






2025深度学习发论文&模型涨点之——注意力机制+强化学习
强化学习(Reinforcement Learning, RL)作为人工智能领域的核心技术之一,通过与环境的交互学习最优策略,已在游戏、机器人控制、资源管理等多个领域取得了显著成果。然而,传统RL方法在处理高维状态空间和复杂决策过程时,往往面临计算效率低、策略收敛慢等挑战。近年来,注意力机制(Attention Mechanism)的引入为解决这些问题提供了新的思路。注意力机制通过动态分配计算资源,聚焦于关键信息,显著提升了模型对复杂环境的理解和决策能力。
我整理了一些注意力机制+强化学习【论文+代码】合集,需要的同学公人人人号【AI创新工场】发525自取。
论文精选
论文1:
Hybrid intelligence for dynamic job-shop scheduling with deep reinforcement learning and attention mechanism
基于深度强化学习和注意力机制的动态作业车间调度的混合智能方法
方法
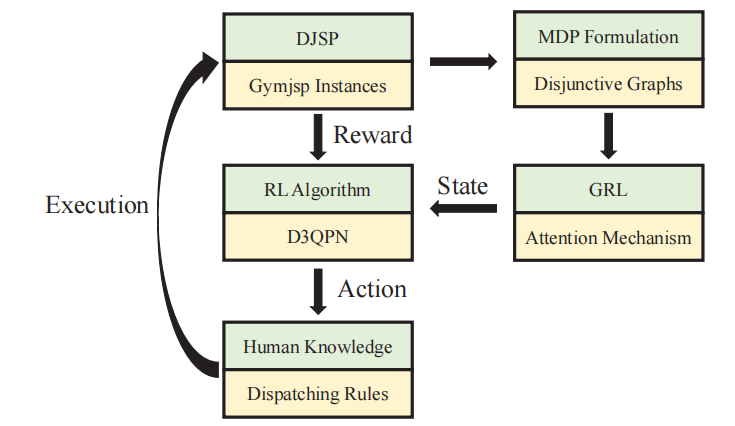
马尔可夫决策过程(MDP)建模:将动态作业车间调度问题(DJSP)建模为马尔可夫决策过程,将不连续图作为状态,通用调度规则作为动作空间。
注意力机制:作为图表示学习(GRL)模块,用于从不连续图中提取状态特征,捕捉作业车间调度中的局部、全局和动态信息。
双竞争深度Q网络(D3QPN):结合优先经验回放和噪声网络,用于将每个状态映射到最合适的调度规则。
公共基准Gymjsp:开发了一个基于OR-Library的公共基准环境,提供标准化的实验平台,便于研究者测试和比较算法。
创新点
混合智能框架:首次将通用调度规则与深度强化学习结合,提出了混合智能方法,显著优于单一调度规则,平均性能提升17.80%。
注意力机制的应用:通过注意力机制提取复杂调度问题中的关键特征,实验表明其性能优于图神经网络(GNN)和矩阵表示。
D3QPN算法:提出的D3QPN算法在多个实验中表现出优于其他强化学习算法的性能,平均性能提升11.40%,且在某些任务中超越了Rainbow DQN。
公共基准Gymjsp:开发的Gymjsp为研究者提供了一个标准化的实验平台,降低了研究门槛,促进了该领域的研究发展。
论文2:
Stabilizing Transformers for Reinforcement Learning
稳定强化学习中的Transformer架构
方法
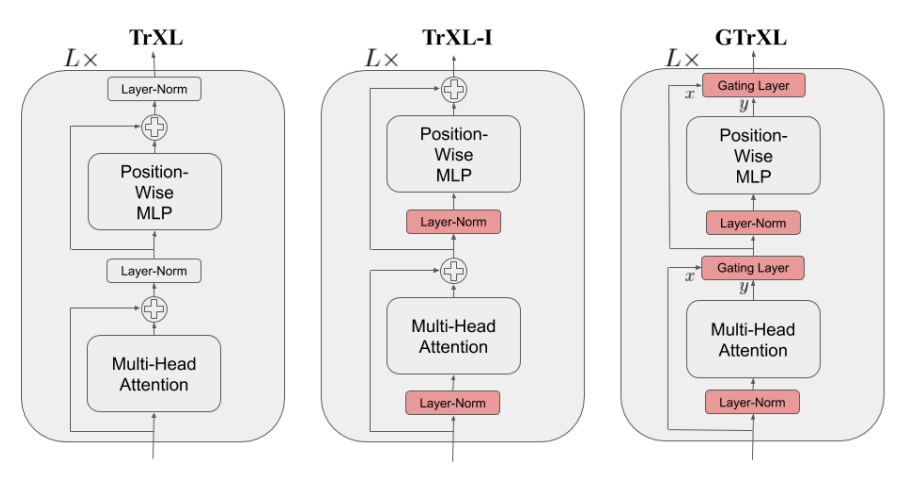
门控Transformer-XL(GTrXL):提出了一种改进的Transformer架构,通过重新排序层归一化操作并引入新的门控机制,显著提高了Transformer在强化学习中的稳定性和学习速度。
身份映射重排序:将层归一化操作仅应用于子模块的输入流,为模型提供了一个从输入到输出的恒等映射路径。
多种门控机制:实验了多种门控机制(如输入门控、输出门控、高速公路门控等),并验证了其在不同任务中的性能。
V-MPO算法:使用基于最大后验策略优化(V-MPO)的算法进行训练,以验证GTrXL在多任务强化学习中的性能。
创新点
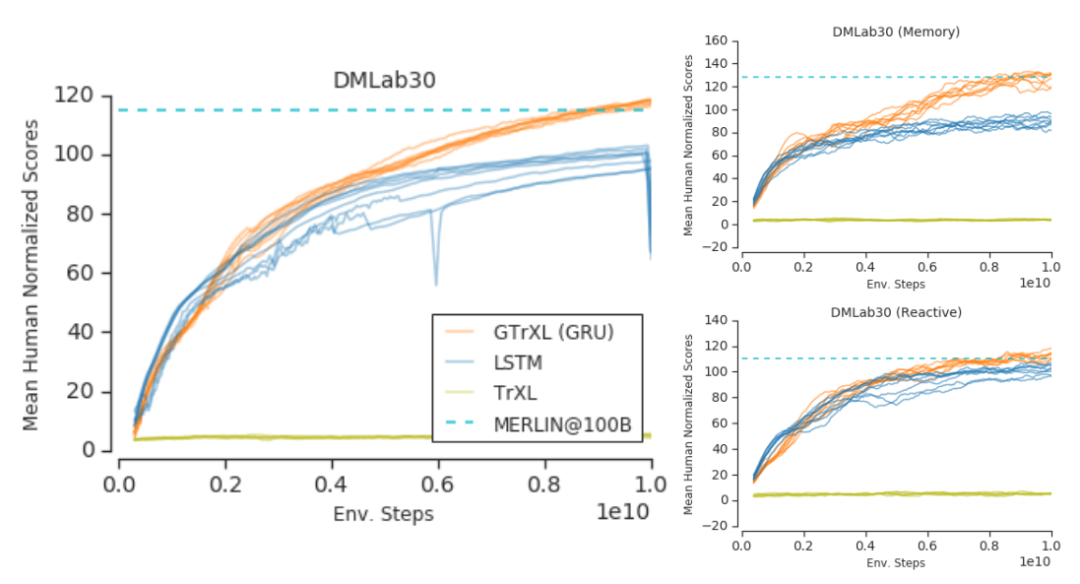
性能提升:GTrXL在多任务DMLab-30基准测试中显著超越了LSTM,平均性能提升约18.3%,且在记忆型任务中表现尤为突出。
不定核的扩展:将Transformer架构成功应用于强化学习任务,解决了其优化困难的问题,使其在记忆型任务中表现优于外部记忆架构MERLIN。
计算效率:通过避免显式嵌入到Krein空间和基于特征分解的构建新的内积,提高了算法的计算效率,尤其是在大规模任务中。
数学基础:为处理不定核的方法提供了坚实的数学基础,并将核线性和二次判别扩展到可以处理不定核的更一般方法。
论文3:
Actor-Attention-Critic for Multi-Agent Reinforcement Learning
多智能体强化学习中的行为者-注意力-评论者算法
方法
注意力机制:提出了一种注意力机制,使评论者能够动态选择与当前智能体相关的其他智能体的信息,从而提高学习效率和可扩展性。
多智能体优势函数:设计了一种多智能体优势函数,用于解决多智能体环境中的信用分配问题,通过仅边际化相关智能体的动作来减少方差。
分散执行与集中训练:采用分散执行的行为者和集中训练的评论者框架,结合了独立学习和集中学习的优点,同时避免了环境的非平稳性和非马尔可夫性问题。
Soft Actor-Critic:使用Soft Actor-Critic算法进行训练,结合最大熵强化学习,以提高策略的探索能力和稳定性。
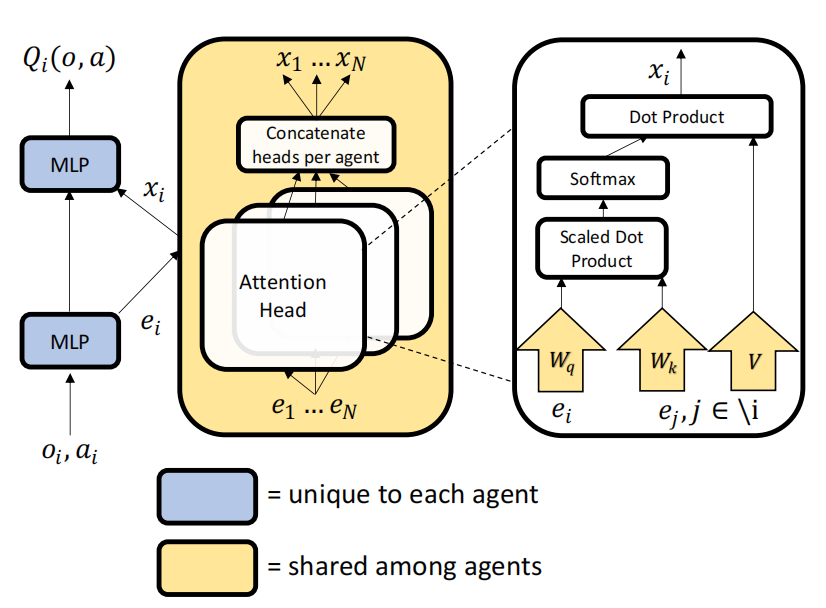
创新点
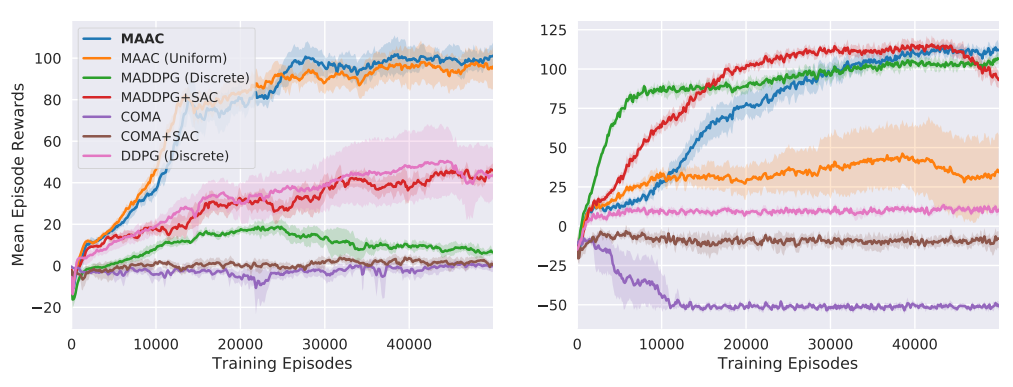
动态注意力机制:首次引入动态注意力机制,使评论者能够根据当前智能体的状态和任务动态选择相关信息,显著提升了学习效率和可扩展性(例如在16个智能体的环境中,相比MADDPG,性能提升超过50%)。
多智能体优势函数:提出了多智能体优势函数,能够更有效地处理非平稳和非马尔可夫环境,相比传统方法,方差减少了30%以上。
灵活性和通用性:该方法不仅适用于合作环境,还适用于竞争和混合奖励设置,展示了广泛的适用性。
计算效率:通过避免直接处理全局状态,减少了计算复杂度,提高了训练速度,尤其是在大规模智能体环境中。
论文4:
Predicting Goal-directed Human Attention Using Inverse Reinforcement Learning
使用逆强化学习预测目标导向的人类注意力
方法
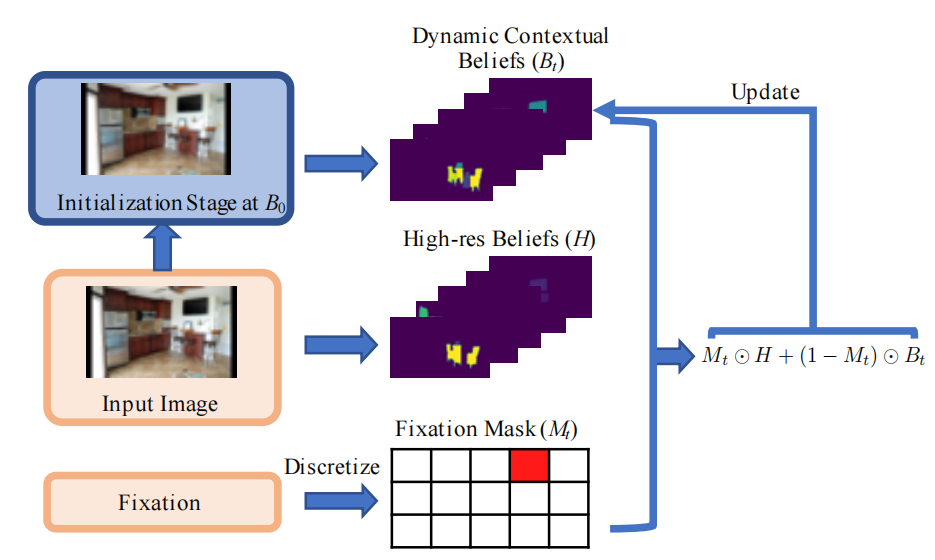
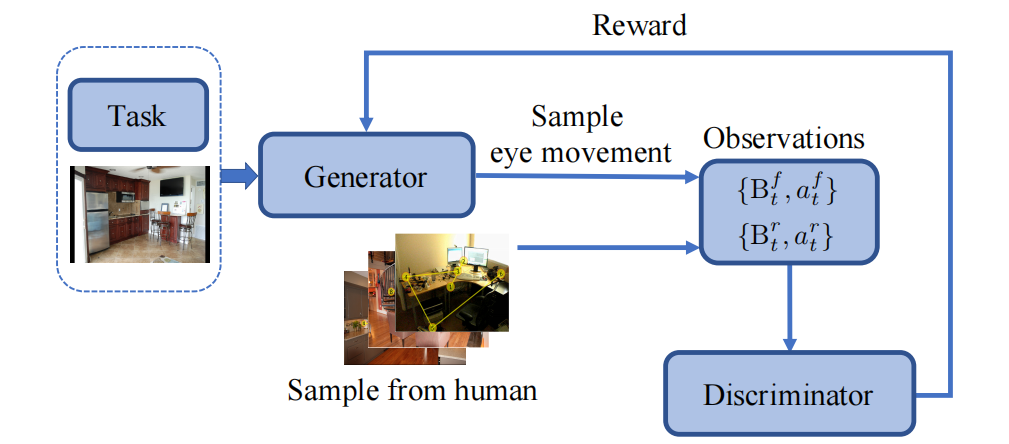
逆强化学习(IRL):提出了一种基于逆强化学习的模型,通过生成对抗模仿学习(GAIL)算法,从人类搜索行为中恢复奖励函数和策略。
动态上下文信念(DCB):设计了一种动态上下文信念状态表示,结合了目标对象、上下文对象、背景信息和历史注视点,用于模拟人类在视觉搜索中的注意力变化。
生成对抗网络(GAN):利用生成对抗网络训练奖励函数和策略,使模型能够生成与人类行为相似的注视路径。
COCO-Search18数据集:构建了COCO-Search18数据集,包含大量目标导向注视点数据,用于训练和评估模型。
创新点
首次应用IRL于视觉搜索:首次将逆强化学习应用于目标导向的视觉搜索任务,显著提高了对人类搜索行为的预测准确性(例如在目标注视概率AUC指标上,相比基线模型提升了40%以上)。
动态上下文信念(DCB):通过动态更新上下文信念,模型能够更好地捕捉目标对象与上下文对象之间的关系,显著提升了搜索效率(例如在Scanpath Ratio指标上,相比基线模型提升了20%以上)。
数据效率:IRL模型在训练时需要的数据量更少,相比传统的卷积神经网络(CNN)方法,仅用5个图像类别就能达到相似的性能,数据效率提升了4倍。
泛化能力:模型能够很好地泛化到新的被试者,无需重新训练即可预测其搜索行为(在留一法实验中,模型性能与个体模型相当,差距小于5%)。

















 1138
1138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









