







零、上节课学到了什么?
1、“神器”nn.linear,通过nn.linear(A,B)可以把数据从A维度转换到B维度
一个(16,4)的矩阵(表示16条数据每个数据有四个参数)经过nn.linear(4,1)会转化为(16,1).
2、梯度下降算法,SGD(随机梯度下降),通过沿着损失函数梯度的反方向更新参数来逐步逼近最优解,每次迭代使用一个小批量的数据样本。
相对于标准梯度下降,提高了参数更新的稳定性,又加快了收敛速度
缺点是对学习率敏感:选择合适的学习率至关重要。如果学习率过高,可能会跳过最优点;如果太低,则会显著增加训练时间。
优化方法:通过加入动量项加速SGD,并且有助于减少方差。动量考虑了之前梯度的方向,使得更新方向更加稳定,尤其是在遇到局部极小值或鞍点时能够更快地“滚动”出来。
optim.SGD(model.parameters(), lr=config["lr"], momentum=config["momentum"])目前流行的Adam(Adaptive Moment Estimation自适应矩估计)通过计算梯度的第一时刻估计(均值)和第二时刻估计(未中心化的方差)为每个参数计算自适应的学习率。
一、如何做分类的输出?
可以用linear(4,1)输出成一个数,根据数的大小来分类么?
不能,因为对于分类的每个项的权重是相当的,pred_y=0.4对于y=1和y=4这两个分类来说不应该存在远近关系
要采用独热编码来进行分类
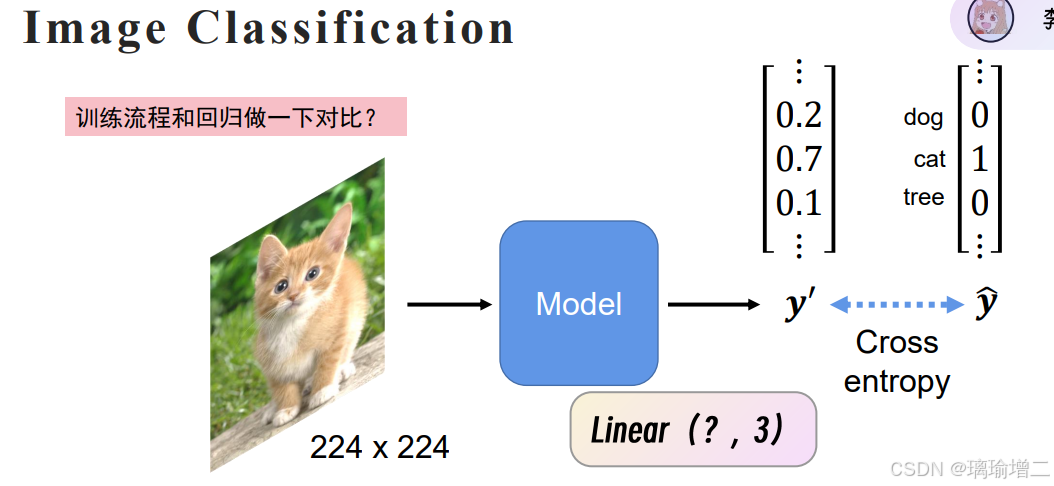
图片输入模型,经过linear(?,3)生成一个三维向量,跟分类项的独热编码通过交叉熵损失函数来得到loss(不能用回归任务里的MSE/MAE等损失函数了,因为这是三个值和三个值之间的对比)预测值表示的是概率分布。
二、如何做模型的输入
卷积神经网络,卷积层通过滑动一个或多个卷积核遍历整个输入空间,并对每个位置进行点乘运算来生成特征图。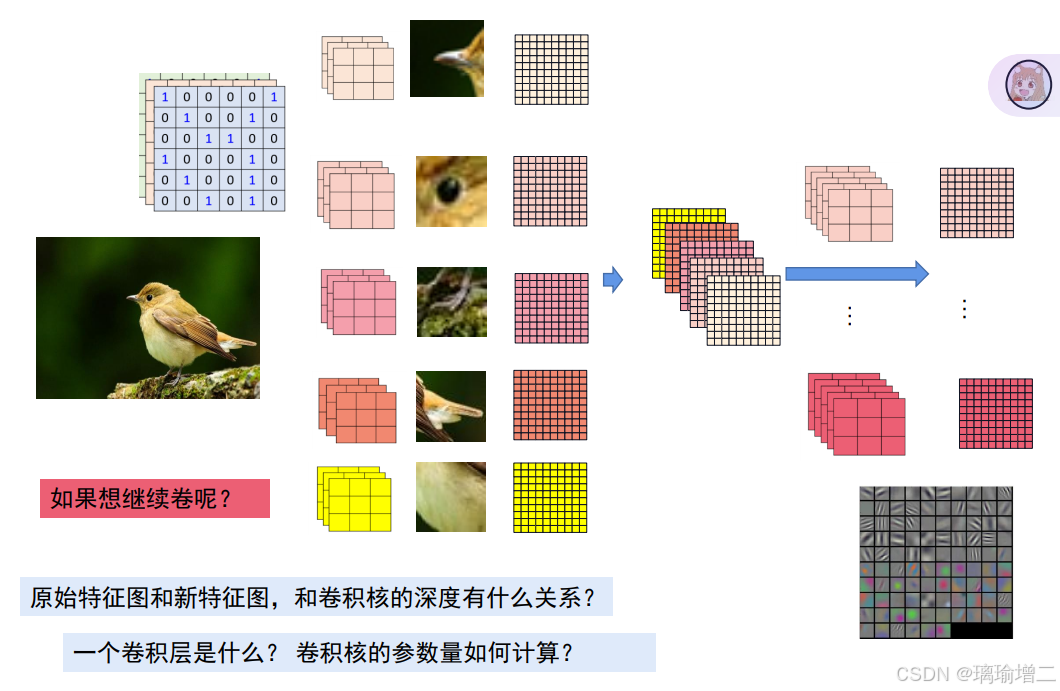 原始特征图和新特征图,和卷积核的深度有什么关系?
原始特征图和新特征图,和卷积核的深度有什么关系?
特征图有多少个通道/层数、卷积核就要有多少层数
一个卷积层是什么? 卷积核的参数量如何计算?
一个特征图通过卷积核卷积,得到新的特征图,这个过程被称为一层卷积。
卷积核的参数量计算
,其中,out是输出尺寸,IN是输入尺寸,k(kernal)是卷积核尺寸,P是padding,S(stride)是步长,向上取整。
如何缩小输出尺寸?扩大步长可能会丢失信息,采用池化(pooling)。
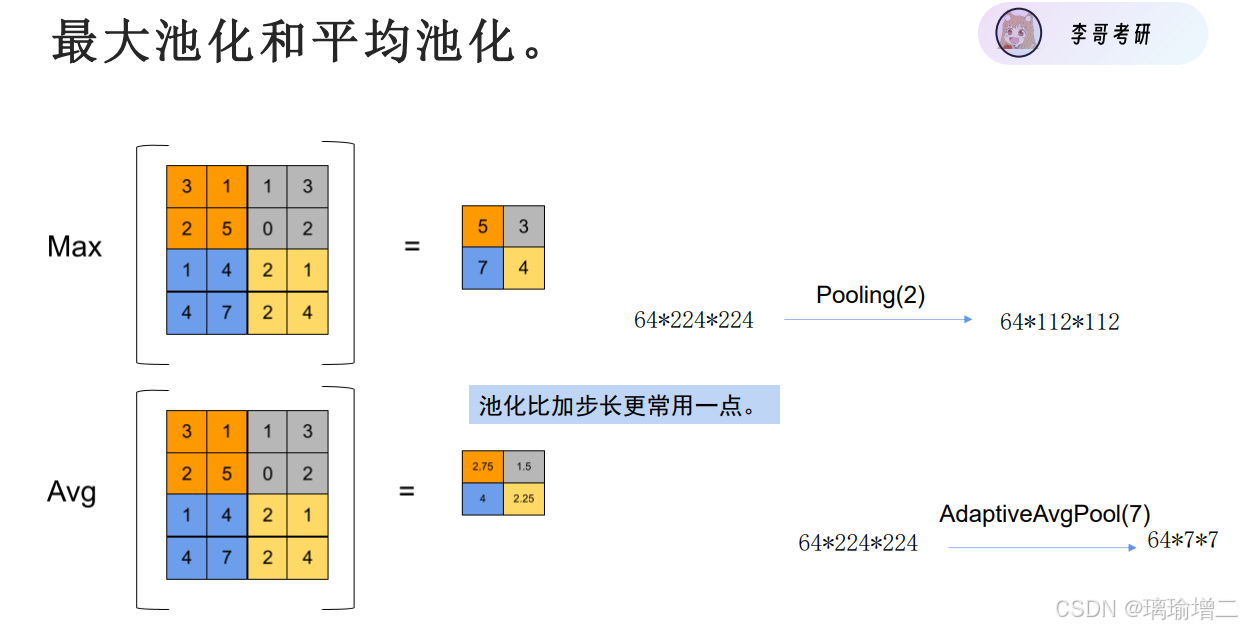
| 特性 | 最大池化 (Max Pooling) | 平均池化 (Average Pooling) |
|---|---|---|
| 主要作用 | 突出显著特征,增强模型对重要特征的关注 | 平滑特征图,抑制极端值,保留背景信息 |
| 噪声鲁棒性 | 对噪声有一定的鲁棒性 | 对噪声敏感 |
| 非线性 | 非线性操作 | 线性操作 |
| 计算量 | 小 | 大 |
| 适用场景 | 更适合用于检测显著特征的任务,如边缘检测、物体识别 | 更适合用于需要保留整体结构的任务,如图像分类,对绘画风格等整体特征能更好识别 |
通过多次卷积和池化层的结合,逐步改变特征图的尺寸
例如3 * 224*224——(64个3*3*3卷积核,padding=1)——> 64*224*224 ——(128个64*3*3卷积核,padding=1)——>(128 * 224*224)——(maxpooling(2))——>128*112*112 ——(256个128*3*3卷积核,padding=1)——(maxpooling(2))——> 256*56*56 ——(512个256*3*3卷积核,padding=1)——(maxpooling(2))——> 512 * 28*28——(1024个512*3*3卷积核,padding=1)——(maxpooling(2))——> 1024 * 14*14 ——(maxpooling(2))——>1024*7*7
三、怎么卷出来一个类别呢
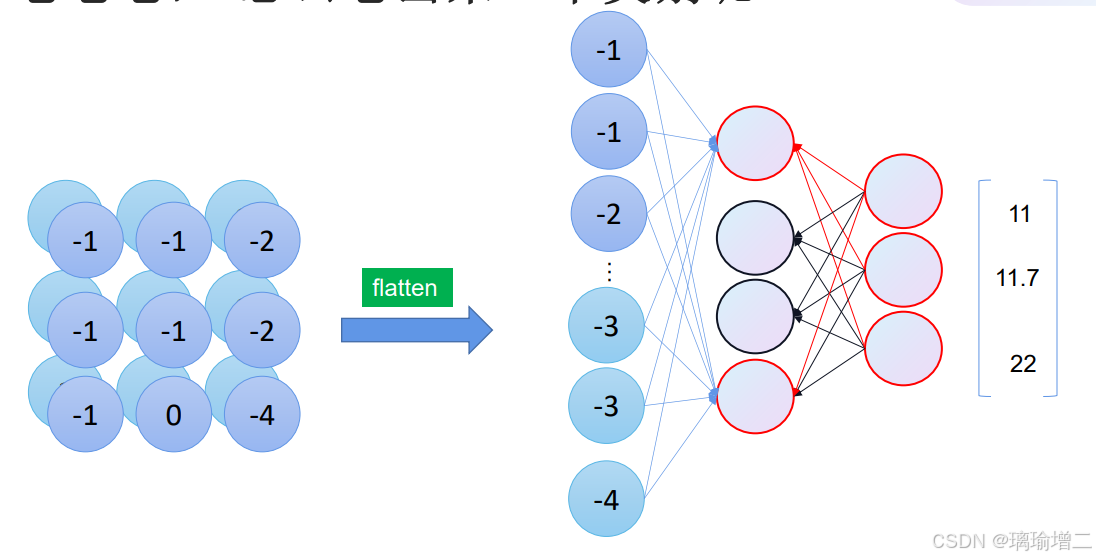
将卷积的特征图展平(flatten)并通过全连接神经网络输出为待分类别维数的张量
四、loss?
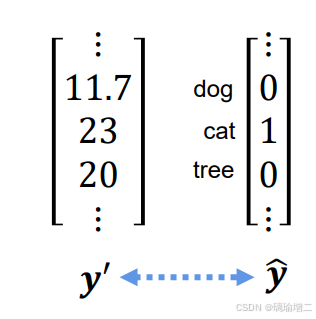 输出的pred_y各项的和不为1,如何表示分类概率?
输出的pred_y各项的和不为1,如何表示分类概率?
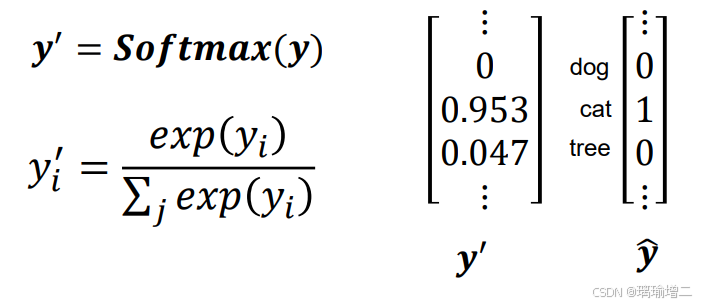
通过softmax激活函数,将一个K维的实数向量映射为另一个K维的概率分布向量,使得每个元素都在[0,1]范围内,并且所有元素之和为1。nn.softmax()
交叉熵损失函数
CrossEntropy loss
关于信息熵 ,KL散度,交叉熵,一文读懂(bushi)。_分布的信息熵-优快云博客
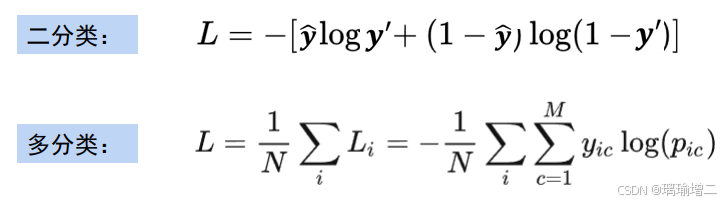
 预测的分布即FC输出的结果,真实值下标即按分类传入【0,1,2,3,。。。。】
预测的分布即FC输出的结果,真实值下标即按分类传入【0,1,2,3,。。。。】
五、经典图片数据集
MNIST数据集(手写数字识别)
cifar10(分十类,经典的小图片数据集)
imagenet(最大、最出名、有百万级别的照片量,1024类)
coco(除标签外包含一些对图片的描述)
六、经典神经网络
Sota 模型。 Sota: the state of the art(可以理解为对模型效果的评价,相当于行业黑话,最好、最先进的模型的意思)
- 经典神经网络 AlexNet:AlexNet有6亿个参数和650,000个神经元,包 含5个卷积层,有些层后面跟了max-pooling层, 3个全连接层 (创新点: relu。 drop out。 池化 归一化) 归一化:各个数据项减去均值除以标准差,统一量纲,避免某些数值过大的参数对模型造成过大影响,它可以让模型关注数据的分布,而不受数据量纲的影响。 归一化可以 保持学习有效性, 缓解梯度消失和梯度爆炸。
from torchvision import models model = models.alexnet() print(model) #AlexNet( (features): Sequential( (0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2)) (1): ReLU(inplace=True) (2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2)) (4): ReLU(inplace=True) (5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (7): ReLU(inplace=True) (8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (9): ReLU(inplace=True) (10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (11): ReLU(inplace=True) (12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) ) (avgpool): AdaptiveAvgPool2d(output_size=(6, 6)) (classifier): Sequential( (0): Dropout(p=0.5, inplace=False) (1): Linear(in_features=9216, out_features=4096, bias=True) (2): ReLU(inplace=True) (3): Dropout(p=0.5, inplace=False) (4): Linear(in_features=4096, out_features=4096, bias=True) (5): ReLU(inplace=True) (6): Linear(in_features=4096, out_features=1000, bias=True) ) )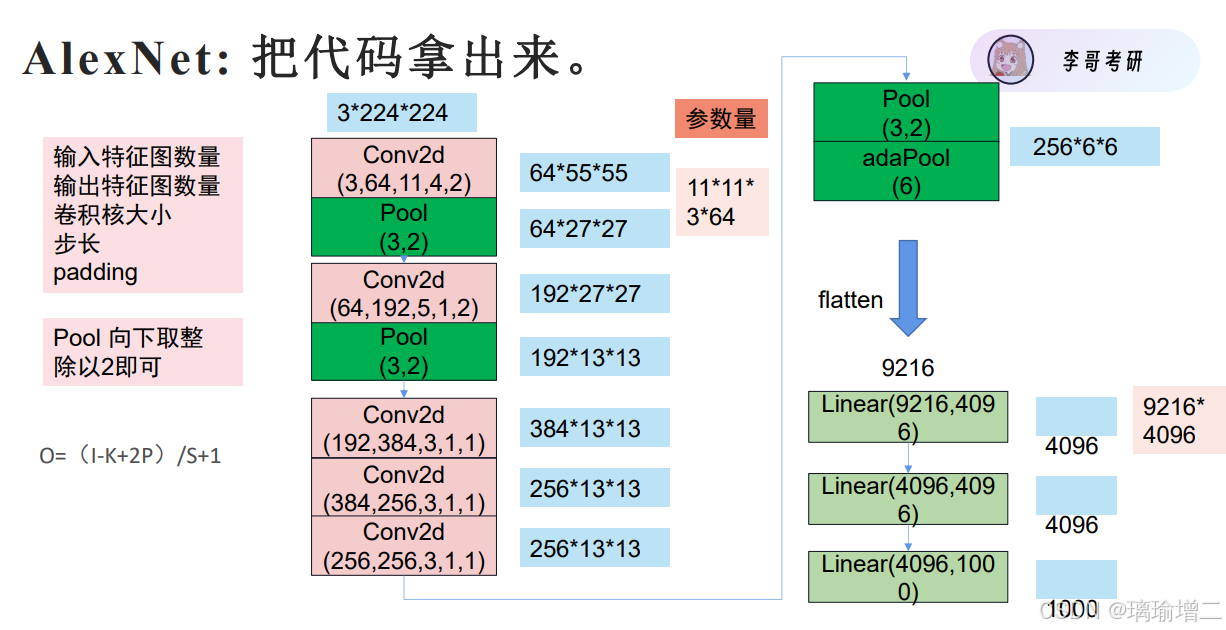 pool(3,2)是三个一poll,但每次走两步
pool(3,2)是三个一poll,但每次走两步 - VGGNet:用两个更小的卷积核代替大的卷积核、加深了网络
- 这样做的好处:在感受野相同的情况下,串联的小卷积核有更少的参数量,更多的非线性变换(多次激活函数),对特征的学习能力更强
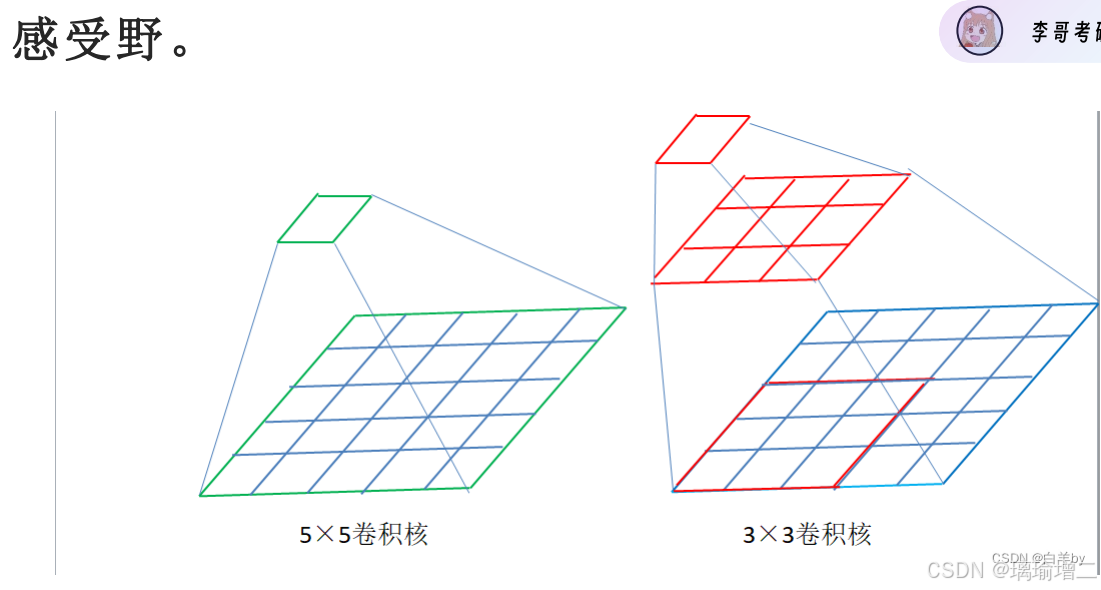 用两个3*3的卷积核代替了一个5*5的卷积核
用两个3*3的卷积核代替了一个5*5的卷积核 
- ResNet (创新: 1乘1卷积和残差连接)
- 残差连接,改善梯度消失的情况,可以把模型做到很深
- 1*1卷积,减少参数量
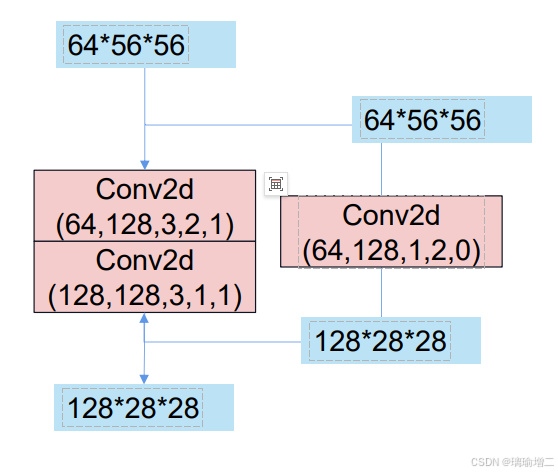 用1*1卷积实现残差连接
用1*1卷积实现残差连接
七、卷积和全连接的关系
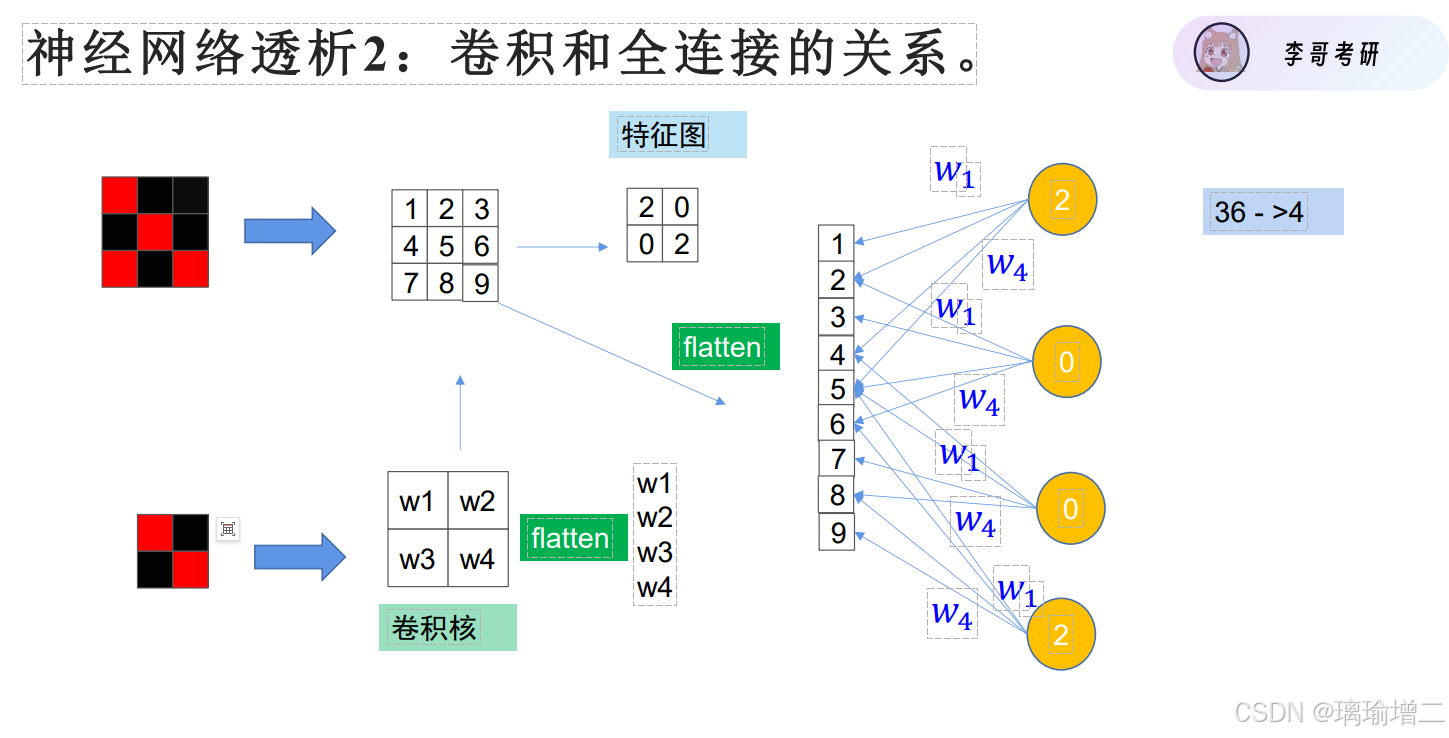
卷积是一种参数共享的不全连接

















 259
259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









