






2025深度学习发论文&模型涨点之—— 聚类+transformer
Transformer 模型在自然语言处理(NLP)领域取得了显著的成果。然而,传统的聚类算法在数据分析和模式识别中也扮演着重要角色。将聚类技术与 Transformer 模型相结合,不仅能够提升模型的性能,还能在数据预处理和特征提取方面提供新的思路。
聚类Transformer结合了Transformer的强大特征提取能力和聚类算法的高效性,在多视图聚类、目标检测、医学图像分割、高效聚类和通用视觉任务中均展现出显著的优势。这些方法不仅提高了聚类性能,还优化了计算效率和模型的可解释性。
我整理了一些 聚类+transformer 【论文+代码】合集,需要的同学公人人人号【AI创新工场】自取。
论文精选
论文1:
[CVPR] CMT-DeepLab: Clustering Mask Transformers for Panoptic Segmentation
CMT-DeepLab:用于泛视觉分割的聚类掩码变换器
方法
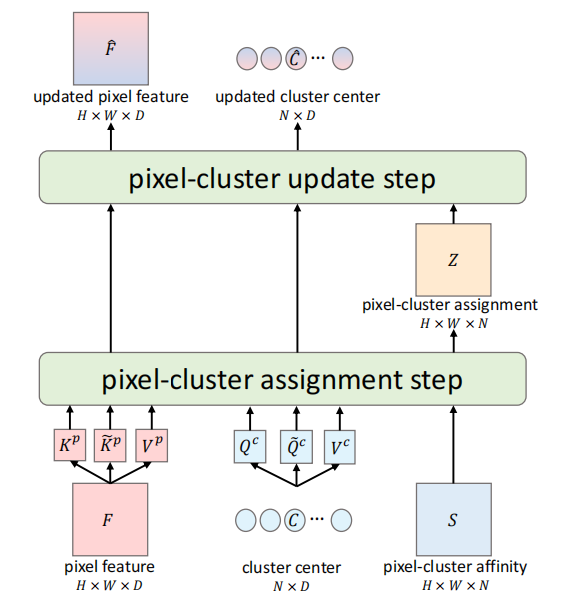
聚类掩码变换器(CMT):提出了一种基于聚类的变换器架构,将目标查询视为聚类中心,通过交替过程(像素分配和聚类中心更新)生成密集的交叉注意力图。
动态位置编码:引入动态位置编码,通过预测参考掩码并结合坐标卷积,增强模型对位置信息的利用。
像素-聚类交互:在每个变换器解码器中更新像素特征和聚类中心,促进像素与聚类中心之间的频繁通信。
掩码近似损失:通过最小化预测参考点与真实掩码点之间的分布距离,优化参考掩码的预测。

创新点
聚类视角的变换器:首次从聚类角度重新思考变换器架构,将目标查询作为聚类中心,显著提升了分割任务中的密集预测性能(在COCO数据集上PQ指标提升了4.4%,达到55.7%)。
动态位置编码:通过动态位置编码和参考掩码预测,增强了变换器对位置信息的利用,进一步提高了模型对分割任务的适应性(PQ指标提升了0.7%)。
性能提升:在COCO数据集上,CMT-DeepLab显著优于现有的端到端泛视觉分割方法,小模型版本(Axial-R50)PQ指标达到53.0%,超越了多尺度Axial-DeepLab(PQ为43.4%)。
论文2:
[CVPR] PaCa-ViT: Learning Patch-to-Cluster Attention in Vision Transformers
PaCa-ViT:在视觉变换器中学习从块到聚类的注意力机制
方法
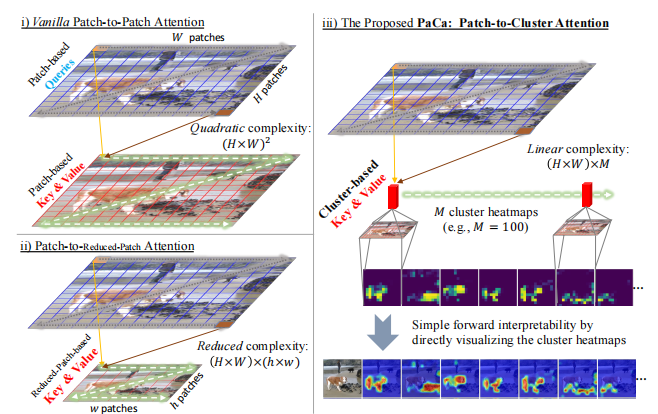
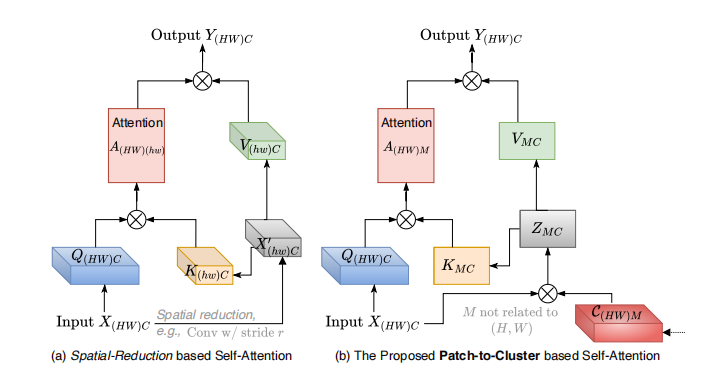
从块到聚类的注意力(PaCa):提出了一种新的注意力机制,通过轻量级聚类模块将输入序列聚类为少量的“视觉标记”,并基于这些聚类结果计算注意力。
外部聚类教师网络:引入外部聚类教师网络,为模型提供更丰富的指导信息,进一步提升模型性能。
线性复杂度:通过聚类将二次复杂度降低为线性复杂度,显著提高了模型的计算效率。
语义分割头:设计了一种轻量级的语义分割头,利用聚类结果进行语义分割任务。
创新点
从块到聚类的注意力:首次提出将块聚类用于视觉变换器的注意力机制,有效解决了传统块到块注意力机制的二次复杂度问题,同时通过聚类生成更具语义意义的视觉标记(在ImageNet-1k数据集上Top-1准确率提升了0.9%,达到83.08%)。
外部聚类教师网络:通过外部聚类教师网络为模型提供更丰富的指导信息,进一步提升了模型性能(在MS-COCO数据集上AP指标提升了0.6%,达到46.4)。
计算效率:通过避免显式嵌入到Krein空间和基于特征分解的构建新的内积,提高了算法的计算效率(在MIT-ADE20k数据集上mIOU指标提升了1.7%,达到50.39)。
性能提升:在图像分类、目标检测和语义分割等多个任务中验证了方法的有效性,取得了优于现有视觉变换器模型的性能。
论文3:
[TPAMI] TCFormer: Visual Recognition via Token Clustering Transformer
TCFormer:基于令牌聚类变换器的视觉识别
方法
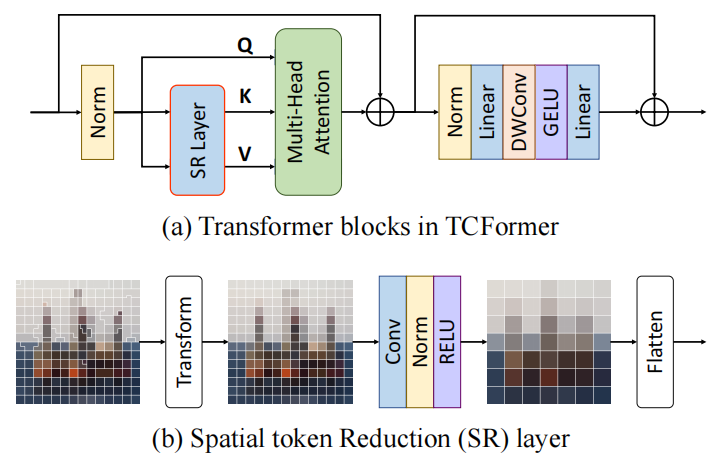
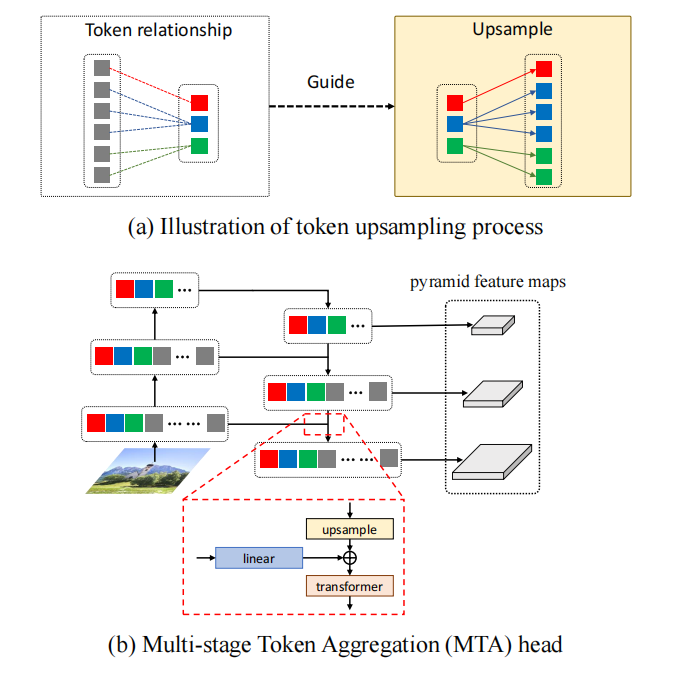
动态视觉令牌生成:提出了一种基于语义的动态视觉令牌生成方法,能够根据图像内容的语义信息动态调整令牌的形状和大小,以更好地表示图像区域。
多阶段令牌聚合(MTA)模块:通过逐层聚合多尺度特征,保留细节信息的同时降低计算复杂度。
聚类引导的MTA(CR-MTA)模块:在MTA模块的基础上引入聚类结果引导注意力过程,进一步提升特征学习能力。
局部CTM模块:在早期阶段对令牌进行局部聚类,降低计算复杂度,同时保持性能。
创新点
动态视觉令牌:通过动态令牌生成,模型能够更好地对齐图像中的对象,提升对象关系学习能力,同时在图像分类任务中Top-1准确率提升了6.3%(与ResNet50相比)。
局部CTM模块:显著降低了计算复杂度,TCFormerV2-Small的GFLOPs比TCFormerV1降低了23.7%,同时保持了相同的性能。
CR-MTA模块:通过聚类结果引导注意力过程,进一步提升了性能,mIoU在语义分割任务中提升了0.7%(与SR-MTA模块相比)。
多任务验证:在图像分类、人体姿态估计、语义分割和目标检测等多个任务中验证了方法的有效性,均取得了优异的性能提升。
论文4:
Transformer-Based Hierarchical Clustering for Brain Network Analysis
基于变换器的脑网络层次聚类分析
方法
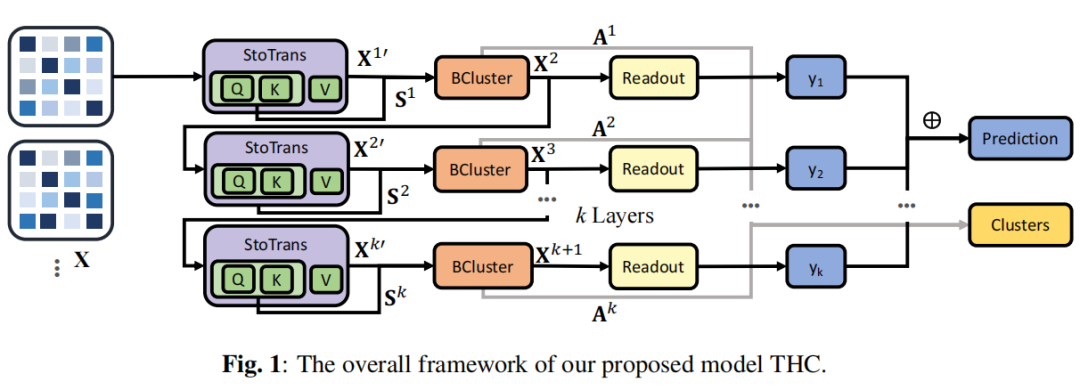
层次聚类模块(BCluster):通过变换器编码器和聚类层联合学习全局共享的聚类分配,逐步将低层次模块组合成更抽象的高层次聚类表示。
随机噪声增强:在变换器注意力机制中引入随机噪声,增强模型的聚类学习能力。
多层读出模块:每一层聚类模块都连接一个读出模块,有效利用每一层的聚类嵌入,提升模型的预测能力。
端到端学习:通过端到端的方式学习聚类分配,并针对下游任务进行优化。
创新点
层次聚类:通过层次聚类结构,模型能够学习更抽象的高层次聚类表示,显著提升了脑网络分析的准确性,AUROC在ABIDE数据集上提升了3.2%,在ABCD数据集上提升了1.7%。
计算效率:通过聚类减少节点数量,将计算复杂度从O(n²d)降低到O(k²d),其中k为聚类数量且k<<n,显著降低了运行时间,ABCD数据集上运行时间减少了24.7%,ABIDE数据集上减少了22.0%。
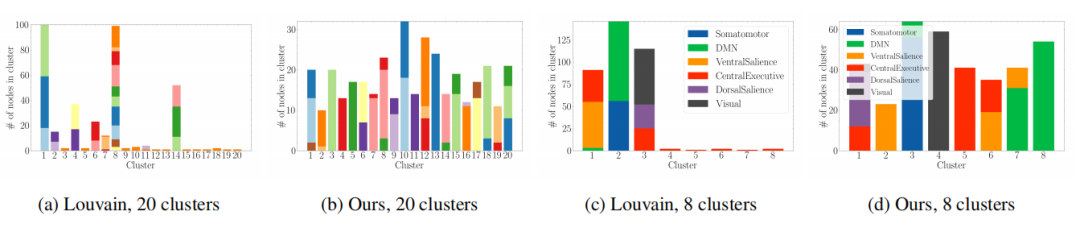
聚类质量:与传统聚类方法(如Louvain、Lloyd算法)相比,THC模型的聚类纯度(purity)达到了88.9%,比最高基线高出4.7%,NMI和同质性(homogeneity)也显著优于基线方法。
临床可解释性:聚类结果与脑功能模块的真实标签高度一致,为临床诊断提供了有价值的见解。

















 1231
1231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









