






单一决策树的弱点与集成方法的优势
使用单一决策树的一个主要问题是它对数据中的微小变化非常敏感。例如,假设我们在训练集中只改变一个样本的特征(比如将一只猫的特征从“尖耳朵、圆脸、有胡须”改为“软耳朵、有胡须”)。这种微小的改变可能导致决策树在根节点选择不同的特征进行分割(比如从“耳朵形状”改为“其他特征”),从而使得左右子树的数据分布完全不同。随着决策树学习算法的继续运行,左右子树会进一步分化,最终生成完全不同的决策树。因此,仅仅改变一个训练样本,就可能导致决策树在根节点产生不同的分割,进而生成一个完全不同的决策树。这种对数据微小变化的敏感性使得单一决策树算法不够健壮。
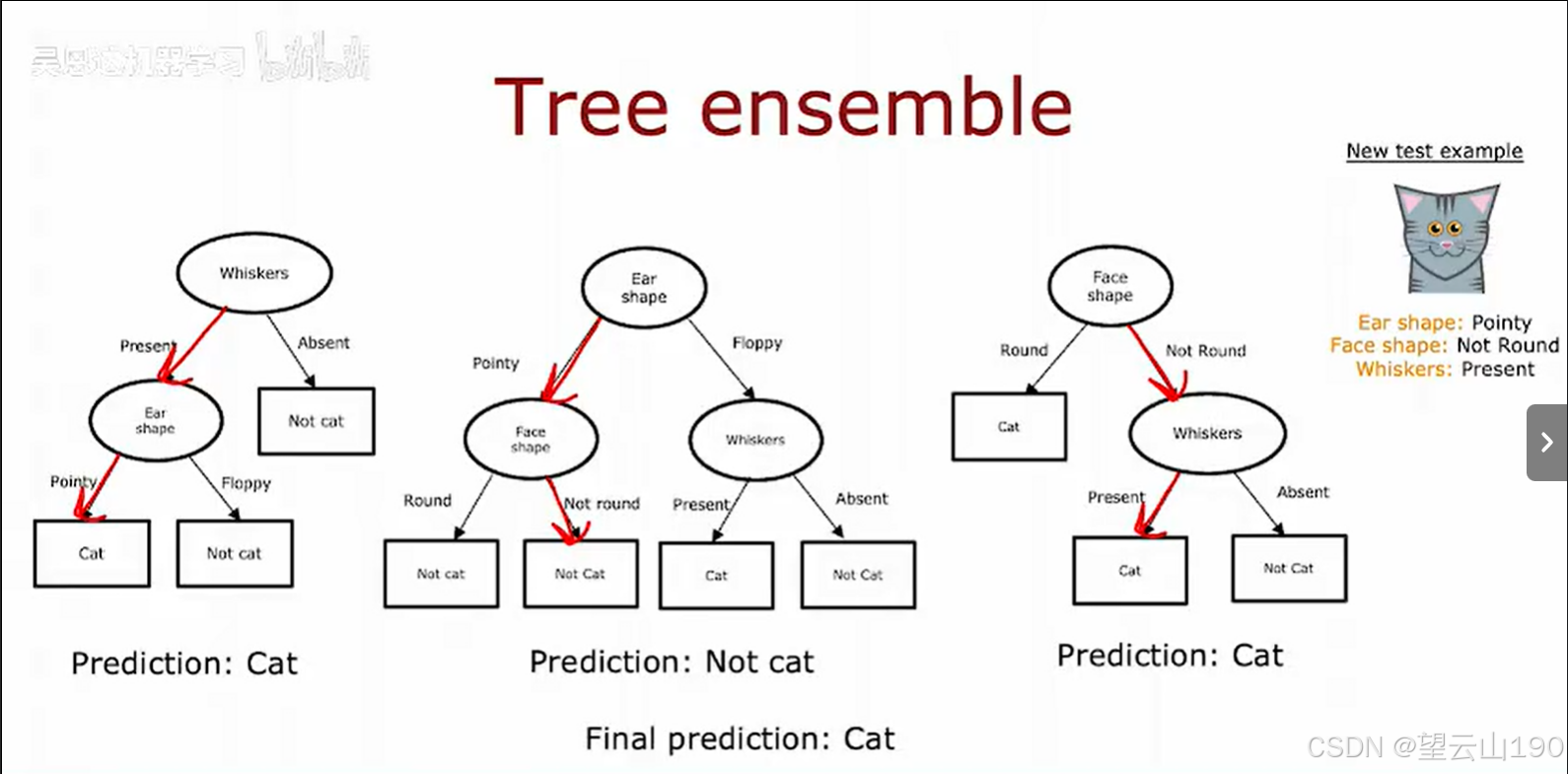
为了解决这一问题,我们可以采用集成方法,即构建多个决策树而不是单一决策树。通过让这些决策树共同投票决定最终的预测结果,可以显著提高算法的鲁棒性。例如,假设我们有三棵决策树,每棵决策树都基于不同的特征和数据子集进行学习。当有一个新的测试样本需要分类时,我们分别用这三棵树对样本进行预测。假设这个样本有“尖耳朵、圆脸和胡须”,第一棵树可能会预测它是猫,第二棵树可能会预测它不是猫,第三棵树可能会预测它是猫。这三棵树做出了不同的预测,但通过投票机制,多数树预测它是猫,因此最终的预测结果就是“猫”。这种基于投票的集成方法使得整体算法对单个决策树的决策不那么敏感,因为每棵树的预测只占总票数的一部分。
通过让多个决策树投票,整体算法变得更加健壮。即使某些决策树因为数据微小变化而产生错误预测,其他树的正确预测可以通过投票机制弥补这一缺陷。接下来,我们将探讨如何构建这些决策树的集合,以及如何通过不同的策略让它们产生多样化的决策,从而进一步提升集成方法的性能。
替换取样:构建决策树的关键技术
为了构建集成模型,我们需要一种技术,叫作替换取样。(即拿出放回再拿)它的原理如下:
假设我们有一个袋子,里面有4个不同颜色的球:红色、黄色、绿色和蓝色。我们从袋子里随机抽取一个球,比如抽到了绿色球。然后,我们将绿色球放回袋子里,摇一摇,再抽取下一个球。可能这次抽到黄色球,我们同样把它放回袋子里,继续抽取。第三次可能抽到蓝色球,再次放回。第四次可能又抽到蓝色球。这样,我们得到的抽取序列是:绿色、黄色、蓝色、蓝色。
注意,由于每次抽取后都会放回,所以某些颜色可能会被重复抽到,而有些颜色可能一次都抽不到(比如红色)。通过这种方式,每次抽取的结果都是随机的。
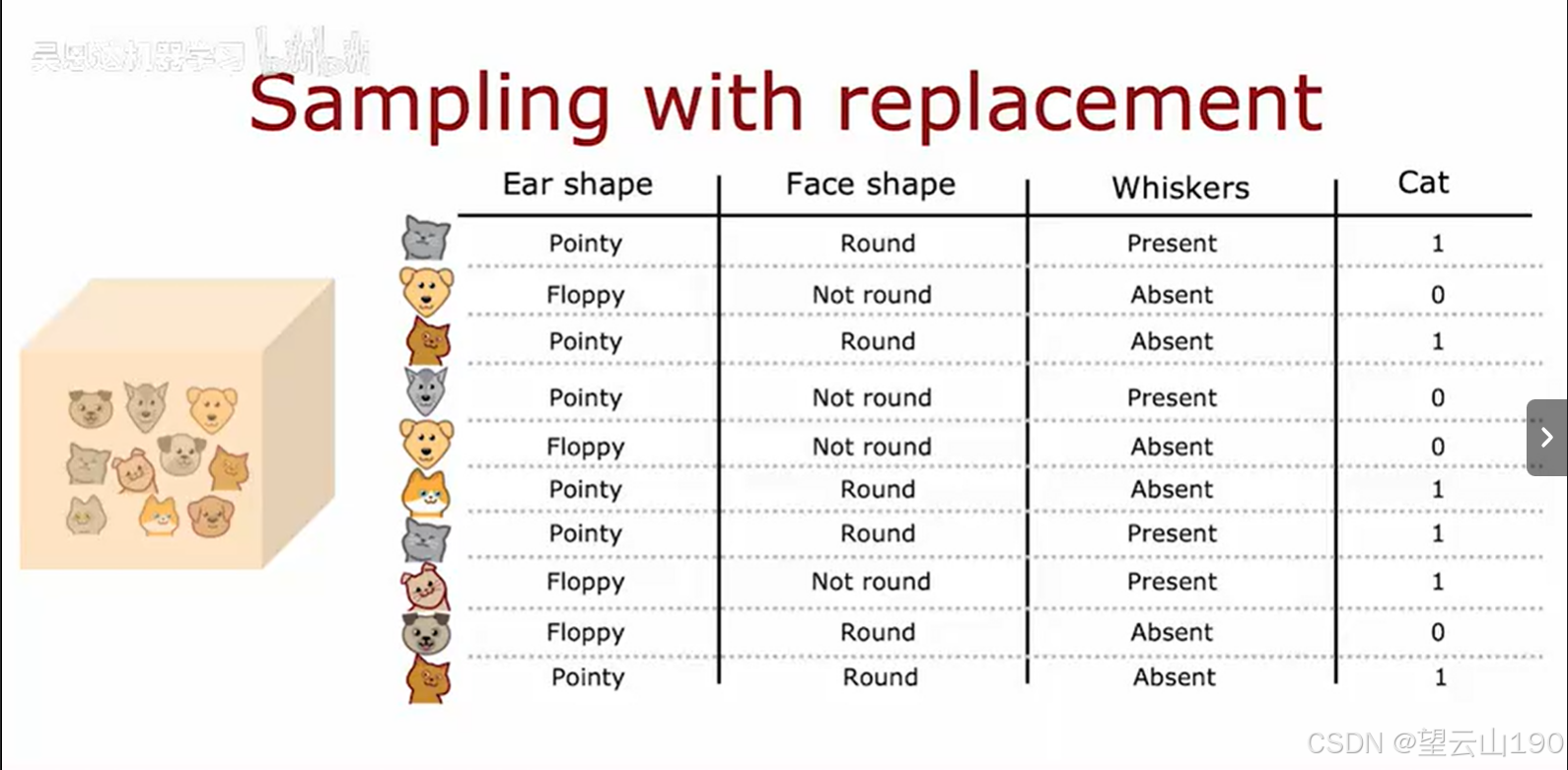
这种替换取样的方法非常适合用来构建决策树。具体来说,我们可以用它从初始的训练数据集中生成不同的随机训练子集。例如,假设我们有一个包含10个样本的训练集(比如10张猫和狗的图片)。我们可以将这10个样本放入一个“袋子”中,然后通过替换取样的方式从中抽取新的样本,构建一个新的训练集。这个新的训练集与最初的训练集可能有所不同,因为某些样本可能会被重复抽取,而有些样本可能一次都没有被抽到。
这种通过替换取样生成不同训练集的方法,是构建决策树森林的关键。每棵决策树都可以基于不同的数据子集进行学习,从而增加模型的多样性和鲁棒性。


















 9006
9006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









