E
[
(
V
θ
(
s
t
)
−
R
t
)
2
]
L_{\text{value}}(\theta) = \mathbb{E} \left[ \left( V_{\theta}(s_t) - R_t \right)^2 \right]
Lvalue(θ)=E[(Vθ(st)−Rt)2]
-
目标值计算:对于一条轨迹 ( s t , a t , r t , s t + 1 , … ) (s_t, a_t, r_t, s_{t+1}, \dots) (st,at,rt,st+1,…),目标值 R t R_t Rt 是未来累积折扣奖励:
R t = ∑ k = 0 T − t γ k r t + k R_t = \sum_{k=0}^{T-t} \gamma^k r_{t+k} Rt=k=0∑T−tγkrt+k
其中, γ \gamma γ 是折扣因子(通常取 γ = 0.99 \gamma = 0.99 γ=0.99), r t + k r_{t+k} rt+k 是在时刻 t + k t+k t+k 获得的奖励。
为什么需要折扣因子?
首先,考虑这个式子:
R
t
=
∑
k
=
0
T
−
t
γ
k
r
t
+
k
R_t = \sum_{k=0}^{T-t} \gamma^k r_{t+k}
Rt=k=0∑T−tγkrt+k
其中:
•
R
t
R_t
Rt 是从时刻
t
t
t 开始的未来累积奖励(即未来的期望回报)。
•
r
t
+
k
r_{t+k}
rt+k 是在时刻
t
+
k
t+k
t+k 获得的即时奖励。
•
γ
\gamma
γ 是 折扣因子,它控制着未来奖励的重要性。
折扣因子 γ \gamma γ 用于调节 未来奖励的权重。在强化学习中,智能体不仅考虑当前的奖励,还需要考虑未来的奖励。如果没有折扣因子,未来奖励就会和当前奖励一样重要,这样就可能导致智能体过于关注远期奖励,忽视了当前的行动。而通常情况下,智能体对远期奖励的兴趣逐渐降低——这时就需要折扣因子来 折扣 未来奖励。
具体来说:
•
γ
=
1
\gamma = 1
γ=1:没有折扣因子,智能体会完全关注未来奖励,这会导致对长期结果的高度依赖。
•
γ
=
0
\gamma = 0
γ=0:智能体只关注即时奖励,不考虑未来的奖励。
•
0
<
γ
<
1
0 < \gamma < 1
0<γ<1:这是最常见的情况,智能体会部分考虑未来奖励,但会逐渐降低对远期奖励的重视,通常在实际应用中,
γ
\gamma
γ 的值设置为 0.99 或 0.9,这样可以确保智能体在训练时考虑到适当的长期回报。
-
损失函数:价值网络的损失函数为均方误差(MSE):
L value ( θ ) = E [ ( V θ ( s t ) − R t ) 2 ] L_{\text{value}}(\theta) = \mathbb{E} \left[ (V_\theta(s_t) - R_t)^2 \right] Lvalue(θ)=E[(Vθ(st)−Rt)2]
通过最小化该损失函数,价值网络逐渐学会准确估计每个状态的价值。
2. 策略网络训练(Policy Network)
策略网络 π θ ( a t ∣ s t ) \pi_\theta(a_t \mid s_t) πθ(at∣st) 的目标是生成动作的概率分布。在强化学习的训练过程中,策略网络的任务是学会从给定状态 s t s_t st 中选择一个最优的动作。策略网络通过与价值网络(Critic)配合,更新智能体的行为策略,从而最大化累积奖励。
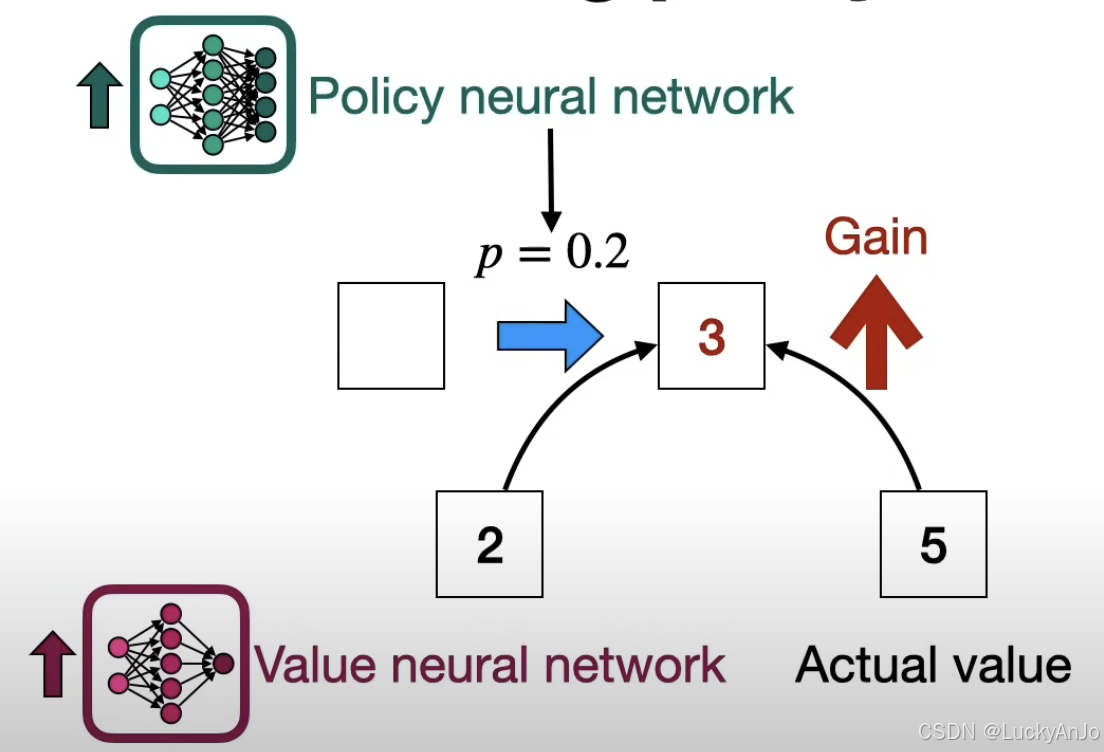
在策略网络训练中,我们遇到的问题是,价值网络可能会低估某些状态的价值,导致策略网络做出次优的决策。举个例子,对于某个状态 s t s_t st,价值网络可能会低估该状态的价值 V ( s t ) V(s_t) V(st)。同时,策略网络可能对某个动作(例如向右移动)给予过低的选择概率。例如,在状态 s t − 1 s_{t-1} st−1,策略网络估计 π θ old ( a t ∣ s t ) \pi_{\theta_{\text{old}}}(a_t \mid s_t) πθold(at∣st) 只有 0.2 的概率选择向右前进。这说明,两个网络都低估了向右移动可能带来的回报。为了纠正这种低估,策略网络需要通过策略梯度更新来调整其行为,从而更好地与价值网络配合。
- 重要性采样比
在 PPO 中,更新策略时需要考虑 新旧策略的差异,这时需要引入 重要性采样比,即:
r
t
(
θ
)
=
π
θ
(
a
t
∣
s
t
)
π
θ
old
(
a
t
∣
s
t
)
r_t(\theta) = \frac{\pi_\theta(a_t \mid s_t)}{\pi_{\theta_{\text{old}}}(a_t \mid s_t)}
rt(θ)=πθold(at∣st)πθ(at∣st)
其中,
π
θ
old
\pi_{\theta_{\text{old}}}
πθold 是旧策略,
π
θ
\pi_\theta
πθ 是当前策略。这个比值用于衡量新策略相较于旧策略在某一状态下选择某一动作的可能性。通过这个比值,PPO 可以修正新旧策略之间的差异,确保训练时不会因为策略更新过大而导致训练不稳定。
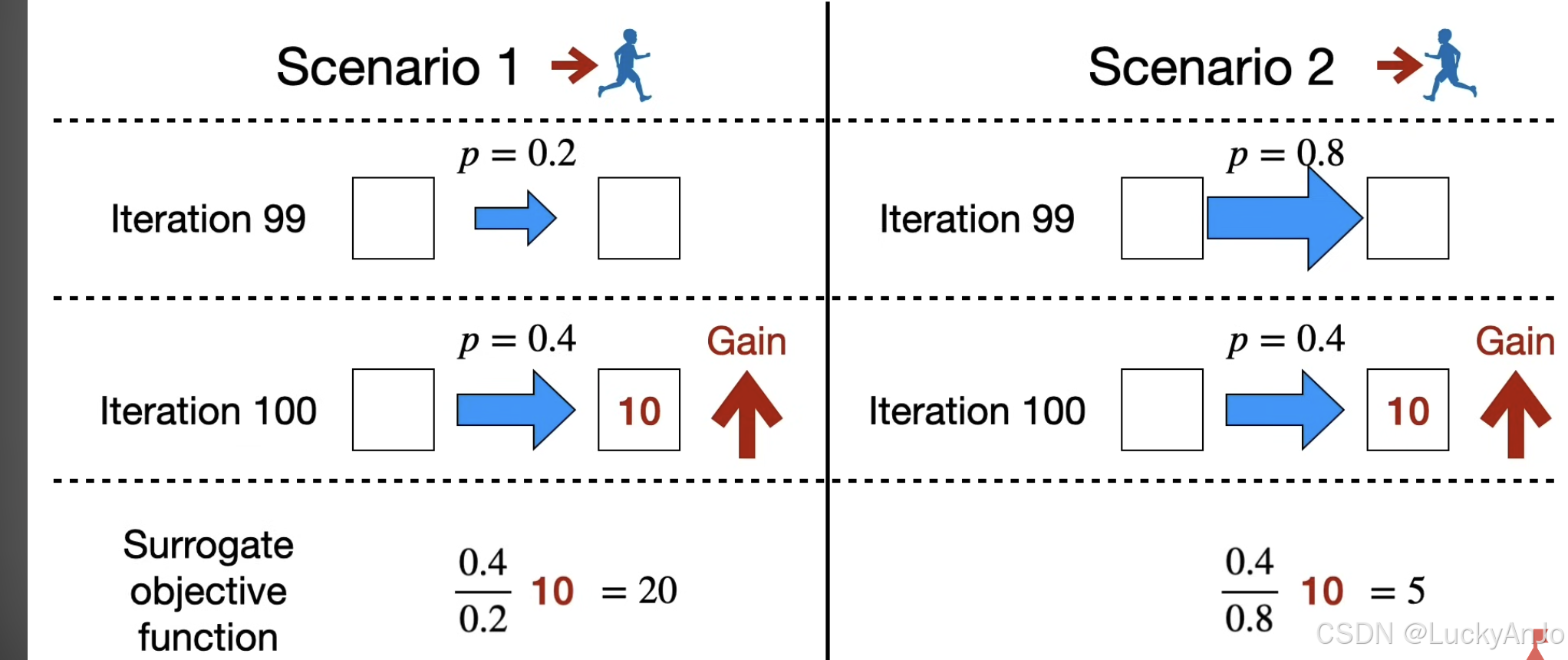
例如,假设智能体在状态
s
t
s_t
st 下选择向右移动的概率在旧策略中是
0.3
0.3
0.3,而在新策略中是
0.5
0.5
0.5。此时,重要性采样比
r
t
(
θ
)
r_t(\theta)
rt(θ) 计算如下:
r
t
(
θ
)
=
π
θ
(
a
t
∣
s
t
)
π
θ
old
(
a
t
∣
s
t
)
=
0.4
0.2
=
2
r_t(\theta) = \frac{\pi_\theta(a_t \mid s_t)}{\pi_{\theta_{\text{old}}}(a_t \mid s_t)} = \frac{0.4}{0.2} = 2
rt(θ)=πθold(at∣st)πθ(at∣st)=0.20.4=2
这个比值表示新策略选择向右的概率相对于旧策略增加了 2 倍。通过这个比值,PPO 可以调整策略,使得训练过程更加平稳。
- 优势函数(Advantage Function)
在 PPO 中,优势函数
A
t
A_t
At 用于衡量某一动作相对于当前状态价值的“优势”。通过优势函数,策略网络能够知道某个动作在当前状态下相较于平均水平是否更好。优势函数的计算通常通过 广义优势估计(GAE) 来实现:
A
t
=
∑
k
=
0
T
−
t
(
γ
λ
)
k
δ
t
+
k
A_t = \sum_{k=0}^{T-t} (\gamma \lambda)^k \delta_{t+k}
At=k=0∑T−t(γλ)kδt+k
其中,
δ
t
=
r
t
+
γ
V
(
s
t
+
1
)
−
V
(
s
t
)
\delta_t = r_t + \gamma V(s_{t+1}) - V(s_t)
δt=rt+γV(st+1)−V(st),表示当前奖励加上折扣后的未来状态价值与当前状态价值之间的差异。
γ
\gamma
γ 是折扣因子,
λ
\lambda
λ 是平滑系数。优势函数
A
t
A_t
At 可以帮助策略网络在状态下选择更有价值的动作。
假设智能体当前在状态 s t s_t st,价值网络估计当前状态的价值 V ( s t ) = 3 V(s_t) = 3 V(st)=3,并且智能体向右移动(动作 a t a_t at)后,得到的奖励是 r t = 2 r_t = 2 rt=2,并且下一状态的价值估计为 V ( s t + 1 ) = 4 V(s_{t+1}) = 4 V(st+1)=4。
此时,优势函数
A
t
A_t
At 可以通过广义优势估计(GAE)来计算:
δ
t
=
r
t
+
γ
V
(
s
t
+
1
)
−
V
(
s
t
)
=
2
+
0.99
×
4
−
3
=
3.96
\delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) = 2 + 0.99 \times 4 - 3 = 3.96
δt=rt+γV(st+1)−V(st)=2+0.99×4−3=3.96
如果在这一情况下,优势函数为
A
t
=
3.96
A_t = 3.96
At=3.96,说明向右移动相对于其他动作有很大的优势,策略网络应当增加向右的选择概率。
-
代理目标函数:PPO 使用 Clipped Surrogate Objective 来限制策略更新的幅度。具体形式如下:
L policy ( θ ) = E [ min ( r t ( θ ) A t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A t ) ] L_{\text{policy}}(\theta) = \mathbb{E} \left[ \min \left( r_t(\theta) A_t, \text{clip} \left( r_t(\theta), 1 - \epsilon, 1 + \epsilon \right) A_t \right) \right] Lpolicy(θ)=E[min(rt(θ)At,clip(rt(θ),1−ϵ,1+ϵ)At)]
其中, ϵ \epsilon ϵ 是裁剪阈值(如 ϵ = 0.2 \epsilon = 0.2 ϵ=0.2),用于防止更新幅度过大。
3.Clip
PPO 的核心创新在于引入了 Clipped Surrogate Objective,其作用是限制策略更新的幅度,避免训练不稳定。具体来说,当新旧策略的比值 r t ( θ ) r_t(\theta) rt(θ) 超出范围 [ 1 − ϵ , 1 + ϵ ] [1 - \epsilon, 1 + \epsilon] [1−ϵ,1+ϵ] 时,裁剪操作会将其限制在该范围内。
当新旧策略的比值过大或过小时,会导致训练不稳定。因此,PPO 使用裁剪操作(Clip)来限制新旧策略的比值,使其维护在一个范围内。
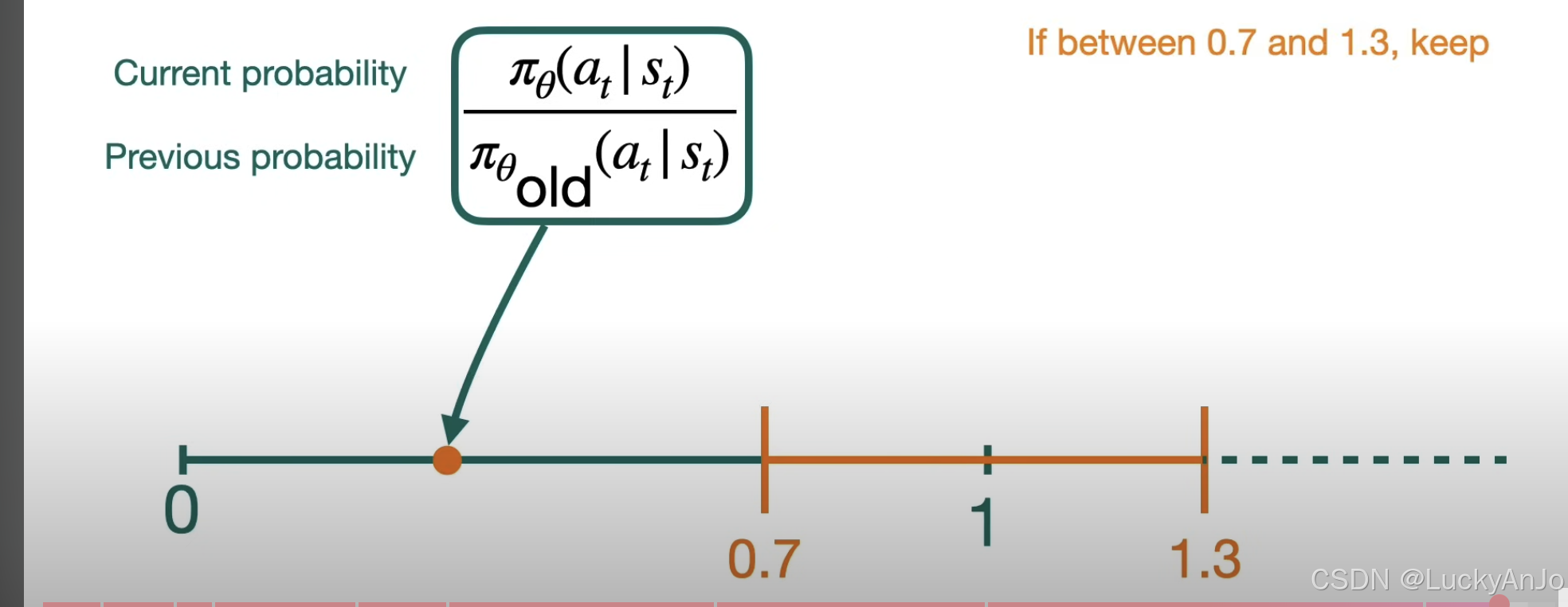
- 为什么需要 Clip 操作?
在强化学习中,策略梯度算法(如 REINFORCE)通常会计算当前策略与旧策略之间的差异,并使用这一差异来调整策略。为了确保训练稳定,更新幅度不能过大。但如果直接使用该差异更新策略,可能会导致策略跳跃式变化,从而影响学习过程,甚至导致性能下降。
Clip 操作的目的就是解决这个问题。它通过限制策略更新幅度,防止过度的策略更新影响训练过程。
- Clip 操作的实现
在 PPO 中,Clip 操作通过 重要性采样比 来调整新旧策略的差异。给定一个状态
s
t
s_t
st 和对应的动作
a
t
a_t
at,新策略和旧策略的比值
r
t
(
θ
)
r_t(\theta)
rt(θ) 计算如下:
r
t
(
θ
)
=
π
θ
(
a
t
∣
s
t
)
π
θ
old
(
a
t
∣
s
t
)
r_t(\theta) = \frac{\pi_\theta(a_t \mid s_t)}{\pi_{\theta_{\text{old}}}(a_t \mid s_t)}
rt(θ)=πθold(at∣st)πθ(at∣st)
如果这个比值
r
t
(
θ
)
r_t(\theta)
rt(θ) 超出了一个设定的裁剪阈值
ϵ
\epsilon
ϵ(例如,
ϵ
=
0.2
\epsilon = 0.2
ϵ=0.2),就会进行裁剪操作。裁剪操作的具体形式是:
clip
(
r
t
(
θ
)
,
1
−
ϵ
,
1
+
ϵ
)
\text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon)
clip(rt(θ),1−ϵ,1+ϵ)
即:
- 如果 r t ( θ ) < 1 − ϵ r_t(\theta) < 1 - \epsilon rt(θ)<1−ϵ,则将其设置为 1 − ϵ 1 - \epsilon 1−ϵ
- 如果 r t ( θ ) > 1 + ϵ r_t(\theta) > 1 + \epsilon rt(θ)>1+ϵ,则将其设置为 1 + ϵ 1 + \epsilon 1+ϵ
- 如果 r t ( θ ) r_t(\theta) rt(θ) 在 [ 1 − ϵ , 1 + ϵ ] [1 - \epsilon, 1 + \epsilon] [1−ϵ,1+ϵ] 范围内,保持不变
Clip 的作用
- 防止过度优化:Clip 操作防止了大幅度的策略更新,从而避免了训练过程中的震荡或不稳定。
- 提高训练稳定性:通过限制新旧策略之间的差异,PPO 能够更平稳地优化策略,提升训练的可靠性。
- 简化实现:与其他基于 KL 散度约束的算法(如 TRPO)相比,PPO 的 Clip 操作更为简单高效,实现起来更加容易。
3. 代理目标函数(Surrogate Objective Function)
PPO 算法的核心创新之一是引入了 Clipped Surrogate Objective,其作用是通过限制策略更新的幅度,防止训练过程中出现不稳定的情况。代理目标函数用于衡量当前策略的好坏,并通过优化该目标来更新策略。
在 PPO 中,代理目标函数的具体形式如下:
L
P
P
O
(
θ
)
=
E
[
min
(
r
t
(
θ
)
A
t
,
clip
(
r
t
(
θ
)
,
1
−
ϵ
,
1
+
ϵ
)
A
t
)
]
L^{PPO}(\theta) = \mathbb{E} \left[ \min \left( r_t(\theta) A_t, \text{clip} \left( r_t(\theta), 1 - \epsilon, 1 + \epsilon \right) A_t \right) \right]
LPPO(θ)=E[min(rt(θ)At,clip(rt(θ),1−ϵ,1+ϵ)At)]
其中:
- r t ( θ ) = π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) r_t(\theta) = \frac{\pi_{\theta}(a_t \mid s_t)}{\pi_{\theta_{\text{old}}}(a_t \mid s_t)} rt(θ)=πθold(at∣st)πθ(at∣st) 表示新旧策略的比值,称为 重要性采样比。它衡量了当前策略与旧策略在选择动作 a t a_t at 时的差异。
- A t A_t At 是 优势函数,表示动作 a t a_t at 相对于当前策略的平均水平的优势,反映了某个动作的相对好坏。
- Clip 操作:当重要性采样比 r t ( θ ) r_t(\theta) rt(θ) 超出设定的范围 [ 1 − ϵ , 1 + ϵ ] [1 - \epsilon, 1 + \epsilon] [1−ϵ,1+ϵ] 时,裁剪操作会限制其在该范围内,从而防止策略更新过大。
3.1 代理目标函数的作用
PPO 通过最小化代理目标函数来优化策略。在更新策略时,代理目标函数的目标是最大化 优势函数 A t A_t At 与重要性采样比的乘积。使用 Clip 操作 后,若重要性采样比超出限制范围,则会裁剪它,防止策略更新过大。
例如,当 r t ( θ ) = 1.5 r_t(\theta) = 1.5 rt(θ)=1.5 且裁剪阈值 ϵ = 0.2 \epsilon = 0.2 ϵ=0.2 时,裁剪操作会将 r t ( θ ) r_t(\theta) rt(θ) 限制在 [ 1 − ϵ , 1 + ϵ ] = [ 0.8 , 1.2 ] [1 - \epsilon, 1 + \epsilon] = [0.8, 1.2] [1−ϵ,1+ϵ]=[0.8,1.2] 的范围内,因此裁剪后的比值为 1.2 1.2 1.2。
3.2 代理目标函数的优化
代理目标函数的优化过程包括:
- 计算重要性采样比 r t ( θ ) r_t(\theta) rt(θ):衡量新旧策略之间的差异。
- 计算优势函数 A t A_t At:评估动作 a t a_t at 相对于其他动作的好坏。
- 使用 Clip 操作:限制新旧策略比值的范围,防止过大的更新幅度。
- 通过优化代理目标函数:根据上述计算的 r t ( θ ) r_t(\theta) rt(θ) 和 A t A_t At 更新策略。
通过最小化代理目标函数,PPO 使策略的更新在合理的范围内进行,从而保证了训练的稳定性和有效性。
总结
PPO(Proximal Policy Optimization)算法通过限制策略更新幅度,提供了一种更加稳定和高效的强化学习方法。在网格迷宫游戏中,智能体可以利用PPO算法平衡探索和利用,从而逐步学习到优化的行动策略。通过结合 价值网络 和 策略网络,PPO 能够有效地处理复杂的状态空间和动作空间,提高智能体在环境中的表现。

















 1047
1047

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









