






ResNet-101 是一种深度卷积神经网络(CNN),属于残差网络(Residual Network)系列。它在许多计算机视觉任务中表现出色,比如图像分类、目标检测等。以下是 ResNet-101 网络的详细介绍:
1. 背景与目标
ResNet-101 是由 Kaiming He 等人在 2015 年提出的 ResNet(Residual Network)中的一个变种。其主要创新是引入了残差学习(Residual Learning)的方法,这使得网络可以更深而不容易出现梯度消失或梯度爆炸的问题,从而提升了网络的表现力和训练效率。
2. 网络结构
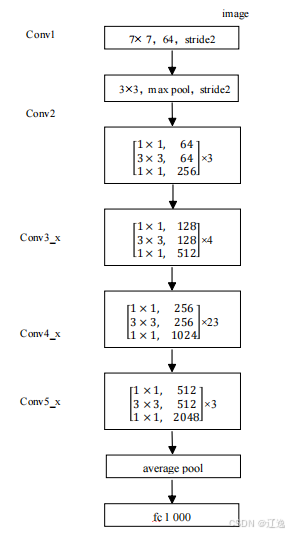
基本构建块
-
残差块(Residual Block):ResNet-101 使用的主要构建块是 Bottleneck 残差块。每个 Bottleneck 块包含三个卷积层:
- 1x1 卷积:用于降低维度。
- 3x3 卷积:用于提取特征。
- 1x1 卷积:用于恢复维度。
这些卷积层被 Batch Normalization 和 ReLU 激活函数所包围。残差块的输出与输入通过加法操作进行融合,形成最终的块输出。
网络层次
-
输入层:通常是一个大尺寸的卷积层(例如 7x7 卷积,步幅为 2)和一个最大池化层。
-
四个阶段(Stages):
- Layer 1:由若干个 Bottleneck 残差块组成,通常有 3 个块。
- Layer 2:由若干个 Bottleneck 残差块组成,通常有 4 个块。
- Layer 3:由若干个 Bottleneck 残差块组成,通常有 23 个块。
- Layer 4:由若干个 Bottleneck 残差块组成,通常有 3 个块。
每一层的输出通道数和步幅都是不同的,通常是随着网络深度的增加而增加。
-
输出层:全局平均池化层(Global Average Pooling)将特征图的空间维度压缩到 1x1,然后通过全连接层(Fully Connected Layer)进行分类或回归。
3. 优点
-
深度网络训练:由于引入了残差学习,ResNet 可以有效训练非常深的网络,而不会出现传统深度网络中的梯度消失或梯度爆炸问题。
-
性能优越:ResNet-101 在多个标准数据集(如 ImageNet)上表现优越,证明了其有效性和泛化能力。
-
迁移学习:可以将预训练的 ResNet-101 模型用于其他任务,如目标检测、图像分割等,具有很好的迁移学习能力。
4. 应用
-
图像分类:在大规模数据集(如 ImageNet)上的图像分类任务中,ResNet-101 表现优异。
-
目标检测:作为 backbone 网络,ResNet-101 被广泛应用于目标检测模型中,如 Faster R-CNN 和 Mask R-CNN。
-
图像分割:ResNet-101 也被用于图像分割任务,通过将其与特定的解码器结构结合,可以实现高质量的分割结果。
import torch
import torch.nn as nn
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.conv3 = nn.Conv2d(out_channels, out_channels * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channels * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
super(ResNet, self).__init__()
self.in_channels = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, out_channels, blocks, stride=1):
downsample = None
if stride != 1 or self.in_channels != out_channels * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channels, out_channels * block.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * block.expansion),
)
layers = []
layers.append(block(self.in_channels, out_channels, stride, downsample))
self.in_channels = out_channels * block.expansion
for _ in range(1, blocks):
layers.append(block(self.in_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet101(num_classes=1000):
return ResNet(Bottleneck, [3, 4, 23, 3], num_classes)
# 创建模型
model = resnet101(num_classes=10) # 修改为你自己的类别数量
# 将模型移动到设备(例如 GPU)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model.to(device)
print(model)

















 1110
1110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









